
融合组合赋权与嵌套集成分类器的服务商评价
2021-01-14 01:49刘鹏程孙林夫张常有
计算机集成制造系统 2020年12期
刘鹏程,孙林夫+,张常有
(1.西南交通大学 信息科学与技术学院,四川 成都 610031;2.中国科学院 软件研究所,北京 100190)
1 问题的提出
汽车售后服务是一项非常繁杂的工程,售后服务业务经营的优劣不仅直接影响制造企业的利润,还对品牌、客户忠诚度等方面产生不同程度的影响,提供高水平售后维修服务的企业,其市场销售额往往处于上升趋势,反之,则处于不利地位[1]。
合理提升售后服务网络覆盖面是制造企业提升售后维修服务水平的基础支撑,拥有完善的售后服务网络可以及时响应用户的服务需求。而构建覆盖全国的售后维修服务网络则需要投入大量资源,这势必会导致制造企业减少对产品研发、制造等环节的资源投入,如此将影响制造企业核心业务的发展,且与当前企业归核化[2]发展趋势不符,因此多数汽车制造企业采取与其他企业合作经营等策略来扩展服务网络,如汽车制造企业通过与4S店、汽车维修服务商进行合作,提升售后服务网络覆盖面,双方通过合作不仅为汽车制造企业节省了大量资源,还为服务商带来了更多的利润。
通过这种合作形成了以制造企业为核心,同时,通过与服务商群开展服务业务协同,为终端用户提供售后服务的服务价值链(如图1)。汽车服务价值链包括汽车制造企业、售后服务商群、终端用户群在内的价值节点及其间的服务业务活动,其中服务商群主要由4S店、加盟维修服务商等构成,终端用户群包括个人和企业用户,服务价值链通过服务业务活动产生的物流、信息流,资金流实现价值流动。汽车制造企业对整条价值链进行管控,通过与售后服务商群开展服务业务协同,共同为终端用户群提供售后服务,实现整条价值链的增值。
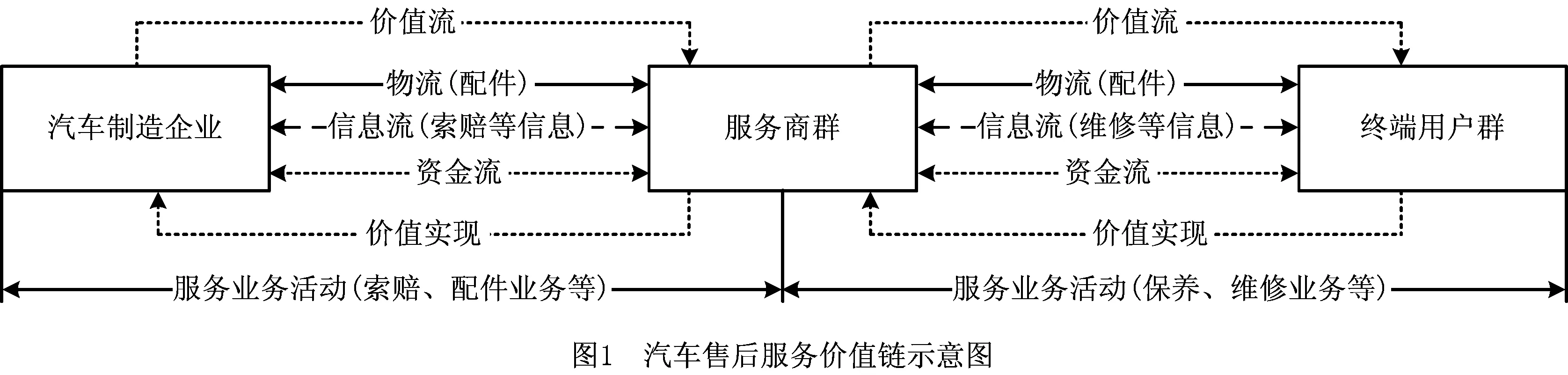
服务价值链中的服务业务活动主要包括两种:①汽车制造企业与服务商群之间的服务业务协同活动;②服务商群与终端用户群间的服务业务活动。服务商群是整条价值链中承上启下的关键节点,制造企业通过与服务商群开展服务业务协同,向各地用户提供售后服务资源,用户可以直接从服务商处获取售后服务资源,所有影响制造企业与服务商群进行业务协同的因素最终将影响终端的服务质量,而服务商群的业务协同能力就是其中一个重要因素,服务商的业务协同能力不仅反映出服务商对核心服务业务的处理能力,还反映出服务商与制造企业协同处理服务业务的能力,因此该因素是制造企业对服务价值链管控和优化的重点。而对服务商进行业务协同能力评价是汽车制造企业管控服务价值链和提升售后服务质量的重要方法。
2 相关研究及问题分析
2.1 服务商评价研究现状分析
当前,对服务商评价的研究已经取得了许多成果,主要集中于评价指标体系和评价方法两个方面。其中:评价体系指对评价对象相关指标内容的研究;评价方法主要包括基于赋权算法的评价方法和基于分类模型的评价算法。
(1)评价指标体系
选择评价指标形成服务商评价指标体系是开展服务商评价的第一步,通过分析服务商评价指标体系相关研究,可以发现当前服务商评价指标主要涉及到对服务商与客户端之间的服务活动进行评价,如文献[3]构建了汽车售后服务客户满意度评价指标,以开展汽车售后服务客户满意度评价;文献[4]构建了售后服务维修质量评价体系,以开展对服务商整车维修质量的评价;文献[5]构建了服务商服务能力评价指标体系开展对服务能力的评价;文献[6-9]围绕服务商服务质量评价指标开展对服务商服务质量的评价;文献[2,10]构建了综合评价指标,开展对服务商服务质量、服务能力和维修等多方面的评价。
(2)基于赋权算法的评价方法
基于赋权算法的评价方法主要依据服务商评价指标进行赋权计算,基于相关评价指标的权重计算评价结果。当前评价指标赋权算法可以归为主观赋权法、客观赋权法和主客观组合赋权法3种类型,3种赋权算法从不同层次进行赋权计算。
1)主观赋权算法 主观赋权算法依据人为主观判断对各评价指标间的重要程度进行赋权,以实现目标对象量化评价,其中Delphi[2]和层次分析法(Analytic Hierarchy Process, AHP)[4,11-12]等算法是常用的主观评价算法。Delphi算法侧重于从全局考虑各个指标项间的相对权重关系,AHP算法侧重于考虑不同层级指标之间的相对权重,多数研究以该算法为基础开展进一步的研究。除直接使用AHP计算评价结果外,相关研究还将AHP算法与其他模型结合以优化评价结果,如文献[12]利用AHP算法结合服务质量差距模型(也称GAP模型)开展对轿车服务质量评价的研究。
2)客观赋权算法 客观赋权算法是基于评价数据计算各指标项所包含的评价信息来确定权重的方法,其中Critic赋权算法[2,13]、主成分分析(Principal Component Analysis, PCA)赋权算法[14]和熵权法[2,6,8]为常用的客观评价算法。Critic算法侧重于考虑指标间的对比强度和冲突性。PCA赋权算法通过转换成n(主成分个数参数)个互相独立的主成分后,利用特征向量计算权重,并不考虑指标间的关系。熵权法依据各指标项中包含信息量的多少来确定当前指标项权重,其在对服务商评价研究中有较多的应用,如文献[6]基于评价指标收集问卷数据,利用问卷数据和熵权法实现对汽车4S店售后服务质量评价指标进行赋权,找出影响服务质量的原因。文献[8]提出基于售后服务数据进行分析,利用熵权法结合逼近理想解排序 (Technique for Order Preference by Similarity to Ideal Solution, TOPSIS)算法实现对售后服务商的维修和保养业务的评价。
3)主客观组合赋权算法 主客观组合赋权算法是通过相关组合算法将主观赋权算法所得权重和客观赋权算法所得权重进行组合,形成新的评价权重,通过对主客观权重进行特定组合,实现对多组权重信息的融合,同时兼顾主客观赋权算法对评价的影响。文献[2]提出一种三阶段主客观公平权重评价算法,组合利用主观和客观赋权算法,设计了一种公平权重算法,以权重差异度最小化为目标函数确定组合权重。文献[13]利用AHP等3种主观赋权算法与熵权法和Critic等3种客观赋权算法进行组合,实现对评价指标的定权,通过计算3种主观赋权和3种客观赋权的算术平均值后,计算两组平均值的几何均数作为最后的组合权重进行评价。文献[15]提出通过建立以主客观权重贡献趋于均衡为优化目标的平衡模型,通过利用平衡系数来替代经验因子进行主客观权重的组合。文献[16]提出一种混合AHP算法和客观赋权数据包络分析法(Data Envelopment Analysis, DEA)的评价方法,利用AHP确定各个指标的主观权重,利用DEA评价方法计算评价得分,最后通过TOPSIS算法组合AHP和DEA的结构得出最后评价结果。
(3)基于分类模型的评价方法
服务商评价问题本质上是一类分类问题,该问题是基于不同的指标数据将不同的服务商划分到预定类别中。因为机器学习技术可以实现较好的分类效果,所以一些机器学习分类模型被应用到评价任务中。
1)基于监督学习分类模型的评价方法 基于监督学习的分类模型从已评价数据中学习评价知识构建分类模型,训练完成的分类器模型可以直接对未知对象进行评价,如文献[17]提出利用相关向量机模型实现对服务商维修服务质量的评价,文献[18]利用决策树算法实现对目标的评价,文献[19]提出利用改进支持向量机对目标进行等级分类从而实现对目标的评价。
2)基于非监督学习分类模型的评价方法 利用非监督学习分类模型不需要已知评价结果,而是基于对评价数据本身进行计算形成分类结果,但这种分类结果是一种不明确的评价结果,因此基于非监督学习评价方法常与赋权算法相结合形成评价模型,如文献[4,20]利用AHP算法结合聚类算法,通过分类实现目标评价。
2.2 服务商评价问题分析
2.2.1 服务商评价指标问题分析
多数文献构建的评价体系均以服务商维修质量、服务质量和服务能力为主,重点关注于服务终端与客户之间的活动,而忽略了服务价值链中服务商与制造企业的业务协同活动,缺少面向汽车制造企业的服务商业务评价指标,尤其是汽车制造企业所关注的三包期内索赔、保养、救援等核心售后服务业务,多数文献中均没有涉及。文献[2,10]构建的评价指标体系中涉及了汽车制造企业所关注的相关服务业务指标,但该类评价指标体系存在层次划分不够清晰、重复冗余指标、缺失部分重要业务指标等问题。如文献[2]关注服务商的业务效率但却忽视了服务商的业务量,文献[10]缺少对服务业务真实性评价指标等。
2.2.2 服务商评价算法问题分析
利用指标赋权算法进行评价是常用的方法,而利用主客观赋权算法进行组合赋权为其中的研究重点,此外基于机器学习的分类算法也成为评价问题的研究内容,下面将对这两大类方法在评价中的应用展开具体分析。
(1)主客观组合赋权评价算法分析
主客观组合赋权的目的在于将客观数据规律与主观人为经验判断进行融合,在一定程度上缓解数据偏差或主观偏好引起的赋权偏差,所以当前研究多集中于主客观组合赋权,而不只考虑一种赋权方法,从模型结构角度出发主客观组合赋权可以分为单层主客观权重组合评价模型和双层主客观权重组合评价模型。
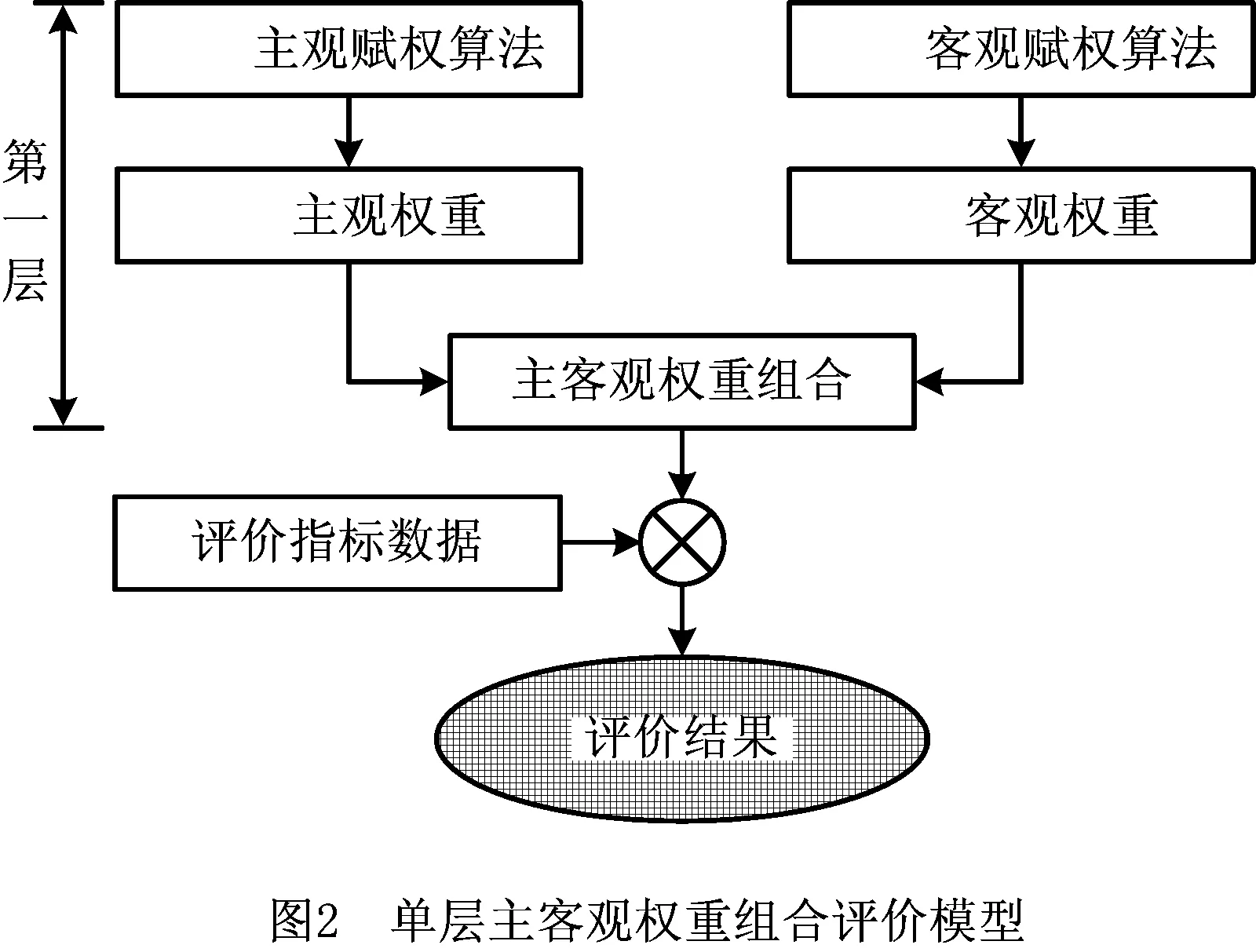
1)单层主客观权重组合评价模型。单层指该类模型仅进行一次主客观权重组合,即直接将单个主观赋权算法与单个客观赋权算法进行组合,如图2所示为该模型的主要结构,利用主观赋权算法和客观赋权算法分别求解主观权重和客观权重,而后通过主客观组合权重实现对指标数据的评价。如文献[15]利用层次分析法作为主观赋权算法、变异系数法作为客观赋权算法,利用权重平衡模型对主客观权重进行组合赋权;文献[21]利用层次分析法作为主观赋权算法、通过粗糙集确定各个指标客观权重,再将权重结合起来对目标进行评价;文献[22]利用层次分析法作为主观赋权算法、主成分分析法作为客观赋权算法实现组合赋权。
2)双层主客观权重组合评价模型。双层模型主要包括两个层次,如图3所示,由第一层的主观权重组合和客观权重组合及第二层的主客观权重组合构成。双层模型较单层模型增加了主观权重组合和客观权重组合,利用第一层主观和客观部分的组合权重结果作为第二层的权重输入,由第二层实现主客观权重的组合。

