
基于混合变量选择的绿茶酚氨比近红外光谱检测方法
2021-01-08 02:35:54黄俊仕王冬欣熊爱华艾施荣吴瑞梅文建萍
江西农业大学学报 2020年6期
黄俊仕 ,王冬欣,熊爱华,刘 鹏,3,李 红,艾施荣,吴瑞梅,文建萍*
(1.江西农业大学工学院,江西南昌 330045;2.婺源县鄣公山茶叶实业有限公司,江西婺源 333200;3.江西机电职业技术学院,江西南昌 330013)
【研究意义】茶叶最早生产于我国,由于其良好的滋味口感和有益的药用价值,深受消费者喜爱,已经成为世界三大饮料之一。随着茶文化的推广以及“一带一路”等贸易政策的提出,我国茶叶生产和消费总量不断增长,2018年国内茶叶消费总量达到200万吨,消费总额达到2 400亿元。近年来,茶叶行业不断增加与茶叶内部有益成分相关的质量控制措施,以提高其市场价值[1]。茶多酚(tea polyphenols,TP)、氨基酸(amino acid,AA)等茶叶内部成分直接影响着茶叶滋味品质。茶多酚含量决定了茶叶滋味的醇厚,儿茶素是茶叶中最丰富的多酚类物质,在绿茶中含量很高,有一种独特的涩味,适合大多消费者的口味[2]。氨基酸含量影响着茶叶鲜爽味,可以起到缓解涩味,增加甜味的作用[3−4]。涩味与鲜爽味的协调是茶叶滋味的关键,即茶叶中茶多酚与氨基酸含量比例(酚氨比)是决定茶叶滋味品质的重要指标。王海利等[3]研究表明酚氨比相对于氨基酸和茶多酚含量单一指标,能更好地反应茶叶滋味,且酚氨比与茶滋味鲜度、醇度和滋味化学总分均存在极显著负相关性。对于茶叶品质内部成分的检测,常采用液态色谱−串联质谱法[5],分光光度法[6],高光谱成像技术[7]等理化方法进行分析,而这些方法存在成本高,耗时耗力,前处理复杂等缺陷,难以适应现场快速检测需要。近红外光谱(near infrared spectroscopy,NIR)是一种介于可见光和中红外之间的电磁辐射,主要反映有机物中C−H,N−H,O−H等含氢基团振动的合频、倍频吸收光谱信息,由于该技术具有成本低、效率高、响应速度快、绿色无损等优势,被广泛应用于茶叶品质检测[8−10]。近红外光谱数据量大,不仅包含分析物相关的有用信息,也存在大量的冗余信息。当所有光谱波长信息均被用于模型建立时,将导致模型计算量大以及过拟合等问题降低模型预测性能,研究者们将这种现象称之为“维度灾难”。
【前人研究进展】针对这一问题,许多研究者利用变量选择方法提取有效光谱特征波长,用于预测模型的建立,不仅可以提高模型的预测性能,还能提供更佳的解释性模型。Chen等[11]利用主成分分析方法提取近红外光谱低维特征,并结合反向传播自适应提升算法建立8种茶叶滋味相关的内部成分预测模型,模型预测集相关系数大于0.7。Yang等[12]采用联合区间最小二乘(synergy interval partial least square,Si−PLS)方法优选近红外光谱变量区间,建立水泥原料主要成分(CaO、SiO2、Al2O3和Fe2O3)检测模型,预测集相关系数达到0.729 4~0.930 4,平均预测误差为0.03%~0.13%。然而,即使选择小区间变量,一些共线性的相关变量依旧存在,且在实际建模中变量数仍然很多。