
基于改进LDA模型的信息安全事件提取算法
2021-01-10 08:22吴君戈张笑笑邹春明宋好好
网络空间安全 2020年12期
吴君戈,张笑笑,邹春明,宋好好
(公安部第三研究所/上海网络与信息安全测评工程技术研究中心,上海 200031)
1 引言
随着互联网技术的不断发展,信息化已经深入到人们生活的方方面面,信息化高速发展也导致了各式各样信息安全事件的出现,给人民的财产安全造成了严重的威胁[1]。与此同时,信息安全事件往往被淹没在海量的新闻事件中,研究人员较难快速地定位到信息安全事件之上,难以有针对性地提出解决方案[2]。因此,如何有效地从海量的新闻事件中抽取出信息安全事件,对于维护社会稳定和公共利益具有积极而重要的意义[3]。
近年来,国内外学者针对信息安全事件的分类提取工作进行了大量的研究。文献[4]中,作者利用TextRank和隐含狄利克雷分布(Latent Dirichlet Allocation,LDA)模型对信息安全热点事件进行分类和提取,然而LD模型需提前预设参数,参数选择对于其分类性能有着直接的影响。文献[5]中,G Jelena等人提出了基于K最近邻(k-Nearest Neighbor,KNN)分类算法和支持向量机(Support Vector Machine, SVM)的多层文本分类算法,并证明了所提算法的有效性。然而,实验中所用数据需提前进行主标签分类,当数据量增加时分类效率必然会有所降低。文献[6]中,A Ritter等人提出利用弱监督学习算法从Twitter上提取信息安全事件,但是由于Twitter属于文本表现自由的短文本,较之新闻文本有较大差别,因此该算法用于新闻文本中进行信息安全事件的分类抽取时并无优势。
对于信息安全管理而言,如何快速、准确地从大量新闻事件中提取信息安全事件是一个挑战。为了解决这个问题,本文提出一种基于改进LDA模型的信息安全事件提取方法,首先通过对传统LDA模型中文本主题数确定指标进行优化,提高LDA模型对于事件主题挖掘的准确性,进而从海量新闻事件中形成信息安全事件候选事件集,最后采用投票机制从候选事件集中分类出真正的信息安全事件。
2 基于改进LDA模型的候选事件集构建
2.1 传统LDA模型