文献[2]在第一层的主观组合维度中分别利用Delphi法和AHP两种算法,客观组合维度部分分别利用熵权法和Critic法两种算法,在第一和第二层中均利用最小化权重差异程度的目标函数实现权重的组合。文献[13]在第一层中主观组合维度部分分别利用对比排序法法、AHP和专家直接评分法3种算法,客观组合维度部分分别利用标准离差法、熵权法和Critic法3种算法,并分别利用算法平均数和几何平均数作为各层的权重组合值。
虽然主客观权重组合可以同时融合主观与客观两个维度的信息,但利用单层和双层主客观权重组合评价模型进行权重组合的方法却存在以下不足:首先,对主观权重和客观权重进行组合时,权重相乘法和最优化模型法等算法并不能实现主客观权重之间的权衡,经验因子法会增大主观意愿的影响等[15]。这些组合算法存在的不足将导致最终的组合权重偏向于主观或客观权重的一方,不能实现组合权重进行均衡融合的目的;其次,单层的主客观权重组合评价模型仅应用单一的主观或客观赋权算法,较双层模型而言其组合后的权重受赋权算法本身偏差的影响较大。
(2)基于分类模型的评价模型分析
基于分类模型进行评价已经成为一种重要的评价方法,但将分类模型应用于评价问题时需要解决训练数据集的标注和提升模型泛化性两个问题:
1)训练数据集标注。通过对文献的分析可以发现,分类模型使用的训练数据来源于专家标注和基于赋权算法计算所得的评价结果,利用专家标注进行模型训练易受标注专家主观偏好影响,利用赋权算法的计算结果训练模型存在同样的问题,由此引起的训练数据偏差将导致分类模型的分类偏差。
2)提升分类模型的泛化性。模型从训练数据集中学习数据规律,挖掘分类知识,但评价数据会随时间发生变化造成基于有限数据学习的知识成为一种近似知识,因此使用当前训练数据集进行知识挖掘存在不稳定性,而通过提升分类模型的泛化性可以缓解这类问题。
3 融合组合赋权与嵌套集成分类器的服务商评价的总体方案
3.1 服务商评价指标体系构建
设计科学、合理、可靠的评价指标体系是进行服务商业务协同能力评价的基础,本文主要考虑面向汽车制造企业构建服务商业务协同能力评价指标,实现制造企业对售后服务业务管控和优化的目的,该指标体系内容主要涵盖以下两个方面:
(1)服务业务协同能力评价指标
从汽车制造企业对服务商业务活动管控的实际需求出发,针对保养、索赔、外出救援、重大质量问题等三包期内售后服务业务进行分析得出关键指标类别,如表1所示。

