
服装设计知识图谱中的服装装饰工艺分类模型
2021-01-05 06:00:04张远鹏
纺织学报 2020年8期
杨 娟, 张远鹏
(1. 苏州大学 纺织与服装工程学院, 江苏 苏州 215123; 2. 南通大学 纺织服装学院, 江苏 南通 226001;3. 南通大学 智能信息技术研究中心, 江苏 南通 226001; 4. 香港理工大学 电子计算学系, 香港 999077)
知识经济时代是伴随着大数据、物联网、云计算、人工智能、区块链等技术的成熟和相互融合而开始的。随着计算机技术的迅速发展和网络信息数据的爆炸式增长,服装设计资源信息通过数字化、网络化的形式,高速在互联网上传播形成了巨型的知识网,为设计者提供了丰富的素材积累和实时的潮流资讯。就目前对服装设计行业的调研来看,网络资源的利用呈现出2方面的特征:一方面手动检索效率低下,信息的可信度甄选困难,信息反馈滞后;另一方面,海量数据通过各种渠道井喷式涌现,其中所包含的信息鱼龙混杂、良莠不齐,很难快速高效地提取有价值的信息并加以利用。如何解决信息超载与知识饥渴的矛盾,实现服装设计资源的有效检索与利用是当前服装设计领域的关键课题。服装设计资源知识图谱能够从语义层面为设计师提供辅助检索、智能推荐等功能,在服装设计行业具有极高的应用价值。在服装设计资源知识图谱自底向上构建过程中,会面临各类资源的分类问题,其中,文本资源分类尤为常见。
服装工艺作为服装设计的三要素之一,是服装设计得以实现的重要环节。装饰工艺作为其主要的组成部分已经成为展现服装艺术性、时尚性和风格特征的重要手段,促进当今服装设计与服饰审美的多元化呈现,因此,服装设计知识图谱中装饰工艺已成为不可或缺的重要知识资源。在互联网上存在大量有关装饰工艺的文本描述,例如:“在中原地区,印花技术的再度复兴是从缬开始的,缬有绞缬、葛缬和夹缬。绞缬、葛缬实际上就是一种仿染印花的织物……”[1],对于这类文本资源,期望能够自动判断其工艺类别属于刺绣、印染、编结、手绘或镶嵌等其中的一种,因此,智能分类模型不可或缺[2-3]。由于文本资源较为复杂,在进行向量表示后维数高,从单一视角建立分类模型进行分类已很难满足应用需求,故具备多视角协同学习的分类模型应运而生。例如:Jiang等[4]提出一种具备双视角协同学习的分类模型,通过在目标函数中引入各视角决策误差最小的约束实现协同学习,同时引入信息熵学习各视角的权重;张远鹏等[5]提出一种多视角模糊聚类算法,利用各视角代表点一致性约束来实现多视角协同学习。
