
聚类问题中的算法
2021-01-11 08:43李晓明
中国信息技术教育 2021年1期
李晓明
本专栏上一期介绍的是分类问题中的算法,这一期讨论聚类。
“分类”指的是要将一个未知类别的对象归到某个已知类别中。“聚类”则是要将若干对象划分成几组,称每一组为一个类别。
在实际应用中,分类的类别是事先给定的,往往对应某种现实含义,如网购者可能分为“随性”和“理性”两个类别,人们大致也知道是什么意思。聚类则是本无类,只是根据对象之间的某种相似性(也称邻近程度或距离),将它们分组。例如,有两个任务要完成,于是需要将一群人分成两组,分别去完成一个任务,为了有较高的效率,希望组内成员之间关系较好,配合默契。聚类形成的类不一定有明显的外在特征,往往只是根据事先给定的目标类数(如有三个任务,就要分成三组),将对象集合进行合理划分。
所谓“合理”,在这里的原则就是尽量让同组的成员之间比较相似(距离较近),组间的成员之间距离较远(不相似)。一旦分类完成后,就可能会按照不同类的某些特征给它们分别命名。
与分类一样,为了聚类,对象之间的相似性(或距离)含义和定义是基础。在有些应用中,对象两两之间的相似性是直接给出的;在更多的应用中,相似性则要根据对象的特征属性按照一定的规则进行计算。下面我们讨论两个算法。
● 自底向上的分层聚类法
想象我们要搞城市群建设,需要规划将一些城市分成几个群,群内统筹协调发展。一共要分成几个群?哪些城市该放在同一个群里?这是很现实的问题。当然,做出这样的决定取决于许多因素,但其中一个重要因素就是城市间的空间距离。很难想象同一个群内的城市之间相距很远,而相距很近的两个城市却分到了不同群。
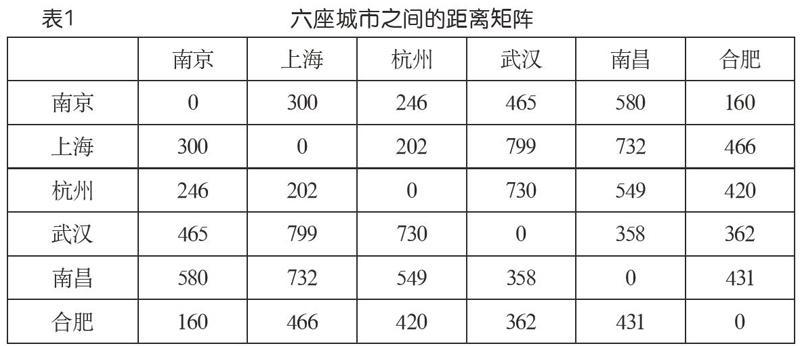
表1是六座城市之間的距离矩阵(在搜索引擎中查出来的数据,不一定很准,这里只是作为例子),如果我们想分成两个群,该如何分?分成三个呢?这就是聚类问题。我们注意到,在这种背景下,两个对象(城市)之间的相似性或邻近程度自然地以距离的方式给了出来。
1967年,Stephen Johnson发表了一个针对这种场景的算法,称为“分层聚类法”(hierarchical clustering)。基本思想如下(假设有n个对象,要聚成k类):
(1)初始,每一个对象看成是一个类,于是有n个类,类和类之间的距离由表1那样的矩阵数据给出。
(2)两两检查现有类之间的距离,挑出最小的,也就是表1数据中最小的(不算对角线元素,因为它们是“自己到自己”的距离)。将对应的两个类合并,具体就是将它们的数据“合并到”一行(列)上,删去另一行(列)。数据合并的策略有多种考量,其中一种是取对应两个数的较大值。(注意,现在类数少了一个,对应表1那种矩阵少了一行一列)
(3)如果已经是k类了,就结束;否则返回(2)。
我们以表1为例,初始6个类,考虑k=3,也就是要聚为3类,来模拟算法的运行。核心是算法的第(2)步。由于数据矩阵的对称性,观察的时候只需考虑上三角。为简单清楚起见,更新的时候则统一处理。
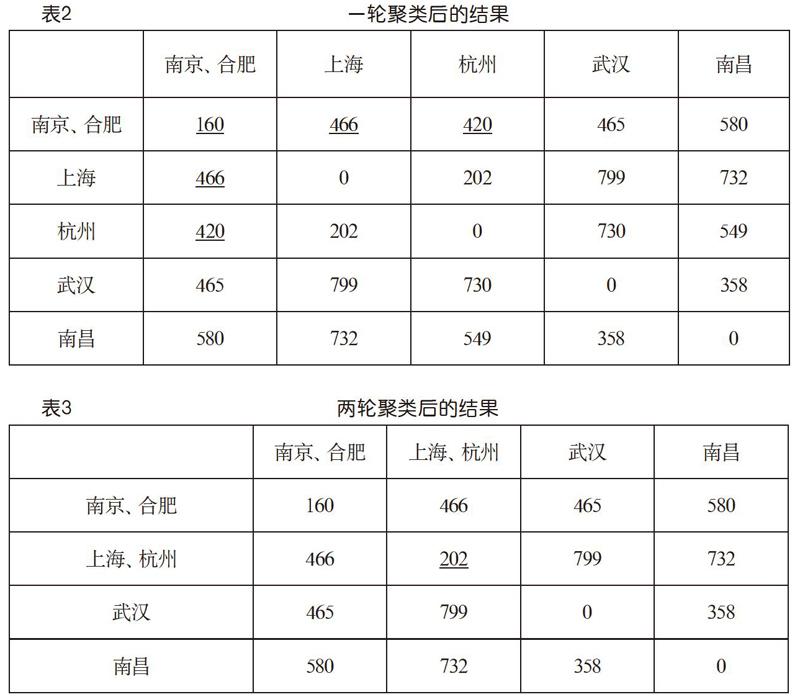