表1 服务业务协同能力评价指标类别说明

续表1
(2)维修业务评价指标
针对服务商维修质量,设计维修合格率和配件满足率两个指标,其中维修合格率指标反映服务商维修质量的合格率,配件满足率指标反映该服务商能否用原厂配件及时响应客户的维修需求,不会因为缺件导致客户维修受阻。通过这两个指标反映服务商能否高效保质地响应客户维修需求。
在文献研究、企业调研及专家咨询的基础上,从以上两方面出发,本文提出了服务商业务协同能力评价指标体系,该指标体系分为目标层、一级指标层和二级指标层,如图4所示。
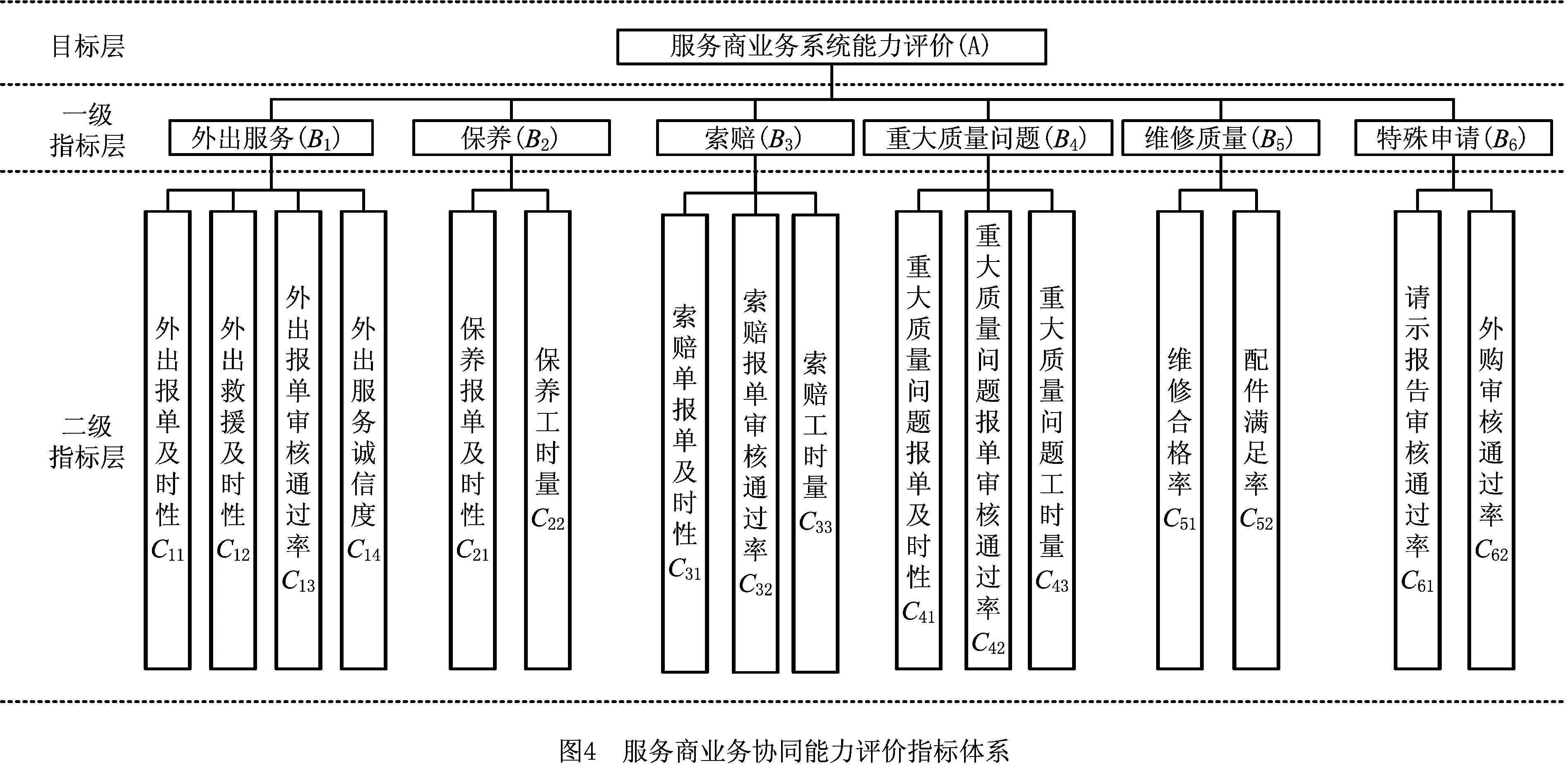
定义1A表示目标层,Bi表示一级指标层中第i个指标,Cij表示第i个一级指标下的第j个二级指标。
3.2 融合组合赋权与嵌套集成分类器的服务商评价模型
主客观权重组合的目的是通过主观与客观的融合实现两种权重的相互约束,形成一种均衡的权重,但由于当前组合算法存在的不足,导致组合后的权重会偏向主观或客观权重,因此针对单层和双层评价模型中主客观权重组合存在的不足,引入融合组合赋权与嵌套集成分类器的服务商评价模型,从两个阶段完成对目标的精确评价,其两阶段的总体架构如图5所示。
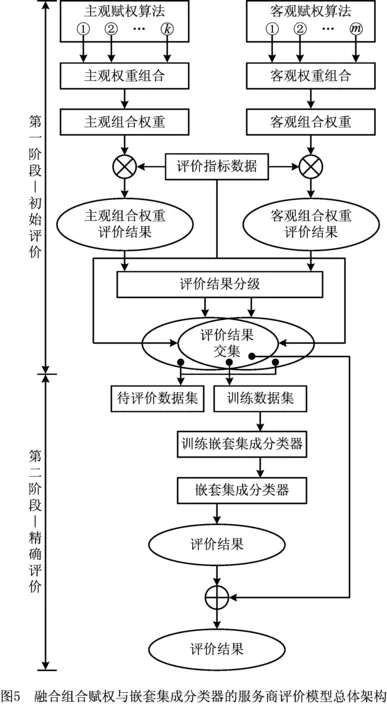
(1)第一阶段。本阶段不通过权重组合这种更为微观的方式进行主客观融合,而是从更为宏观的评价结果层面进行融合,通过一种更为松弛的约束方式实现对目标的初始评价及部分客观数据的精确标注,完成对服务商的初始评价。
通过双层主客观权重组合评价模型中第一层取得主观组合权重和客观组合权重,但并不进入第二层进行主客观权重组合计算,而是通过评价指标数据进行评价结果计算,对评价结果进行集合运算取得确定性的相同评价结果(交集部分)和不确定性的相异评价结果(对称差集部分)形成初始评价结果,此时处于相同评价结果集中的评价指标数据规律与人为主观认识基本一致,即交集中评价结果所对应的数据是融合了人为经验和客观数据规律的共性知识,而相异评价结果则表示评价数据与主观认识之间存在偏差。
(2)第二阶段。基于第一阶段形成的确定性的评价结果(交集部分)形成标注数据,将泛化性能更高的集成分类模型融入该阶段,通过集成分类模型对标注数据的学习形成融合人为经验和客观数据规律的共性知识,利用其对第一阶段中不确定性评价结果(对称差集部分)进行精确评价,实现对服务商的评价。
以相同评价结果(交集)形成的标注数据构建第二阶段的嵌套集成分类器,本文提出的嵌套集成分类器在深度和广度两个维度同时扩展实现集成,融入更为多样性的基分类器以提升集成分类器的泛化性。同时将存在相异评价结果所对应的评价数据作为第二阶段的待评价数据。利用融合主客观知识和较强泛化性能的嵌套集成分类器对相异评价数据进行分类,权衡偏差评价,实现精确评价。
本文提出岭回归的集成分类决策算法对嵌套集成分类器的基分类决策进行集成,通过赋予高性能基分类器的分类结果以较大权重来提升嵌套集成分类器的性能,实现对嵌套集成分类器的分类决策集成。
4 融合组合赋权与嵌套集成分类器的服务商评价模型
4.1 基于极大熵组合赋权算法的一阶段初始评价
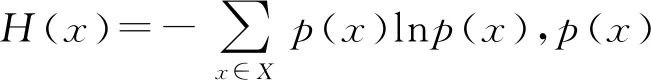
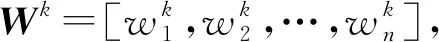
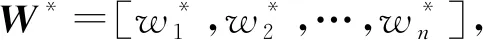
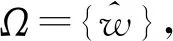