在目前已有的多视角分类模型中,噪声视角或弱相关视角给多视角分类模型分类结果带来负影响的研究较少。所谓噪声视角或弱相关视角,指的是在其所包含的样本特征空间中,缺乏有效的模式识别信息来训练模型参数。装饰工艺文本在向量化后,每一维特征表示每个特征词,如果将每个特征词看成是一个视角的话,那么在进行多视角分类模型建模时,就必然要考虑如何降低噪声视角或弱相关视角带来的负影响。这是因为一篇装饰工艺文本中肯定存在一些特征词,对其类别判定贡献较小,甚至起到负作用。为此,本文提出一种具备视角约减的多视角分类模型(VR-MV-CM),该模型以经典1-阶 TSK(Takagi-Sugeno-Kang)模糊[6]系统作为基础,引入变体信息熵,控制各视角的权重学习;然后设计约减规则,在VR-MV-CM的目标函数优化过程中,动态约减噪声视角或弱相关视角,对服装装饰工艺文本进行分类。
1 服装装饰工艺文本预处理
本文所使用的服装装饰工艺文本资源来源于表1 所示的站点(仅包含部分)。文本资源的抽取方式采用本文作者2018年所开发的领域模型[7]。在进行装饰工艺文本所属类别判定之前,需要对其进行预处理。预处理的主要过程如图1所示。

表1 服装装饰工艺文本资源部分站点Tab.1 Some of web sites for text recourses describing garment ornamenting craft
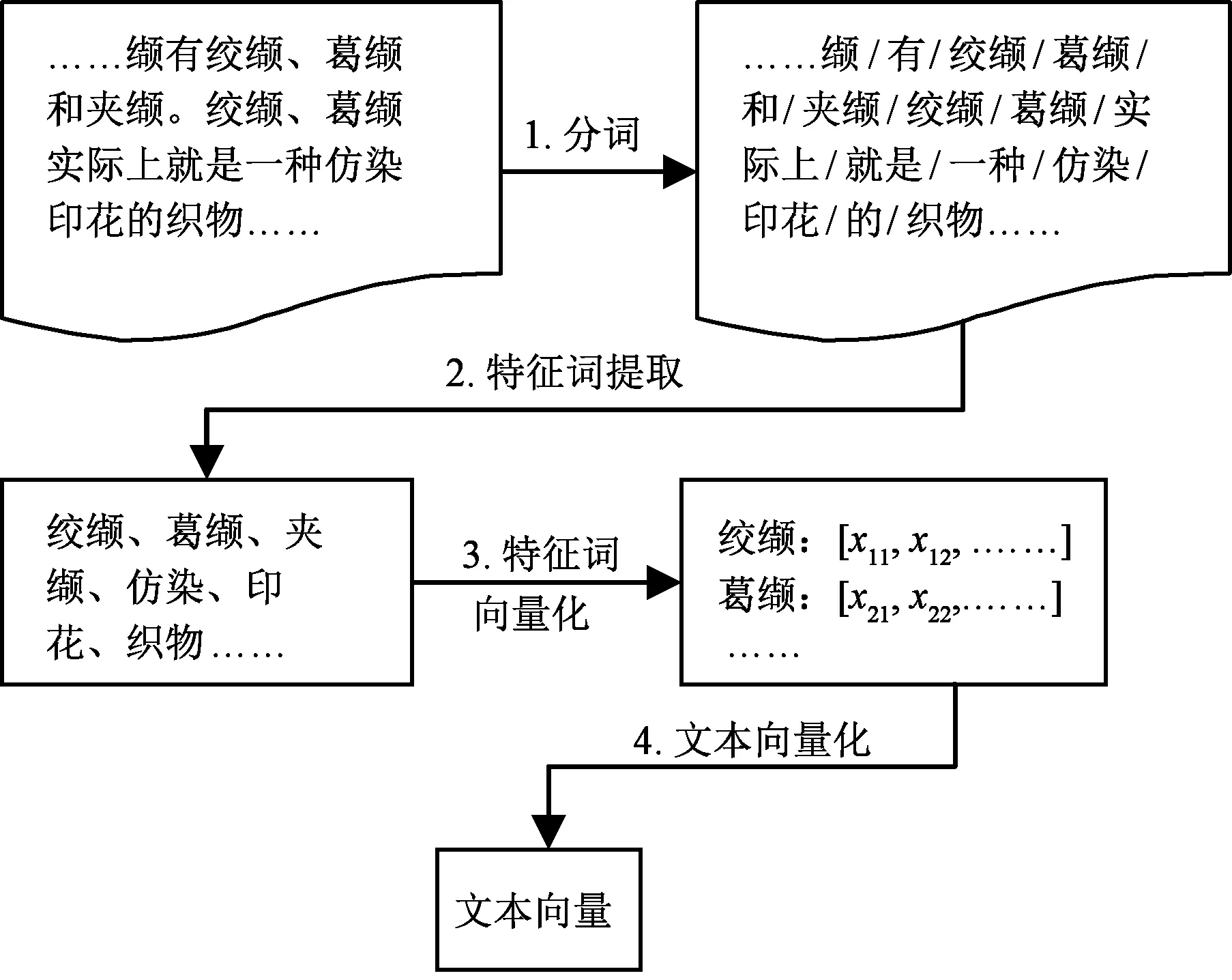
图1 服装装饰工艺文本资源的预处理过程Fig.1 Preprocessing of text recourses describing garment ornamenting craft
从图1可看出,在构建分类器进行装饰工艺文本分类之前,需要进行4个步骤的预处理。1)分词:分词的主要目的是从文本中划分出最小实体表示单位,即词。本文使用中科院提供的分词工具ICTCLA[8]进行分词处理。2)特征词提取:特征词提取的主要目的是从分词结果中提取具有一定代表性的特征词。在本文中,对于分词获取的所有实体词,利用词频-逆文档(TF-IDF)[9]计算权重值并按照权重值从小到大排序,取前60%的实体词作为特征词。3)特征词向量化:特征词向量化的主要目的是利用1组量化的数值(向量)来表示特征词,方便分类模型处理。在本文中,利用Mikolov在2013年提出的Word2vec模型[10]来训练特征词向量模型,进而将特征词向量化。4)文本向量化:文本向量化是在特征词向量化的基础上,利用词向量来表示文本。用于文本向量化的方法有很多,本文采用一种朴素的文本表示方法,即用所有特征词向量的平均值来表示文本。
