
深度学习技术在学科融合研究中的应用
2021-01-09 06:39刘晓东倪浩然
数据与计算发展前沿 2020年5期
刘晓东,倪浩然
1. 中国科学院计算机网络信息中心,信息化战略发展与评估中心,北京 100190
2. 华威大学,真实系统数学,英国 考文垂
1 Introduction/Overview
The number of published papers contributed by the Chinese Academy of Sciences (CAS) is around 70,0001The data in this paper is collected from the public database of Web of Science.in the year 2018, which rose by 21.8% year-on-year. Due to the increasing number of papers each year and the disciplinary inter-crossing, artificial classification of papers by disciplines becomes harder and harder. There are several difficulties with the artificial classification. First, research paper contains massive information, which makes the workload much heavier than other classification tasks. Secondly, reading papers from specific disciplines requires professional knowledge. However, hiring experts for the classification task is expensive and impractical. Finally, the inter-crossing of disciplines makes it hard to tell even when the papers are evaluated by experts in the related fields. In the meantime, the demand for classifying papers and trend prediction is rapidly increasing. In this background, text classification in natural language processing (NLP) is considered to solve this problem.
As an essential component in NLP applications, text classification has aroused the interest of many researchers. There are many classic application scenarios for it, such as public opinion monitoring (Bing & Lei, 2012)[1], intelligent recommendation system, information filtering and sentiment analysis (Aggarwal & Zhai, 2012)[2].
One of the main problems in text classification is the word representation. Bag-of-Words (BoW) model (Zhang et al., 2010)[3]is the pioneer in this area, where some designed patterns such as uni-grams, bi-grams and n-grams are extracted as features. With the higher order in n-grams and the complicated feature structure (Post & Bergsma, 2013)[4], the model could consider more contextual information and word orders. However, these models failed in capturing the semantics of the sentences and the data sparsity problem remains unsolved. As a distributed representation of words, pre-trained word embedding offers a way to capture meaningful syntactic and semantic regularities (Mikolov, Chen et al., 2013)[5], and mitigates the data sparsity problem (Bengio et al.,2003)[6]. As one of the state-of-art method of word embedding, word2vec (Rong, 2014)[7]includes two training models: continuous Bag-of-Word (CBoW) (Mikolov, Chen et al., 2013)[5]and skip-grams (Mikolov, Sutskever et al., 2013)[8]. In this paper, we apply the Global Vectors for Word Representation (GloVe) model proposed by Pennington et al. (2014)[9], which outperforms word2vec on the word representation task.
Another problem is the classifier. There are many machine-learning algorithms that can be used as classifiers, such as logistic regression (LR), naive Bayes (NB) and support vector machine (SVM). However, these methods all have the data sparsity problem and do not have a satisfying performance on NLP tasks. With the development of deep neural networks, convolutional neural networks (CNNs) and recurrent neural networks (RNNs) are widely used in NLP tasks as the state-of-art classifiers due to their exceptional performance. In our research, we build a CNN (Kalchbrenner et al., 2014)[10]model and apply it to the paper classification. The input of the model handles sentences of varying length. The layers include several one-dimensional convolutional layers and ak-max pooling layer. The convolutional layers apply one-dimensional filters across each row of features. The max pooling layer is a non-linear subsampling function that returns the maximum of a set of values. A convolutional layer followed by a max pooling layer and/or a non-linearity form a basic block to calculate matrix named feature map. In the input layer, we enrich the representation by computing multiple feature maps with disparate filters. Subsequent layers followed by the input layer also have multiple feature maps computed by convolving filters with all the maps. The weights at these layers form an order-4 tensor. The resulting structure is named as Convolutional Neural Network (Lecun et al., 1998)[11].