依据最大熵原理,在给定约束下选择不确定性最大的概率分布为权向量的系数,建立如下最大化模型:
(1)
式中m种权重计算算法会产生m种不同的随机权向量,组合权重值与这m种随机权向量越近似,则组合权重值越接近真实权重值,文献[23]利用相对熵来度量组合权重值与这m种随机权向量的符合程度(离散分布相对熵计算如定义5所示),当进行组合权重计算时,若m种权重计算算法所产生的m种不同的随机权向量有最优一致性,利用最小化组合权重和m种不同随机权向量的相对熵实现。
(2)
将式(1)和式(2)两个目标函数转化为单目标优化函数:
(3)
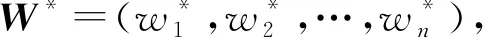
由于此时两组评价值处于不同的度量空间,导致两组结果不能直接进行比较,通过对两组评价结果进行分级划分,统一度量评价结果,结合汽车制造企业的需求及评价数据规律,对评价结果进行分级划分。在文献[6,11,17]通过主观设置分段值的方式对服务商等级划分存在一定的主观偏差,文献[4]运用系统聚类方法并结合定量评分结果计算售后服务质量等级,但系统聚类的聚类个数仍是主观设置,并未兼顾考虑评价数据本身的特性。基于K-means结合轮廓系数探索评价数据是一种自动确定聚类数目的有效方法,如文献[24]中利用轮廓系数改进K均值聚类算法(K-means)为神经网络反向传播算法(Back Propagation, BP)构造分类数据集,有效提升了BP算法的计算精度。因此,本文基于轮廓系数和K-means算法(简称SC-KC算法)来确定服务商业务协同能力评价结果的分级数目,实现对服务商业务协同能力等级划分完成一阶段初始评价,其流程如图6所示,主要步骤如下:
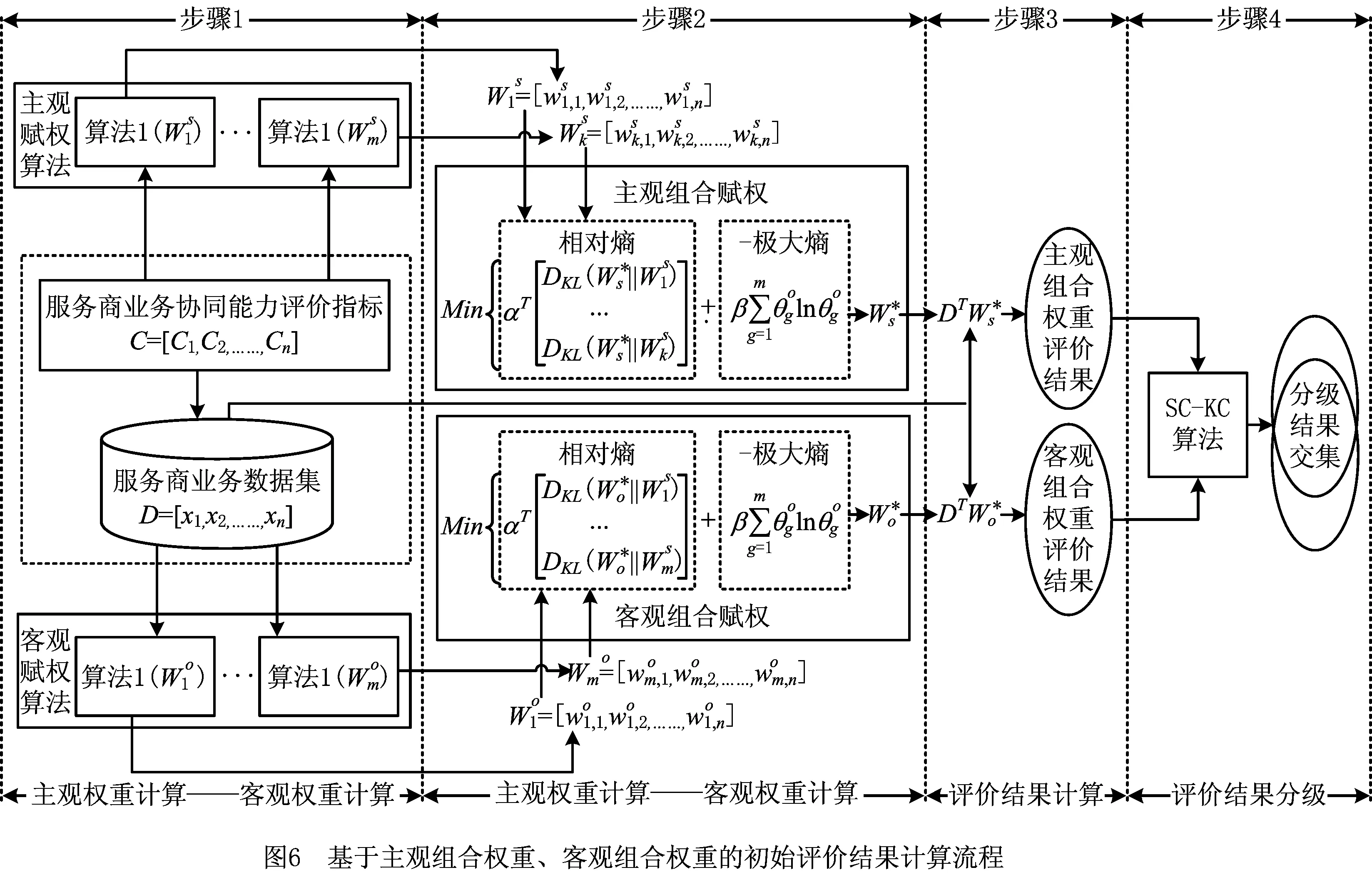



步骤4基于轮廓系数和K-means算法对服务商业务协同能力的主观评价结果和客观评价结果进行等级划分,将主观评价结果和客观评价结果划分到统一的CN个等级的度量空间内,对分级后的两组评价结果进行集合运算,所得交集为主客观相同分级评价结果,对称差集为相异评价结果,两集合构成服务商初始评价结果。
4.2 嵌套集成分类器
集成分类器通过将多个基分类器的分类结果按照一定规则进行集成,形成最终分类结果,将互补且精确的基分类器进行集成分类,其分类性能将优于单个基分类器性能[25]。目前,集成分类器在诸多领域[26-30]得到有效应用,但较少应用于服务商评价,本文通过融合组合权重算法对集成分类器在评价问题的应用展开研究。
集成分类器有较好的泛化性和抗噪性,在泛化性方面,多个多样性的基分类器(分类正确率>50%)集成为强分类器实现降低分类器过拟合的目的;在抗噪性方面,通过对多个分类器进行集成可以降低分类器的方差和分类结果对分类器性能的扰动,从而提升分类器抗噪性[31]。此外,集成分类器在针对不平衡数据分类的研究方面取得了极大关注,它通过从数据集、数据特征和算法角度构建包含多样性基分类器的集成分类器提升对不平衡数据分类的正确率。
4.2.1 构建基于特征选择的基分类器
基分类器是构成集成分类器的基本单元,基分类器的多样化是影响集成分类器泛化性能的重要因素[25],基于特征选择产生特征子集是构建多样化基分类器的重要方法[32],特征选择是基于某种选择准则,从数据特征集中选择最小特征子集的方法,通过特征选择可以提升分类器的分类性能[33]。按照选择准则是否与分类器相关,特征选择方法分为过滤式、封装式和嵌入式[32-34],本文运用封装式方法进行特征选择,通过与分类器结合及以分类正确率等指标为准则,选择出分类正确率较高的特征子集。
特征子集的选择一般被视为多目标优化问题,多目标优化问题的一般描述为[35]:
miny=F(x)=(f1(x),f2(x),…,fm(x))T,
s.t.
gi(x)≤0,i=1,2,…,q,
hj(x)=0,j=1,2,…,p。
(4)
其中:x=[x1,x2,…,xn]∈X,X⊂Rn为n维决策向量,X为n维决策空间,y=[y1,y2,…,ym]∈Y⊂Rn为m维目标空间,gi(x)≤0定义了q个不等式约束,hi(x)≤0定义了p个等式约束。
近年来,基于多目标的进化算法被应用于特征子集的选择中,其中带精英策略的快速非支配排序遗传算法(fast elitist Nondominated Sorting Genetic Algorithm, NSGAⅡ)[36]作为一种典型的多目标的进化算法被大量应用到此任务中,通过NSGAⅡ算法求得一组非支配解作为各基分类器的训练数据特征,以训练多样化的基分类器提升分类器的泛化能力。如文献[37]利用NSGAⅡ算法同时优化3个度量目标,对不平衡数据进行特征选择,文献[38]利用改进NSGAⅡ算法选择多种大小不同的局部特征子集实现对全局非支配特征子集的选择等都对改善分类器性能起到了积极作用。本文基于封装式特征选择方法结合NSGAⅡ算法,设定最小化分类性能指标f1和特征数目f2两个目标函数为适应度函数构建特征子集。
miny=
(5)

