
基于布谷鸟算法优化K_means聚类的缺失数据填充算法*
2020-12-31 00:52林枫蔡延光蔡颢张丽
自动化与信息工程 2020年6期
林枫 蔡延光 蔡颢 张丽
学术研究
基于布谷鸟算法优化K_means聚类的缺失数据填充算法*
林枫1蔡延光1蔡颢2张丽1
(1.广东工业大学自动化学院,广东 广州 510006 2.奥尔堡大学健康科学与工程系,丹麦 奥尔堡 9920)
针对K_means聚类算法对初始参数较敏感且相对容易出现局部最优解的问题,提出基于布谷鸟算法优化的K_means聚类算法,并将优化后的K_means聚类算法与条件均值填充算法相结合,递归地填充缺失数据。实验结果表明:与传统算法相比,基于布谷鸟算法优化K_means聚类的缺失数据填充算法具有更好的效果。
缺失数据;填充;布谷鸟算法;K_means算法
0 引言
数据集在收集与整理过程中,因各种不可控因素导致数据部分属性值缺失,从而对数据质量造成较严重影响且降低数据挖掘效果[1-2]。因此,为提高数据集的分析效果,对其中缺失数据进行填充是至关重要的。常用的缺失数据填充方法有回归插补法、聚类插补法、人工神经网络插补法等。
回归分析是一种基于变量间关系的预测性分析方法,广泛应用于各个领域[2]。回归插补法的基本思想是通过数据中的缺失属性与其余属性的关系建立回归模型,再利用回归模型预测缺失属性的值并进行填充。卜范玉等利用CFS聚类算法对不完整数据集进行聚类,对降噪自动编码模型进行改进,并根据聚类结果,利用改进的自动编码模型对缺失数据进行填充[3]。戴明锋等利用logistic回归算法对数据中的缺失属性值进行填充并取得较好成效[4]。李建更等为解决基因谱的数据缺失问题,提出基于双向核加权回归估计算法,取得较好缺失值填充效果[5]。
在数据挖掘领域,聚类算法是对数据进行分类统计分析的一种经典算法。它通过度量数据间的相似性对数据进行分类划分,使相同类的数据聚集成一类[6]。聚类算法广泛应用于缺失值填充问题,并取得较好效果。史倩玉等为解决不完全数据集的缺失值填充问题,提出一种新的集成聚类算法,该算法规避了传统单一填充算法造成的不良影响并取得较好填充效果[7]。针对传统聚类算法无法准确度量缺失数据间相似性的问题,郑奇斌等将PatDist-PCM与PatClu-PCM相结合,提出一种改进的模糊聚类算法,有效提高了不完全数据集聚类的准确度[8]。
