
中文期刊知识图谱研究范式的优化
2020-12-28 02:32贾维辰李文光余明媚
中国远程教育 2020年11期
贾维辰 李文光 余明媚
【摘 要】
在科学知识图谱领域,代表性软件CiteSpace对于期刊数据的分析具有重要价值,但是CiteSpace软件对中文期刊数据的分析仅能完成几类基础聚类和数据分析,如若希望做深入解读就需要对已有中文期刊CiteSpace研究范式进行完善和创新。本研究通过深入分析CiteSpace两篇代表性文献,提取了标准研究范式,从CSSCI收录的文献中梳理出通用的CiteSpace中文期刊研究范式,并将两种范式进行对比,探究中文期刊研究范式需要优化之处。基于此,本研究通过使用自然语言处理技术(简称“NLP”)主题挖掘的典型模型Latent Dirichlet Allocation(简称“LDA”)处理论文摘要数据,通过这种技术完善文献检索策略和文献数据处理方法,提出的“优化范式”丰富了中文期刊CiteSpace研究来源数据,增强了中文期刊CiteSpace研究内容的深度和系统性,并通过对国内人工智能在教育领域应用的研究进一步验证了该“优化范式”的可操作性,揭示出国内人工智能在教育领域应用研究的前沿主要聚焦于智慧学习环境的构建和相关技术支持。在与国内CSSCI同类型文献的对比中,“优化范式”在数据收集、数据分析、数据解读三个阶段的表现均优于传统中文期刊CiteSpace研究范式。
【关键词】 期刊知识图谱;文献计量;LDA模型;CiteSpace;研究范式;人工智能教育;中文社会科学引文索引(CSSCI)
【中图分类号】 G420 【文献标识码】 A 【文章编号】 1009-458x(2020)11-0001-10
随着20世纪90年代信息可视化技术的发展,科学知识图谱在21世纪初迅速成为科学计量学的一个新领域,诸多可视化分析软件被陆续引进国内。CiteSpace软件引入中国后,得到学术界极大关注和推广应用,并取得丰硕成果(Lu, T., Hu, & X. 2019)。但是随着研究的深入,我们发现CiteSpace软件对中文期刊的数据分析仍处在表层(郭丽君, 等, 2018; 刘勇, 等, 2018; 王建华, 等, 2019),仅能完成几类基础聚类和数据分析。要解决这一问题,迫切需要对已有中文期刊CiteSpace研究范式进行完善和创新。
一、CiteSpace回顾
(一)CiteSpace理论基础
CiteSpace软件是美国德雷塞尔大学计算与信息计量学院陈超美教授在怀特(White & Griffith, 1981)作者共被引分析理论和库恩(Kuhn, 1962)科学结构演进理论的基础上使用Java语言开发的信息可视化软件。该软件主要用于分析和可视化作者共被引网络,生成知识概念图谱、知识聚类图谱,帮助研究者探索知识领域中的研究热点、前沿和潜在新趋势。
CiteSpace主要包括“研究前沿”和“知识基础”两个概念模型(陈悦, 等, 2015)。
· 研究前沿模型。某个科学领域中的施引文献聚类。从施引文献群组本身内容和施引文献群组引用参考文献两个方面体现研究前沿的特征。
· 知识基础模型。某个学科领域中相对于研究前沿的所有前期文献集合。
CiteSpace基于以上兩个概念模型,通过信息可视化技术基础实现对研究领域的研究热点、前沿和潜在新趋势的探索和预测。
(二)CiteSpace在教育学领域的应用
CiteSpace软件在教育学领域的应用涵盖教育学多个子领域或研究主题,研究者借助CiteSpace对子领域的研究热点、前沿和潜在趋势进行文献计量分析和预测。涉及的子领域主要包括大数据学习分析(Wang, J., et al., 2016; Tho, S. W., et al., 2017; 闵光辉, 2020)、新技术在教育领域的应用(Wang, F., et al., 2018; Jing, et al., 2019; 徐坚, 等, 2017; 任利强, 等, 2018)、学科教学(Wang, B., Wang, & Z., 2018; 李韬, 等, 2019; 孟宇, 等, 2019)、教师专业发展(何灿娟, 等, 2017; 张华阳, 等, 2018; 郭丽君, 等, 2018)和学生素养(Zhao, Y., et al., 2016; Yu, L., et al., 2018; Stopar, K., et al., 2019; 任艳莉, 等, 2018)。CiteSpace可以帮助教育学领域研究者发现领域研究热点,对教育学发展趋势和研究方向进行预判并做出决策。