4.2.2 构建嵌套集成分类器
本文设计了一种嵌套集成分类器模型,该模型分为内外两层次,内层包含多组多样化的基分类器,基于该层基分类器通过逐层有效地集成分类决策形成嵌套集成分类器,下面将从模型结构和分类决策集成两个方面进行说明。
(1)嵌套集成分离器结构
嵌套集成分类器是一种集成分类器,当前典型的集成分类器框架主要包括Boosting、Bagging和Stacking三类。其中:Boosting串行生成一组互相依赖的基分类器,关注于通过提升基分类器的正确率实现提升集成分类性能目的,如Adaboost、梯度提升树算法;Bagging并行生成一组相对独立的基分类器,关注于通过提升基分类器的多样性来达到提升集成分类性能的目的[20],如随机森林算法;Stacking通过训练元模型将一组基分类器的分类结果进行组合实现集成多个基分类器的分类。
嵌套集成分类器的结构如图7所示,通过在内层构造多组多样化的子集成分类器形成外层集成分类器的基分类器,再经外层的集成分类器进行分类决策的集成,进而实现多组基分类器在广度上的分类组合,在深度上的分类决策集成,实现两个维度的同时延伸。嵌套集成分类器较Bagging和Stacking算法不仅实现了对多样性基分类器的集成,还对模型深度进行扩展,实现对更高层维度数据特征的提取,通过广度扩展增加了基分类器的多样性,保证了集成分类器的泛化能力,深度扩展提升了模型对数据特征的提取能力,从这两个维度提升了分类性能。

(2)基于岭回归的分类决策集成算法
基分类器的分类决策集成性能将影响集成分类器的性能,文献[39-41]研究了5种常用集成分类决策算法,通过对各个基分类器的分类结果进行取最大值、投票和求和等方法进行集成,但这些算法未能对各集成分类器结果进行差异化区分以识别出高性能分类器的分类结果。本文通过基于岭回归的分类决策集成算法对重要分类结果特征进行识别,并赋予高性能分类器的结果以较高权重以提升嵌套集成分类的分类性能。
定义7设数据集D中各样本对应类分布为P=[p1,p2,…,pn]T,其中pi=[p(i,1),p(i,2),…,p(i,m)]T为某样本xi对应的类分布,Pl=[p(1,l),p(2,l),…,p(n,l)]T为数据集D中样本对应类l的分布。

运用岭回归计算子集成分类器中各基分类器的预测类分布与真实类分布的误差,利用权重解析解计算各分类器的类分布预测权重,设子集成分类器ec对l类的分类决策目标函数为:
(6)
其解析解为:
(7)
其中式(7)为k个基分类器对l类的分类决策权重向量。嵌套集成分类器的外层分类决策集成与子集成分类器的集成算法相同,将多个子集成分类器视为嵌套集成分类器的基分类器,运用式(7)计算外层嵌套集成分类器的分类决策集成权重。
(3)嵌套集成分类器构建流程
嵌套集成分类器的构建包括训练和测试两个阶段,训练阶段主要包括:训练数据集分割、特征选择、各内层子集成分类器训练、集成分类决策4个步骤,其中集成分类决策又包括内层子集成分类器的集成决策和外层集成分类器的集成决策;测试阶段主要包括:测试数据集分割、各内层子集成分类器测试数据的生成、测试各内层子集成分类器及集成分类决策、测试嵌套集成分类器及集成分类决策4个步骤,其构建详细流程如图8所示。

5 应用实例分析
5.1 服务商业务协同能力数据集
本文以汽车产业链云服务平台[42]上CQ汽车制造企业及其与之进行服务业务协同的300多家服务商的服务业务数据为基础,对服务商业务协同能力评价模型进行实验验证。
汽车产业链云服务平台支撑CQ与其服务商开展售后服务业务协同,累积了多年服务业务数据,包括售后保养数据、售后索赔数据、售后配件数据、售后旧件数据等。基于对服务商业务协同评价指标研究,从平台服务业务数据库中抽取所需评价数据,通过数据预处理构建服务数据集作为评价数据源,预处理后形成服务业务数据集,其部分数据集如表2所示。
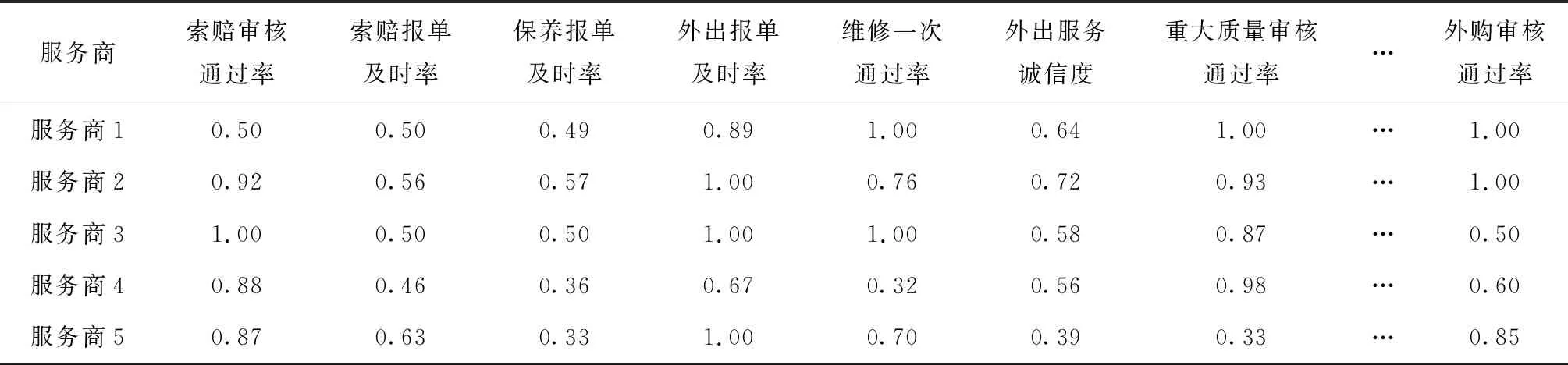
表2 服务业务数据集
5.2 基于主观组合权重与客观组合权重的一阶段初始评价计算
5.2.1 主观组合权重计算
本实验利用Delphi算法、AHP算法作为主观组合赋权的基础算法。
(1)Delphi算法计算评价指标权重
选择多位来自汽车制造企业服务部门和服务管理专家对服务商业务协同能力评价指标项的全局相对重要性进行评分,单指标项评分值越高,其相应权重值就越高,对各个专家的评分结果进行汇总,计算出各专家的评分结果得出各评价指标项的权重,如表3所示。

表3 Delphi算法评价指标权重值
(2)AHP算法计算评价指标权重
AHP算法权重计算依然基于专家的知识对各个指标项权重进行计算,具体步骤如下所示。
步骤1建立服务商业务协同能力评价层次模型,将服务商协同能力评价指标中各项指标划分为相互联系的有序层次,形成一级和二级指标体系(如表4),其中各个指标均为正向指标。

表4 服务商业务协同能力评价层次模型
步骤2采用1~9标度,依据各指标间的相对重要程度,计算指标体系中的一级指标权重,权重值如表5所示。

表5 AHP服务商业务协同能力评价层次模型一级指标权重
步骤3在各一级指标下,基于各二级指标间的相对重要程度,计算一级/二级指标权重,权重值如表6所示。

表6 AHP服务商业务协同能力评价层次模型一级/二级指标权重
步骤4基于步骤2和步骤3中所计算的各个指标权重计算出最终各二级指标的权重,形成的评价指标权重值如表7所示。

表7 AHP算法评价指标权重值
(3)主观组合权重计算
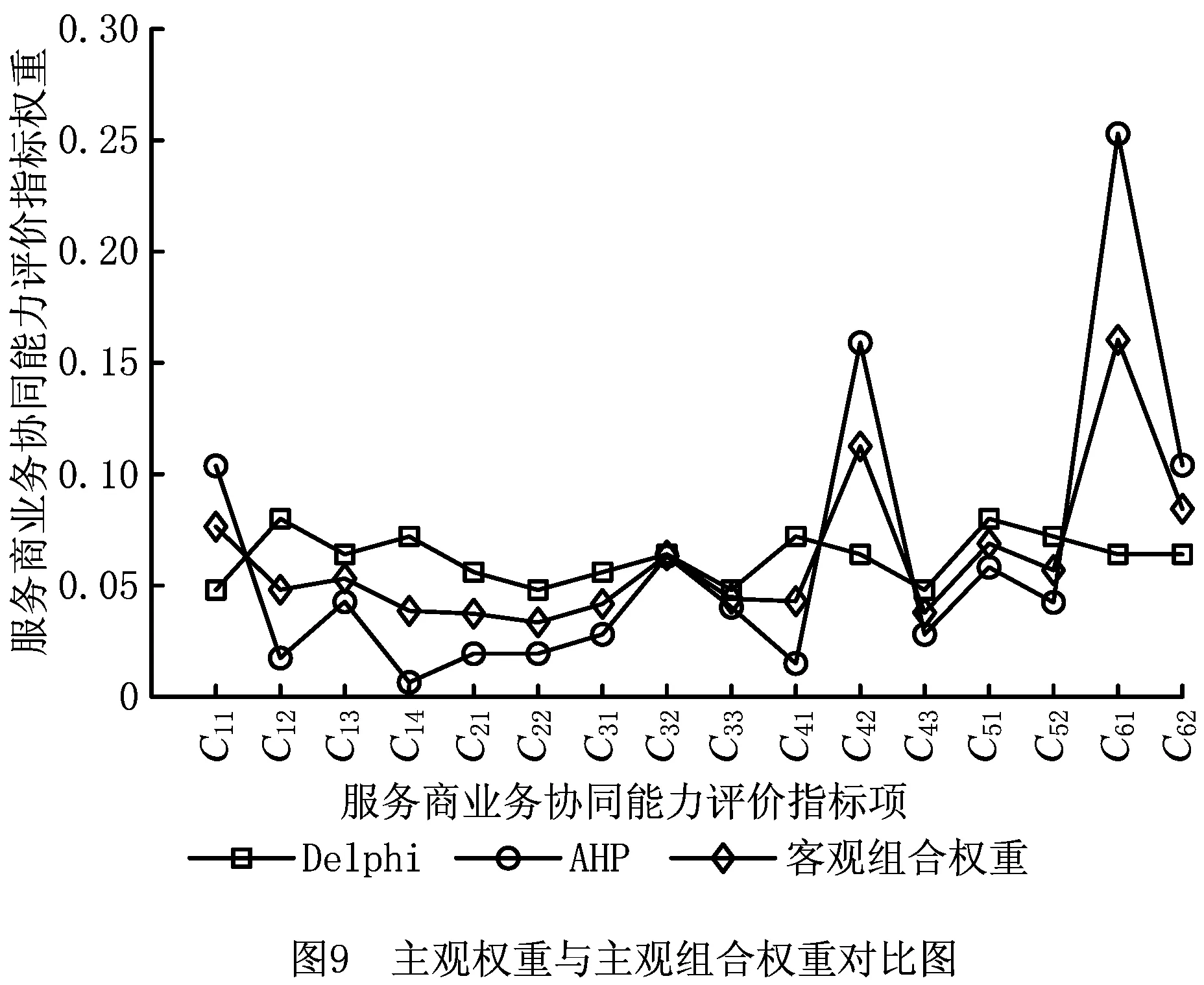
基于Delphi和AHP计算主观指标权重,利用式(3)中的目标函数计算主观组合权重,所得主观组合权重数值如表8所示,所得两种主观权重与主观组合权重对比如图9所示。