因此,Dong等[13]采用自适应权重加权算法对Si−PLS优选的近红外光谱区间变量再次进行特征选择,利用极限学习机结合自适应提升算法建立工夫红茶发酵过程中茶黄素与茶红霉素比值快速检测模型,模型预测集决定系数为0.893,预测均方根误差为0.004 4。【本研究切入点】面对光谱数据中的大量特征变量,需考虑变量选择过程计算速度和精度,混合特征筛选方法越来越多的被研究者所关注。【拟解决的关键问题】本文采用变量组成集群分析−迭代保留信息变量混合特征提取方法对茶叶浸出物近红外光谱波长变量进行优选,利用筛选出的特征波长建立随机森林(randomforest,RF)茶叶滋味品质指标酚氨比预测模型,并与线性偏最小二乘(partial least squares,PLS)模型进行比较。
1 材料与方法
1.1 样本制备
选取来自不同省份的93个不同等级市售茶叶样本,所收集的样本均经过正常的处理和储存,以确保在处理过程中不会出现明显的变质。首先,每个样本称取3 g干茶加入150 mL沸腾蒸馏水中,盖上杯盖浸泡5 min。用滤纸过滤后,待冷却至25 ℃左右进行后续测定分析。
1.2 酚氨比化学测定
每个样品取10 mL上层浸出液,滴入25 mL的容量瓶中,用蒸馏水稀释刻度线。采用福林酚试剂比色法,依据GB/T 8313-2008《茶叶中茶多酚和儿茶素类含量的检测方法》国家标准进行茶多酚测定;采用茚三酮分光光度法,依据GB/T 8314-2013《茶游离氨基酸总量的测定》国家标准进行氨基酸测定。酚氨比由茶多酚总量除以氨基酸总量得来。图1所示为茶叶样本酚氨比统计图,所有样本酚氨比呈正态分布。

图1 茶叶样本酚氨比统计Fig.1 Statistical diagram of ratio of TP to AA for tea samples
1.3 近红外光谱采集
Antaris II型近红外光谱仪(美国Thermo Fisher公司)用于检测茶叶浸出液,并利用InGaAs检测器光谱数据采集。光谱扫描范围为10 000~4 000 cm−1,分辨率为3.856 cm−1,扫描次数为32,每个样本具有1 557个光谱数据。吸光度数据以log(1/R)的形式存储,R表示透射率。每个样本被测定3次,以3个光谱的平均值作为该样本最终光谱数据。由于茶叶浸出液中可能存在气泡等因素,导致光散射[14],原始光谱中除分析物自身信息外,还包含一些噪音信息。标准正态变量变换(standard normalvariate transformation,SNV)能够有效消除散射引起的噪音,提高光谱信噪比。因此,在预测模型建立之前选择SNV方法对茶汤近红外光谱进行预处理,图2所示为经预处理后所有样本光谱图。
1.4 变量组成集群分析-迭代保留信息变量混合特征提取方法
1.4.1 变量组成集群分析 变量组成集群分析(vari-able combination population analysis,VCPA)[15]是一种基于达尔文“适者生存”进化论的变量选择方法。该方法主要运用指数衰减函数(exponentially decreasing function,EDF),二进制矩阵采样法(binary matrix sampling,BMS)和模型集群分析(model population analysis,MPA)从变量空间中选取最优变量子集。首先,采用EDF确定每次迭代剩余变量数,BMS根据剩余变量数从变量空间进行采用组成若干变量子集。然后,利用各变量子集分别建立偏最小二乘子模型,采用MPA方法从前10%的最优子模型中保留出现频数最多的变量。在保留的变量空间上再次重复以上操作,迭代N次,最终筛选出最优的变量子集[16]。