首先,看到表1上三角中最小的数是160,即南京和合肥之间的距离。它位于第1行第6列。按照算法,应该将南京与合肥聚成一类,同时合并它们的数据,对应矩阵数据的更新。我们取较大值方案,并让第6行(列)向第1行(列)合并,就得到表2所示的结果。发生了更新的数据由下画线标示。现在是5个类,比初始减少了一个。其中加下画线显示的数就是取较大值更新的结果。
继续,看到最小的数是202,上海与杭州之间的距离,位于第2行第3列。将它们合并为一类,并让第3行(列)向第2行(列)合并,就得到表3所示的结果。这一次,除了对角线上的数据外,第2行的其他数据恰好没有变化。现在就是4类了。
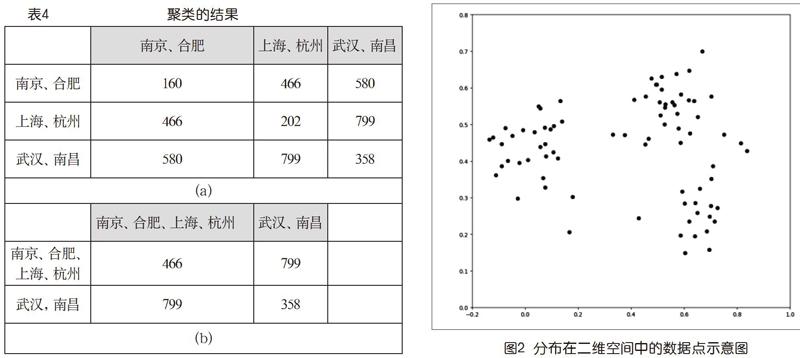
再来一轮,看到第3行第4列的358最小,让第4行(列)向第3行(列)合并,就得到下页表4(a)所示的结果。这就是聚成3类了,达到了预定目标。
若需要,还可以在这个基础上继续,得到聚为2类的结果如下页表4(b)所示。
如果能把这个例子跟踪下来,相信读者一定就掌握了这个算法的要领。
这个算法的聚类效果如何?看这个例子,似乎还不错。但要意识到,像许多机器学习算法一样,效果没有一个“金标准”度量,而是与数据集和应用目的有关。因而,这类算法常常包含一些启发式,用以根据具体情况斟酌采用。对S.C. Johnson算法而言,启发式的体现就在于算法第(2)步中的数据合并策略。我们例子中用的是“较大值”,其他策略还有“较小值”“平均值”等。建议读者思考体会这几种策略的“物理意义”,从而在应用中可以有针对性地选用。
这个算法的时间效率如何?如果任务是要把n个对象聚成k类,每一轮找到最小的数是主要操作,总起来就是O((n-k)*n2)。
● K-means
下面讨论另一个聚类算法——K-means(K均值)算法,也是现在大数据聚类中比较流行的算法,其中的K是预先给定的要形成的类数。作为一个例子,考虑有若干数据点(不妨认为它们代表一些人的年龄),并将其放到数轴上,如下页图1所示。
设想要把它们分成4组,每一组内的人的年龄比较相近,以便谈话更有共同语言。怎么分合适呢?就这个例子而言,乍一看这个图,可能还真有点为难。头3个为一组,接着7个为一组,再接着6个为一组,后面4个为一组?还真不见得。
这个例子数据,每个数据点就一个值,称之为1维数据。而在实际中常见的是多维数据。例如,图2是一个二维数据点集的情形。如果要把它们聚成2类,似乎有很直观的结果,3类也行,4类就不太好说了。读者还可以想到,如果数据的维数>2,情况会变得更加复杂①,而且不太可能有视觉直观。
无论数据的维度如何,如前所述,数据之间的距离都是聚类算法的基础。在前面讨论分层聚类法的例子中,我们直接用城市间的空间距离作为距离。在本专栏上一期讨论分类的时候,我们谈到了不同的应用背景有不同的距离、如欧式距离、曼哈顿距离,余弦距离等,此处不再赘述。
下面以二维为例进行算法讨论,其思想也可以用于多维。后面的运行例为简单起见,则采用上面的年龄数据(一维)。
1.问题
给定一个二维数据集合D={x,y,…}和希望聚成的类别数K,要将那些数据分成K组,使得每一组内的数据点较近,而组间数据点的距离较远。假设采用欧式距离。