表8 主观评价组合权重值
5.2.2 客观组合权重计算
本实验利用Critic算法、PCA赋权算法和熵权法作为客观组合赋权的基础算法。
(1)Critic算法计算评价指标权重
基于服务商业务协同能力评价指标相关性来确定属性权重,分析指标数据间的对比强度和冲突性,基于此求得各个评价指标的权重,权重值如表9所示。
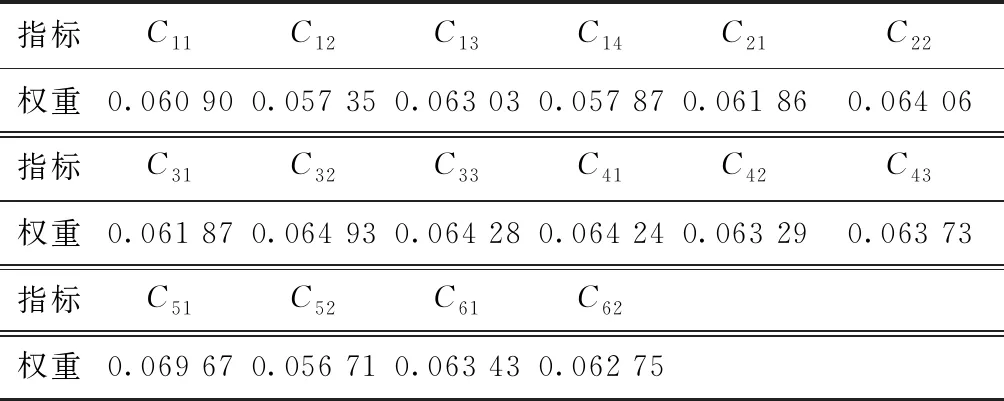
表9 Critic算法评价指标权重值
(2)PCA赋权算法计算评价指标权重
通过线性变换消除服务商业务协同能力各指标项间的信息冗余问题,将原指标变量经过PCA变换后形成n(主成分个数参数)个互相独立的主成分,进而计算服务商业务协同能力评价权重,权重值如表10所示。

表10 PCA算法评价指标权重值
(3)熵权法计算评价指标权重
针对服务商业务协同能力的各项评价指标,计算某项指标对于评价对象的特征比重和熵值,形成评价指标的熵权,求得各个评价指标的权重,权重值如表11所示。
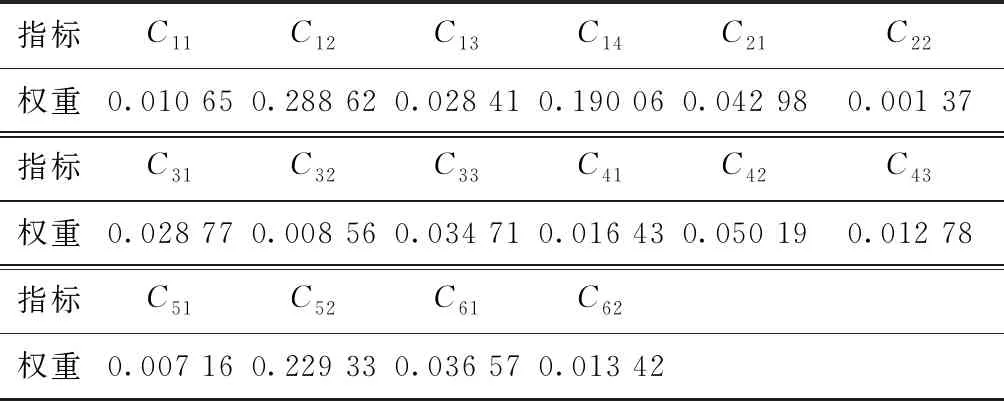
表11 熵权法算法评价指标权重值
(4)客观组合权重计算
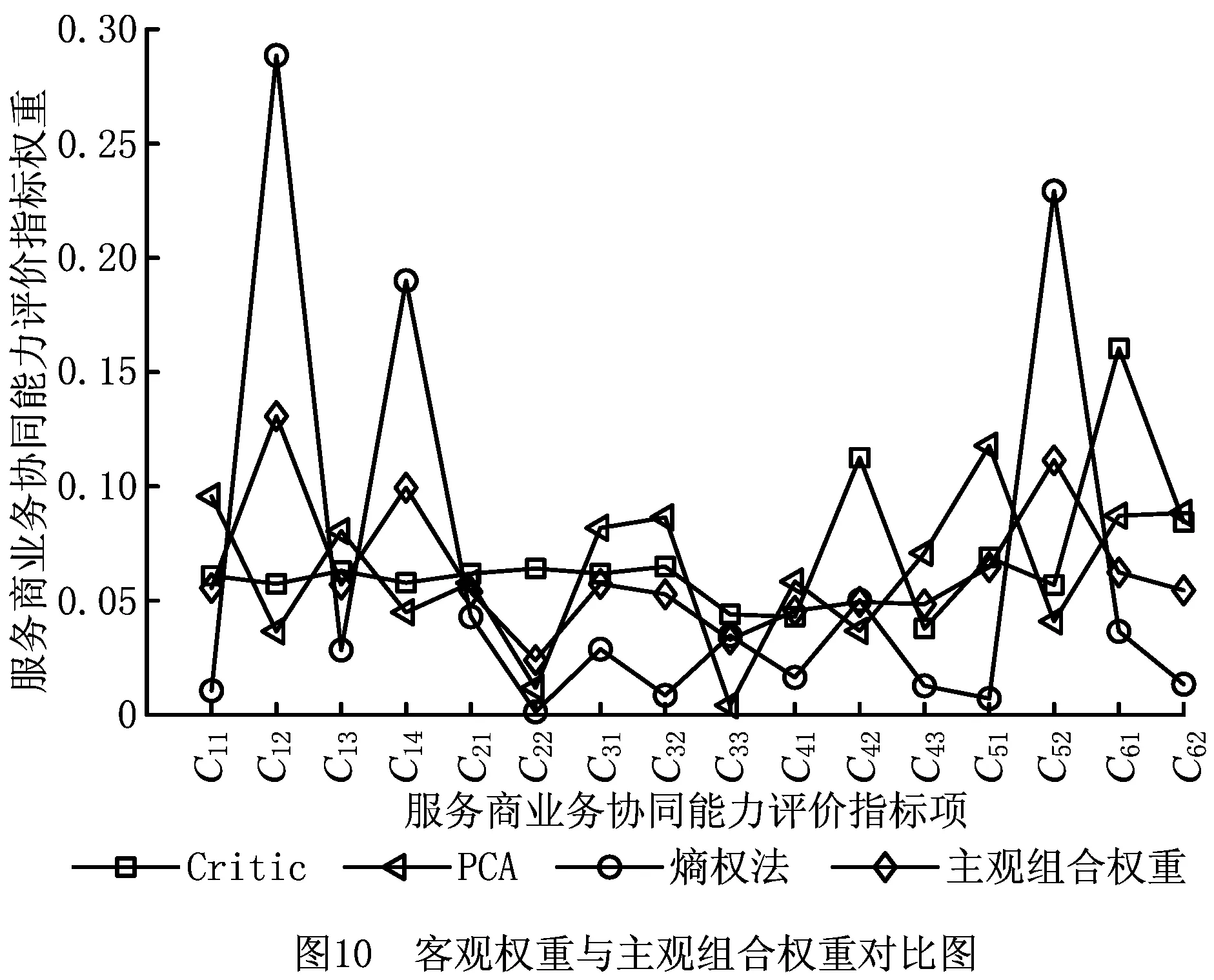
基于Critic赋权算法、PCA赋权算法和熵权法计算客观指标权重,利用式(3)中的目标函数计算客观组合权重,所得客观组合权重数值如表12所示,所得3种客观权重与客观组合权重对比如图10所示。