二、CiteSpace研究范式
(一)英文期刊CiteSpace研究范式
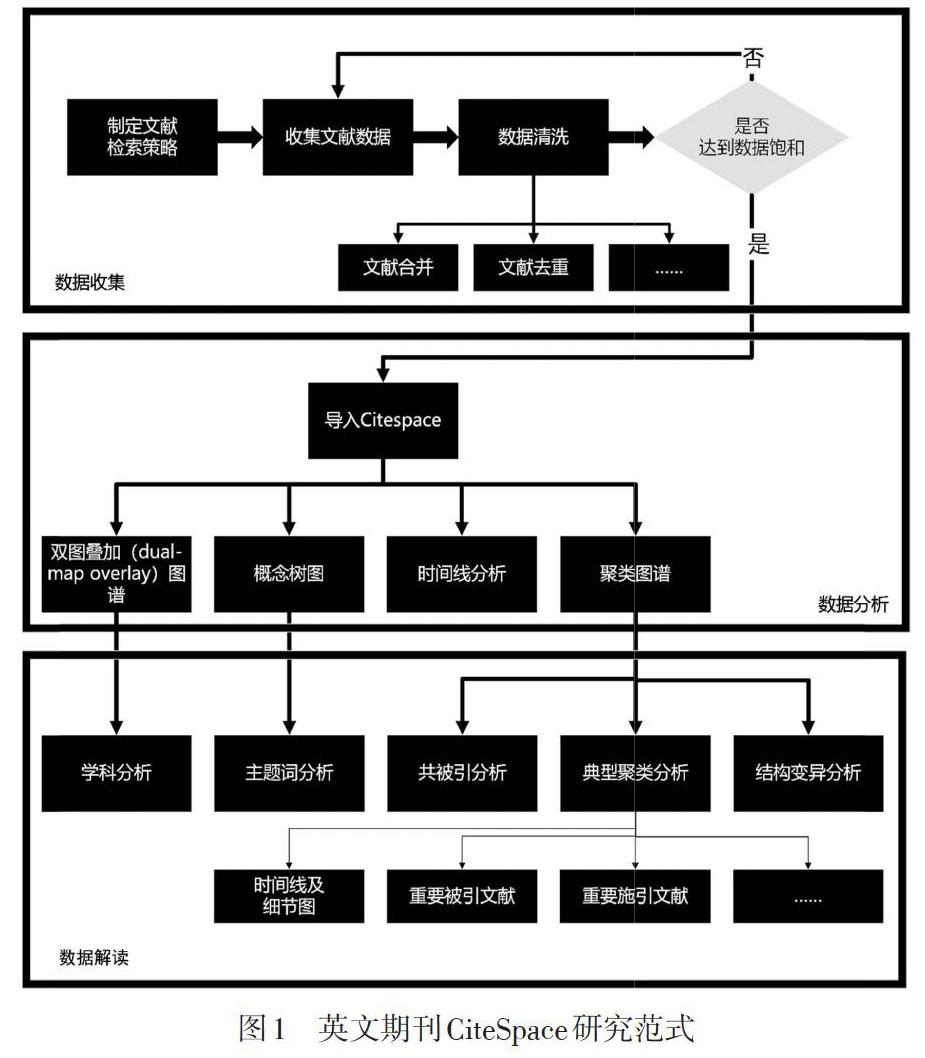
在英文期刊CiteSpace研究范式方面,CiteSpace开发者、大连理工大学教授陈超美教授最具权威性,我们对陈超美教授在2012年和2017年发表的两篇论文(Chen, et al., 2012; Chen, 2017)进行分析后进行了总结,如图1所示。
英文期刊研究范式包括三个阶段:数据收集、数据分析、数据解读。
· 数据收集阶段。选择Web of Science(WoS)数据库,通过采用系统的综合检索策略,优先保证文献查全率。完成数据采集和数据清洗后将数据传入CiteSpace进行处理。
· 数据分析阶段。生成“双图叠加图谱”“概念树图”“时间线分析”“聚类图谱”等数据可视化图谱。
· 数据解读阶段。对各类图谱进行解读,陈超美教授的研究路径是从宏观到微观,从直观到复杂,从整体到局部。具体分析内容包括:“学科分析(宏观)”“主题词分析(微观与直观)”“共被引分析(复杂与整体)”“典型聚类分析(局部)”“结构变异性分析(特殊)”。同时在聚类层面上分析,一般会选取较大的或较新的典型聚类进行分析,在每个典型聚类分析中都会提供“概念树”“时间线及细节图”“重要被引文献”“重要施引文献”。基于以上的解读,最后生成该领域的研究热点、研究前沿、研究趋势预测以及核心研究者研究动向等结论。
(二)中文期刊CiteSpace研究范式
与英文期刊类似,中文期刊CiteSpace研究同样包括三个阶段:数据收集、数据分析、数据解读,如图2所示。但是因为数据库字段不完整等原因,能够实现的分析项目远少于英文期刊。
· 数据收集阶段。通常选择中国知网(CNKI)数据库或中文社会科学引文索引(CSSCI)数据库其中一个数据库,采用单关键词或多关键词的方式进行检索。数据采集完成后大多数研究者不会对数据进行清洗(在近几年发表的CSSCI文献中仍可以找到研究机构重复的聚类分析图(王小明, 2018))就直接传入CiteSpace进行处理。
· 数据分析阶段。基于输入数据生成“时间线分析”“聚类图谱”等数据可视化图谱。
· 数据解读阶段。对生成的图谱进行解读,内使用时间线分析图谱对研究领域进行阶段划分,而后基于聚类图谱和聚类关键词凸显表进行进一步解读,最后生成该领域的研究热点、研究前沿、研究趋势预测等结论。
将图1和图2对比后可以发现,中文期刊CiteSpace研究范式在数据收集、数据分析和数据解读三个阶段都存在一定缺陷:数据收集缺少系统检索策略、缺少数据清洗这一关键步骤;数据分析缺少“双图叠加图谱”和“概念树图谱”;數据解读在缺少对应图谱的前提下,仅能基于聚类图谱进行共被引分析和典型聚类分析,不再是一个从宏观到微观、从直观到复杂、从整体到局部的完整体系,而CNKI数据库因为缺少引文数据字段,无法进行共被引分析。研究者只能基于自身学科知识背景进行主观解读,这与CiteSpace“让一个没有相关专业知识的人也能给出有价值的综述”的软件设计初衷相背离。
三、中文期刊CiteSpace研究范式存在的问题
(一)数据来源问题
对于知识图谱软件而言,“一切皆为数据”,后续研究均围绕输入数据展开,输入数据的深度、覆盖面与研究质量和可信度有较强相关性。传统中文期刊CiteSpace研究存在数据库单一、关键字段缺失等问题。