稍为仔细一点读这个问题描述,会感到它只是表达了一个宏观的愿望,细节要求并没有说清楚。“较近”和“较远”的具体比较对象是什么呢?以图2为例,若聚成3类,无论怎么聚,不同类边界上两个点的距离都有可能比类中两个点的距离更近。那岂不是说这个问题没法解决?
为此,我们需要让那种宏观的愿望具有可操作性,明确“类中数据点较近”和“类间数据点较远”的具体含义。注意到由于有了距离的概念,我们就可以谈论一组数据的“中心”,如一维空间中两个数的中心就是它们的均值,二维空间中两个数据点的中心就是它们连线的中点,等等。而如果有多个中心,就可以谈论一个数据点离哪一个更近。K-means就是从初始给定的数据点集合出发,对K个不同中心的确定和数据点归属关系进行迭代,最终形成K个数据类别的算法。
2.算法思路
在K-means算法中,K表示类别数,means表示均值。意指聚类过程将数据集分成了K类,每一类中的数据点都离它们的中心(亦称质心)更近,离其他的中心较远。
“中心”,在本文的讨论中就是一个虚拟的数据点,其坐标为它所代表的数据集中数据点坐标的平均值。如果是两个点,如x=(1,2),y=(4,6),其中心就是((1+4)/2,(2+6)/2)=(2.5,4);如果是三个点,如x=(1,2),y=(4,6),z=(4,4),其中心就是((1+4+4)/3,(2+6+4)/3) =(3,4);等等。一般地,n個点,d1=(x1,y1),…,dn=(xn,yn),中心就是:
K-means算法,就是基于待聚类的数据,迭代寻找中心的过程。它根据预设的类别数K,为每个类别设定一个初始中心(可以随机产生),然后按照离它们距离的远近,将数据做归属划分。一旦有了数据划分,反过来就可以计算它们的中心,然后再按数据离新中心的远近对数据做重新划分。如此反复,直到中心不再改变。届时,就达到了每个数据点都离所在类的中心最近的目标。
3.算法描述(如图3)
4.算法运行例
二维数据作为手工呈现的例子会比较烦琐。我们不妨利用前面的一维年龄数据例子,体会一下过程。
5,10,13,21,23,24,25,39,41,42,52,55,58,59,61,62,72,79,82,92
根据题意,K=4,随机设初始中心为10,30,50,70。注意,它们不需要属于初始数据点集。
以距离最近为原则,将20个数据点做第一次划分,如表5(a)所示,而根据划分得到的新中心如表5(b)所示。
然后以这些中心为参照,将所有数据按离新中心的距离重新划分(看到先前第4类中有些数据跑到第3类了),得到新的4个类别:{5,10,13},{21,23,24,25,39},{41,42,52,55,58,59,61,62},{72,79,82,92}。
再计算中心,前两个不变,第3个成为(41+42+52+55+58+59+61+62)/8=53.75,第4个变成(72+79+82+92)/4=81.25。按它们再划分数据,发现没有引起变化,K-means聚类过程完成!我们清楚地看到了中心的确定和类别划分之间的相互“迭代”。上述过程也可以用下页表6来表示。
5.算法分析