在将所有的服装装饰工艺文本向量化后,接下来构建分类模型,进行工艺类别判定。
2 服装装饰工艺分类模型
经预处理获得的服装装饰工艺文本向量维数较高,必然存在一些特征对文本分类精度贡献较低,甚至还会产生负影响。如果将每一维特征看成一个视角的话,那么在构建多视角分类模型时,就需要考虑如何约减这些贡献度较低的视角。本文提出一种针对服装装饰工艺文本分类且能够进行视角约减的多视角分类模型。
2.1 多视角协同学习机制

(1)
其中,
(2)
(3)
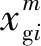
2.2 视角约减机制
在训练数据集D中,可能会存在某些视角(特征)对最终的分类结果产生负影响,因此,需要一种机制来实现对此类视角的自动约减,减少或屏蔽此类视角的负影响。故提出基于变体信息熵的视角权重自适应学习机制来学习各视角的权重,并通过预先设定的规则对视角权重小于某一阈值的视角进行约减,消除他们对分类结果的负影响。对于训练数据集D而言,视角加权的机制可表示为如式(4)所示的形式:
(4)
式中:yic表示第i个文本向量属于第c类;w=[w1,w2,…,wM]表示视角权重向量,其中wm表示第m个(m=1,2,…,M)视角的权重;δm为控制权重wm学习的参数;参数β用于控制Φ的贡献程度,该值由用户指定或者在训练数据集上通过交叉验证的方式得到。
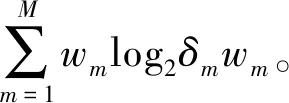
在概率统计领域,通常使用方差均值比(VMR)来观察样本的分散程度,VMR值越小,表示样本越聚集,反之则表示样本越分散。在式(4)中,期望通过第2项,使得包含分散特征的视角能够获得较小的权重,因此,在本文中采用VMR的倒数形式,即均值方差比(RMV)作为δm,来实现对各个视角权重学习的控制。
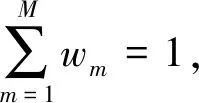
2.3 目标函数及其优化
基于上述协同机制以及视角约减机制,VR-MV-CM 的目标函数可表示为如式(5)所示的形式:
(5)
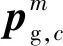