人工神经网络是基于对人脑神经元网络进行抽象处理而建立的一种计算模型[9-12]。神经网络在处理随机数据或复杂数据时具有明显优势,广泛应用于复杂数据集的缺失值填充。毛玫静等针对不完备信息系统的缺失数据填补精度不高的问题,以水产养殖预警信息系统为背景,提出一种基于属性相关度的缺失数据填补算法,该方法在填补准确度和时间性能上有明显提高[13]。姚休义等采用非线性神经网络对缺失数据进行重构并取得较好效果[14]。李武翰等为恢复缺失的音频数据,提出一种基于神经网络的缺失值预测算法,该算法不仅具有较高的处理效率还具有较高的处理精度[15]。
以上3种数据预处理方法在处理数据缺失问题上都是行之有效的。与其他预处理方法相比,聚类插补法具有实现简单、处理效率高、准确度高的特点。为此,本文采用聚类算法对数据集中的缺失数据进行填充处理。
1 基于布谷鸟算法优化的K_means聚类算法
K_means聚类算法具有实现简单、运行效率高、聚类效果精确等特点。但聚类效果对初始聚类中心的选择相对比较敏感,如果选择不恰当容易出现局部最优问题。布谷鸟算法能够较好地平衡局部搜索与全局搜索的能力且不易出现局部最优特性。针对K_means聚类算法的缺点,本文将布谷鸟算法与K_means聚类算法融合,可有效避免出现局部最优的问题且提高寻优能力。
设数据集为,其中含有个数据样本,每个数据样本的维度为,聚类个数为,则数据样本记为x= {x1,x2, ...,x}, (= 1, 2, ...,), (= 1, 2, ...,);数据集记为= {1,2, ...,x};聚类中心记为= {1,2, ...,w};聚类结果记为= {1,2, ...,W}。基于布谷鸟算法优化的K_means聚类算法具体步骤如下:
1)初始化参数,聚类个数为,最大迭代次数为,布谷鸟的巢寄行为被寄主发现的概率为且∈[0,1],n,w适应度函数()为
2)从数据集内随机选取个数据样本作为初始鸟巢位置;
3)根据当前鸟巢位置,按照距离最小准则将数据集划分为个类,划分完成后重新计算每个鸟巢位置的适应度函数()的值;
4)根据式(2)对鸟巢位置进行更新操作,计算更新后的鸟巢位置的适应度函数()的值并与上代鸟巢位置对比,取较优鸟巢;

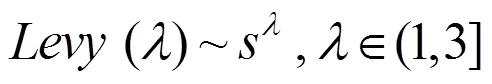
式中,表示步长控制量,且一般= 1;•代表点乘运算;()表示随机搜索路径,且()服从Levy分布;为莱维飞行得出的随机步长;
5)生成一个随机数,若>,未对值进行设置则随机地对鸟巢位置进行改变;若≤,则跳转至步骤7);
6)对更新后的鸟巢位置重新进行聚类划分操作,根据式(3)重新计算聚类中心,计算每个鸟巢位置的适应度函数()的值并与当前鸟巢位置比较,取较优鸟巢;
