
基于BIM-DB仿真和LS-SVM的建筑能耗预测
2021-01-06 01:02吴贤国邓婷婷陶妍艳
土木工程与管理学报 2020年6期
吴贤国,邓婷婷,陈 彬,陶妍艳,王 雷
(1.华中科技大学 土木与水利工程学院,湖北 武汉 430074;2.武昌首义学院 城市建设学院,湖北 武汉 430064)
近些年来,我国建筑业能耗在不断上升,从2009年到2017年,建筑业能源消费总量由4712万t标准煤大幅度增加至8555万t标准煤[1]。而在建筑运营阶段,外围护结构对建筑能耗的影响占一半以上,因此,基于建筑外围护结构对建筑能耗进行研究具有重要意义,在设计阶段以外围护结构对建筑能耗进行预测,可以较大程度提高建筑能耗优化效率并提供数据依据,以达到节能目标。
对建筑进行建筑能耗预测最主要的两个步骤为:获取建筑能耗数据和进行建筑能耗预测分析。从国内外研究来看,对于设计阶段的建筑,建筑能耗数据获取方式主要有两种,分别为能耗计算和数值模拟。Lin等[2]利用建筑能耗经验公式求出围护结构与建筑能耗的关系,并对办公建筑能耗进行优化分析;Zhang[3]建立了可能影响节能效果的数学模型,其中需要优化的参数多取自经验公式。Naderi等[4]为了对智能遮阳百叶窗的结构规格和控制参数进行优化,使用EnergyPlus进行仿真,利用JEPLUS识别目标函数;Zemero[5]等使用EnergyPlus输出最小化年度能耗和输出建筑最小建设成本。以上获取数据的方式均能得到比较完整的数据,但是利用能耗计算获取数据会有很大的工作量,而仅数值模拟有可能会导致较大误差。
国内外许多学者采用了多种方式进行建筑能耗预测。樊丽军[6]针对城市建筑节能,提出一种基于多元线性回归的建筑能耗预测模型,证实了此模型评估后实施改善措施后建筑的节能潜力。陈彦熹等[7]通过监测绿色办公建筑HVAC系统获取实际能耗数据,证实了分类多层感知器神经网络预测模型效果最好。Zhong等[8]利用建筑夏季逐时冷负荷数据作为能耗数据,提出了一种基于向量场的支持向量回归方法,结果表明,该方法在精度、鲁棒性和泛化能力方面均优于常用方法。以上研究在建筑能耗预测方面均有所贡献,但是预测精度无法达到要求,在建筑设计阶段对建筑能耗进行预测分析时可能会存在较大误差。
本文以某栋拟建教学楼为例,以围护结构参数为研究对象,利用正交试验,基于BIM(Building Information Modeling)和DesignBuilder获取建筑能耗仿真模型并获取能耗数据集,这样可以在减少工作量的前提下,利用BIM可视化及优化性提高仿真数据的准确性;然后利用LS-SVM模型对建筑能耗仿真数据进行预测;最后与其他三个预测模型进行预测精度对比,验证LS-SVM(Least Squares Support Vector Machines)模型的可靠性和适用性,为建筑能耗预测提供一种新思路。
1 方法及原理
1.1 DesignBuilder建筑能耗模拟
1.1.1 建筑能耗模拟软件