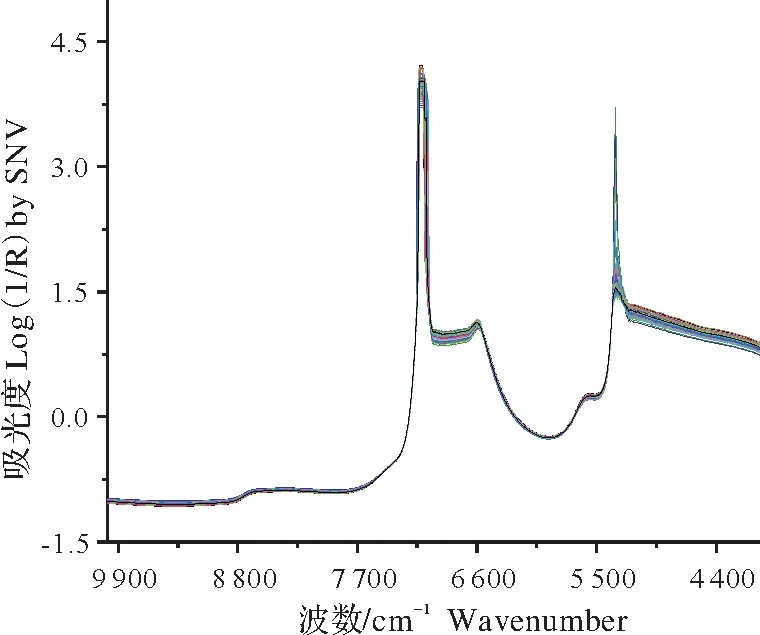
图2 SNV预处理后的茶汤光谱Fig.2 NIR spectra of tea infusion by SNV preprocessing
1.4.2 迭代保留信息变量 迭代保留信息变量(iteratively retains informative variables,IRIV)[17]把变量分为4类:降低模型性能明显的干扰信息变量,降低模型性能不明显的无信息变量,提高模型性能不明显的弱信息变量和提高模型性能明显的强信息变量。IRIV可以有效地提出干扰信息变量和无信息变量,并保留弱信息变量和强信息变量[18]。IRIV采用BMS从变量空间进行随机采用,对于每个变量,IRIV观察其在所有变量组合中的包含与排除是交叉验证均方根误差(root mean square error of crossvalidation,RM-SECV)的差异,而其他变量的状态(包含或排除)保持不变。每个变量的重要性是根据RMSECV的差异来评估的。如果当RMSECV被排除在变量组合之外时,RMSECV会增加,这表明该变量是有用的和信息丰富的。不断重复排除策略,直到变量子集中不包含干扰信息变量和无关信息变量。
1.4.3 混合特征提取方法 VCPA采用EDF方法快速剔除变量,最终筛选出的变量数通常较少,一些信息变量可能会被剔除;而IRIV方法充分考虑到每个变量的重要性,因此需要大量的计算时间,当面对大量的变量时,会耗费大量的时间,导致计算效率低下。VCPA−IRIV混合方法能够充分发挥两种方法各自优势、弥补不足。首先采用VCPA进行快速缩小变量空间,设置最终剩余变量数为N;然后再通过IRIV评估剩余变量空间中每个变量的重要性,以优选出最佳变量子集。
1.5 模型建立与评价
采用线性PLS和非线性随机森林[19]建立茶叶滋味品质成分检测模型,采用相关系数(R)评价模型预测值与实验值之间的相关程度,其值范围为0~1,且越接近1越好;以训练集均方根误差(root mean square error of calibration,RMSEC)评价模型训练误差,预测集均方根误差(root mean square error of predic-tion,RMSEP)评价模型预测误差,其值越小越好;以预测集相对分析误差(relative percent deviation,RPD)评价模型性能可靠程度。如果RPD大于3.0,说明模型性能可靠,预测精度好,可用于实际检测;RPD在2.5~3.0,说明模型可靠性有待提高,只能用于实际估测;RPD在2.0~2.5,模型可以近似定量预测;RPD值小于2.0,方法预测不可靠。
2 结果与分析
2.1 光谱特征提取