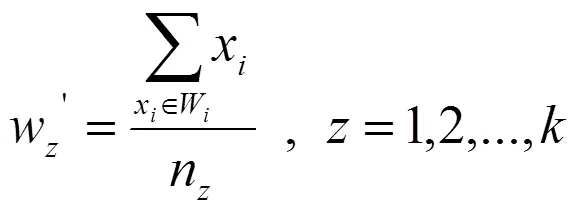
7)若达到最大迭代次数或适应度函数收敛,则输出最终结果;否则跳转至步骤4)。
基于布谷鸟算法优化的K_means聚类算法流程如图1所示。
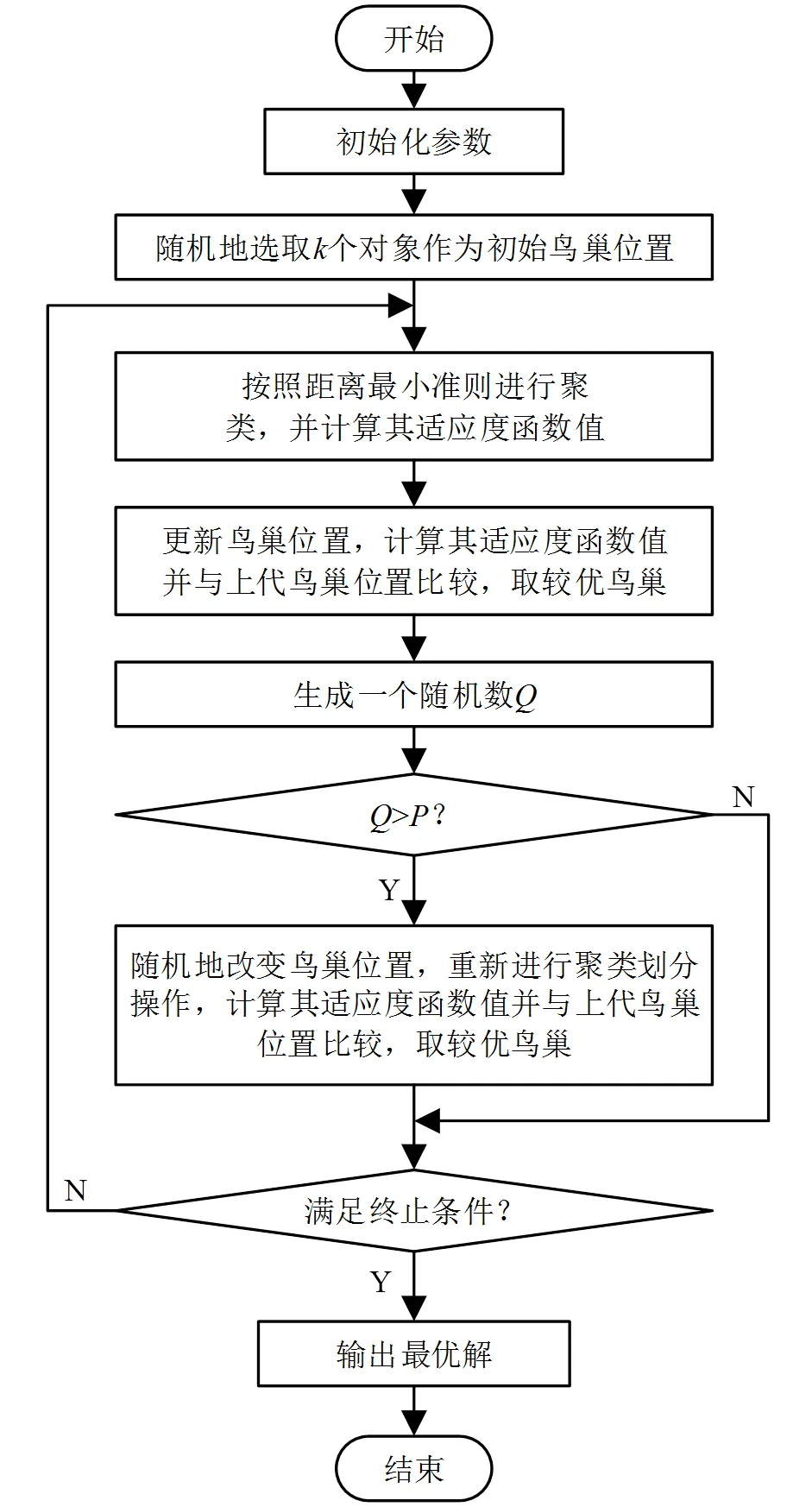
图1 基于布谷鸟算法优化的K_means聚类算法流程图
2 优化后K_means聚类的缺失数据填充算法
2.1 缺失值填充策略
基于聚类的传统填充算法是通过在聚类结果的同类簇数据中求取最近邻点来插补缺失数据,但当数据的缺失属性过多时,聚类算法就无法度量缺失样本之间的相似性。因此,本文将优化后的K_means聚类算法与条件均值填充算法相结合,采用递归填充的策略,提出基于优化后K_means聚类的递归填充算法。该算法主要思想是:首先,利用总体的分组属性均值对不完全数据集中的缺失数据进行预填充形成初始完全数据集;然后,对初始完全数据集进行聚类,利用聚类结果中的属性均值更新缺失样本中的属性值,多次进行直至满足终止条件。
2.1.1 初始预填充方法
在对不完全数据集进行聚类前,需对不完全数据集中的缺失数据进行预填充,形成初始完全数据集。总体均值填充算法使用总体中完全样本的属性均值对缺失数据进行填充,但该方法降低了样本的变异程度和各属性之间的关联程度,导致原始样本分布被严重扭曲。为此,本文采用条件均值填充算法对不完全数据集的缺失属性值进行预填充。首先,将不完全数据集随机地分成若干组;然后,计算各组中完全数据的属性均值;最后,利用组内完全样本的属性均值填充缺失数据的属性值。相比于总体均值填充算法,条件均值填充算法可提高对总体样本变异程度的预估,改善各属性之间的关联程度。
设不完全数据集,其中包含了个数据样本,每个样本由个条件属性组成,每个样本记为D= {x1,x2, ...,x}。将不完全数据集随机地分为组,则组内样本缺失值的填充公式为
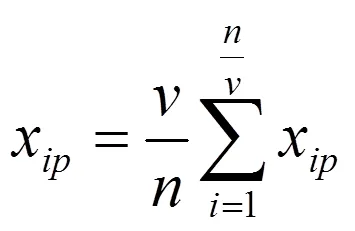
2.1.2 基于聚类的递归填充方法
采用优化后的K_means聚类算法对初始完全数据集进行聚类,得到聚类中心= {1,2, ...,w}和聚类结果= {1,2, ...,W},利用聚类结果中的属性均值更新缺失样本中的属性值。
2.1.3 递归终止条件
