
基于MATLAB的字符识别及其在化探野外资料整理中的应用
2021-01-08 05:30:36聂小力罗敏玄戴亮亮
资源信息与工程 2020年6期
聂小力, 张 涛, 罗敏玄, 吴 丰, 戴亮亮, 李 新
(中国地质调查局长沙自然资源综合调查中心,湖南 长沙 410600)
0 引言
在物化探野外工作中,常需将手写的记录表转化为电子文档以便入库管理,但现阶段尚无此类专业软件,因此开发能实现这一功能的程序很有必要。本文选用MATLAB来做图像处理[1],将图片文件转化为与之对应的矩阵,通过对矩阵进行处理运算便可起到处理图像的效果,这把字符识别问题转化成了数学问题,极大程度简化了研究内容。
研究过程中首先对图片进行预处理,将需提取信息的部分识别出来并进行剪裁,将彩色图像灰度化转为灰度图像,再对图像中的无用信息进行去噪处理。然后将灰度图转为二值图像,进行切割后得到单个字符的特征矩阵。最后利用模板比对法,通过相关性大小最终确定字符信息。
1 字符识别原理及算法流程
本文采用光学字符识别(OCR)的方法来进行字符识别,主要分为图像预处理、图像分割、文字识别三个步骤。图像预处理即将原始图像转化为非黑即白的二值图,并去除噪声,然后分割剪裁得到单个字符特征矩阵,最后利用模板比对法确定字符信息。
具体算法流程图如图1所示。
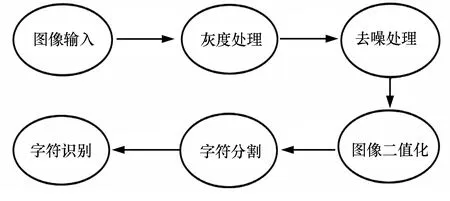
图1 算法流程图
2 字符识别的MATLAB实现
考虑到字符识别的一些处理步骤可合并到一起,故从三个环节来说明字符识别的MATLAB实现方法,分别是图像预处理、图像切割和字符识别[2]。
2.1 图像预处理
图像预处理主要包括去噪和二值化,通过预处理后的图像便可得到待识别字符的特征矩阵。对图像而言,常见噪声有两种,一种是高斯噪声,即概率密度函数服从高斯分布的噪声;另一种是随机出现的脉冲噪声,在图像上表现为无规律分布的白点或黑点。首先利用imnoise函数对示例图像分别加入这两种噪声。imnoise(f,′gaussian′,m,v)为加入高斯噪声的程序语句,其中f为输入图像,单引号内部为所需添加噪声的类型,m和v分别为所加高斯噪声的均值和方差。imnoise(f,′salt&pepper′,d)为加入脉冲噪声的程序语句,其中d为脉冲噪声的噪声密度。对每种噪声都采用中值滤波和算术均值滤波两种方法做去噪处理,并对比效果,如图2所示。核心程序语句及去噪效果如下:
img=imread(′程序实现方法举例.jpg′);
I_gray=rgb2gray(img);%转换为灰度图
I_GaussNoise=imnoise(I_gray,′gaussian′);%加入高斯噪声
I_SaltPepperNoise=imnoise(I_gray,′salt & pepper′,0.02);%加入脉冲噪声
g1=medfilt2(I_GaussNoise);%中值滤波
g2=medfilt2(I_SaltPepperNoise);%中值滤波
i=[111;111;111];
i=i/9;%定义9点模板
g3=conv2(I_GaussNoise,i);%算术均值滤波
g4=conv2(I_SaltPepperNoise,i);%算术均值滤波

图2 高斯噪声及脉冲噪声处理效果对比图
由图2可知,对高斯噪声而言,中值滤波处理能力不及算术均值滤波,但对脉冲噪声处理而言,中值滤波比算术均值滤波的效果好很多,故对不同类型噪声需选取不同去噪方法,多次滤波往往效果更好。
经去噪的图像即可转为二值图以作后续处理。首先利用graythresh函数,利用最大类间方差法找到二值化图片的最佳阈值,再利用im2bw函数将原图转为二值图。
img=imread(′已去噪图像.jpg′);
I_gray=rgb2gray(img);%转换为灰度图
thresh=graythresh(I_gray);%最大类间方差计算阈值
I_bw=~im2bw(I_gray,thresh);%灰度图转二值图
二值化后图像如图3(a,b)所示。