随着计算机技术的不断进步,计算机在建筑能耗模拟方面的应用也越来越广泛。在国外,使用DOE-2,EnergyPlus,ECOTECT以及DesignBuilder进行能耗模拟最为频繁。在国内,建筑能耗模拟软件以DeST和PKPM为主。这六个建筑能耗模拟软件都有各自的功能特点,其中DesignBuilder和EnergyPlus是这几个软件中功能最齐全的,既可以进行能耗的动态模拟,又可以对自然通风、照明以及热舒适度进行设计计算。DesignBuilder和EnergyPlus两个软件中,DesignBuilder存在图形界面,即在进行能耗分析时,可以显示出建筑模型的大致结构,便于使用者运用软件。
综上可得,为了更加全面且形象地进行建筑能耗模拟,本文利用DesignBuilder软件进行建筑能耗模拟是一个比较好的选择。
1.1.2 DesignBuilder软件
DesignBuilder软件的能耗计算原理为热平衡法,采用这种方法可以准确获取建筑能耗热平衡方程。在求外围护结构热传递时,运用的方法为热传导传递函数系数法(Conduction Transfer Function,CTF)。CTF是反应系数法的一种,这个方法的核心是求解所在区域的空气热平衡方程,在方程中所利用的温度是一种基于墙体内表面的温度而非室内空气的温度,故计算结果会更加接近实际值,其中区域热平衡方程为:
E=Q1+Q2+Q3+Q4+Q5
(1)
式中:E为存储于区域空气中的总能量,即空气热容;Q1为总内部对流负荷;Q2为区域表面对流换热;Q3为区域内空气混合所致的热交换;Q4为外部空气渗透造成的热交换;Q5为系统热量输出。
1.1.3 基于BIM和DB的建筑能耗模拟
由于BIM技术具有可视化、协调性、模拟性、优化性等特点,以BIM技术为核心的各种软件为绿色建筑分析自动化、智能化提供了基础和平台。因此,本文基于BIM模型进行建筑能耗分析,将Revit生成的rvt模型文件转换为gbXML格式文件之后导入Designbuilder软件生成skh格式的模型,在Designbuilder软件中对模型的相应参数进行设置,便可对建筑模型的能耗进行计算。
1.2 最小二乘支持向量机
支持向量机模型可以很好地克服非线性问题,具有全局性并适用于小样本研究[9]。在处理非线性的优化过程中,为了解决泛化性能较差的问题,可以引入希尔伯特空间,并利用函数φ(x)把样本数据映射至空间中,再通过核函数达到函数线性化的效果,就可以利用线性支持向量回归机解决问题。非线性支持向量机得到最优的非线性回归函数为:
(2)

最小二乘支持向量机(LS-SVM)对传统的SVM进行了改进,采用最小二乘线性系统作为损失函数,将SVM中优化问题的不等式约束转化为等式约束。设训练的样本集为:(xi,yi),xi∈Rn,yi∈{-1,+1},i=1,2,…,N,其中N为训练样本的总数,n为样本空间的维数,y为样本的类别标签。根据结构风险最小化原则,LS-SVM的分类问题的最优分类面由下面的优化问题得到[4]:
(3)
式中:φ(·)为非线性映射;ω为权重;ξi为误差变量;c为惩罚系数,c>0。于是,LS-SVM的优化问题所对应的Lagrange函数为:
(4)