The networks are trained on 7,000 abstracts of the research papers from 23 different subjects labelled artificially by experts in CAS. After training, the networks generally surpasses 90% in the prediction accuracy on the hand-labelled test, experimented on the well-trained networks in the published research papers contributed by the CAS from 2012 to 2018. By labelling the papers with the classifiers of selected subjects, the trend of interdisciplinary research is shown in the results.
The outline of the paper is as follows. Section 2 reviews the related works including word representation models, neural networks, optimization of hyperparameters and related applications of text classification. Section 3 defines the classifier, word representation model, the relevant operators and the layers of CNN and the auto-optimization method we applied in the paper. Section 4 discusses the experiments and the results.
2 Related Works
The text classification tasks mainly include three parts: feature engineering, feature selection and classifiers. The feature engineering was commonly based on the BoW model. Rong (2014)[7]proposed the word2vec method, which is widely accepted as the state-of-the-art for word representation. However, it is limited in utilizing statistical information, since there is no global co-occurrence counts. Pennington et al. (2014)[9]introduced the GloVe model, which combines the advantages of latent semantic analysis (LSA) (Deerwrester et al., 1990)[12]and word2vec. This new word-representation method efficiently improved the accuracy of many basic NLP tasks, especially for limited training dataset. There are also other advanced methods recently, such as Bidirectional Encoder Representation from Transformers (BERT1) (Devlin et al., 2018)[13]. Feature selection is applied for filtering the noisy features and improving the performance of the classifiers. The common feature selection methods include removing stopping words, statistic, mutual information andL1regularization (Ng, 2004)[14]. For classifiers, there are several machine learning algorithms such as logistic regression (LR), naive bayes (NB), and support vector machine (SVM). However, they all have the data sparsity problem.
2.1 Neural Networks in NLP
With the development of deep neural networks, the data sparsity problem has been well solved. Many neural models have been proposed for word embedding and classification. Recursive Neural network (RecursiveNN) (Socher, Huang et al., 2011; Socher, Pennington et al., 2011; Socher et al., 2013)[15-17]captures the semantics of a sentence via a tree structure. However, the time complexity of constructing a textual tree is at leastO(n2), which is time-consuming for long documents. The Recurrent Neural Network (RNN) (Elman, 1990)[18]is a model, which analyzes the semantics of the text in fixed-sized hidden layers, with a time complexityO(n). However, it is a biased model where later contents are more dominant than earlier contents. To tackle the bias, the Long Short-Term Memory (LSTM) (Liu et al., 2016)[19]model is proposed, which gives a better performance for long documents. The Convolutional Neural Network (CNN) (Kalchbrenner et al., 2014)[10]is another unbiased model introduced to NLP tasks. Although the time complexity of CNN isO(n)too, we found that empirically it outperforms LSTM in both training time and accuracy. Advanced models include Attention Networks (Abreu et al., 2019)[1], Contextual LSTM (C-LSTM) (Ghosh et al., 2016)[20]and Recurrent CNN (RCNN) (Lai et al., 2015)[21]. We will not discuss them since they are too sophisticated and do not contribute noteworthy improvement in accuracy.
The performance of the model also depends on the choice of optimizer and the hyper-parameters. There are many classic optimizers, such as Batch Gradient Descent (BGD), Stochastic Gradient Descent (SGD), Momentum, Adadelta, Adam. We apply the SGD method in our experiments due to its sensitivity to hyper-parameters and model performance. Zhang and Wallace (2015)[22]researches deeply in the sensitivity analysis and gives some practical advises in the selection of hyperparameters. However, it requires rich experience in NLP engineering, and consumes massive energy and time. Instead of manual selection, we apply auto-optimization algorithms in our research, which offers a modest performance with time and energy saving. The most direct algorithm is Grid Search. However, it costs too much computing resources. Bergstra and Bengio (2012)[6]proposes Random Search which improves the performance of optimization. Bayesian algorithm (Snoek et al., 2012)[23]is more efficient than Random Search, but it cannot deal with continuous variables. To tackle this problem, we apply Tree-structured Parzen Estimator (Bergstra et al., 2011; Bergstra et al., 2013)[24-25]for optimizing the hyper-parameters. To exploit the parallelism of the operations, the network is trained on GPUs using Pytorch.