利用聚类结果中的属性均值更新缺失样本中的属性值,灵活地运用了聚类算法自动求取近邻的功能。通过多次迭代,对缺失数据的属性值进行多次填充,可获得更好的填充效果。本文采用前后两次填充值的差值Δ作为递归终止条件,Δ的计算公式为
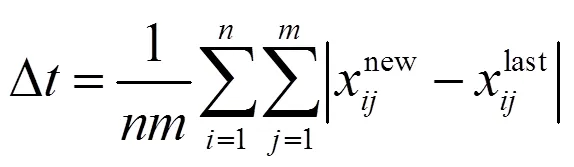
当Δ小于设定的阈值或算法达到最大迭代次数时,递归终止,输出填充后的完全数据集。
2.2 填充算法流程
优化后K_means聚类的缺失数据填充算法具体步骤如下:
1)初始化参数,聚类个数为,输入不完全数据集;


5)计算Δ值,若小于阈值或者算法达到最大迭代次数,则填充结束并输出最终结果;否则跳转至步骤3)。
优化后K_means聚类的缺失数据填充算法流程如图2所示。

图2 优化后K_means聚类的缺失数据填充算法
3 实验与分析
3.1 实验设计
为有效评估算法对缺失值的填充效果,本文在实验过程中取出数据集中的完全数据,并采用人工方式随机抹去其中真实的属性值,按5种不同的缺失比率(5%,10%,20%,30%,40%)分别产生10个缺失比率相等但缺失属性不同的数据集。为验证本文提出的基于布谷鸟算法优化K_means聚类的缺失数据填充算法(CKMI)的有效性,将该算法与KNN填充算法、EN填充算法、基于K-means聚类的缺失数据填充算法(KMI)进行实验比较,交叉验证10次并取其平均值作为最终的实验结果。
由于数据集中同时含有连续型属性与离散型属性,为正确地评估算法对缺失属性的填充效果,本文对连续型属性与离散型属性的填充效果分别采用基于距离的平方根误差与错误分类度进行评估,并以与的和作为总误差进行分析。
基于距离的均方根误差的计算公式为

式中,n表示含连续型缺失属性值的数据样本数量;xguess表示缺失属性的填充值;xtrue表示属性的真实值。
值越小,表明填充误差越小,连续型缺失值的填充效果越好。
错误分类度的计算公式为
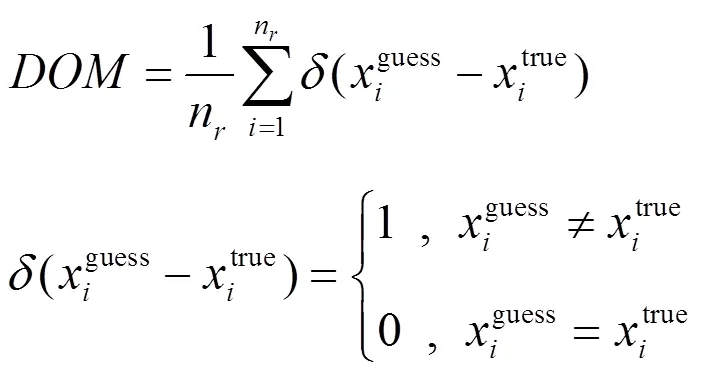

值越小,表明填充误差越小,离散型缺失值的填充效果越好。
3.2 结果分析
实验结果如图3所示。
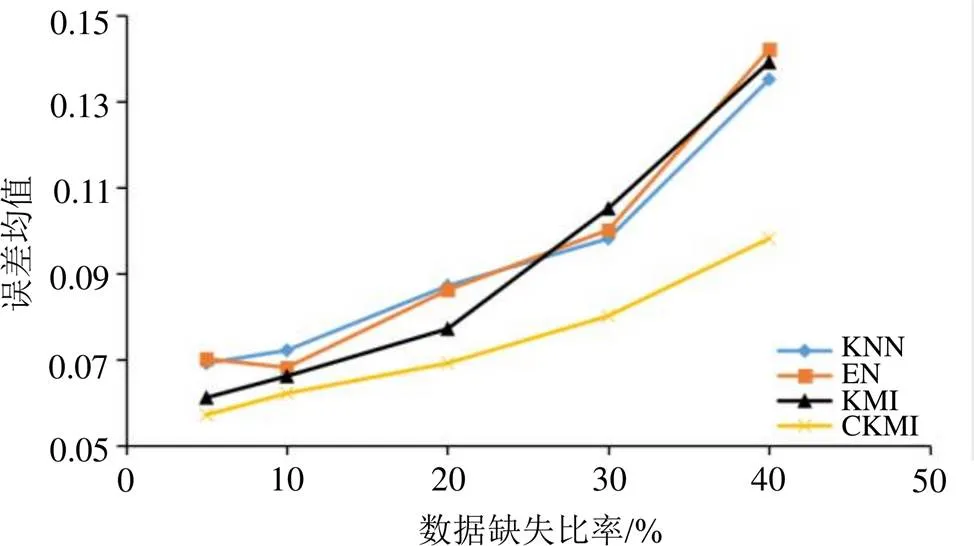
图3 4种算法对缺失属性值的填充结果
由图3可知:4种算法的误差均值随缺失比率的上升而逐渐增大,但CKMI算法一直保持着较低的误差水平,说明CKMI算法相比于其他算法具有更好的处理效果;当缺失比率上升到一定程度时KMI算法的误差突然增大,说明传统K_means聚类算法无法准确地度量缺失比率较高数据间的相似性,从侧面证明本文所提出的基于布谷鸟算法优化K_means聚类算法的有效性。