CiteSpace软件数据是来自于期刊数据库的文献索引文件,因此文献索引中包含的字段决定了后续研究的深度和广度。英文期刊数据库Web of Science(WoS)为研究者提供涵盖从“文件名”到“研究方向”多达66个字段,使英文期刊CiteSpace研究能够实现“概念图”“重要被引/施引文献”“结构变异性”等数据可视化,进而完成“聚类主要研究对象、主要研究内容”“领域高被引文献、最相关施引文献”“高产作者引用足迹”等深层数据分析。
我们对2008—2019年CSSCI收录的125篇CiteSpace知识图谱文献进行统计,发现中文期刊知识图谱研究主要数据来源是CNKI(90篇)和CSSCI(45篇)两个数据库(部分文献同时使用CNKI和CSSCI数据)。国内研究者通常会基于一个数据库,下载研究领域内近若干年的文献索引进行分析。与WoS数据库相比,中文期刊数据库存在字段不完整的情况。CSSCI和CNKI的文献索引字段覆盖面有较大差异。CSSCI索引文件包含文献引文数据,缺乏文献摘要字段;CNKI索引文件包含文献摘要数据,缺乏文献引文数据。同时,两个数据库对期刊划分和收录标准的不同导致相同检索策略获得的检索结果存在较大差异。不同的检索结果、字段缺失导致研究者的数据存在较大差异,其研究结果的质量和可信度都存在问题。
(二)研究内容问题
在研究内容方面,如上文所述,英文期刊CiteSpace分析能够对数据进行深入挖掘和分析,而中文期刊CiteSpace的研究内容主要集中在对领域内研究热点、研究前沿、研究趋势进行探索(陈悦, 2014)。在阅读近年CiteSpace在教育领域应用的相关文献后我们发现,由于缺乏有效的分析和可视化方法,很多研究者仅基于关键词聚类图和突显词分析图对该领域近10年的研究热点、研究前沿和研究趋势展开分析。另外,在对CiteSpace数据解读方面,研究者主要依赖自身在领域内的经验和知识储备,不可避免地导致结果分析中掺杂研究者的主观经验。
综上所述,我们认为目前中文期刊CiteSpace研究范式在数据来源和研究内容等方面均存在一定问题。
四、基于LDA模型的中文期刊
CiteSpace研究范式优化
针对上文提出的中文期刊CiteSpace研究范式存在的问题,本研究提出基于Latent Dirichlet Allocation(简称“LDA”)模型的中文期刊文献计量研究范式(简称“优化范式”)。与英文期刊CiteSpace研究范式不同,“优化范式”对数据收集和数据分析阶段进行延伸,引入文献摘要作为新的分析数据,使用自然语言处理对文献摘要进行主题抽取。基于“优化范式”的变化,需要设计相关文献收集策略、选择合适的主题抽取算法等,最终形成完整的范式体系。
(一)范式的改进思路
1. 新的文献计量数据
文献在出版前都要通过严格的同行评议,这一过程保证了研究成果的可靠性和先进性。论文摘要是具有独立性和完整性的短文,是对论文内容的简短陈述,作者在摘要中扼要说明研究目的、研究方法和最终结论。论文摘要比论文关键词所携带的信息更加全面、具体。如果能对目标领域内所有文献的摘要进行全样本分析,配合CiteSpace聚类功能,就可以更加系统、清晰、立体地分析该领域的研究脉络,弥补中文期刊CiteSpace研究范式中体系不完整的缺陷。因此,有必要将论文摘要作为文献计量的新数据。
2. 论文摘要的数据处理
论文摘要属于长文本数据,具有非结构化、多主体、数据稀疏等特征(Wu, et al., 2020)。Citespace软件5.0版本具备“概念树(Concept Tree)”功能,能够根据文献题录数据提取各主题概念间的相互联系和强度。但是,该功能不适配中文数据。我们希望通过构建主题抽取模型来处理文献摘要数据。主题抽取的研究方法主要有LDA模型、图模型、概率模型、聚类分析等,实践证实这些模型在长文本主题抽取方面取得了良好的效果(谭文堂, 等, 2013; 林萍, 等, 2014; 唐晓波, 等, 2014; 何建云, 等, 2015; 王鹏, 等, 2015; 关鹏, 等, 2016; 曲靖野, 等, 2018; 杨奕, 等, 2019)。本研究选取LDA模型作为论文摘要主题抽取模型。LDA模型是自然语言处理(NLP)中主题挖掘的典型模型,其基本思想是将每个文本表示为主题的多项分布,每个主题表示为词汇的多项分布,进而得到文本的潜在主题结构。LDA模型可以从文本语料库中抽取潜在的主题,提供量化研究主题的方法,已经被广泛应用到科学文献主题发现中,如研究热点挖掘(王小明, 2018)、研究主题演化(杨星, 等, 2012; 范云满, 等, 2014; 关鹏, 等, 2016)、研究趋势预测(李湘东, 等, 2014; 曾利, 等, 2014)等。