3 Methods
3.1 Classifier
For training sample sets {s1,s2,s3,s4}, whereSn,n=1,2,3,4 is the sample set with the categorycn, we define the classifier as an one-versus-rest model in our task.
Training Samples

In our research, we train separate classifiers for different subjects and label each paper with these classifiers according to the above model. If there is more than one positive prediction for the paper, we believe cross-discipline happens between the labelled subjects.
3.2 Word Representation Learning
We introduce GloVe model in this section. The model is proposed by Pennington et al. (2014)[9]. We denote the matrix of word-word co-occurrence counts asX, where the entriesXijtabulate the number of times wordjoccurs in the context of wordi. The number of times any word appears in the context of wordiis denoted asXi=k Xik. We denotew∈das word vectors and ∈das separate context word vectors. The model is given as follows:

whereVis the size of the vocabulary,biandbjare the bias. We practically choose the function:
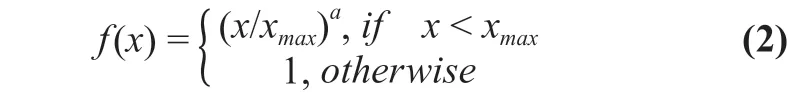
as the weighting functionf(Xij). We fixxmax= 100 andα= 3/4 as they give the best performance for our experiments (Mikolov, Chen et al., 2013)[5].
3.3 Convolutional Neural Network
We build a model using a convolutional architecture that alternates 3 or 4 convolutional layers with pooling layers given byk-max pooling. The resulting architecture is the Convolutional Neural Network.
3.3.1 Convolution
For a vector of weightsm∈mand a vector of inputss∈sas the sentence, the one-dimensional convolutional operation is to take the dot product ofmand eachm-gram ofsto obtain the vectorc:

There are two types of convolution depending on different requirements. The narrow type requiress≥mand the resulting sequencec∈s-m+1, wherejis frommtos. In the wide type of convolution,scould be smaller thanm. The inputsiare taken to be zero wheni<1 ori>s. In the case, it yields the sequencec∈s+m-1, where the range of the indexjis 1 tos + m-1. Notice that, the sequencecin the narrow convolution is a sub-sequence of which in the wide convolution. Wide convolution has some advantages such as ensuring that all weights in the filter reach the entire sentence and producing a non-emptycwhich are independent of the widthmand the sentence lengthsall the time. We apply wide convolution operation in our model. For the sentence matrixs∈d×swhich is constructed by the embeddingwi∈dfor each word, we obtain a convolutional layer by convolving a matrix with trained weightsm∈d×mwith the activations at the layer below. The resulting matrixcat each layer has dimensionsd×s + m-1.
3.3.2 Non-Linear Activation Function
After each convolutional layers, a biasb∈dand a non-linear activation functiongare applied componentwise to the resulting matrixcof the convolution. DefineMto be the matrix of diagonals:

wheremare the weights of thedfilters of the wide convolution. Thus, we obtain:
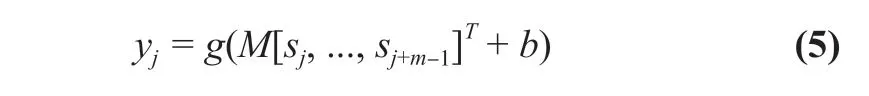
This function makes sure that the output of our network is not just another linear combination of the inputs and gives the possibility to generate more complicated functional relationship for different tasks. There are many different activation functions, such asSigmoid,tanh(Gulcehre et al., 2016; Glorot & Bengio, 2010)[26-27],ReLU(Nair & Hinton, 2010; Glorot et al., 2010)[28-29]andmaxout(Goodfellow et al., 2010)[30]. We applyReLUfunction due to its faster convergence rate and generally moderate performance in practice.