综上所述,本文提出的基于布谷鸟算法优化K_means聚类的缺失数据填充算法相比于传统的处理算法具有更好的性能。
4 总结
本文采用K_means聚类算法对数据集中的缺失数据进行填充。针对K_means聚类算法对初始参数较敏感且相对容易出现局部最优解的问题,采用布谷鸟算法对K_means聚类算法进行优化,提出基于布谷鸟算法优化的K_means聚类算法。为解决聚类算法无法度量缺失数据间的相似性,提高缺失数据的填充效果,本文提出基于布谷鸟算法优化K_means聚类的缺失数据填充算法,运用条件均值填充算法与优化后的K_means聚类算法相结合,递归地填充缺失数据。实验结果表明:基于布谷鸟算法优化K_means聚类算法的聚类效果有所提升,且与传统缺失数据填充算法相比,基于布谷鸟算法优化的K_means聚类的缺失数据填充算法具有更好的效果。
[1] 王妍,王凤桐,王俊陆,等.基于泛化中心聚类的不完备数据集填补方法[J].小型微型计算机系统,2017,38(09): 2017-2021.
[2] AYDOGMUS Ozgur. Phase transitions in a Logistic metapopulation model with nonlocal interactions[J]. Bulletin of Mathematical Biology, 2018, 80(1): 228-253.
[3] 卜范玉,陈志奎,张清辰.基于聚类和自动编码机的缺失数据填充算法[J].计算机工程与应用,2015,51(18):13-17.
[4] 戴明锋,金勇进,查奇芬,等.二分类Logistic回归插补法及其应用[J].数学的实践与认识,2013,43(21):162-167.
[5] 李建更,郭庆雷,贺益恒.时序基因表达缺失值的加权双向回归估计算法[J].数据采集与处理,2013,28(02):136-140.
[6] JIA Cangzhi, ZUO Yun, ZOU Quan. O-GlcNAcPRED-II: an integrated classification algorithm for identifying O-GlcNAcylation sites based on fuzzy undersampling and a K-means PCA oversampling technique[J]. Bioinformatics, 2018, 34(12): 2029-2036.