表12 客观组合权重评价指标权重值
5.2.3 评价结果等级划分
基于主观组合权重和客观组合权重对服务业务数据集中各个服务商业务协同指标数据进行计算可以得到主观、客观两组评价结果,从图11中可以分析出主观组合权重与客观组合权重在某些具体指标值权重上存在较大差异,两组权重的差异性将导致评价结果的差异,通过对评价结果进行等级划分在统一的度量空间下对主观及客观组合权重的评价结果进行融合,该融合过程包括以下两步:

步骤1基于主观组合权重和客观组合权重计算出主观和客观两组评价结果(如图12),通过分析可以发现,主观组合权重计算的评价结果值总体大于主观组合权重评价结果,但主观组合权重与客观组合权重评价结果的相对趋势有较高重合度。

步骤2基于K-Means算法和轮廓系数对步骤1中所得主观组合权重与客观组合权重评价结果进行等级划分,不同聚类个数代表着不同的分类等级,如当聚类个数为n时,意味着将评价结果划分为n个等级,依据各个聚簇中心值大小确定等级顺序。如图13是不同聚类个数下主观组合权重与客观组合权重评价结果的分级轮廓系数值,对于主观评价结果其轮廓系数在聚类个数为2和3时数值较大,对于客观评价结果其轮廓系数在聚类个数为3和4时轮廓较大,结合制造企业对评价等级划分的需求,将评价等级定为3个等级。
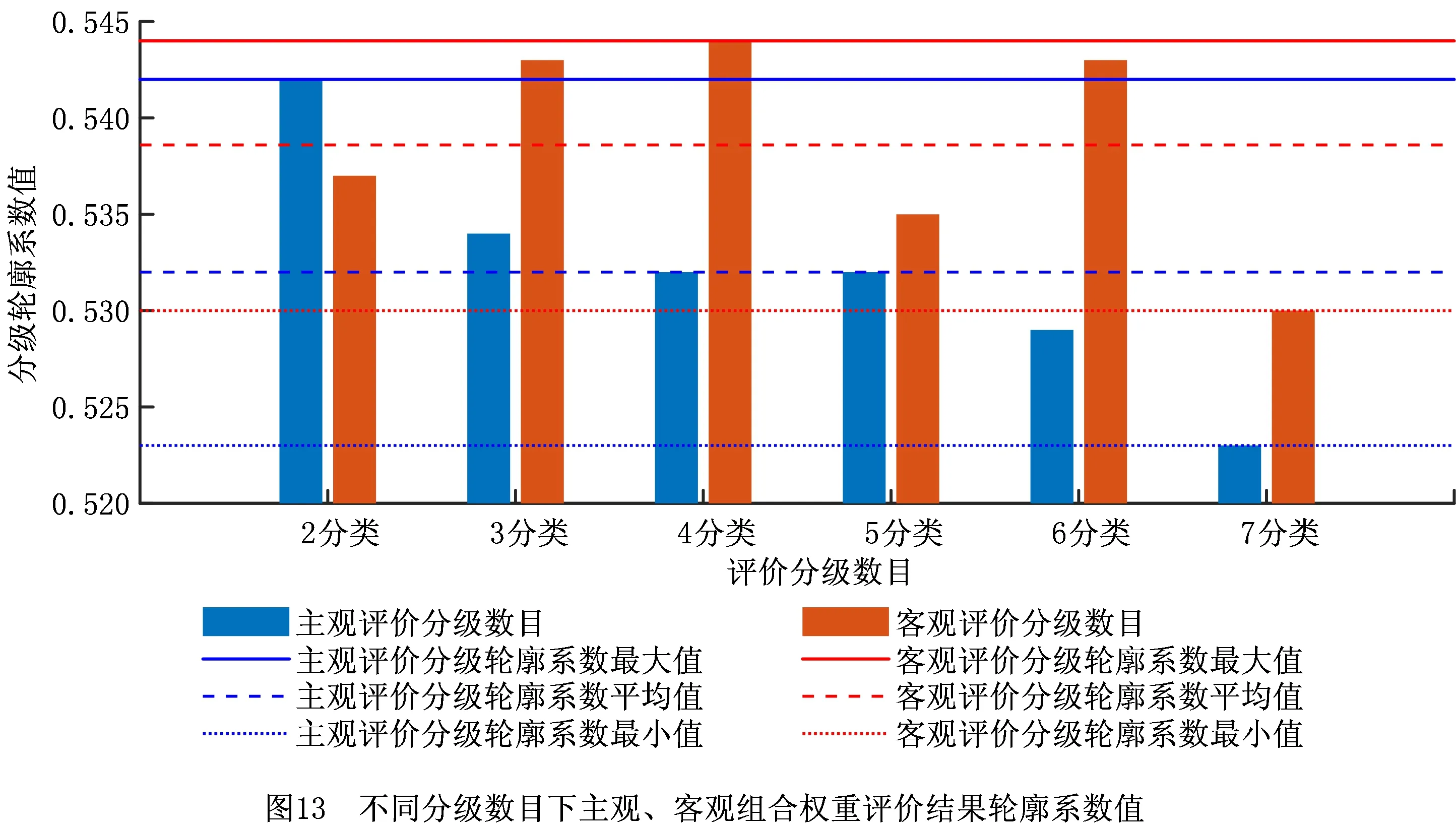
将由权重计算所得的评价结果数据依据其数值的相对大小映射到A级、B级和C级3个等级空间中,其中A级为最高等级,B级为中间等级,C级为最低等级,从分类结果中随机抽取150家服务商进行分析,如图14所示。分析发现,主客观组合权重两种算法对多数企业具有相同的评价结果,但存在一定数量的相异评价结果,这些相异评价结果将在第二阶段中进行精确分类。
5.3 基于岭回归集成分类决策算法的嵌套集成分类器测试
选择K最近邻算法(K-Nearest Neighbor,KNN)、支持向量机算法(Support Vector Machine,SVM)和逻辑斯特回归算法(Logistic Regression,LR)三种常用分类算法分别作为内层子集成分类器的基分类器,构建ne1、ne2、ne3三个内层子集成分类器,分别运用岭回归集成分类决策算法集成各组基分类器的分类结果形成内层分类决策。利用ne1、ne2、ne3组成外层集成分类器构建嵌套分类器ne,运用岭回归集成分类决策算法集成ne1、ne2、ne3分类结果形成嵌套集成分类的最终分类结果。
5.3.1 算法测试数据集
由于服务商业务协同能力评价可视为多分类问题且服务商的优秀等级和不合格等级占整体数量较少,导致数据存在一定程度的不平衡性,基于以上两个特点,为检测基于岭回归集成分类决策算法的嵌套集成分类器在此类型分类数据上的性能,实验选取来自UCI Machine Learning Repository(UCI数据集)中10个以多分类和不平衡数据集为主的数据集(如表13)用于测试算法性能。