3.3.3 Max Pooling
Given a numberkand a sequencep∈p, wherep≥k,k-max pooling is the pooling operation that extracts theklargest values ofpwith the same order and constructs a sub-sequenceIn our experiments, we setk=1in thek-max pooling layers.

where thej-th sequence of the matrixzis the maximum in thej-th elements ofyi.
By applying thek-max pooling operators after the convolutional layers, it is available to pool thekmost active features inpand to capture the information throughout the entire text. It preserves the order of the features and ignores their positions. It also discerns precisely the number of times the feature is highly activated inpand the change of the feature activations acrossp. There are other kind of pooling operators such as average pooling (Collobert et al., 2011)[31]. We do not apply them here since only a few words are meaningful for capturing the semantics and further classification in the text. After all the convolutional layers and max pooling layers, a fully connected layer followed by the softmax function is applied for converting the output numbers into probabilities, which predicts the classes of the input sentence.

For binary classifier, we letn=2in both Equation 6 and Equation 7.
4 Experiments
4.1 Datasets
Our datasets are collected from the internal database of CAS. The datasets include 330,907 published papers of CAS from 2012 to 2018. We randomly take 7,000 abstracts out of the papers as the training samples labelled them with 23 subjects by experts. In the word representation training, our pre-trained vectors for GloVe are 50-dimensionalWikipedia2014 +Gigaword5, which are provided in the GloVe project (Pennington et al., 2014)[9]. After that, we classify the remaining papers by 8 main subjects, which are Astronomy, Atmospheric Science, Electronic Science and Technology, Geology, Mathematics, Nuclear Science and Technology, Physics and Computer Science and Technology, using the welltrained models. We investigate the cross-disciplines between Computer Science and Technology and other 7 selected subjects on timeline.
4.2 Hyper-Parameters and Training
In our experiments, the optimization goal is to minimize the difference between the prediction and the true distribution, which includes anL2regularization term over the parameters. The set of parameters in the optimization are the word embeddings, the filter and the fully connected weights. The network is trained with mini-batches by back-propagation. Stochastic gradient descent is applied here to optimize the training target. The hyper-parameters comprise the batch size, including the learning rate of optimization, the number of negative samples, the number of layers, the kernel number, and the kernel size of each convolutional layer. To optimize these hyper-parameters, the Tree-structured Parzen Estimator Method is applied here as an auto-optimization algorithm.
4.3 Experiment Settings
We preprocess the datasets as follows. We use Natural Language Toolkit (NLTK) to obtain tokens and stems. Stop words and symbols are also removed by this toolkit. We split each dataset into training dataset, validation dataset and testing dataset by the ratio 6:2:2. We apply F1 measure to evaluate the model performance, Precision, Recall and Accuracy to evaluate the classification results. The hyper-parameter settings of the neural networks depend on the used datasets.
We use the CNN model to classify the abstract information of the paper, and use 3 or 4 layers of convolutions to train the observation effect. The algorithm of the training model chooses to use the stochastic gradient descent algorithm. Because the stochastic gradient descent algorithm is more sensitive to hyper-parameters than other optimization algorithms and can get better results by adjusting the parameters.
4.4 Results and Discussion
4.4.1 Interdisciplinary Design
According to the experimental research in this paper, due to the rapid development of computer science informatization, the development of information technology represented by cloud computing, big data, deep learning, etc. has entered an explosive phase since around 2010, and a large number of cutting-edge technologies of computer science have been used for each scientific research in the field. As shown in the Figure 1, the field of physics ranks first in the number of 48,450 papers published in last 6 years. Using the method proposed in 3.1.2 of this paper, 5,254 papers in the field of physics are used to apply the knowledge in the field of computer science and technology. The crossover rate is as high as 11.1%, ahead of the other seven areas of the dataset. In Figure 2, the integration of various fields and computer science and technology is getting closer and closer, and the correlation between various scientific research work and computer science and technology is getting stronger and stronger.