K-means算法是经典的聚类算法,上一轮的结果作为新一轮计算的开始值,直至前后两轮计算的结果落在一个误差范围中,即趋于稳定。这里要关心的基本问题就是它是否能趋于稳定,也就是其中|new_centers-centers|是否能变得小于一个任意设定的门槛值threshold,即“收敛”。否则,这算法就会无穷无尽地执行下去。数学理论告诉我们,收敛会发生。尽管我们不需要懂得证明,但懂得这是需要关心的事情是算法素养的要求。
也许我们觉得还应该从收敛时聚类结果是否合理来讨论正确性,也就是“到底聚对没有”?但这通常会比较主观,与应用背景有关。以上述一维数据为例,如果将它们看成是年龄,我们脑子里事先已经有了少年、青年、中年、老年这样几个背景概念,也许你会觉得若41和42在第2类会更加合理。但如果那些数据有不同的含义,就不一定了。由于算法是不理解数据的含义的,它只负责类中心的收敛(数学上严格的,也符合实际中关于聚类的一些直觉)。在这个意义上,它就是正确的。至于它在某个具体问题上是否合适,则需要在特定应用背景下的实践来检验了。不过,取决于初值的选取,尽管都会收敛,但结果类中心不是唯一的,可能造成数据集划分的不同。这也需要在实际应用中注意。
从执行效率看,算法是一个两重循环。内层循环就是对数据集的两次遍历,一次做划分(在K个类中心中选取最近的),一次计算新的中心。外层循环执行的次数与类中心初值的选取有关。假设N为样本数据量,K为类别数,M为外层循环的迭代次数,算法复杂性就是O(M*N*K)。
由上述讨论可见,K-means算法的时间开销除了与数据样本数、聚类的类别数有关外,初始聚类中心的选择对聚类结果也有较大的影响,一旦初始值选择得不好,不仅会影响收敛速度,而且可能无法得到有意义的聚类结果。由此可见,聚类算法的效率和质量不仅仅是计算机算法的问题,对要解决的问题本身的了解和经验也是重要的因素。
当然,当我们对要处理的问题不够了解时,可以用随机数作为初始中心,还可以用不同的类别数对同一数据集合做多次尝试,与熟悉应用背景的专业人士合作,解读、解释有关数据,最终确定合适的类别数,预设中心的初始值。
释: ①所谓“维数”,指的是数据对象特征的个数。在人工智能应用中,维数可能达到成千上万。
参考文献:
[1]S.C.Johnson.Hierarchical Clustering Schemes[J].Psychometrika,1967(02):241-254.
[2]Anil K. Jain.Data clustering:50 years beyond K-means[J].Pattern Recognition Letters,2009.
注:作者系北京大学计算机系原系主任。
猜你喜欢
少儿画王(3-6岁)(2020年4期)2020-09-13
华东师范大学学报(自然科学版)(2019年5期)2019-11-11
东方教育(2018年20期)2018-08-22
软件(2017年6期)2017-09-23
电子技术与软件工程(2016年23期)2017-03-06
上海故事(2016年5期)2016-05-10
学苑创造·A版(2016年2期)2016-03-10
海外英语(2013年1期)2013-08-27
微型计算机(2009年4期)2009-12-23
