
基于布模拟算法与三角形插值的稀疏点云处理方法
2020-12-30 03:11:02郝耀庭张鹏飞王丽媛
河南城建学院学报 2020年5期
郝耀庭,杨 保,张鹏飞,王丽媛
(1.河南理工大学 测绘与国土信息工程学院,河南 焦作 454000;2.河南四维远见信息技术有限公司,河南 郑州 450000)
点云分割是在二维图像分割受到局限的情况下,研究者将数据维度从二维提升到三维,从根本上解决二维图像在空间位置上的局限性。在二维图像分割中,国内外许多研究者都提出了用于深度学习的算法[1],点云分割与分类模型的效果也与训练样本的质量息息相关,在Wang[2]等人提出的DGCNN网络模型中,设计了一个用于提取中心点的特征以及此点与邻域点的边缘向量的边缘卷积操作,在这部分操作中,点云的稠密程度影响较大,总体的分割效果与点云的点数呈现线性关系,点云点数越多,分割效果越好。点云数据密度较大时,会存在大量的数据冗余,造成计算量大、效率低、显示不便等一系列问题,由此陈佩奇等[3]针对城区LiDAR点云数据提出了自适应采样的抽稀算法。对于稀疏点云的插值,康帅[4]以冷龙岭断裂上一处典型地貌点云为例,对比了最邻近法、距离反比法、不规则三角网法、样条函数法、克里金法等5种插值方法,实验结果表明:不规则三角网插值法结果最优,可以较好地还原野外真实场景。
对于室外复杂场景,先对点云进行滤波处理分为地面点和非地面点,再对两部分点云进行分别插值。点云滤波是LiDAR点云数据处理过程中的重要环节之一,常用于点云去噪、分离地面点与非地面点等。传统的常见点云滤波方法一般有直通滤波、体素滤波、统计滤波、条件滤波、半径滤波。直通滤波是对具有一定空间分布特征的点云数据进行处理,适用于处理x、y方向具有一定范围但z方向分布较广的这类点云的离群点。体素滤波通过体素网格去除噪音点以及离群点,可对点云进行降采样,同时可以使点云本身的几何结构不被破坏。统计滤波是定义某一部分区域的点云密度阈值,小于阈值的部分点云无效。条件滤波即设定一个或多个条件对点云进行过滤,符合设定的条件即保留。半径滤波与统计滤波类似,同样是区域性的滤波,但是滤波方式有差别,是以某点为中心画一个圆并计算落在该圆中的数量,当数量大于阈值的时候保留该点,小于阈值则剔除该点,圆的半径与阈值均要人工指定。目前,国内外研究者提出了大量的点云滤波算法,基本分为基于形态学的滤波算法[5-6]、自适应不规则三角网滤波[7]、基于多尺度滤波。
1 点云数据与算法原理
1.1 布模拟算法
2003年,张建忠[8]等人通过对布匹动力学的物理模型简化,提出了一种快速有效的布模拟算法(Cloth Simulation Filtering,CSF),其可以模拟布料在真实场景中的状态。2016年,张吴明[9]等人将布模拟算法的思想应用于点云滤波中。应用于机载LiDAR点云的布模拟点云滤波算法的主要原理是将点云反转之后,设定格网分辨率和迭代次数,生成一个该分辨率下迭代多次的弹性格网来模拟布匹落在地面上的状态,再设定一个阈值,通过点云与弹性格网的欧式距离来分离地面点与非地面点,见图1、图2。
布模拟算法包含3个参数,分别为格网分辨率、迭代次数、分类阈值。格网分辨率是指覆盖地形的格网大小,设置的分辨率越大,模拟的弹性格网越粗糙。迭代次数是指地形模拟的最大迭代次数。分类阈值是根据点与地形模拟弹性格网的距离,将点云分为地面点与非地面点两部分的阈值。
1.2 三角形内部线性插值
已知三角形的3个顶点坐标P1、P2、P3,三角形内部一点P与3个顶点连线将三角形分为3个面积分别为V1、V2、V3的小三角形,大三角形面积为V,如图3所示。
P点坐标P=u×P1+v×P2+w×P3,其中,u=V1/V,v=V2/V,w=V3/V,u+v+w=1,由此可以得出三角形内任意一点的坐标。
由于大面积三角形需要的插值点过多,所以总体采用随机插值的方法,先在(0,1)范围内随机得到两个数字c,d,则令
u=min(c,d)
(1)
v=|c-d|
(2)
w=1-max(c,d) (3)
这样的随机取值方法可以确保在对大面积三角形进行插值的时候不会出现插值点聚集在一起的现象,使插值结果更加均匀。
2 实验流程及结果分析
2.1 实验条件
操作系统:Windows10;软件环境:Python3.5;点云显示软件:CloudCompare;点云数据:ModelNet10数据集,郑州市高新技术开发区一处机载LiDAR实测点云。
2.2 实验数据
论文中所使用的模型点云数据为ModelNet10点云数据集,该数据集共有662种目标分类,127 915个CAD模型以及10类标记过方向的数据。点云数据为off格式,包含点数量、面数量、边数量、点信息、面信息。室外点云数据使用郑州市高新技术开发区一块实测点云,点云数据为las格式。
原始点云数据包含13 147 331个点,点云密度较大,如图4所示。对点云进行随机降采样,降采样后生成的点云包含893 871个点,使用降采样后的点云作为实验对象,如图5所示。