隐含狄利克雷分布(Latent Dirichlet Allocation,LDA)模型由D M Blei等人提出,通过无监督学习方法分析文档集中每篇文档的主题分布,然后根据主题分布进行主题聚类或文本分类[7]。LDA模型认为一篇文档可以包含多个主题,这与一个信息安全事件往往涉及多个主题相吻合。
LDA模型的基本思想:首先是生成“主题-词汇”多项分布,此多项分布是服从参数为 β 的狄利克雷先验分布,再生成“文档-主题”多项分布,此多项分布是服从参数为 的狄利克雷先验分布,具体过程如图1所示[8]。
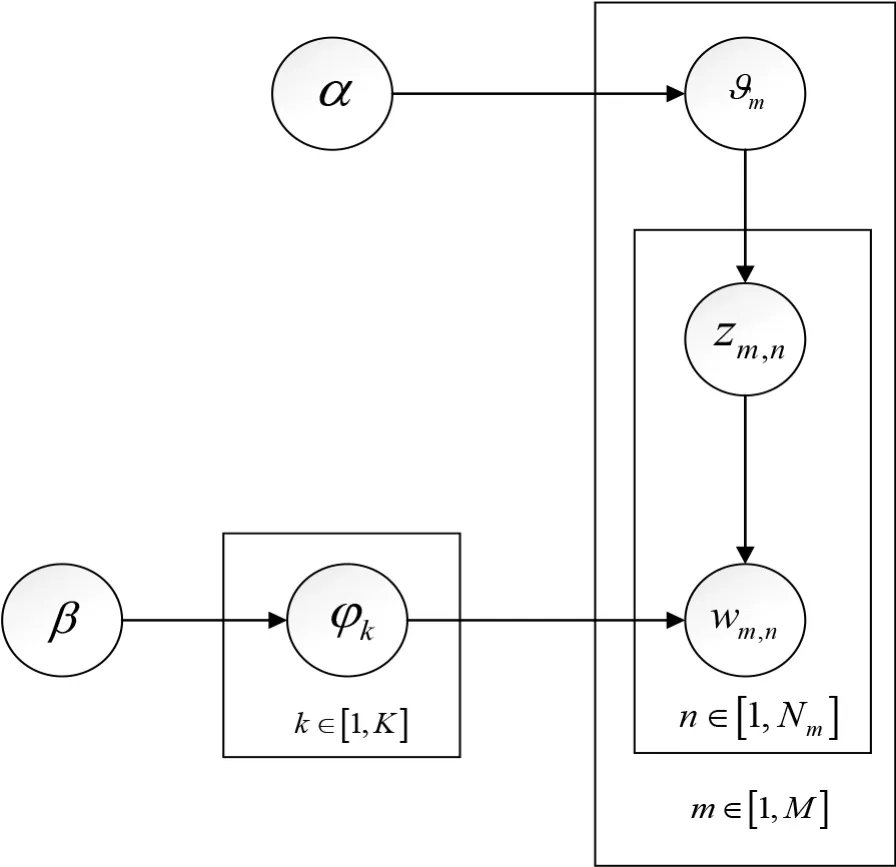
图1 LDA模型实现图
LDA模型具体实现就是确定出参数(α,β),常用的估计方法有期望传播、贝叶斯推断和Gibbs抽样等,由于Gibbs抽样的算法比较简单,而且对参数的抽样效果较为理想,因此在LDA主题模型中,常使用Gibbs抽样方法对语料库中的所有文档和词汇的主题进行提取,具体流程如下[9]:
1)选择合适的主题数K,初始化参数向量α和β;
2)对应语料库中每一篇文档的每一个词,随机的赋予一个主题编号Zm,n;
3)重新扫描语料库,对于每一个词,利用Gibbs采样公式更新它的主题编号,并更新语料中该词的编号;
4)重复第3)步的基于坐标轴轮换的Gibbs采样,直到Gibbs采样收敛;
5)统计语料库中的各个文档各个词的主题,得到文档主题分布,统计语料库中各个主题词的分布,得到LDA的主题与词的分布
由上述流程可以看出,确定参数(α,β)需提前预设好最优主题个数,因此影响最终LDA模型主题分类效果的一个重要因素是最优主题个数的确定。
2.2 改进的LDA模型
目前,LDA模型中常用于衡量最优主题数的指标有困惑度(Perplexity)、JS散度(Jensen-Shannon Divergence)等[10]。然而,Perplexity指标注重模型对新文档的预测能力,往往导致求得的最优主题数偏大,而JS散度侧重于主题之间的差异性和稳定性,虽弥补了Perplexity的缺点,但求得的主题数偏小。因此,本文结合两者的优点提出一种改进的最优主题数确定指标Perplexity-Aver,来得到更贴合实际要求的主题数目。
为衡量主题空间的整体差异性,首先在JS散度的基础上引入JS散度平均值Aver(T)的概念,表达式如下所示:

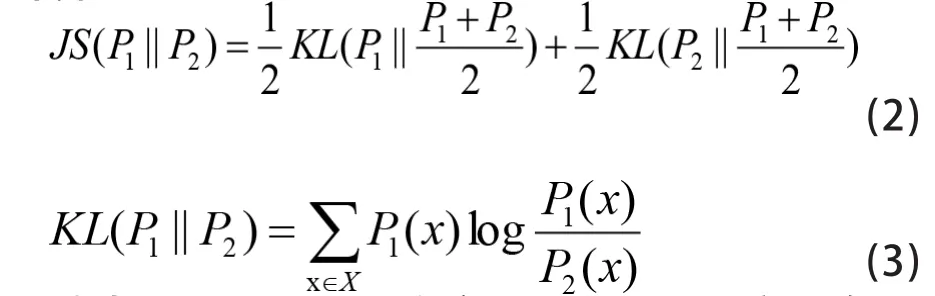
其中,P1和P2分别为主题k1和k2的概率分布。
最后,综合Perplexity和Aver(T)两个指标,提出一种确定最优主题数指标Perplexity-Aver,其计算方法如下:

其中,Dtest表示实验的文本数据集,Perplexity(Dtest)表示实验数据集的困惑度,Aver(Ttest)表示实验数据集的JS散度平均集。
由公式(4)可以看出,当Perplexity(Dtest)越小时,主题模型的泛化能力越强,对新文档主题的预测效果更好;当Aver(Ttest)越大时,主题模型各主题之间的差异就越大,主题的平均相似度就越小,主题抽取的效果就越好。因此,当Perplexity-Aver的指标最小时,对应的主题数是最优主题数。
综上所述,利用改进的LDA模型进行主题建模时分为七步骤:
1)将各类别混合的N篇文档进行预处理,包括去分词和去停用词;
2)将预处理好的文档集输入改进的LDA主题模型,输入模型参数K、α、β;
3)利用Gibbs抽样计算出模型的θ和φ分布;
4)改变K的值,重复步骤2)和3),得到不同主题数下的建模结果;
5)根据Perplexity-Aver确定最优主题数K;
6)修剪无关的词汇,输出各类信息安全事件下的关键词;
7)输出主题建模结果。
其中,步骤1)中分词是指遵循一定的规则,将一个个连续的字序列划分为词汇的过程;去停用词是指删除文档中出现的虚词和对文本分类没有实际意义的高频词汇。
2.3 候选事件集构建
通过改进的LDA模型进行主题建模,可以得到信息安全事件的几大类别,并得到每一类主题下的主题词,主题词可以作为该类信息安全事件的触发词,由触发词引发的事件集合称为候选事件集。
然而,并非所有含触发词的事件都是与信息安全相关的事件。例如表1所示,只有句子1是信息安全相关事件,即句子中的“病毒”是网络病毒的含义;句子2和句子3都不属于信息安全事件的范畴,不是我们真正关注的事件。
因此,本文对事件触发词进行改进,将触发词分为“限制词”和“业务词”,业务词是指事件涉及到的敏感词汇,限制词则根据每一类事件实际描述的事件内容,限定了业务词引起的事件的范围。将“限制词”和“业务词”同时作为触发条件,以使候选事件更接近于信息安全相关事件。

表1 触发词触发的事件示例

表2 业务词和限制词共同触发的事件示例
虽然将事件触发词改进为“限制词”和“业务词”,可以提高候选事件集中信息安全事件的比例,但是得到的候选事件集中仍然存在不合要求的事件。例如表2所示,其中句子1和3是与信息安全相关的事件,句子2和4明显是与信息安全无关的事件。
因此,本文选择触发语句所在位置、触发语句在全文的比例、标题是否为触发语句作为候选事件集中的特征项对候选事件集进行特征提取,具体定义为:
① 触发语句所在位置F1的计算方式如公式(5)所示:

其中,Nrank表示触发语句在文中的位置,即触发语句在文中第几句;Ntotal表示文中句子总数。
② 触发语句在全文中的比例F2的计算方式如公式(6)所示:

其中,ntotal表示触发语句在文中的数量。
③ 标题是否为触发语句F3的计算方式如公式(7)所示:

3 基于改进LDA模型的信息安全事件提取算法
由于候选事件集中的文章仅有两类,与信息安全相关的事件和与信息安全无关的事件,因此识别真正的信息安全事件问题可以看作是一个二分类问题。基于此,本文对候选事件集进行特征提取之后,利用投票机制,完成对信息安全事件和与信息安全无关的事件的分类。
基于投票机制的文本分类属于集成学习,其基本思路是先使用多个分类器单独对样本进行预测,然后通过一定的方式将各个分类器的分类结果融合起来,以此决定文本的最终归属类别。集成学习是否有效的关键有两点:
一是各个基分类器必须有一定的差异性;
二是各个基分类器的预测正确率必须不小于50%。
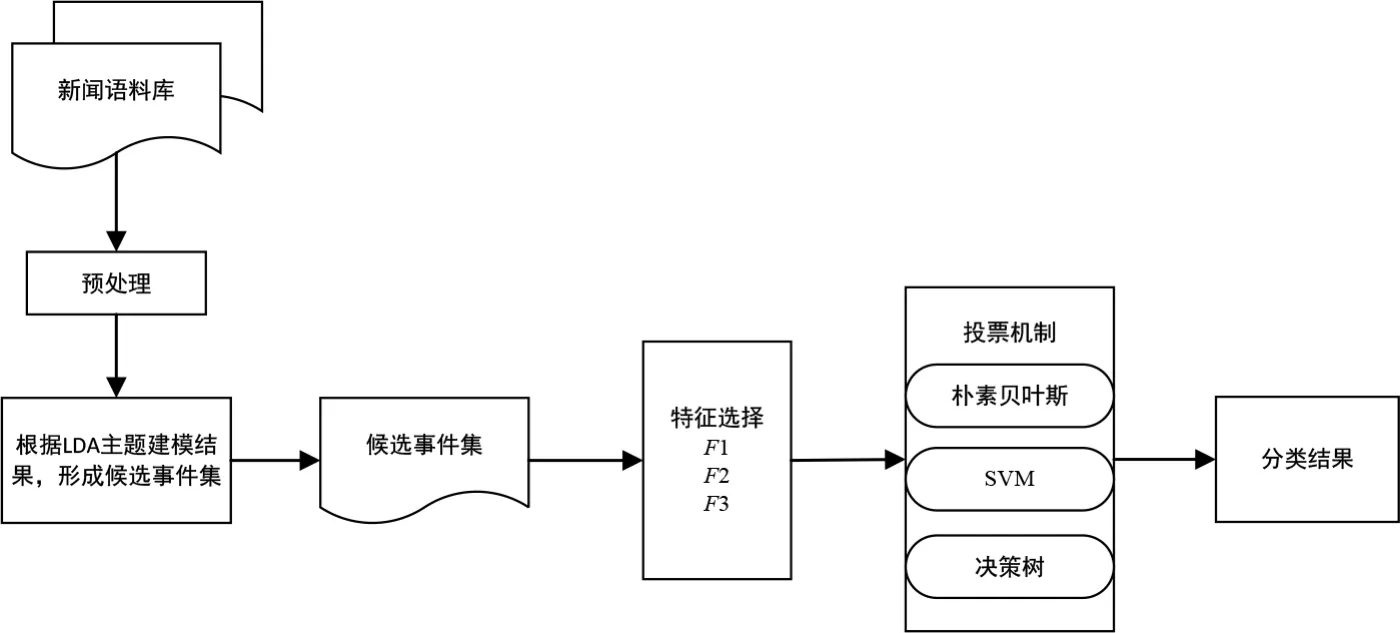
图2 信息安全事件提取算法流程图
因此,本文选取朴素贝叶斯、SVM、决策树构建投票机制,利用候选事件集特征F1、F2和F3,供二元分类算法学习,进而采用训练完成后的投票机制进行预测,预测数据的最终结果为服从多数分类器预测的结果,具体算法流程图如图2所示。
4. 实验结果及分析
4.1 实验数据及预处理
本文通过网络爬虫工具GooSeeker,收集国内主流的信息安全网站(中国信息安全等级保护网、中国信息安全网等)2015年1月1日至2019年12月30日期间报道的信息安全事件作为原始数据集。原始数据集内容为上述网站的新闻内容、标题和发布时间,其中新闻内容只保留文字,去除视频、图片等格式的数据。
由于采集到的原始数据中含有垃圾数据,因此经对采集到的数据进行去除重复数据和删掉无文本的空白数据后,共获得有效数据13,684条。
4.2 实验结果分析
本文在对对原始数据进行分词和去停用词的预处理后,利用改进的LDA模型对原始数据集进行主题建模,设置迭代次数为100,经验值参数α和β参照文献[11]分别设置为50/k和0.01。对于主题数量K,根据以往信息安全事件的分类经验,将主题数量约定在3~10之间,利用Perplexity-Aver确定最优的主题数K。图3为主题建模过程中Perplexity-Aver值与Perplexity、JS散度的对比关系,从图3中可以看出,Perplexity因更看重对新文档的预测能力导致主题数偏大,而JS散度因更看重整体的差异性和稳定性而导致主题数偏小。
为了进一步验证本文所提信息安全事件提取方法的性能,选取准确率(Precision)、召回率(Recall)和F值作为评价标准,表达式如下所示:

其中,TP表示正确匹配的样本数量,即将信息安全事件样本预测为信息安全事件的数量,FN表示漏报的样本数量,即将信息安全事件的样本错误预测为非信息安全事件的数量,FP表示误报的样本数量,即将非信息安全事件的样本错误预测为信息安全事件的数量,TN表示正确的非匹配样本数量,即将非信息安全事件的样本预测为非信息安全事件的数量。
实验中,使用交叉验证的方法进行5折交叉验证,即每次选择实验数据的1/5作为测试数据,剩下的4/5作为训练数据,进行5次试验,并将5次试验结果的准确率、召回率、F值的平均值作为最终的准确率、召回率和F值。为了验证本文所提信息安全事件提取方法的有效性,选取文献[4]和文献[12]中所提分类算法进行比较,其中文献[4]为采用传统LDA模型进行文本分类提取的方法,文献[12]提出一种基于改进BP神经网络的文本分类方法,结果如表3所示

图3 Perplexity-Aver与Perplexity、JS散度的对比关系
从表3中可以看出,在准确性、召回率和F值指标上,本文所提事件提取方法均要优于文献[4]和文献[12]所提的文本分类方法,这是证明了本文所提算法在信息安全事件提取方面的有效性。
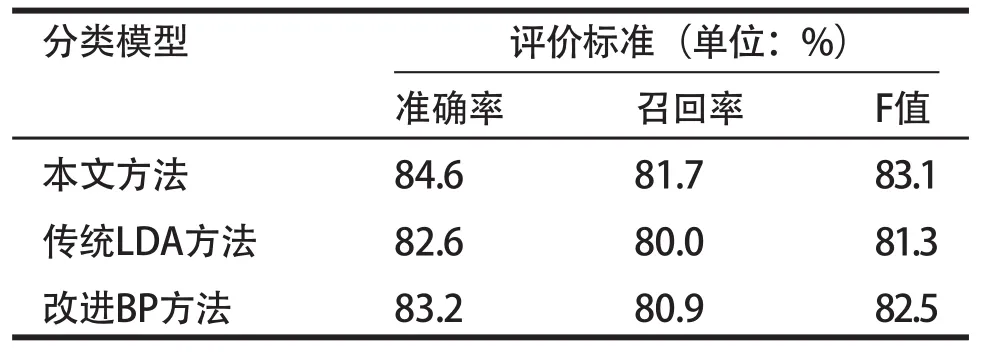
表3 本文方法与其他文献方法性能比较
5 结束语
本文提出一种基于LDA模型和投票机制的信息安全事件提取方法,通过利用LDA主题模型和改进的主题数确定指标Perplexity-Aver对新闻事件进行主题建模,得到信息安全候选事件集,最后利用投票机制从候选事件集中识别出真正的信息安全事件。仿真结果表明,本文所提信息安全事件提取方法,无论在准确率、召回率,还是F值方面,均优于传统的文本方法,可以获得较好的文本分类性能。
猜你喜欢
舰船科学技术(2022年10期)2022-06-17
客联(2022年3期)2022-05-31
中国新闻周刊(2021年26期)2021-07-27
电脑爱好者(2021年9期)2021-05-12
信息化建设(2021年5期)2021-01-16
电脑爱好者(2017年7期)2017-05-06
数学教学通讯·初中版(2014年6期)2014-08-11
小学生·多元智能大王(2014年6期)2014-07-09
中国计算机报(2014年18期)2014-07-05
小雪花·初中高分作文(2009年8期)2009-11-16