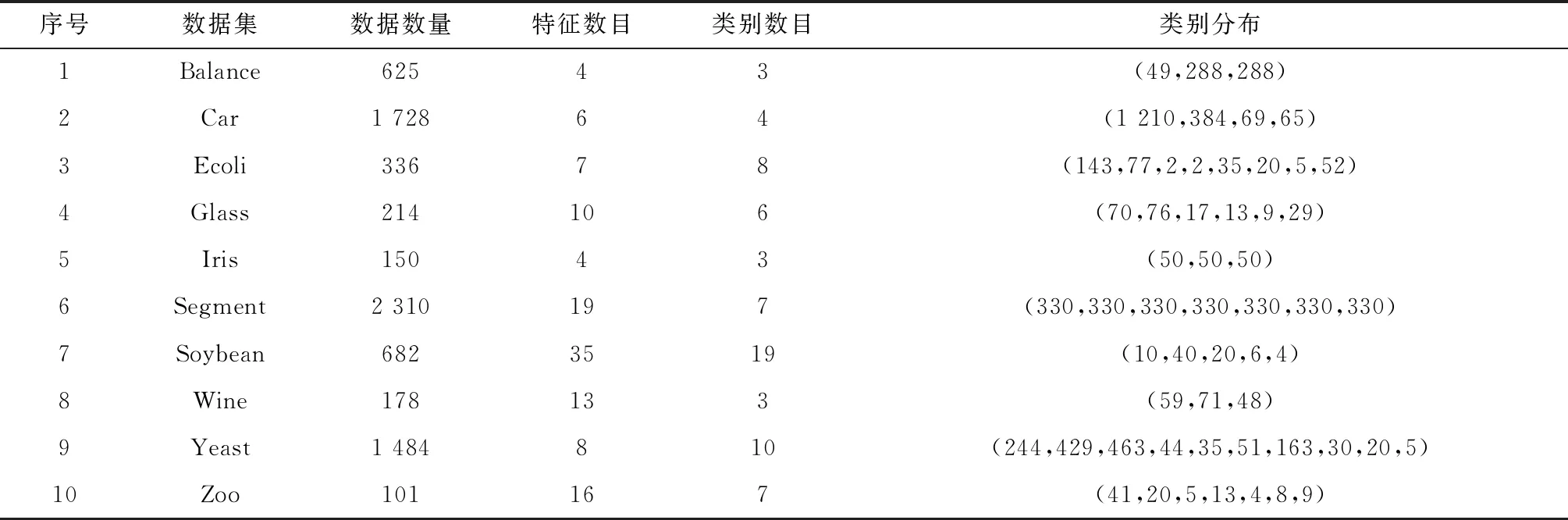
表13 算法性能对比测试所用实验数据
5.3.2 算法性能测试分析
针对本文的多分类问题,在实验部分利用所有类别中分类正确的样本数占总样本数的百分比来计算正确率,通过计算各类F1值的平均值作为分类的F1值,其中F1值为精准率和召回率的调和平均数是对精准率和召回率的综合考虑。
对基于岭回归集成分类决策算法的嵌套集成分类器(简称RREC)进行性能测试(测试结果如表14所示),与当前主要集成分类算法(包括:梯度提升树(Gradient Boosting Tree, GBT)、随机森林(Random Forest, RF)、自适应增强算法(简称SAMME)、堆叠集成分类器(Stacking Classifier, SC))进行性能对比。针对每个测试数据集,各算法运行30次求出平均正确率和F1值展开对比。
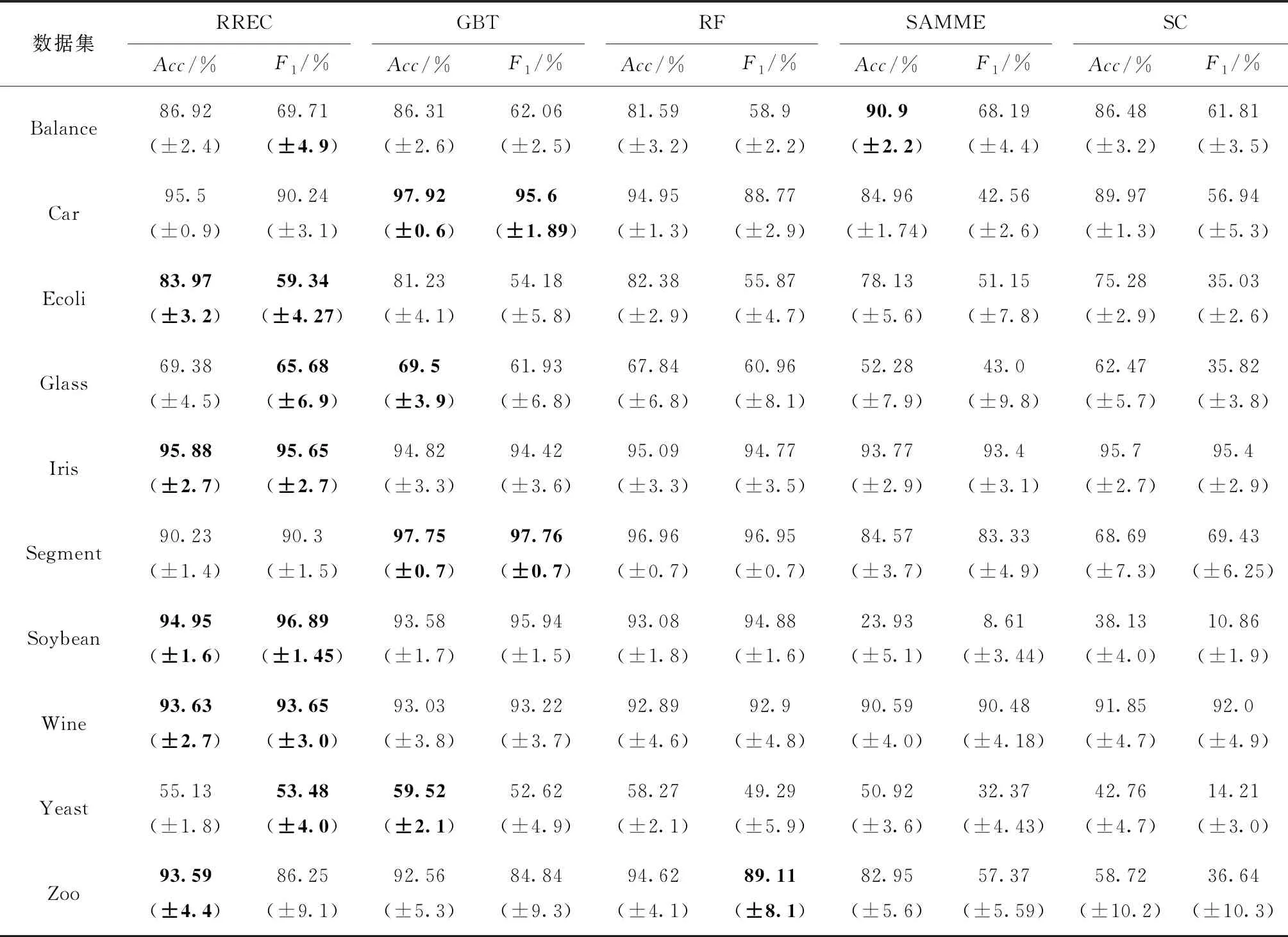
表14 算法性能测试结果
通过对算法性能测试结果进行分析可以发现RREC算法的正确率和F1值较其他对比算法有最优或较优值,说明RREC算法在正确率(Acc)和F1值指标度量下可以取得整体优势,尤其在较少类别的不平衡数据集,如Balance、Soybean、Glass等数据集中。
RREC算法运用了岭回归集成分类决策算法计算最终的分类结果,如表15所示为5种常用的分类决策集成算法,将这5种常用算法作为嵌套集成分类器的集成分类决策算法与岭回归集成分类决策算法进行性能测试对比,测试指标为分类正确率和F1值。

表15 集成分类决策算法
针对每个测试数据集,各算法分别运行30次求出平均正确率和F1值并进行对比。实验测试结果如表16所示,对算法性能测试结果进行分析可以发现在80%的测试数据集上,岭回归集成分类决策算法的正确率和F1值较其他集成分类决策算法取得了最优值。

表16 集成分类决策算法测试结果
5.4 基于嵌套集成分类器的二阶段精确评价计算
5.4.1 面向服务商业务协同能力评价的嵌套集成分类器构建
利用主观组合权重与客观组合权重对服务商业务协同能力进行评价,形成初始评价后,利用相同评价结果所对应的评价指标数据集作为训练和测试数据构建嵌套集成分类器,构建流程如图8所示。利用训练后的嵌套集成分类器对服务商业务协同能力评价进行测试,与梯度提升树、随机森林、Adaboost、堆叠集成分类器进行性能对比,表17展示了各算法的评价测试结果,通过对结果分析可以看出RREC算法较其他算法在Acc和F1值两个指标上均取得了最优值,这与表14中对UCI数据集的测试结果相吻合。

表17 服务商业务协同能力评价测试结果
5.4.2 嵌套集成分类器对服务商业务协同能力的精确评价
利用嵌套集成分类器对初始评价中相异评价结果进行精确评价是构建嵌套集成分类器的目的,将不确定的相异评价结果集作为嵌套集成分类器的输入实现对服务商业务协同能力的最终评价,如图15所示为嵌套集成分类器的精确评价结果与主观组合权重和客观组合权重分级的部分服务商评价结果对比,经过对比分析发现,嵌套集成分类器与主观组合权重或客观组合权重的评价结果之一相匹配,没有生成第3种评价结果,可以实现对不确定评价结果的精确评价。

6 结束语
服务商业务协同能力评价是制造企业进行服务价值链管控的重要手段,在服务价值链优化方面发挥着重要作用。本文面向制造企业对服务价值链管控的实际需求,研究并设计了服务商业务协同能力评价指标体系,分析当前主客观权重组合模型中存在的不足,提出了融合组合赋权与嵌套集成分类器的评价模型。
基于该模型通过初始-精确两个阶段完成对服务商业务协同能力的评价,在初始评价阶段中,结合多种主客观赋权算法模型,利用基于极大熵组合赋权算法实现对服务商业务协同能力的一阶段初始评价。在精确评价阶段中,针对一阶段初始评价中的不确定性评价结果,构建基于岭回归集成分类决策算法的嵌套集成分类器模型,嵌套集成分类器通过在广度和深度两个维度进行扩展,保证了分类器的泛化能力和特征提取能力,并利用岭回归集成分类决策算法实现对分类决策的集成,形成对服务商业务协同能力的精确评价结果。通过开展与同类模型的对比实验,表明本文模型在服务商业务协同能力评价应用方面具有较为突出的性能。
目前,本文所提出的嵌套集成分类器训练过程较为复杂,尤其在运用特征选择算法构建差异化训练数据集的过程中,其时间复杂度仍然较高。如何实现模型在进行特征选择过程的同时,完成多样化基分类器的构建以降低时间复杂度,进而提升模型训练的整体速度将成为下一阶段的研究重点。
猜你喜欢
军民两用技术与产品(2022年3期)2022-06-05
中国西部(2022年2期)2022-05-23
民族文汇(2022年9期)2022-04-13
空军工程大学学报(2021年4期)2021-09-23
福建江夏学院学报(2021年6期)2021-08-10
南大法学(2021年6期)2021-04-19
活力(2019年15期)2019-09-25
电影文学(2017年24期)2017-11-16
金融经济(2017年7期)2017-07-15
中国期刊年鉴(2015年0期)2015-01-19