(6)
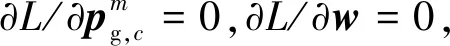
(7)
(8)
(9)
式中:w′m表示更新后的视角权重;M′表示约减后的视角总数。
(10)
3 实验分析
利用本文作者2018年所构建的领域模型[7],从互联网抽取装饰工艺文本文档共5 400篇,并按照图1所示的预处理步骤对所有文本进行向量化。对于5 400个文本向量,选择80%进行人工类别标注,并作为训练文本向量(训练文本示例如表2所示)构建训练数据集,所涉及的服装装饰工艺类别包括5类,分别为“刺绣”“印染”“编结”“手绘”和“镶嵌”,类别标签分别用1、2、3、4、5表示。其余20%作为测试文本向量构建测试数据集。
选择支持向量机(SVM)[11]、C4.5决策树(C4.5)[12]、 1-阶TSK模糊系统(1-TSK-FS)[6]以及Jiang等[13]提出的多视角TSK模糊系统(MV-TSK-FS)作为对比分类模型进行分类结果的比较。SVM、C4.5、1-TSK-FS以及本文提出的VR-MV-CM中的参数均通过在训练数据集上进行5-折交叉验证的方式获取。实验将从3个方面进行:1)对于VR-MV-CM,观察有视角约减和无视角约减(只需将δm设置为0)时在训练数据集和测试数据集上的分类精度;2)观察VR-MV-CM和所引入的对比模型在训练数据集和测试数据集上的分类精度;3)将VR-MV-CM所约减的视角从训练数据集和测试数据集中剔除,用剔除后的训练数据集和测试数据集重新测试对比模型,观察与剔除之前分类精度的变化。

表2 训练文本示例Tab.2 Example of training texts
采用分类精度指标评价实验结果。分类精度定义为正确分类的样本数和总样本数的比值。在训练数据集上的分类精度,称之为训练精度,在测试数据集上的分类精度,称之为测试精度。表3、4分别示出在训练数据集和测试数据集上的实验结果。其精度均为对应模型运行50次的平均值和标准差。
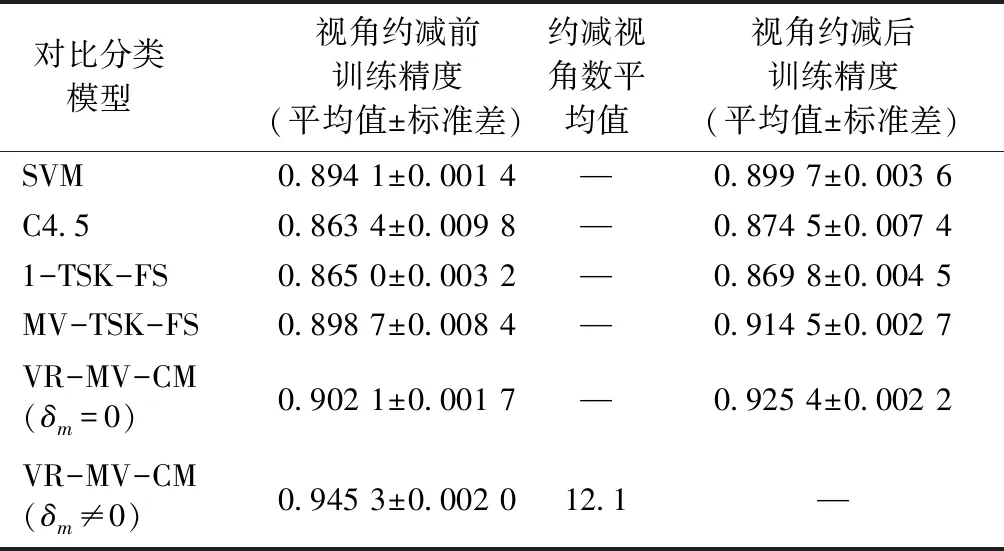
表3 对比分类模型的训练精度Tab.3 Training precison of comparison classification models