(二)“优化范式”的提出
1.“优化范式”的架构
如图3所示,“优化范式”对中文期刊CiteSpace研究范式的数据收集、数据分析和数据解读三个阶段进行补充。在数据收集阶段针对研究领域制定相应的文献检索策略获取查全率更高的原始数据;在完成对原始数据的清洗后,在数据分析阶段通过使用自然语言处理技术对获取的论文摘要进行主题抽取处理,获取相应的主题词列表和主题词聚类分析图谱;基于以上数据分析图表研究者可以进行“主题词分析(微观和直观)”“共被引分析(复杂和整体)”“典型聚类分析(局部)”等数据解读。
2.“优化范式”的数据获取
(1)文献检索策略。研究的原始数据由基于CSSCI的多主题搜索查询和CNKI多主题搜索查询得到的结果组合而成。数据检索策略是基于陈超美教授的“综合检索策略”(Chen, 2017)构造针对目标领域的检索策略。检索策略原则如下:
· 确保文献来源的规范性、权威性和丰富性。选择中文社会科学引文索引(CSSCI)作为目标数据来源;选择中国知网(CNKI)作为辅助数据来源。在数据检索和数据收集时,两个数据来源使用的检索语法必须一致。
· 确保主题搜索查询涵盖目标领域各方面。设置多个检索阶段,通过“施引文献扩展”和“主题词综合检索”的策略提高检索结果的查全率。
(2)数据清洗策略。对CSSCI检索结果进行数据清洗,包括缺失值处理、检测和去除重复文献记录等。由于目标文献来源CSSCI数据库不包含文献综述字段,需要用编写脚本的方式对两个数据源的检索结果进行处理。通过“标题”“第一作者”“年份”三个字段的比对进行匹配,得到的CSSCI记录作为研究的基准数据,CNKI检索结果作为目标领域语料库数据。
3. 图谱生成和解读
文献摘要数据具有非结构化、多主体、数据稀疏的特点,我们使用LDA模型进行处理,通过编写数据分析脚本辅助CiteSpace软件实现主题词表和主题词可视化图谱。在分词部分基于目标领域CNKI数据库检索结果生成细分领域词库,比通用分词模型更加精确。
五、兩种范式的对比分析
应用“优化范式”对2001—2019年国内“人工智能”在教育领域的应用研究进行可视化分析。选取北京邮电大学刘勇教授发表于2018年的关于人工智能在教育领域应用的同类型文献《人工智能在我国教育领域应用的可视化分析》(刘勇, 等, 2018)作为对比对象(简称“对比范式”)。从数据收集、数据分析和数据解读三个阶段进行横向比较。由于篇幅限制,在关键聚类分析部分仅对一个关键聚类进行详细阐述。
(一)数据收集阶段的对比
1.“优化范式”的数据收集
我们选择CSSCI数据库作为目标数据来源,选择CNKI数据库作为辅助数据来源,检索年份设定为“2001~2019”。围绕人工智能主要领域、人工智能与教育的结合产物、在教育中运用的相关技术设计了三轮数据检索策略。最终得到的数据集是包含1,840条CSSCI记录和15,885条CNKI记录的数据集。完成对检索结果的数据清洗后,按照“优化范式”要求对两个数据源的检索结果进行匹配。通过“标题”“第一作者”“年份”三个字段的比对共匹配出1,483条CSSCI记录作为本研究的基准数据,CNKI检索结果作为本研究的细分语料库数据。
2.“对比范式”的数据收集
“对比范式”选取的是CNKI数据库,检索包含关键词“人工智能”/“AI”和“教育”的相关文献,得到1086条检索记录(629条为期刊、457条为学位论文)。
对比两个范式的数据收集阶段,如表1所示,可以发现“优化范式”的筛选标准是优先数据查全率,“对比范式”的筛选标准是优先数据查准率。陈超美教授认为,“相对于不断精炼和清洗检索结果直到将所有无关的研究主题都排除在外(优先查准率),更有效的办法是留着它们(优先查全率),在对生成的科学知识图谱解读的时候可以跳过这些研究聚类或分支”。(Chen, 2017)
