
面向软硬件应用集成的数据库内存排序优化方法
2020-12-30 03:27:22孙杨
东北电力大学学报 2020年6期
孙 杨
(集美大学计算机工程学院,福建 厦门 361021)
数据库应用领域对数据库的存储容量提出更高的要求,结合对数据库的优化访问控制和数据库存储空间设计[1],建立数据库的拓扑结构和内存优化排序控制模型,可以优化数据访问和索引控制
文献[2]将多源资源环境数据纳入到统一的网格参考基础中,形成统一关联查询能力,基于地球剖分网格思想对资源环境数据进行网格编码,实现了多源资源环境数据的统一检索.文献[3]在三支决策问题中,相较于体现单一不确定性的语言变量模型和模糊集模型,通过云综合的方法获得综合评价函数,同时证明了在云模型的距离空间中赋权距离和是一个凸函数,对概念语义进行差异上的描述与定义,将该定义推广到多个云模型的场景下,为损失函数的确定提供了一种新的语义解释,使得三支决策中的误分类率最低.文献[4]以华为Fusion Compute虚拟化平台为基础,使得向虚拟化集群模式进行迁移,构建了HIRFL数据库的迁移方案,优化数据库虚拟机性能优化方案,具有有效性和可行性,降低了数据中心的运行和维护成本.
但是以上方法进行数据库内存排序时的自适应性不好,特征辨识能力不强,降低了数据库内存容量.对此,本文提出基于本体特征映射的数据库内存排序方法,通过构建数据库的内存优化存储结构模型,进行数据库的内存结构分区设计,通过网格化的分区块存储协议设计,实现数据库内存优化,展示了本文方法在提高面向软硬件应用集成的数据库内存排序能力方面的优越性能.
1 数据库内存信息数据拓扑结构模型
为了实现面向软硬件应用集成的数据库内存排序,结合空间结构映射和线性特征重组方法,在融合的系统模型中[5],进行数据库内存信息分配,假设R为数据库的四元组(Ei,Ej,d,t)的相似度特征量,得到数据库的特征分布属性为A={A1,A2,…,Am},假设一个子系统为本地数据库表示为i,得到应用集成数据库的内存信息状态点跟踪函数为
(1)
公式中:xi∈Rn为数据库系统的状态矢量;ui∈Rm为数据库的模糊度观测量.采用关联规则特征挖掘的方法,提取数据库内存信息的信息熵,得到数据库的数据匹配关系为:A={A1,A2,…,Am},以此构建的数据库内存信息的特征分析模型为
(2)
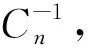
(3)
公式中:i=16,17,…63,采用空间分布式融合方法,使内存调度模式Si-1同内存信息的高分辨输入模式Si共同作用,得到数据库系统传递函数为
(4)
当数据库的内存输出码元序列X中的元素xt满足
P(xt)=P(xt)-1,
(5)
即数据库的数据特征分布序列xt只与它的前n个元素有关,xt∈B.定义数据库内存排序的维度为θi1,i2,…,in+1(x),空间嵌入元素i1经过i2,i3等状态变换,得到in+1.提取数据库内存信息的关联规则特征集,得到文本特征集F={f1,f2,…,fn},应用集成数据库内存信息参数特优化模型为S={s1,s2,…,sn}.由此得到数据库内存信息大数据挖掘的输出结果,将输出结果输入数据库内存信息的特征分析模型中[8],优化数据拓扑结构模型,如图1所示.