式中:ai为Lagrange乘子,ai>0,i=1,2,…,N。对式(2)(3)进行优化,令L对ω,b,ai,ξi的偏导数等于0,然后化简可以得到以下方程:
(5)
式中:Z=(φ(x1)Ty1,φ(x2)Ty2,…,φ(xN)TyN);Y=(y1,y2,…,yN);mN=[1,1,…,1];定义Ω=ZZT=[qij]N×N,利用Mercer条件可得qij=yiyjφ(xi)T,φ(xj)=yiyjK(xi,xj),K(xi,xj)为核函数。用最小二乘法即可求解式(5)。
通过以上公式的推导,LS-SVM的分类回归问题可以通过求解以上的线性矩阵方程获得,综合以上几个式子得到最优回归函数f(x)为:
(6)
1.3 基于BIM和DB的建筑能耗数据获取
将建筑物的BIM模型导入Designbuilder中,并分别输入经正交试验得到的试验方案,进行各外围护结构参数处在不同水平下的建筑能耗模拟,输出n组Designbuilder中获取的建筑能耗结果,作为下面建立基于LS-SVM建筑能耗预测模型的输入原始数据集。
1.3.1 基于BIM和DB建筑能耗模型获取
BIM技术具有可视化、协调性、模拟性、优化性等特点,以BIM技术为核心的各种软件为绿色建筑分析自动化、智能化提供了基础和平台。因此,本文基于构建BIM模型进行建筑能耗分析,将Revit生成的rvt模型文件转换为gbXML格式文件之后导入Designbuilder软件生成skh格式的模型,在Designbuilder软件中对模型的相应参数进行设置,便可对建筑模型的能耗进行计算。
1.3.2 建筑能耗模拟参数选取
在影响建筑能耗的因素之中,外围护结构设计参数对建筑能耗所产生的影响值最大[10],因此本文将选取与建筑能耗水平相关性较强的6个建筑围护结构设计参数:外墙综合传热系数、外墙太阳辐射吸收系数[11]、屋面综合传热系数、屋面太阳辐射吸收系数、外窗综合传热系数、窗墙比[12]进行研究。表1给出了选取的外围护结构设计参数及依据。
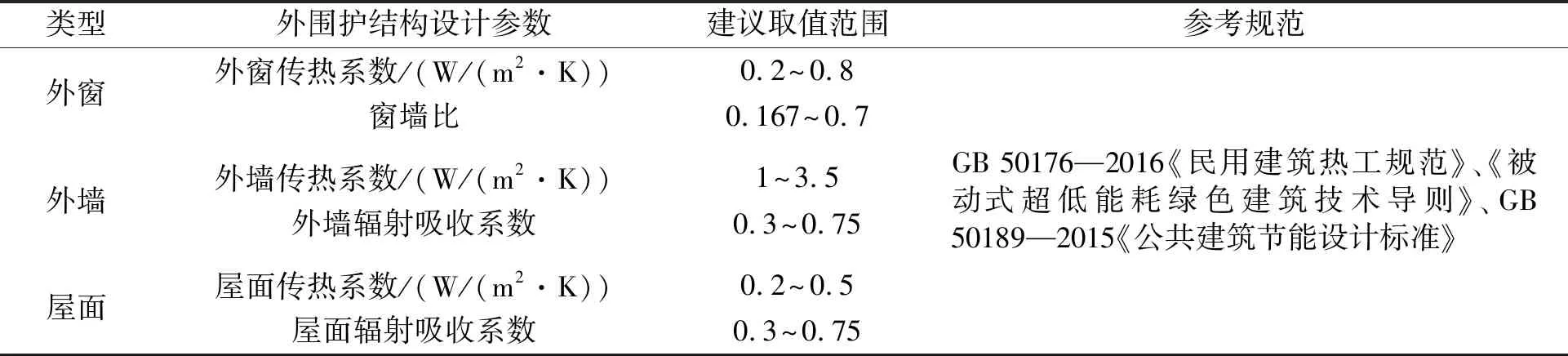
表1 外围护结构设计参数及依据
1.3.3 基于Allpairs正交试验数据集获取
正交试验设计方法是一种在概率论、数理统计和实践经验的理论背景下,以获得优化设计方案的方法[13]。它在满足试验科学性的同时,也能顾及到试验的工作量以及复杂程度。因此选择正交实验设计获取建筑外围护结构设计参数的模拟数据,依据表1中每个围护结构设计参数的建议取值范围对因子水平进行合理划分,采用Allpairs软件获取正交设计水平表,在一定程度上保证所研究方案的齐整度与分散性,避免重复与缺失。
1.4 基于LS-SVM模型的建筑能耗预测
1.4.1 数据预处理
数据预处理主要是对建筑能耗数据进行归一化,以避免样本中一些数据过大或过小,增加训练过程中算法的负担,导致数据被淹没或网络不收敛。数据归一化可以使所输入数据处于一定区间内,如[0,1][-1,1],消除了不同样本特征值维数对预测效率和精度的影响。由于将数据归一化到区间[-1,1]上时,比区间[0,1]更能避免淹没输入向量的特征,因此本文选择将样本输入数据归一化到区间[-1,1]。本文利用式(1)将输入变量和输出能耗统一到[-1,1]区间,实现数据归一化、统一变量维度,使得每个特征在预测过程中起到效果。