[7] 史倩玉,梁吉业,赵兴旺.一种不完备混合数据集成聚类算法[J].计算机研究与发展,2016,53(09):1979-1989.
[8] 郑奇斌,刁兴春,曹建军.结合缺失模式的不完整数据模糊聚类[J].计算机科学,2017,44(12):58-63.
[9] PRIYANKA Singh, Pragya Dwivedi. Integration of new evolutionary approach with artificial neural network for solving short term load forecast problem[J]. Applied Energy, 2018, 217:537-549.
[10] QIAN Jianping, ZHAO Jianping, LIU Yi, et al. Simulation and prediction of monthly accumulated runoff, based on several neural network models under poor data availability[J]. Sciences in Cold and Arid Regions, 2018, 10(6): 468-481.
[11] 王玉哲,许志恒,何虎.仿生物型人工神经网络的探索与实现[J].计算机工程与设计,2018, 39(4):1161-1166.
[12] MOCANU D C, MOCANU E, STONE P, et al. Scalable training of artificial neural networks with adaptive sparse connectivity inspired by network science[J]. Nature Communications, 2018, 9 (1): 2383.
[13] 毛玫静,鄂旭,谭艳,等.基于属性相关度的缺失数据填补算法研究[J].计算机工程与应用,2016,52(6):74-79.
[14] 姚休义,滕云田,杨冬梅,等.基于神经网络的地磁观测数据重构研究[J].地球物理学报,2018,61(06):2358-2368.
[15] 李武翰,魏东兴,王建国,等.基于BP网络和多抽样率处理的缺失音频信号恢复方法[J].大连理工大学学报,2004(5): 729-732.
Optimized of K_means Clustering Based on Cuckoo Algorithm for Missing Data Filling Algorithm
Lin Feng1Cai Yanguang1Cai Hao2Zhang Li1
(1. School of Automation, Guangdong University of Technology, Guangzhou, Guangdong 510006, China 2. Department of Health Science and Technology, Aalborg University, Aalborg 9220, Denmark)
Aiming at the problem that K_means clustering algorithm is sensitive to initial parameters and relatively easy to appear local optimal solution, a K_means clustering algorithm based on cuckoo algorithm is proposed, and the optimized K_means clustering algorithm is combined with conditional mean filling algorithm. Recursively fill in missing data. The experimental results show that the missing data filling algorithm based on K_means clustering optimized by cuckoo algorithm has better effect than the traditional algorithm.
missing data; data filling; Cuckoo algorithm; K_means algorithm
国家自然科学基金(61074147);广东省自然科学基金(S2011010005059);广东省教育部产学研结合项目(2012B091000171,2011B090400460);广东省科技计划项目(2012B050600028,2014B010118004,2016A050502060),广州市花都区科技计划项目(HD14ZD001),广州市科技计划项目(201604016055),广州市天河区科技计划项目(2018CX005)。
TP301 标志码:A
1674-2605(2020)06-0003-06
10.3969/j.issn.1674-2605.2020.06.003
林枫,男,1993年生,硕士,主要研究方向:嵌入式系统及其应用。
蔡延光,男,1963年生,博士,教授,主要研究方向:网络控制与优化、组合优化、智能优化、智能交通系统等。
蔡颢(通信作者),男,1987年生,博士,主要研究方向:大数据分析、智能信息处理。E-mail: howardbrutii@foxmail.com
张丽,女,1994年生,硕士,主要研究方向:物流运输调度、大数据质量优化控制。
猜你喜欢
红蜻蜓·低年级(2021年12期)2022-01-19
红蜻蜓·低年级(2021年12期)2021-12-19
学苑创造·A版(2020年4期)2020-04-24
智富时代(2019年4期)2019-06-01
智富时代(2019年4期)2019-06-01
小学生学习指导(低年级)(2018年9期)2018-09-26
小星星·阅读100分(高年级)(2018年5期)2018-06-12
数学大世界(2018年35期)2018-02-22
发明与创新·中学生(2017年5期)2017-05-12
剑南文学(2016年14期)2016-08-22