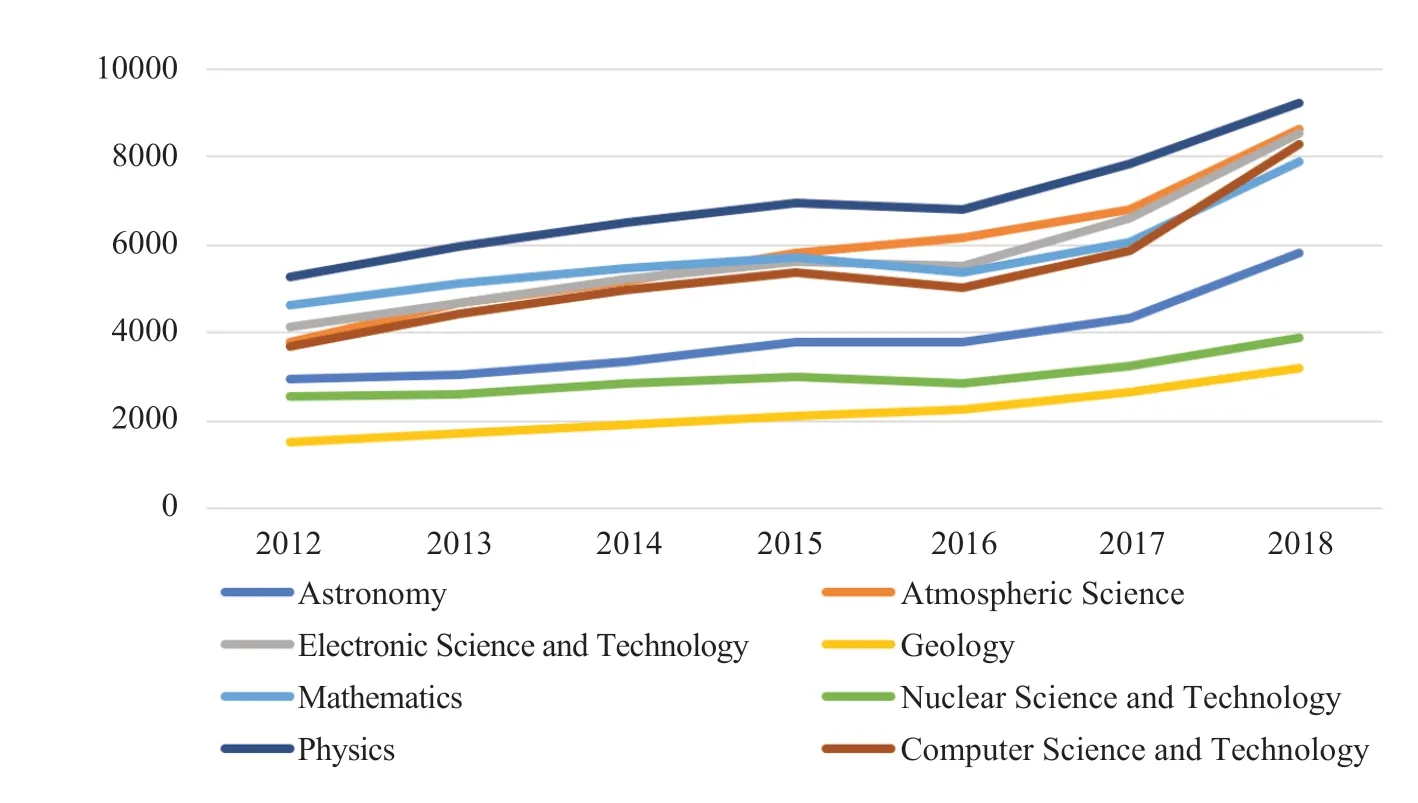
Fig. 1 Total number of articles

Fig. 2 Percentage of crosses
4.4.2 Disciplinary development and interdisciplinary
Secondly, in recent years, in the field of physics, the distributed file systems, machine learning, cloud storage and other technologies have been widely used in the field of physics. The number of papers published in this field has increased from 5,252 in 2012 to 9,204 in 2018, the number of interdisciplinary papers in the field has also increased from 578 to 1,072, both of which have shown a consistent trend of overall curve rise; the same is true in the field of atmospheric science, which grew from 3,808 to 8,598 articles. The cross-disciplinary relationship between this field and computer science and technology has also increased from 410 to 1,011. The growth rate is obvious. The focus of electronic science and technology field is from 4,152 in 2012 to 8,531 in 2018, and it is related to computer science. The interdisciplinary division of technology has also grown from 457 to 1,072. Besides, cross-disciplinary relationships over mathematics, astronomy, and other fields are all growing as shown in Figure 3.