(7)
式中:y为归一化之后的标准值;ymax,ymin分别默认取1,-1;x为样本值;xmax,xmin分别为样本值的最大值和最小值。
完成数据预处理之后,对原始样本集进行划分,随机选取约4/5的样本作为训练集,用来LS-SVM建筑能耗预测模型的训练,剩下五分之一的样本作为测试集,用来检验LS-SVM建筑能耗预测模型的泛化性能和预测精度。
1.4.2 参数优化
(1)核函数选择
核函数对支持向量机预测精度有很大的影响。对于非线性问题,为了得到泛化性能良好的函数,可通过核函数将其转换成线性问题进行研究。在不同预测模型中,应根据研究特点选择合适的核函数。由于高斯核函数在具有径向基核函数优势的同时,还具有良好的抗干扰能力,本文将采用高斯核函数作为预测模型的核函数进行研究,其表达式为[14]:
(8)
式中:xi为输入变量;x为输出变量。
(2)参数优化
确定核函数后,需要选择宽度参数σ2和惩罚系数c,因为这两个参数均会较大程度影响支持向量机的泛化水平。如果宽度参数σ2太小,会导致过度学习;如果宽度参数σ2太大,会导致学习不足,使泛化能力超出合理范围;而惩罚系数c对泛化水平的影响与宽度参数σ2恰好相反,因此,合适的参数选取方法和参数选取结果验证方法就显得十分重要。
目前常用枚举法、网格搜索法、粒子群优化算法进行模型参数选取[15]。网格搜索法是一种全局搜索法,即将各个参数所有可能的组合结果列出并生成“网格”,然后高效地通过搜寻网格中所有结果来确定最优解。与遗传算法、粒子群算法相比,网格搜索法难以造成局部最优的情况,也不会像枚举法一样耗费较多时间。因此,本文将采取网格搜索法进行参数选取。
K折交叉验证常用于支持向量机模型性能的验证[16],它将原始样本集分为K个样本子集,其中随机选取1个样本用来测试,剩余K-1个样本用来训练,交叉验证重复k次,平均k次结果获得估测,可以避免欠学习状态或避免过学习状态。因此选择K折交叉验证方法,对网格搜索得到的参数组合进行寻优,确定使模型精度最高的参数为最优参数。
1.4.3 预测精度分析
采用常用的评价准则对LS-SVM预测模型进行性能评价,主要涉及到两个指标:均方根误差RMSE和拟合优度R2。均方根误差RMSE体现预测值与真实值的离散程度,而拟合优度R2用于验证预测值与真实值之间的拟合程度,两个指标分别由公式(3)(4)给出:
(9)
(10)
2 案例分析
2.1 工程背景
某地的一所高校将新建一栋教学楼,该教学楼的选址位于高校的西南角,建筑用地面积为33350 m2,占地面积为11573 m2,总建筑面积达40318 m2,容积率为1.217。
该建筑将以电力为能源,采用中央空调系统调节室温。上述区域被划分为教室制冷,温度设置为26℃,制冷起始温度(即外部气温超过该温度则开始自动制冷)为29℃;采暖温度设置为25℃,采暖起始温度(即外部气温低于该温度则开始自动采暖)为10℃。教师休息室区域制冷温度为26℃,采暖设置为25℃;厕所区域和走廊区域都为无采暖和无制冷区域。所有区域照明功率都为8 W/m2。