采用Kennard−Stone(KS)方法将93个样本划分为训练集和测试集,60个样本作为训练集用于训练模型,其余33个样本为预测集预测模型性能。利用VCPA−IRIV在训练样本集上进行特征提取,VCPA−IRIV方法超参数EDF剩余变量数设置为100,迭代次数为50,最优子模型的比例为10%,BMS运行次数为1 000,并采用5折交叉验证进行变量重要性评价。通过VCPA−IRIV方法最终优选出18个光谱特征,图3所示为特征变量选择结果,图中“★”所标记光谱特征为算法优选的变量子集。从光谱图(图1)可知光谱在5 155 cm−1和6 900~7 140 cm−1处分别存在与H2O的O−H第一泛音和H2O中O−H基团的拉伸变形结合有关的强吸收带。如果用这些强吸收光谱变量来建立校正模型,会影响模型的性能。然而,VCPA−IRIV方法所选的特征变量很好地避开了与H2O强相关的光谱特征信息,表明该方法所提取特征的有效性。
表1所示为采用VCPA−IRIV算法选择的18个光谱特征及其对应的键,其中9 889.177,9 862.179 cm−1为茶多酚与氨基酸上N−H的二级倍频吸收峰,8 759.096,8 782.237,8 882.518,8 535.394 cm−1为茶多酚与氨基酸C−H的二级倍频吸收峰,5 904.965,5 951.248,6 032.244,6 124.81,6 225.09,6 255.946,6 263.66 cm−1为C−H和S−H的一级倍频吸收峰[20],表明VCPA−IRIV方法提取的光谱特征信息可用于茶叶滋味品质指标酚氨比的有效预测。
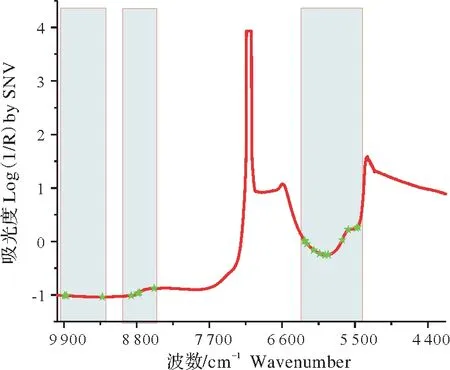
图3 利用VCPA−IRIV选择特征变量结果Fig.3 The result of features selected by VCPA−IRIValgorithm

表1 采用VCPA-IRIV算法选择光谱特征及其对应的键Tab.1 Selected spectra intervals by VCPA-IRIV algorithm and their corresponding bonds
2.2 RF预测模型建立
采用VCPA−IRIV方法提取的特征变量,建立随机森林绿茶滋味品质指标酚氨比预测模型。设置RF算法的超参数回归数棵数(ntree)为1 000,节点分裂候选变量数(mtry)为所有变量数的1/3,即为6。图4所示为训练集和测试集中各样本的实验值与RF模型预测值对比图。由图4可知,RF模型训练集的Rc和RMSEC为别为0.949,0.231;测试集的Rp和RMSEP分别为0.943和0.232,表明模型具有较好的泛化性能。测试集的RPD为3.019,说明模型性能可靠,预测精度好,可用于实际检测。

图4 训练集(a)和测试集(b)中样本实验值与预测值对比图Fig.4 Comparison of experimental and predicted values of samples in calibration set(a)and prediction set(b)
2.3 模型性能比较