从表3、4实验结果可看出,在训练和测试数据集上,VR-MV-CM在约减噪声视角或弱相关视角后,50次的平均分类精度相比约减之前,分别提高了4.32%和2.68%。另外,即使VR-MV-CM未进行视角约减,由于采用了多视角协同学习机制,相比其他单视角决策模型(SVM、C4.5、1-TSK-FS),训练和测试精度仍具有优势。
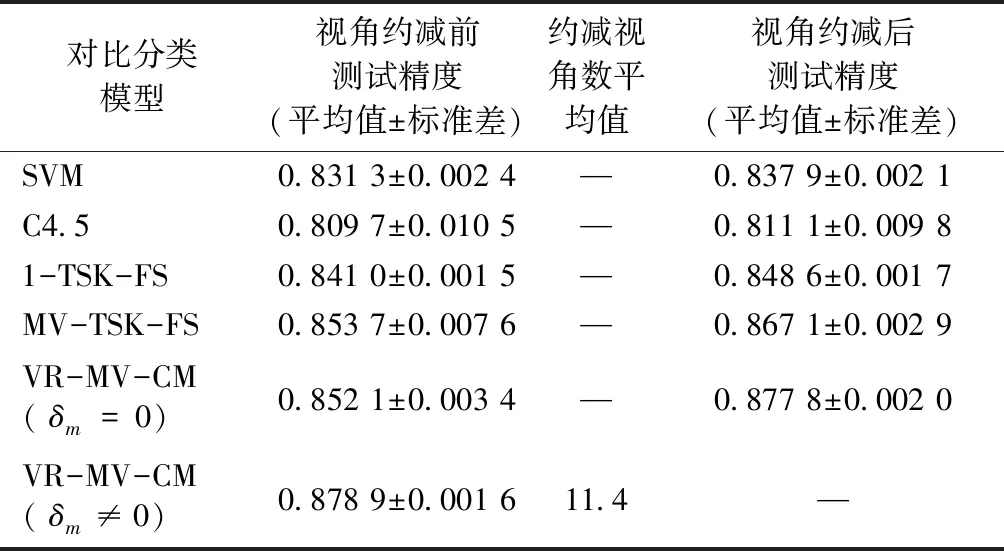
表4 对比分类模型的测试精度Tab.4 Testing performance of comparison classification models
VR-MV-CM在50次运行后,在训练数据集和测试数据集上共约减的视角数的平均值为12.1和11.4。通过将这50次约减的视角交集从测试数据集中剔除,然后重新运行对比算法(包括VR-MV-CM在δm=0时)。从表3和表4的第4列可看出,在剔除噪声视角或弱相关视角后,所有决策模型的训练和测试精度均有所提高,这再次印证了本文所提出的VR-MV-CM进行噪声视角或弱相关视角的有效性。
4 结 论
在服装设计资源知识图谱构建过程中,为判定服装装饰工艺文本的类别,本文提出了一种具备噪声视角或弱相关视角约减功能的多视角分类模型(VR-MV-CM)。该模型综合考虑了视角之间的协同学习以及视角权重的学习,同时利用约减规则过滤权重较低视角。这不仅充分挖掘了视角之间的潜在关联,同时也削减了噪声视角或弱相关视角对于最后分类结果的影响。在服装装饰工艺文本分类实验中,VR-MV-CM能够自动剔除权重较低的视角,相比所引入的对比决策模型,具备更好的分类精度。在后续的研究中,将从文本资源拓展至图像资源,进一步验证模型的功能。
FZXB
猜你喜欢
轻纺工业与技术(2023年5期)2023-11-16 07:13:14
辽宁丝绸(2022年1期)2022-03-29 00:58:56
少年漫画(艺术创想)(2020年8期)2021-01-04 01:43:18
意林(儿童绘本)(2019年12期)2020-01-04 02:10:06
计算机技术与发展(2018年8期)2018-08-21 02:08:14
中国机械工程(2017年22期)2017-12-02 01:52:34
纺织科技进展(2016年3期)2016-11-29 01:27:03
少儿科学周刊·儿童版(2016年2期)2016-03-19 12:01:25
湖南包装(2016年2期)2016-03-11 15:53:11
小学生必读(低年级版)(2016年11期)2016-03-01 06:40:22