(二)数据分析阶段的对比
1.“优化范式”的数据分析
在数据分析阶段,我们主要进行描述性统计分析、共被引网络和时间轴网络分析、典型聚类分析和研究前沿分析。这里仅对各项分析的内容和结论进行概述。
(1)描述性统计分析
对2001—2019年历年CSSCI期刊有关人工智能在教育领域应用文献的发文量、研究机构发文量等指标进行统计并绘制热力图进行可视化分析。
(2)共被引网络和时间轴网络分析
基于2001—2019年CSSCI有关国内人工智能在教育领域应用的文献,合成文献共引分析网络视图,如图4所示。该网络共包含32,344条引文信息,被划分为15个聚类(cluster)。2001—2019年国内人工智能在教育领域应用的文献主要围绕这15个主题展开。
进一步使用CiteSpace中的时间轴功能对15个聚类沿水平时间线进行可视化,展现各个聚类发展演变的时间跨度和研究进程,如图5所示。各个聚类(子领域)的可持续性在时间轴中清晰地展示出来。
(3)典型聚类分析
对15个聚类进行合并、删减,选取具有代表性的5个聚类,如表2所示。在数据解读阶段的对比中,我们将基于聚类1“人工智能”进行解读。
(4)研究前沿分析
通过CiteSpace生成2001—2019年CSSCI国内人工智能在教育领域应用文献突显词列表,如图6所示。2011年以来“个性化学习”“智慧校园”“物联网”“智慧学习环境”“教育信息化”等词汇被引用量突增。说明以上词汇是近年来国内人工智能在教育领域应用的研究前沿。2007年物联网的兴起以及相应大数据挖掘技术的成熟,使与物联网和学习分析相关的自适应推荐系统、智慧学习环境开始逐步完善并得到推广,学生个性化学习成为可能,而智慧学习环境的完善进一步推动了智慧学习的发展。我们认为,CSSCI文献体现出的国内人工智能在教育领域应用研究的前沿,主要聚焦于智慧学习环境的构建和相关技术支持。
2.“对比范式”的数据分析
“对比范式”在完成数据收集和清洗之后就对最终1,086条文献记录进行研究热点分析和前沿分析。
对比两个范式的数据分析阶段,如表3所示。在数据分析阶段“优化范式”和“对比范式”均采用CiteSpace进行数据处理,处理手法类似。
(三)数据解读阶段的对比
1.“优化范式”的数据解读
“优化范式”的数据解读是对典型聚类分析结果的解读。每一个典型聚类都提供主题词解读、时间轴解读和重要被引文献的图谱和研究内容。这里以聚类1“人工智能”为例。
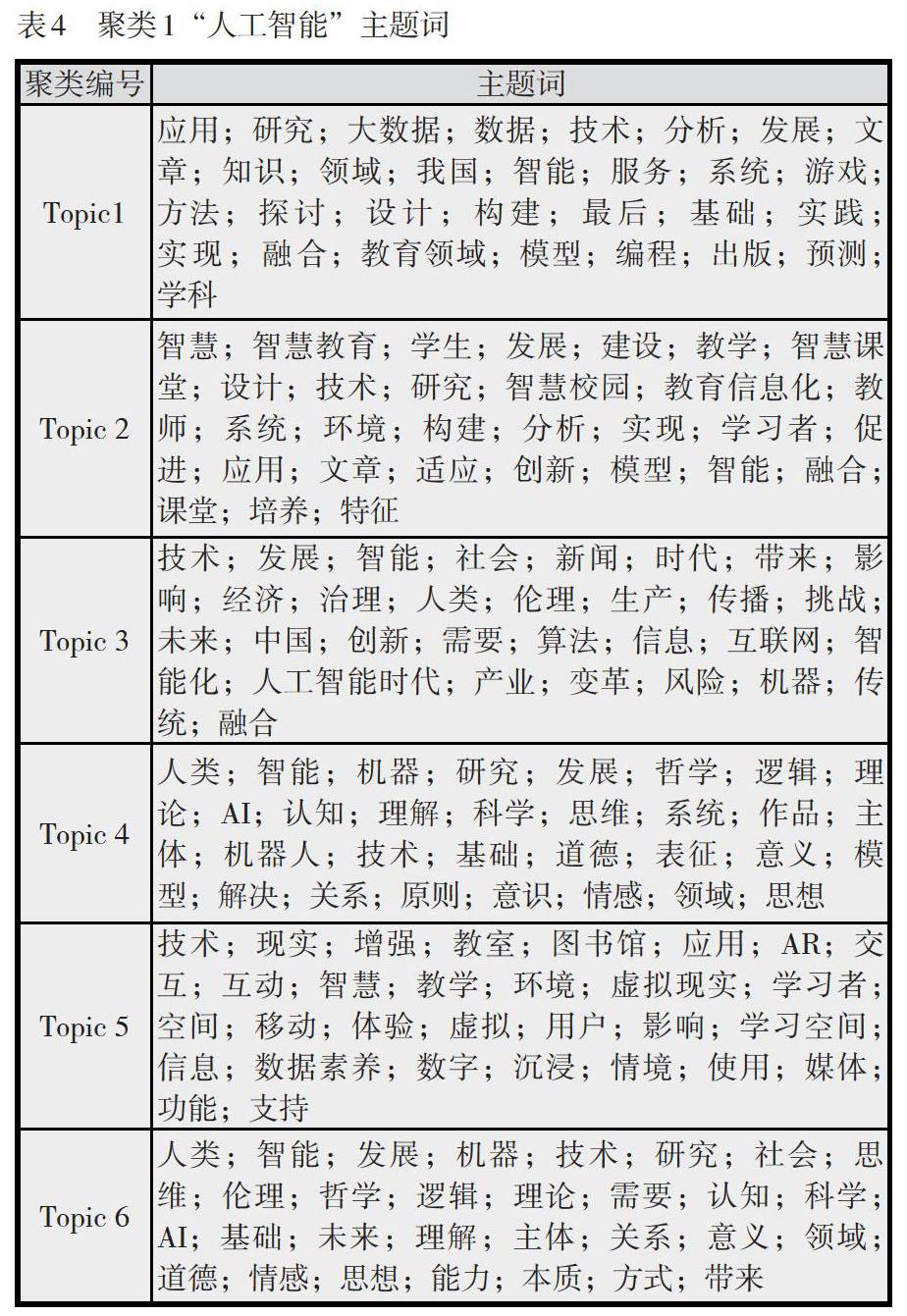
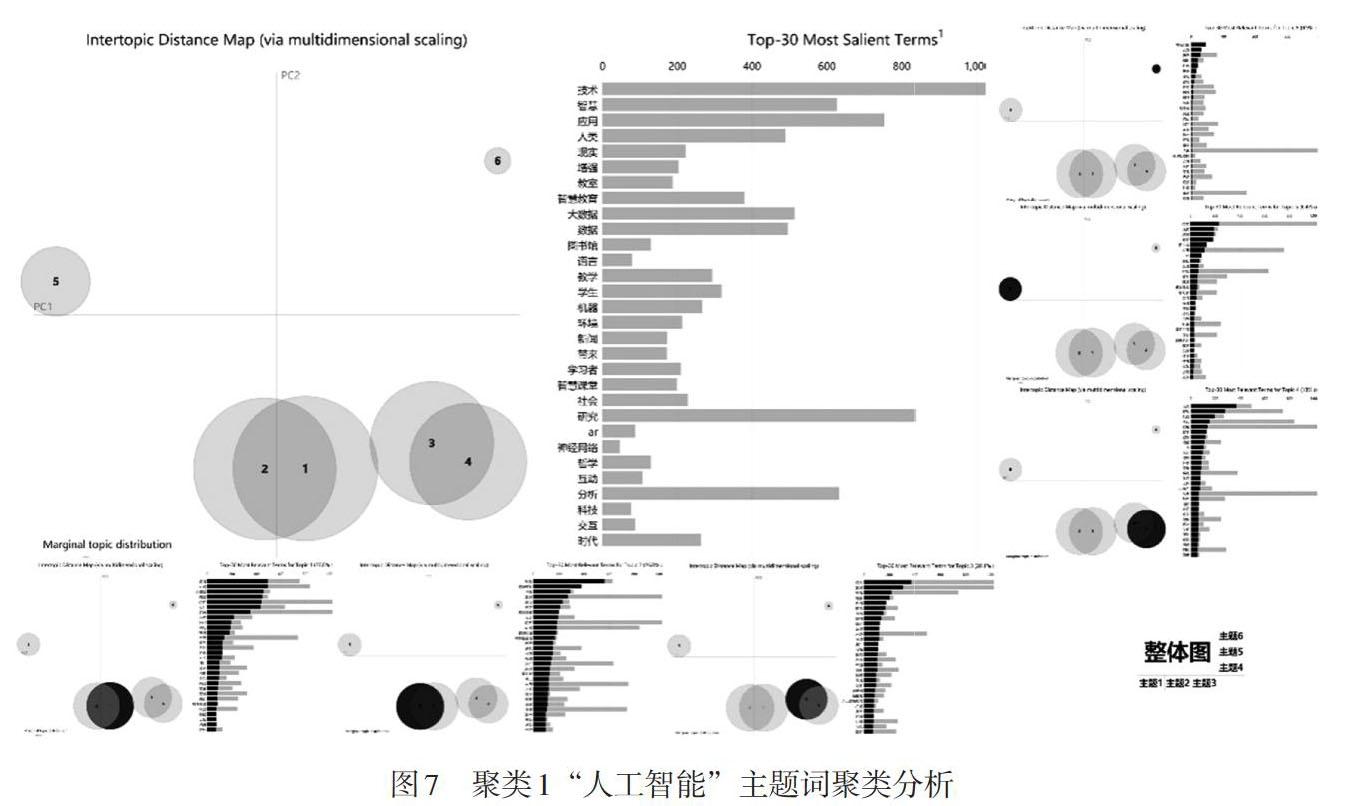
人工智能聚类是目标领域中最大聚类。我们筛选出包含该聚类关键词的文献共1,205篇,占本研究总数据的81%。使用LDA模型对筛选结果的摘要部分进行主题抽取,共得到6个主题,如表4所示,对主题词做进一步可视化处理,如图7所示。
在聚类分析图谱中,不同主题之间的距离代表主题之间的关联性,研究者可以据此将图谱划分为不同区域(Sievert, C., et al., 2014)。结合图7和表4可以将6个主题划分为4部分,分别是位于第一象限的主题6“国外人工智能的应用”,位于第二象限的主题5“人工智能技术在学校教学环境中的应用”,位于第三、四象限的主题2“智慧教育”和主题1“教育大数据”,位于第四象限的主题3“人工智能技术对传播等领域的影响”和主题4“人工智能的哲学思辨”。其中,主题1和主题2、主题3和主题4存在较大重叠,其原因是教育领域中教育大数据为智慧学习环境提供数据支撑,二者相互依托;人工智能在各个领域的应用导致对其存在的优势和隐患的反思。基于可视化结果,我们认为2001—2019年CSSCI人工智能在教育领域应用文献在聚类1中主要关注以上6个主题。
本研究结合图8在时间轴中出现的高被引作者,筛选出该聚类下影响最大的25位被引用作者和相应文献,如图9所示。对以上28篇文献进行分析后发现,聚类1的研究主要可以分为三大类:大数据在学校治理(教育管理)中的应用、基于教育大数据的学习分析应用、基于人工智能的教育应用。