2 数据库内存排序优化
2.1 数据库集成
应用语义本体特征映射方法进行数据库存储空间优化,其中,资源分配的实体模型设为
(6)
公式中:N为应用集成数据库的内存分布序列;|xi-τ-xi+τ|为映射点τ的绝对系数,应用集成数据库的内存分布的字结构为K0,K1,…,K15.提取数据库内存信息的信息熵,采用连接次序段编码的方法,得到稀疏特征分布项qi,再应用集成数据库的内存特征分布邻近特征集di=(di1,di2,...,dini),构建分布式软硬件应用集成的数据库系统传递模型为
(7)
根据上述模型,结合软硬件应用环境特殊性以及用途的多样性,得到在时间窗口t0时刻的排序优化解为
(8)
公式中:λmax为数据库的模糊度属性集;Qrev为数据库内存调度的查询属性类别集;ρmax为数据库的相似度分布属性值.将数据库内存信息的运行状态数据进行特征分解,再根据大数据分类结果,进行信息匹配和融合处理所得到的x(t)与x(t+τ)越相似.通过数据库内存融合处理[9],得到数据库的特征空间分布离散度为
(9)
公式中:hi(t)为集成数据库的迁移函数;npi(t)为干扰项,将数据库的内存开销fj进行多层次特征分解,得到分类结果为
(10)
(11)
(12)
公式中:Max(ωm,μ,j)为数据库内存信息的关联维[10];k为内存的数据读写速度系数,公式(11)处理下缓存函数gn要高出几个数量级;Sumj,k为集成层次特征;Nm为响应延迟,由此进行数据库的集成处理.
2.2 数据库内存特征提取和排序
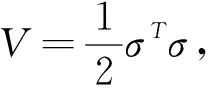
(13)
根据上述分析,在标准时序T下,得到数据库内存特征djn,kn的分布集为
Dj,k=[dj1,k1,dj2,k2,…djn,kn]T.
(14)
结合模糊度特征检测方法,进行数据库内存信息进行自适应融合,得到优化的排序频次参数集为
(15)
采用主成分特征分析方法,进行数据库内存排序,得到模糊隶属度函数为
(16)
公式中:L为数据库内存信息特征分量.结合模糊度特征检测方法,计算数据库内存信息的模糊度特征量,表示为
(18)
公式中:μ为数据库内存分布的阈值系数,综上分析,实现数据库内存排序优化,结果如图2所示.
分析图2得知,根据特征挖掘结果,进行内存排序控制.本文方法实现数据库内存排序优化.
3 仿真测试分析
3.1 实验数据
为了验证本文方法在实现软硬件应用集成数据库内存排序的应用性能,进行仿真测试分析,在UCI MachineLearning Repository ( https://archive.ics.uci.edu/ml/datasets.html )大数据样本库中选择某实际数据库内存信息,排除实际应用性较低的内存信息300 个,剩余软硬件应用集成数据库内存信息的采样样本数为2400,初始的数据库内存信息采样率f0=1.5 KHz,数据库的相似度系数为0.45,内存开销的容量为20 GB,根据上述参数设定,得到软硬件应用集成数据库的内存信息样本序列,如图3所示.