2.2 基于BIM和DB建筑能耗数据获取
2.2.1 基于BIM和DB建筑能耗模型获取
以教学楼CAD图纸为参照,在Revit中建立教学楼BIM模型后,通过文件格式转换,将模型导入DesignBuilder软件中获得建筑能耗仿真模型,其结构模型如图1所示。去除了地下一层的设计,简化后的建筑模型为5层,故软件模拟出来的建筑总面积为31484.4 m2,建筑总体积为129718 m2。
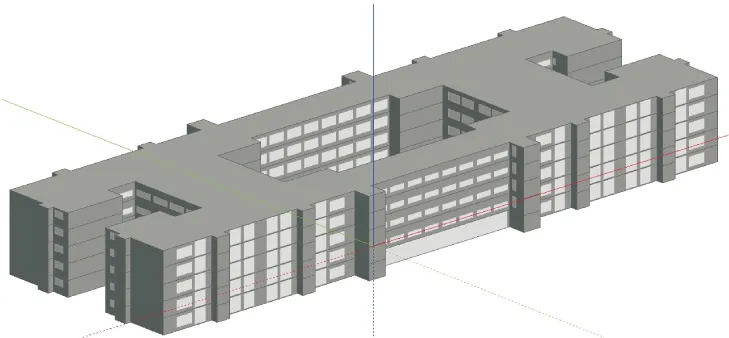
图1 某在建教学楼建筑结构DB模型
2~5层为标准层。为进一步提高模拟速度,对功能相同的相邻房间进行合并处理。将模型建立好之后,对工程概况所提及的相应参数进行设置,便可以进行建筑能耗仿真模拟。
2.2.2 建筑能耗模拟围护结构参数选取
根据1.3.2节中可知,本文将选取6个重要的外围护结构设计参数,分别为:外墙综合传热系数、外墙太阳辐射吸收系数、屋面综合传热系数、屋面太阳辐射吸收系数、外窗综合传热系数、窗墙比,来进行建筑能耗的仿真模拟。
2.2.3 基于Allpairs正交试验数据集获取
本文利用Allpairs软件设计正交表,正交试验的因子数为6,水平数为6,则选用L54(66)正交表,获取正交设计表后,再利用Allpairs软件得到围护结构设计参数正交试验表,然后将每一个正交试验方案依次输入DesignBuilder软件中,模拟得到54组正交试验建筑能耗结果,如表2所示。
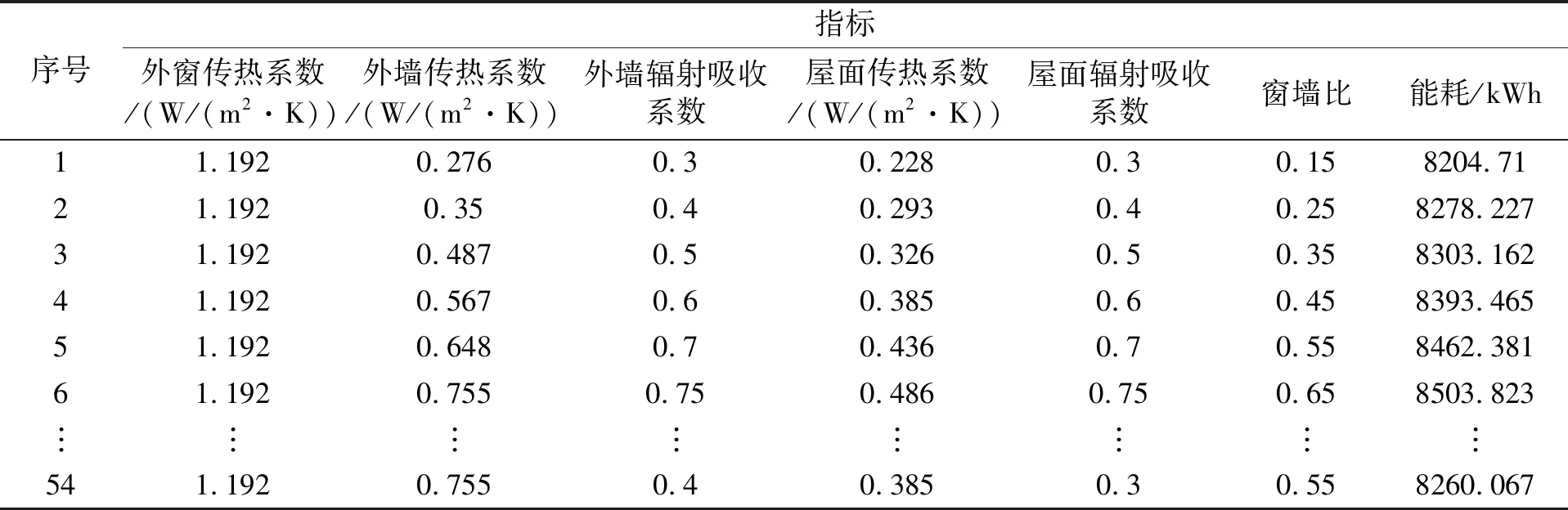
表2 建筑能耗仿真数据
2.3 基于LS-SVM模型的建筑能耗预测
2.3.1 数据预处理
以本工程教学楼为例进行建筑能耗的预测,根据围护结构相关参数分析可得,样本特征中应包含外墙综合传热系数、外墙太阳辐射吸收系数、屋面综合传热系数、屋顶太阳辐射吸收系数、外窗综合传热系数、窗墙比。根据表2正交试验仿真模拟结果可知,建筑能耗仿真结果一共有54组,随机将仿真结果中的42组作为建筑能耗预测的训练集,剩下的12组设作建筑能耗预测的测试集以检验预测效果。当完成建筑能耗围护结构设计参数选择之后,再进行预处理,根据式(1)将建筑能耗数据范围控制在区间[-1,1]之内,使得每个特征都可以在预测过程中起到效果。
2.3.2 参数优化
构建支持向量机预测模型首先需要确定模型的主要参数,为了确认宽度参数σ2与惩罚系数c的最优取值,需要采取网格搜索法进行全局搜索,利用K-CV进行参数验证。首先,将σ2与c的搜索范围均控制在[2-8,28]之内;然后利用所选参数进行寻优,且取k=5,参数寻优结果如图2,3所示。

图2 参数优化结果3D视图
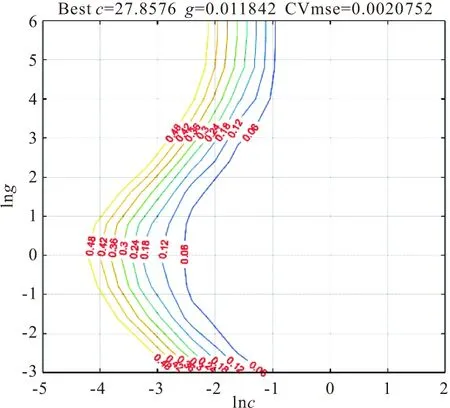
图3 参数优化结果平面图
图2,3分别为参数优化结果3D图和平面图,由两图可知:Bestc=27.8576,g=0.011842,CVmse=0.0020752。含义为:当σ2为0.011842,c为27.8576时,此时经过5折交叉验证得到的测试集的均方误差达到最小值为0.0020752。