在分类1中,研究者主要针对大数据为学校治理提供宏观层面支持进行阐述。宏观层面涵盖教育相关法律制度、管理方式、教学模式、教学观念、个性化教育、专业人才培养和专业课程建设,通过教育大数据的支持帮助决策者发现教育规律、实现精准管理(张燕南, 2013; 柯清超, 2013; 朱建平, 2014; 周湘林, 2014; 张俊超, 2014; 吴志龙, 2015; 孙洪涛, 2016; 姚松, 2016; 钟婉娟, 2016)。
在分类2中,研究者基于教育大数据进行学习分析。研究者搭建或借助现有教学平台采集教育大数据(结构化、非结构化数据),通过学习分析技术构建各类学习者模型,并基于模型绘制学习者肖像、实现学习者个性化学习、预测学习者行为、完成教育评价(李青, 2012; 武法提, 2014; 孟玲玲, 2014; 郑燕林, 2015; 牟智佳, 2016; 武法提, 2016; 张治, 2017; 牟智佳, 2018; 蒋鑫, 2019)。
在分类3中,研究者主要阐述人工智能技术在教育中的应用。与分类2聚焦于学习分析不同,分类3从单纯的数据驱动扩展到线下硬件和情境支持。更加关注自适应学习系统、智能学习空间设计以及人工智能对个性化学习的整体支持(贾积有, 2010; 徐鹏, 2011; 牟智佳, 2017; 张坤颖, 2017; 刘德建, 2018; 许亚锋, 2018; 张治, 2018)。
2.“对比范式”的数据解读
“对比范式”在完成数据收集和清洗之后,使用CiteSpace处理1,086条文献记录。依据关键词聚类得到12个聚类,并进一步归纳为3个大类。在数据分析阶段通过分析聚类特征词(文献的高频关键词)实现对该聚类的解读。
对比两个范式的数据解读阶段,如表5所示,可以发现由于使用LDA模型对摘要数据集进行了主题词抽取分析和可视化呈现,“优化范式”在数据解读阶段能够对目标聚类做出更加系统、客观、具体的解读,而“对比范式”的数据解读由于过多依赖研究者自身知识背景导致解读存在主观性和片面性。
六、讨论和结论
(一)研究结论
本研究提出的“优化范式”并不是对已有中文期刊CiteSpace研究范式的颠覆,而是对目前研究范式进行调整和补充。通过完善中文文献检索策略和文献数据处理技术,采用更加系统全面的检索策略和数据清洗方式整合CNKI和CSSCI索引数据。该方法使中文期刊CiteSpace研究来源数据更加丰富,将非结构化数据“摘要”纳入数据集中。我们使用NLP主题挖掘的典型模型LDA模型处理论文摘要数据,增强了中文期刊CiteSpace研究内容的深度和系统性。对摘要数据的分析使CiteSpace数据分析不再局限于对结构化数据的统计分析,能够获取更加深入和立体的可视化数据,为解读提供依据。
本研究以对国内人工智能在教育领域应用的研究文献的分析为例验证了“优化范式”的可操作性。通过应用“优化范式”,增加目标领域引文摘要数据的采集和分析,规范数据解读流程,得到更加清晰的可视化数据。在数据解读环节,基于LDA模型可视化结果发现聚类1中包括人工智能技术在学校教学环境中的应用、智慧教育、教育大数据等六个主题。在对关键被引文献的梳理中得到大数据在学校治理(教育管理)中的应用、基于教育大数据的学习分析应用、基于人工智能的教育应用三个研究子类,这三个子类的具体内容与LDA模型可视化结果大部分重叠。使用“优化范式”得到的解读结果更加客观、可信,能够为今后该领域研究提供更加具体的趋势预测。
(二)研究展望
本研究使用LDA模型对文献摘要进行降维可视化处理,借助对摘要部分信息的深度挖掘来克服研究者主观经验造成的影响。但是在实际使用中我们发现,聚类出来的主题词分析依旧需要通过人工进行整合和阐述。我们希望在下一阶段的研究中能够通过深度神经网络实现对主题词的文本生成,研究者僅负责对最后生成的主题句进行筛选。
[参考文献]
曾利,李自力,谭跃进. 2014. 基于动态LDA的科研文献主题演化分析[J]. 软件,35(05):102-107.