3.2 实验过程及结果
样本序列为研究对象,进行数据库内存优化排序,得到排序结果如图4所示.
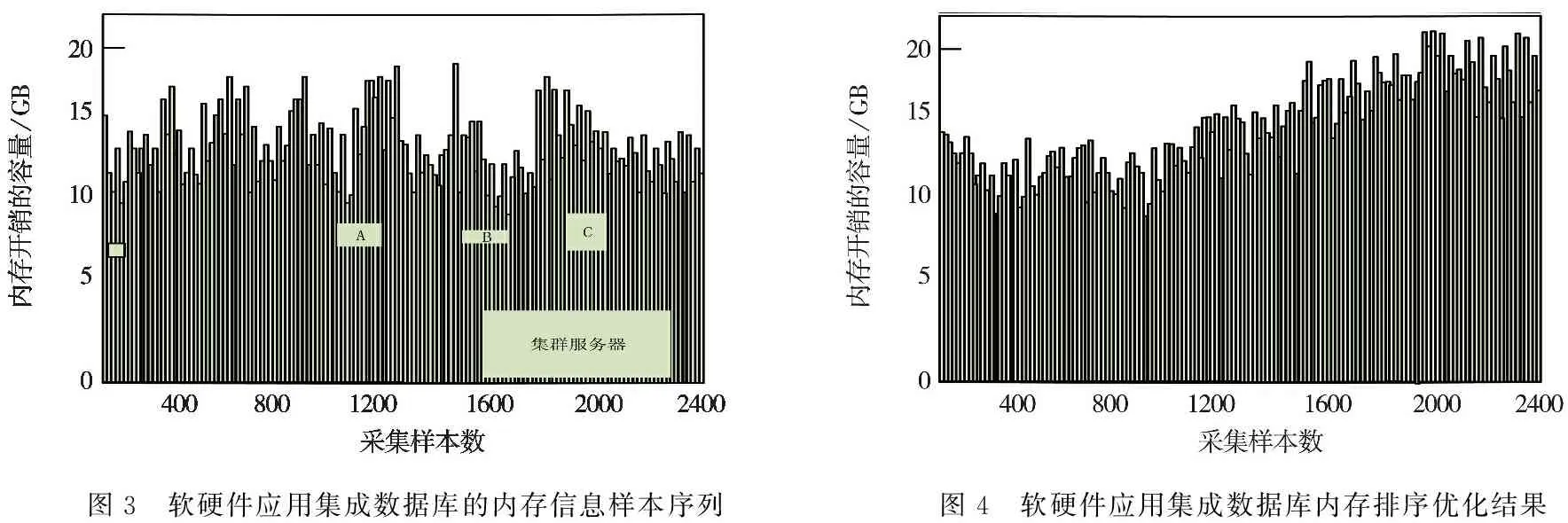
图3 软硬件应用集成数据库的内存信息样本序列图4 软硬件应用集成数据库内存排序优化结果
分析图4得知,本文方法在2400个样本数测试下,内存开销的容量呈现上升趋势,且一直保持8GB以上,说明其能有效实现软硬件应用集成数据库内存排序,提高内存管理能力.
测试数据库的内存容量,得到结果如图5所示.分析图5得知,尽管三种方法的内存起点相同,但是本文方法较早到达20GB,且整体上升趋势较为明显,说明其进行软硬件应用集成数据库内存排序,提高了内存容量,测试数据库排序的时间开销,得到对比结果见表1.
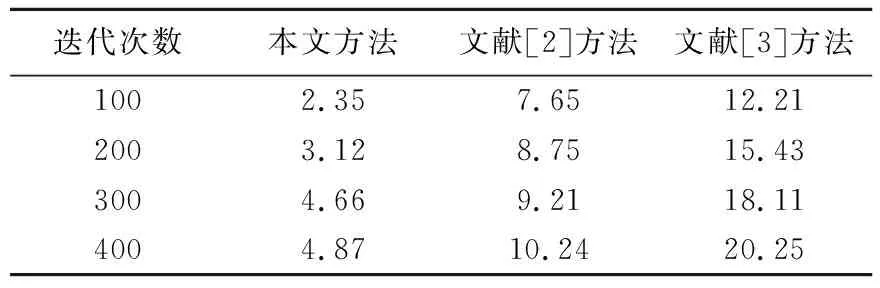
表1 时间开销测试(单位:ms)
分析表1得知,本文方法优于文献[2]、文献[3]的方法,可以明显看出本文方法进行软硬件应用集成数据库的内存排序的时间开销较小,最低仅为2.35 ms,说明本文方法提高了内存管理能力和内存容量即提高了软硬件应用集成数据库内存排序的应用性能.
4 结 语
本文通过分析软硬件应用集成数据库的数据特征分布状态,扩展查询和检索优化配置的方法,进行数据库的集成构造和数据集融合处理,完好匹配软硬件应用集成情况,提高了软硬件应用集成数据库的存储性能和存储容量,进而降低了存储的时间开销.
猜你喜欢
新高考·高二数学(2022年3期)2022-04-29 05:08:09
新高考·高二数学(2022年3期)2022-04-29 05:08:09
中学生数理化·七年级数学人教版(2022年11期)2022-02-14 07:14:12
中学生数理化(高中版.高二数学)(2020年11期)2020-12-14 07:36:40
科普童话·学霸日记(2020年1期)2020-05-08 16:45:11
当代陕西(2019年13期)2019-08-20 03:54:22
小天使·一年级语数英综合(2019年2期)2019-01-10 11:57:30
中学生数理化·高一版(2018年6期)2018-07-09 06:00:54
儿童绘本(2018年5期)2018-04-12 16:45:32
测绘科学与工程(2014年5期)2014-02-27 07:06:14