图4 原始点云

图5 降采样后的稀疏点云
2.3 实验流程
ModelNet10数据集的点云数据格式为off格式,包含了a个点信息和b个面信息。首先,读取点云数据,每一条点信息都包含了该点的x、y、z坐标,每一条面信息都包含了面的边数以及各个顶点的点号,点号从0开始,到最后一个点结束。利用三角网中三角面的权重来确定增加的点数,先计算三角形的边长l1、l2、l3,点P1与P2之间的距离D采用欧式距离,公式为:
(4)
再用海伦公式计算面积,公式为:
(5)
(6)
其中,S为面积,p为半周长。
第i个三角形插值点的数量通过当前三角形的面积Si与三角网总面积的比值n来确定,公式为:
(7)
由于ModelNet10数据提取的三角网存在两边较长一边较短的三角形,为了保证这类细长型三角网的插值,通过判定周长总和与最短边长比m,
(8)

对于室外点云数据先对其进行布模拟滤波处理,对点云进行多层次不同分类阈值的布模拟滤波并进行整合,解决单次固定分类阈值下的滤波导致的部分分类错误问题。
2.4 实验结果分析
2.4.1 ModelNet10数据插值
对一个椅子的点云进行插值,由于点云数据直接包含了三角网的面状属性信息,直接将数据分为点云数据和三角网模型,再对三角网进行插值。
通过对比插值前后的点云,当k=1时,点数从2 382增加到6 050个,当k=2时,点数从2 382增加到8 581个,如图6所示。通过视觉上直观的对比,k=1时,点云插值的结果已经非常理想,足够作为深度学习网络模型来进行训练学习的样本。

图6 插值前后点云以及三角网
2.4.2 室外实测点云插值
对郑州市高新技术开发区一处机载LiDAR实测点云进行实验,实验数据与ModeNet10数据集不同,为las格式数据,先对las数据进行解析提取点云的点信息,进行随机降采样之后对点云进行布模拟滤波处理来分离地面点和非地面点。格网分辨率设置为0.5,迭代次数为500,进行单次滤波作为对比,将分类阈值分别设置为0.5~3.5,以0.5为间隔的分类阈值进行布模拟滤波,滤波后地面点和非地面点的点数见表1。