陈悦,等. 2014. 引文空间分析原理与应用[M]. 北京:科学出版社.
范云满,马建霞. 2014. 基于LDA与新兴主题特征分析的新兴主题探测研究[J]. 情报学报,33(07):698-711.
关鹏,王曰芬,傅柱. 2016. 不同语料下基于LDA主题模型的科学文献主题抽取效果分析[J]. 图书情报工作,60(02):112-121.
郭丽君,陈春平. 2019. 我国教师专业发展研究的知识图谱——2002—2017年CSSCI期刊的文献计量分析[J]. 现代教育管理,(02):86-92.
何灿娟,徐文彬. 2017. 当代新教师专业发展研究现状:基于知识图谱CiteSpace的分析[J]. 上海教育科研(07):15-19.
何建云,陈兴蜀,杜敏,等. 2015. 基于改进的在线LDA模型的主题演化分析[J]. 中南大学学报(自然科学版),46(02):547-553.
胡三华,汪晓东. 2004. 博客在教育教学中的应用初探[J]. 远程教育杂志(01):10-12.
黄鲁成,张璐,吴菲菲,等. 2016. 基于突现文献和SAO相似度的新兴主题识别研究[J]. 科学学研究,34(06):814-821.
贾积有. 2010. 国外人工智能教育应用最新热点问题探讨[J]. 中国电化教育(07):113-118.
蒋鑫,洪明. 2019. 国际教育大数据研究的热点[J]. 中国远程教育(02):26-38.
柯清超. 2013. 大数据与智慧教育[J]. 中国教育信息化(24):8-11.
李青,王涛. 2012. 学习分析技术研究与应用现状述评[J]. 中国电化教育(08):129-133.
李韬,赵雯. 2019. 国内学术英语研究述评[J]. 外语电化教学(03):22-27.
李湘东,张娇,袁满. 2014. 基于LDA模型的科技期刊主题演化研究[J]. 情报杂志,33(07):115-121.
林萍,黄卫东. 2014. 基于LDA模型的网络突发事件话题演化路径研究[J]. 情报科学,32(10):20-23.
刘德建,杜静,姜男,黄荣怀. 2018. 人工智能融入学校教育的发展趋势[J]. 开放教育研究,24(04):33-42.
刘勇,生晓婷,李青. 2018. 人工智能在我国教育领域应用的可视化分析[J]. 现代教育技术,28(10):27-34.
孟玲玲,顾小清,李泽. 2014. 学习分析工具比较研究[J]. 开放教育研究,20(04):66-75.
孟宇,陈坚林. 2019. 信息化时代外语学习方式动态演进研究——基于CiteSpace的可视化分析[J]. 外语教学理论与实践(04):34-40.
闵光辉. 2020. 大数据背景下我国成人教育研究的热点及路径——基于CNKI数据库的Citespace可视化和批判阅读法分析[J]. 中国成人教育(04):19-23.
牟智佳. 2016. 学习者数据肖像支撑下的个性化学习路径破解——学习计算的价值赋予[J]. 远程教育杂志,34(06):11-19.
牟智佳. 2017. “人工智能+”时代的个性化学习理论重思与开解[J]. 远程教育杂志,35(03):22-30.
牟智佳,李雨婷,严大虎. 2018. 混合学习环境下基于学习行为数据的学习预警系统设计与实现[J]. 远程教育杂志,36(03):55-63.
任利强,郭强,王海鹏,张立民. 2018. 基于 CiteSpace 的人工智能文献大数据可视化分析[J]. 计算机系统应用,27(6):18-26.
任艳莉,王彤. 2018. 国内信息素养教育研究知识图谱分析:基于CSSCI论文(2008-2018)[J]. 黑龙江高教研究(09):36-39.
孙洪涛,郑勤华. 2016. 教育大数据的核心技术、应用现状与发展趋势[J]. 远程教育杂志,34(05):41-49.
王建华,周莹,张静茗. 2019. 中国影视翻译研究三十年(1989—2018)——基于CiteSpace的可视化分析[J]. 上海翻译(02):33-38.
吳志龙. 2015. 大数据时代下高校辅导员预警能力研究[J]. 国家教育行政学院学报(04):62-66.
武法提,牟智佳. 2014. 电子书包中基于大数据的学生个性化分析模型构建与实现路径[J]. 中国电化教育(03):63-69.
武法提,牟智佳. 2016. 基于学习者个性行为分析的学习结果预测框架设计研究[J]. 中国电化教育(01):41-48.
徐坚,王维平. 2017. 我国人工智能教育发展及现状研究——基于 1976—2017 年中文文献的 CiteSpace 可视化分析[J]. 信息化研究,43(6):1-6.
徐鹏,王以宁. 2011. 国内自适应学习系统的研究现状与反思[J]. 现代远距离教育(01):25-27.
徐鹏,王以宁,刘艳华,张海. 2013. 大数据视角分析学习变革[J]. 远程教育杂志,31(06):11-17.
许亚锋,高红英. 2018. 面向人工智能时代的学习空间变革研究[J]. 远程教育杂志,36(01):48-60.