4.4.3 Research Ability and Subject Cross
In the end, according to our findings, the degree of information infrastructure construction of scientific research institutions shows that the degree of information technology infrastructure construction of scientific research institutions has been steadily increasing year by year, and the scientific research capabilities of large scientific research institutions have been greatly improved. It is consistent with the trend of integration of various research fields with computer science and technology, according to which we believe that there is a positive correlation between the ability of scientific research and the degree of interdisciplinary. The scientific research ability and the degree of interdisciplinary promote and grow mutually.
4.4.4 Research Extension
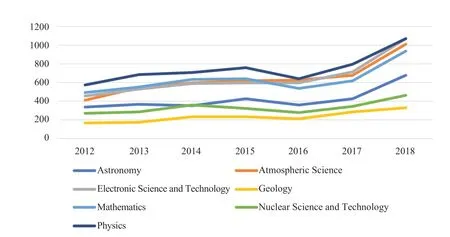
Fig.3 Number of crosses
For the subject classification and fusion problem of this paper, we can apply the results to the evaluation of subject development, talent cultivation, resource optimization, and the establishment of college education study curriculum, or the cultivation of compound talents. The research results in this paper can guide scientific research institutions to carry out strategic planning and deployment better. In addition, our research ideas can also be applied to related expansion issues, such as subject type prediction, attribute judgment, differentiation of low-frequency subjects and confusing subjects. Furthermore, the introduction of attention mechanism would train the subject prediction models to handle the problem of complex case classifications based on the description of each case.
5 Conclusion & Discussion
In this paper, we applied Convolutional Neural Network and Recurrent Neural Network in Research Paper Classification Tasks. We researched the published papers of research institutions over the years, marked the papers and selected eight types of them to train. We used the algorithm model of 1VO+GloVE+CNN to preprocess and train the dataset. The classification and interdisciplinary statistics based on these eight subject models were completed to analyze the number, proportion and regularity of papers with interdisciplinary subjects. Through experiments, this paper believes that the intersection of scientific research work and computer science in various fields is becoming closer, and the degree of interdisciplinary is consistently growing with the rising trend of the number of scientific papers published. In future work, we can apply scientific research results to the development of disciplines, personnel training and resource optimization, which will help scientific research institutions carry out strategic planning and deployment. In the future, we will continue to study different areas on this issue.
Acknowledgments
This work was supported by the National Science Library of the Chinese Academy of Sciences. Thanks to the National Science Library.
猜你喜欢
保健医苑(2022年1期)2022-08-30
——李振声
干旱地区农业研究(2022年3期)2022-06-09
快乐学习报·教育周刊(2022年16期)2022-05-01
新高考·高三数学(2022年3期)2022-04-28
商用汽车(2020年6期)2020-08-14
福建基础教育研究(2019年6期)2019-05-28
三联生活周刊(2016年40期)2016-10-09
投资与合作(2009年3期)2009-05-08
棋艺(2001年21期)2001-01-06