表1 单次不同分类阈值下滤波结果
分类阈值为0.5、2.0、3.5时的滤波结果分别见图7、图8、图9。由表1可以看出,随着分类阈值的增加,地面点数的增速呈递减趋势。分类阈值为0.5时,很大一部分地面点都被错误分类到非地面点。分类阈值为2.0时大部分地面点都正确分类到地面点,只有一小部分依然被错误分类。分类阈值为3.5时,更多的矮建筑物被分类到地面点。所以,选取分类阈值为2.0时的滤波结果进行下一步的插值。
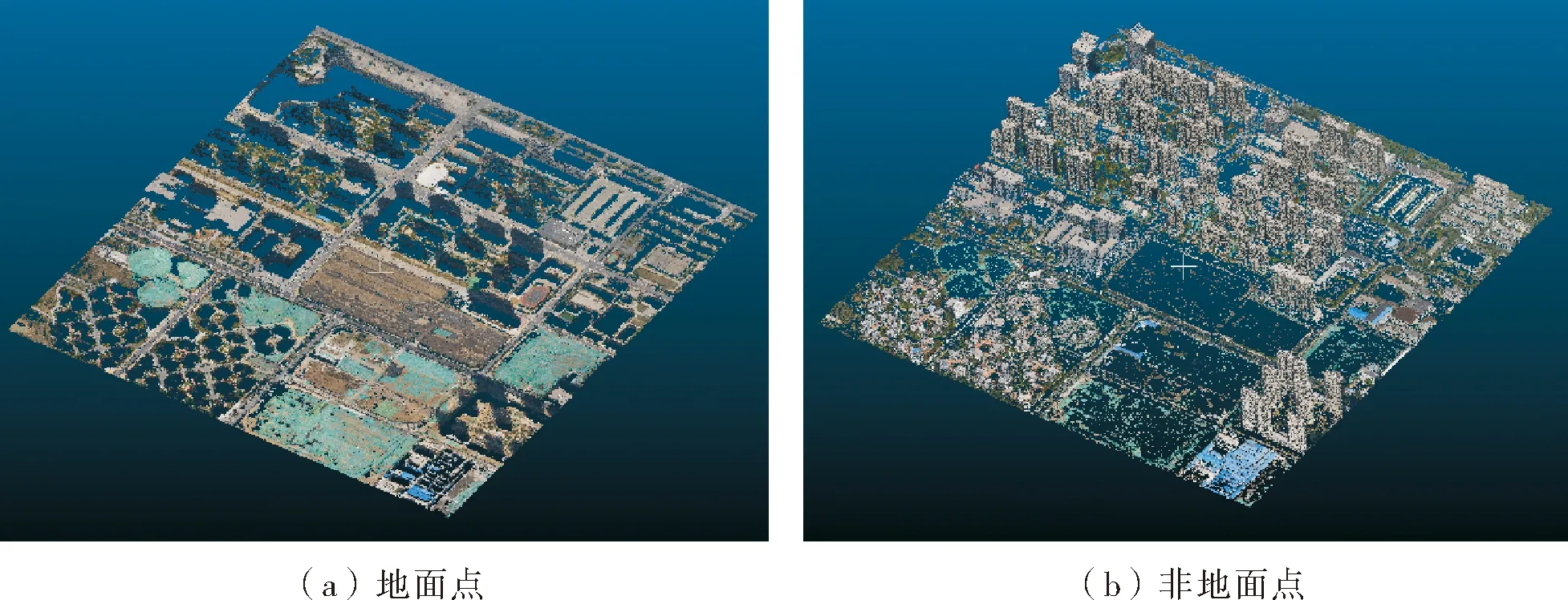
图7 分类阈值为0.5时的分类结果

图8 分类阈值为2.0时的分类结果

图9 分类阈值为3.5时的分类结果
对首次滤波的结果(见图10)再次进行更大分类阈值下的滤波,对地面点与非地面点分别进行更高分类阈值的滤波之后并整合,结果如图11所示,两种方法的分类结果对比见表2。