姚松. 2016. 大数据与教育治理现代化:机遇、挑战与优化路径[J]. 湖南师范大学教育科学学报,15(02):76-80.
张洪孟,胡凡刚. 2015. 教育虚拟社区:教育大数据的必然回归[J]. 开放教育研究,21(01):44-52.
张华阳,梁文玲. 2018. 全球教师专业发展研究的新进展——基于WOS数据库的检索[J]. 教育导刊(07):82-87.
张俊超. 2014. 大数据时代的院校研究与大学管理[J]. 高等工程教育研究(01):128-135.
张坤颖,张家年. 2017. 人工智能教育应用与研究中的新区、误区、盲区与禁区[J]. 远程教育杂志,35(05):54-63.
张燕南,赵中建. 2013. 大数据时代思维方式对教育的启示[J]. 教育发展研究,33(21):1-5.
张志强. 2015. 建设现代大学制度完善高等教育治理体系[J]. 教育探索(06):55-58.
张治,戚业国. 2017. 基于大数据的多源多维综合素质评价模型的构建[J]. 中国电化教育(09):69-77.
张治,刘小龙,余明华,祝智庭. 2018. 研究型课程自适应学习系统:理念[J]. 中国电化教育(04):119-130.
郑燕林,柳海民. 2015. 大数据在美国教育评价中的应用路径分析[J]. 中国电化教育(07):25-31.
钟婉娟,侯浩翔. 2016. 大数据视角下教育决策机制优化及实现路径[J]. 教育发展研究,36(03):8-14.
周湘林. 2014. 大数据时代的教育管理变革[J]. 中国教育学刊(10):25-30.
朱建平,李秋雅. 2014. 大数据对大学教学的影响[J]. 中国大学教学(09):41-44.
Borko, H.(2004). Professional Development and Teacher Learning: Mapping the Terrain. Educational Researcher,33(8):3-15.
Chen, C.(2017). Science Mapping:A Systematic Review of the Literature.数据与情报科学学报:英文版,2(2):1-40.
Chen, C., Hu, Z., Liu, S., et al. (2012). Emerging trends in regenerative medicine: a scientometric analysis in CiteSpace.Expert Opinion on Biological Therapy,12(5):593-608.
Kuhn, T. S. 1962. The structure of scienti?c revolutions.Chicago and London.
Lu, T., & Hu, X. (2019). Overview of Knowledge Mapping Construction Technology. In 2019 IEEE 8th Joint International Information Technology and Artificial Intelligence Conference (ITAIC) (pp. 1572-1578). IEEE.
Jing, L., Ruyu, X., & Anling, S. (2019). Analysis on Research Frontiers and Hotspots of “Artificial Intelligence Plus Education” in China-Visualization Research Based on Citespace V. In IOP Conference Series: Materials Science and Engineering (Vol. 569, No. 5, p. 052073). IOP Publishing.
Sievert, C., & Shirley, K. (2014, June). LDAvis: A method for visualizing and interpreting topics. In Proceedings of the workshop on interactive language learning, visualization, and interfaces (pp. 63-70).
Stopar, K., & Bartol, T. (2019). Digital competences, computer skills and information literacy in secondary education: mapping and visualization of trends and concepts. Scientometrics, 118(2), 479-498.
Tho, S. W., Yeung, Y. Y., Wei, R., Chan, K. W., & So, W. W. M. (2017). A systematic review of remote laboratory work in science education with the support of visualizing its structure through the histcite and citespace software. International Journal of Science and Mathematics Education, 15(7), 1217-1236.
Wang, J., Chen, S. C., Wang, L. L., & YANG, X. M. (2016). The analysis of research hot spot and trend on big data in education based on CiteSpace. Modern Educational Technology, 26(2), 5-13.
Wang, B., & Wang, Z. (2018). Analysis of mapping knowledge domains of tennis teaching research in China. Educational Sciences: Theory & Practice, 18(6).
Wang, F., & Tao, X. (2018). Visual Analysis of the Application of Artificial Intelligence in Education. In 2018 International Joint Conference on Information, Media and Engineering (ICIME) (pp. 187-191). IEEE.
Webster-Wright A. (2009). Reframing Professional Development through Understanding Authentic Professional Learning. Review of Educational Research, 79(2): 702-739.
White, H. D., Griffith, B. C. (1981). Author cocitation: A literature measure of intellectual structure. Journal of the American Society for information Science,32(3):163-171.
Wu, Z., Yang, F. (2020). A Thematic Analysis Method of Academic Documents Based on TF-IDF and LDA. Computer Technology and Development, 30(1).
Yu, L., Wu, D., Zhu, S., & Li, H. (2018). Visualizing and Understanding Information literacy Research Based on the CiteSpaceV. In Challenges and Solutions in Smart Learning (pp. 113-118). Springer, Singapore.
Zhao, Y., Shan, C., Dong, H., & Hu, G. (2016). Evolution path and research hotspot in international information literacy education field based on citespace II. In Proceedings of the 2nd International Conference on Communication and Information Processing (pp. 79-82).
收稿日期:2020-02-29
定稿日期:2020-05-06
作者簡介:贾维辰,博士研究生,澳门城市大学教育学院(999078)。
李文光,本文通讯作者,博士,硕士生导师,副教授,深圳大学教育信息技术系(518060)。
余明媚,硕士,南方科技大学高等教育研究中心(518055)。
责任编辑 张志祯 刘 莉
猜你喜欢
甘肃教育(2021年10期)2021-11-02
福建江夏学院学报(2021年6期)2021-08-10
少先队活动(2020年12期)2021-01-14
大连民族大学学报(2020年2期)2020-06-16
英美文学研究论丛(2018年1期)2018-08-16
电子测试(2017年15期)2017-12-18
中成药(2017年3期)2017-05-17
雷达学报(2017年6期)2017-03-26
电子设计工程(2015年6期)2015-02-27
华东师范大学学报(自然科学版)(2014年6期)2014-02-27