图3 图像预处理及图像切割效果图
2.2 图像切割
图像切割分字符切割和边界拓展两部分,横纵两方向进行。考虑到手写习惯都是由左至右横向书写,因此首先按行对图像进行遍历后可剪裁掉不包含字符信息的空白行,然后利用bwlabel函数,按8连通来识别连通区域,再分别对各连通区域进行切割,以得到单字符图像。
由于切割是沿字符边缘进行的,为提高后续模板比对的准确率,我们对切割后的图像做边界拓展,使字符信息位于图像正中并沿上下左右四个方向分别外延相同像素点,再用imresize函数对图像尺寸做归一化处理。具体程序语句如下:
[a,b]=size(I_bw);
k=1;
for i=1:a
temp=sum(I_bw(i,:));
if temp==0
backline(k)=i; k=k+1; %横向切割去除上下白边
end
end
I_bw2=I_bw;
I_bw2(backline,:)=[];
[L,Ne]=bwlabel(I_bw2);
for n=1:Ne%纵向切割分割单一字符
[r,c]=find(L==n);
n1=I_bw2(min(r):max(r),min(c):max(c));
[height,width]=size(n1);
h=fix(height/3);w=fix(width/3);
n2=zeros(2*h+height,2*w+width);
for i=1:height%边界拓展及尺寸归一化
for j=1:width
n2(h+i,w+j)=n1(i,j);
end
end
strname1=[′num′,num2str(n),′1′]; strname2=[′num′,num2str(n),′2′];
strname1=imresize(n1,[50 50]); strname2=imresize(n2,[50 50]);
end
程序运行结果如图3(c,d,e)所示。
2.3 字符识别
经图像预处理、切割及尺寸归一化后便可得到单一字符的特征矩阵。特征矩阵中只有0和1两种元素,再利用corr2函数逐一对特征矩阵及字库模板做相关性分析,相关性最高的模板便为字符信息。
3 字符识别在物化探资料整理中的应用
本文借助以上基于MATLAB编写的字符识别程序,以大别山区某项目土地质量地球化学调查中的野外采样记录卡为处理对象,从手写区范围标记、识别区剪裁、文字识别以及电子表格自动填写四个步骤,系统编写了由原始表格到电子表格的自动转化程序,大大提高了资料整理的工作效率。
3.1 手写区范围标记、识别区剪裁及文字识别
由于野外记录表格式固定,首先利用鼠标交互方式,调用getPosition函数获取手写区的范围及其坐标位置,并保存至模板文件。具体语句如下:
Mat=imread(′表格模板.jpg′);
imshow(Mat);
for i=1:43
mouse=imrect;
pos(i,:)=getPosition(mouse);% x1 y1 w h
ROI.pos(i,:)=[pos(i,1) pos(i,2) pos(i,3) pos(i,4)];
CutPic=imcrop(Mat,ROI.pos(i,:));
imwrite(CutPic,[′./temp/num′,num2str(i),′.jpg′]);
end
获得了手写区范围模板文件后便可利用CutPic函数对识别区进行剪裁,图4上方为手写的野外记录表,下方为通过程序自动剪裁得到的单个单元格的图像。保存单个单元格图像,依次进行识别即可得到表格中各记录属性的内容。

图4 识别区剪裁效果图
以输水方式属性为例,切割后的图片经上述各过程后可得到单个字符的特征矩阵,其中红色标记的位置即为二值化处理后赋有文字信息的像素点,可看到单个字符的特征矩阵能很好地反应字符信息,具体效果如图5所示。在此基础上进行模板比对即可得到对应字符内容。

图5 文字剪裁及特征矩阵获取
3.2 电子表格填写
通过以上字符识别已得到各属性的内容,将其写入电子表格中即可完成手写表格到电子表格的转换。利用xlswrite函数即可完成这一过程,具体程序代码如下:
samplename=[′化探表格模板.xls′];
pointNum=cellstr(ROI.text(7));
newfilename=[pointNum,′.xls′];
copyfile(samplename,newfilename);
for i=1:size(ROI,1)
a=floor(i/3);
b=mod(i/3);
c=[′A′,′B′,′C′,];
position=[c(b),num2str(a)];
xlswrite(newfilename,cellstr(ROI.text(i)),′Sheet1′,position);
end
4 结论及讨论
MATLAB因其强大的数据处理功能在各行业得到了广泛应用。本文以MATLAB编程语言为基础,利用光学字符识别(OCR)的方法实现了字符识别这一过程。以土地质量地球化学调查的野外记录表为例,证明通过MATLAB实现手写表格到电子表格的快速转化。但是由于不同作业人员字迹的多样性,使得字符识别的准确性受到了一定影响,可进一步优化字符识别算法以及扩大模板字库量两个方面来解决识别准确率不够高的问题。
猜你喜欢
学苑创造·A版(2024年5期)2024-06-10 21:55:57
科学大众(2022年17期)2022-09-22 01:37:30
故事作文·低年级(2021年12期)2021-12-21 23:04:39
作文成功之路·小学版(2020年7期)2020-08-24 08:19:18
电子制作(2018年18期)2018-11-14 01:48:08
小学生优秀作文(高年级)(2018年4期)2018-09-11 01:23:30
新闻传播(2018年10期)2018-08-16 02:10:08
成都信息工程大学学报(2017年3期)2017-11-09 02:56:12
湖南城市学院学报(自然科学版)(2016年2期)2016-12-01 04:06:38
华东理工大学学报(自然科学版)(2015年2期)2015-11-07 09:16:29