2.3.3 预测精度分析
(1)模型预测结果分析
利用上述优化后的参数,进行模型训练,得到能耗预测图如图4,5所示。
从图4可以看出,训练集对建筑能耗进行预测得到的结果与仿真模拟情况基本一致,拟合度R2为0.98304,经计算,训练集中模拟值与预测值之间的均方根误差mse为0.006079,验证了支持向量机预测模型精准的预测效果。图5为测试集预测结果对比,作用是验证训练集预测的模拟效果。可以看出测试集对建筑能耗进行预测得到的结果与仿真模拟情况也基本一致,拟合度R2为0.99267,经计算,测试集中模拟值与预测值之间的均方根误差为0.0069255,充分验证了训练集预测拟合函数的正确性。
因此,依据所选指标所构建的支持向量机能耗预测模型预测精度较高,预测效果良好,可以基于所选指标构建多目标优化模型对能耗进行优化。
(2)模型精度对比分析
将支持向量机预测结果分别同BP(Back Propagation)人工神经网络、小波神经网络以及SVM预测结果进行对比分析,如表3所示。

表3 各预测模型均方根误差及拟合优度
从表3可以看出:在利用不同预测模型对建筑能耗进行预测的结果中,支持向量机模型的均方根误差为0.077,拟合优度为0.9927,其预测精度远远高于其余三类预测模型,进一步验证了支持向量机预测应用在建筑能耗上的优势。
3 结 论
(1)在建筑设计阶段,在Revit中建立教学楼BIM模型后导入DesignBuilder软件中获得建筑能耗仿真模型,进而利用Allpairs正交试验可获取建筑能耗模拟数据,为设计阶段能耗数据的获取提供了一个可行的方法。
(2)本文将外墙综合传热系数、外墙太阳辐射吸收系数、屋面综合传热系数、屋顶太阳辐射吸收系数、外窗综合传热系数和窗墙比等6个主要的围护结构参数作为输入,将54组建筑能耗模拟数据作为输入参数,利用LS-SVM预测模型进行建筑能耗预测,由预测结果可知:预测模型的拟合度高达0.9927,均方差为0.077,体现了LS-SVM预测模型的高精准度。
(3)为了进一步验证LS-SVM预测模型在建筑能耗研究的优势,将其分别与BP人工神经网络、小波神经网络以及SVM三种模型预测结果与支持向量机预测结果进行对比分析,发现LS-SVM预测模型的拟合优度和均方根误差均为最优状态,从而进一步验证了LS-SVM预测模型的可靠性。
猜你喜欢
计算机仿真(2022年9期)2022-10-25
中国建筑金属结构(2022年7期)2022-08-08
昆钢科技(2022年2期)2022-07-08
当代水产(2021年10期)2022-01-12
建材发展导向(2021年19期)2021-12-06
建材发展导向(2021年15期)2021-11-05
建材发展导向(2021年23期)2021-03-08
装饰装修天地(2020年10期)2020-07-04
——以嘉兴市为例
绿色科技(2019年12期)2019-07-15
华人时刊(2018年15期)2018-11-10