图10 单次固定分类阈值的分类结果

图11 多次不同分类阈值整合的分类结果

表2 不同方法结果对比
与单次单分类阈值情况下的滤波相比,多次不用分类阈值整合的分类结果更加精确。单次滤波的分类结果中有部分矮建筑被错误分类到地面点,也有部分街道上的点云被分类到非地面点,使用多次不同分类阈值并进行整合的方法可以很大程度地降低类似的分类错误,提高分类精度,准确性更好。对最终分离的地面点和非地面点分别生成三角网,再对三角网进行插值,插值结果如图12所示。
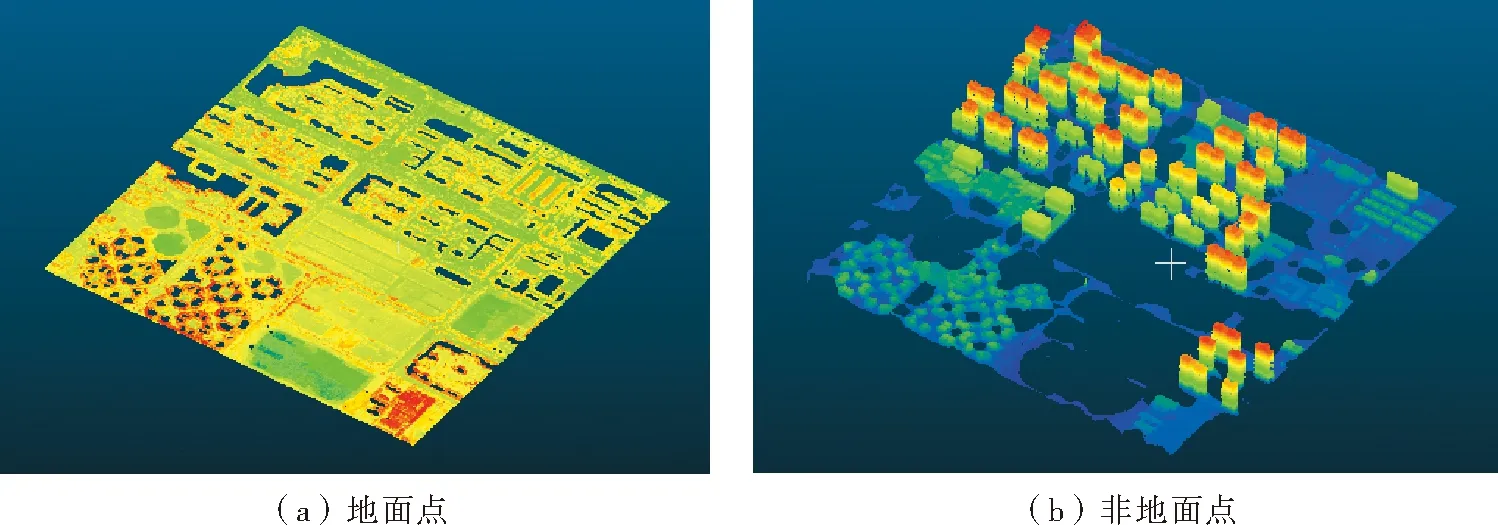
图12 插值后的地面点与非地面点
通过插值前后对比,地面点由617 391个增加为1 019 494个,非地面点由276 480个增加为536 911个,插值效果理想。在保证增加了点云细节的情况下,不使深度学习模型对点云进行分割分类的计算量过于巨大。
3 结论
论文设计实现了一种基于布模拟算法和三角形内部线性插值的快速高效点云插值方法。利用三角网中三角形面积权重与三角形边长总和与最短边的比值来确定插值点数量,并在三角形面内进行随机均匀线性插值,在ModelNet10数据集上插值效果理想。对于室外场景,插值效果受点云滤波处理的影响,布模拟算法可以很好地贴合地面点,但单次固定分类阈值下的分类会导致有一部分高度比较低的地物和面积比较大的矮建筑被分类到地面点,造成分离错误。论文提出的方法通过对室外点云进行多次不同分类阈值滤波,整合所得到的分类结果很大程度地降低了单次固定滤波造成的分类错误,只有极少部分的地物分类错误。地物点的颜色信息一般与地面点有一定差异,可以从这个角度出发对布模拟算法做进一步的研究和改进。
猜你喜欢
空间科学学报(2020年6期)2020-07-21 05:36:46
西南石油大学学报(自然科学版)(2019年1期)2019-01-28 09:33:52
智能计算机与应用(2017年2期)2017-05-04 00:45:34
电测与仪表(2016年10期)2016-04-12 00:26:24
电测与仪表(2016年14期)2016-04-11 12:32:48
江西理工大学学报(2015年3期)2015-12-22 05:26:18
长江工程职业技术学院学报(2014年4期)2014-11-30 02:41:40
电测与仪表(2014年11期)2014-04-04 09:21:30
测绘科学与工程(2014年4期)2014-02-27 07:06:03
测绘通报(2013年2期)2013-12-11 07:27:50