为了进一步表现VCPA−IRIV方法提取光谱特征的有效性,采用竞争性自适应重加权算法[21](com-petitive adaptive reweighted sampling,CARS)和连续投影算法[22](successive projections algorithm,SPA)进行光谱特征选择比较。表2所示为基于VCPA−IRIV、CARS和SPA提取的特征所建立的PLS与RF预测模型性能比较结果。结果表明,CARS和SPA提取的光谱变量中均集中H2O的强吸收带(5 155 cm−1和6 900~7 140 cm−1)附近,以这些变量作为输入所建预测模型的预测效果均较差。VCPA−IRIV提取的光谱变量所建的预测模型中,线性PLS预测模型主成分为10时,模型性能最佳,训练集的Rc和RMSEC为别为0.920,0.256;测试集的Rp和RMSEP分别为0.907和0.307;测试集的RPD为2.281;表明非线性的RF模型在鲁棒性和泛化性能上均优于线性的PLS模型。
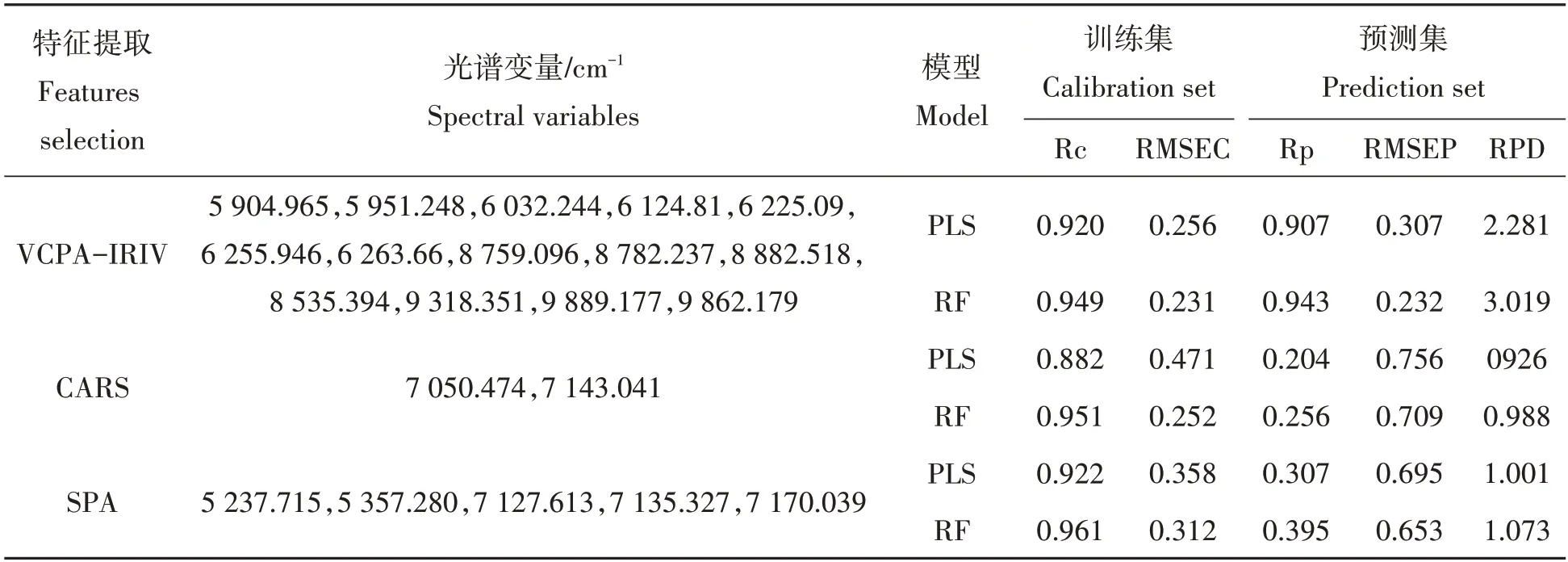
表2 VCPA-IRIV、CARS和SPA提取的特征所建不同预测模型性能比较Tab.2 Comparison of results based on different models based on VCPA-IRIV,CARS and SPA
3 结论与讨论
本研究利用近红外光谱技术结合化学计量学方法实现绿茶滋味品质指标酚氨比值的快速检测方法。绿茶浸出物近红外光谱信息中,H2O的强干扰信息及其他冗余信息的引入将严重影响绿茶滋味品质指标酚氨比的检测模型性能。利用VCPA−IRIV、CARS和SPA 3种不同特征提取方法对近红外光谱变量进行优选,CARS和SPA提取的光谱变量中均集中H20的强吸收带附近,而VCPA−IRIV方法提取的18个特征光谱变量大多与茶多酚和氨基酸相关,很好地避开了H20的强吸收带。
此外,近红外光谱根据当样品被辐射时复杂有机物中不同的化学键吸收或发射不同波长光的原理对分析物进行检测,由于有机物的分子有各种各样的振动和化学键,它们的光谱响应通常并非简单的线性耦合在一起,分析物浓度和光谱数据常常呈现非线性关系[23]。利用非线性RF所建绿茶滋味品质指标酚氨比值快速检测模型性能明显优于线性PLS模型。VCPA−IRIV优选的18个特征变量作为输入建立的非线性RF模型性能最佳,训练集Rc和RMSEC为别为0.949,0.231;测试集的Rp、RMSEP和RPD分别为0.943、0.232和3.019。研究表明VCPA−IRIV方法能够有效的提出有效光谱变量,消除冗余光谱信息;为利用近红外光谱技术对绿茶滋味品质指标酚氨比值快速检测方法提供了新的研究思路,且有助于光谱技术在农产品品质与安全上的推广运用。
猜你喜欢
茶叶通讯(2022年2期)2022-11-15 08:53:56
北京航空航天大学学报(2022年8期)2022-08-31 08:58:58
家教世界(2021年4期)2021-03-09 15:35:38
创造(2020年5期)2020-09-10 09:19:22
学生天地(2019年31期)2019-08-25 08:54:28
数位时尚(幼儿教育)(2018年3期)2018-04-12 05:32:47
快乐语文(2018年36期)2018-03-12 00:56:02
中国光学(2015年5期)2015-12-09 09:00:28
食品工业科技(2014年23期)2014-03-11 18:18:54
无机化学学报(2014年1期)2014-02-28 17:30:08
