
并行传输程序中时序数据相似性检测软件设计
2020-12-28 02:10李学威张瑞
电脑知识与技术 2020年33期
关键词:相似性
李学威 张瑞

摘要:针对并行传输程序中时序数据相似性检测受到网络攻击的影响,以提高时序数据相似性检测性能为目的,提出了并行传输程序中时序数据相似性检测软件设计。结合时间序列相似性度量算法,分析了并行传输程序中时序数据,通过对比不同度量方法的优点,完成时序数据的相似性度量,在处理各块时序数据的基础上,以动态的方式生成聚类网格,并将时序数据逐个映射到相应聚类网格上,完成时序数据的聚类,最后利用时序数据相似性检测程序设计,实现了并行传输程序中时序数据相似性的检测。实验结果表明,提出的并行传输程序中时序数据相似性检测软件可以提高时序数据相似性检测性能。
关键词:并行传输程序;时序数据;相似性;检测软件
中图分类号:TP391 文献标识码:A
文章编号:1009-3044(2020)33-0071-03
开放科学(资源服务)标识码(OSID):
时序数据是随着时间的变化而形成的有序数据序列,时序数据集反映了数据随着时间变化的过程状态,可以采用实际的数值或符号来定义[1]。随着时代的变迁,并行传输程序中产生了大量的时序数据,时序数据在不断地累积过程中,如何分析和处理并行传输程序中的时序数据相似性已经成为一种必要需求。并行传输程序中时序数据相似性检测是指将对时间序列中单位数据点的数值进行度量,对超出阈值或者阈值范围内的时序数据点进行告警[2]。针对并行传输程序中时序数据的相似性检测,传统的检测方法往往存在一定局限性,无法在相同的场景中进行相关技术知识的迁移和推广。
人们在日常生活中产生的社会、经济、政治、文化、食物、衣着、住房、交通等各种数据,都是通过计算机软件技术的字节数据进行传输和存储的。在世界各地,各种活动都会产生大量的数据。爆炸式的过程数据增长、通用的数据标准以及庞大的时序数据信息库,将人类社会带人了真正的虚拟数据时代[3]。因此,如何找到一种通用性和兼容性好、且功能强大的数据分析工具,对并行传输程序中时序数据集进行统计分析,并从中提炼出更多有价值的时序数据信息,早就成了数据时代的必然要求[4]。如何并行传输程序中时序数据进一步系统化,形成更加有效的理论知识,为人类社会的生产和实践乃至调度决策,提供相应的数据支持和理论帮助,已经成为数据时代的必然要求。时序数据相似性检测软件正是基于这一需求而产生的,它在人类社会各行各业中的作用也越来越重要[5]。
基于以上背景,本文设计了并行传输程序中时序数据相似性检测程序,从而提高时序数据相似性检测性能。
1 时序数据相似性检测软件设计
1.1度量时序数据的相似性
在度量时序数据相似性过程中,结合时间序列相似性度量算法,提出了基于支持增量数据的时序数据相似性度量算法。在并行传输程序中时序数据的分析中,计算时序数据相似性是一个重要且基本的问题,通常被应用在时序数据的聚类、相似性搜索、分类和预测中,因此并行传输程序中时序数据相似性度量的好坏直接影响时序数据的分析结果[6]。时序数据相似性度量有以下几种方法:
1.1.1符号化距离
把并行传输程序中的时序数据转换为字符串的形式,然后对转换后的字符串进行相似性度量,这是符号距离的主要思想。符号距离测量的著名方法是以欧几里德距离为基础的。首先将原始时间序列数据转换为满足标准高斯分布值的序列,然后利用SAX表示法将其转换为字符串的形式。极大公共子串问题可视为时间序列数据的符号距离度量[7]。传统的解决方法是采用动态规划法,得到两个字符串的最大公共子串,它的异构性是O(m*n)。很明显,这种方法对于解决较长的时间序列数据的相似度量是无效的。
1.1.2 动态时间弯曲
动态时间弯曲是一种广泛使用的时间序列数据相似性度量方法,它既能对非均等时间序列数据的相似性进行度量,又能对异常时序数据进行相似性度量。其不利之处是时间效率低,长时间序列数据的相似度不高。
由于动态时间弯曲的时间复杂度一般情况下为O(n2),因此对于比较长的两个时间序列数据,在计算过程中耗费的时间往往也是比较长的,不能满足动态时间弯曲的实际需求。当前,研究者们对如何提高动态时间弯曲的时间性能进行了比较深入的研究,其中,快速时间弯曲是经典动态时间弯曲的一种近似方法,它综合利用了约束和时序数据提取两种方法来加快计算速度。該方法首先对原始时间序列数据进行抽象,即通过具体的算法对时间序列数据进行粗粒度处理,再对时间序列数据进行粗粒度计算[8]。在粗粒度条件下,得到的规则路径经过的方块被进一步细化成细粒度的时间序列,并与之前的结果进行了比较。在此基础上,利用动态时间弯曲缩小了时序数据的搜索空间,得到了动态弯曲距离。由于动态时间弯曲影响因素较多,算法的时间复杂度为线性时间复杂度。此外,还提出了一种满足动态时间弯曲下要求的测距方法——快速计算相似度搜索法。
1.1.3其他距离度量方法
时序数据的长度往往超过了正常时序数据的维度,为了进一步提高时序数据的搜索效率,需要对时序数据特征进行变换,通过降维法来提高相似性搜索的效率;在建立时间序列模型的基础上,计算一段时间序列数据产生另一段时间序列数据的相似度,得出相似度度量结果。
1.2聚类时序数据
并行传输程序中时序数据的聚类分为时序数据的在线处理和离线处理两个过程,时序数据在线处理过程中,对各块时序数据进行处理,以动态的方式生成聚类网格,并将时序数据逐个映射到相应聚类网格上。采用密度门限将在线处理算法生成的聚类网格分为稠密聚类网格、过渡聚类网格和稀疏聚类网格[9]。对密集聚类网格、过渡聚类网格和稀疏聚类网格分别采用不同的处理方法得到时序数据聚类集,并将其存储到时序数据库中。离线时序数据处理过程中,根据不同用户对时序数据的需求,抽取一定时间范围内的时序数据聚类集合,通过判断两个时序数据集合是否具有相似性,再对数据进行聚类,得到最终的聚类结果。
传统意义上的固定划分网格方法不能适应并行传输程序中时序数据的相似性特征,而且固定劃分网格一旦划分就不可以发生改变。为了避免这一问题产生,本文在聚类时序数据时引入了动态生成网格方法,根据时序数据的特征生成相应的网格[10]。
当时序数据块内有n个时序数据单元时,先采集时序数据块内部的时序数据单元特征,通过计算时序数据单元在每一个维度属性的均值δj,确定网格单元内每一个维度空间的划分长度hi。时序数据每一个维度属性的均值为:
网格单元的处理方法有两种,包括稠密网格处理及过渡网格和稀疏网格处理。稠密网格处理是以网格的中心点作为顶点,如果选取的任意两个网格都是相邻的,就为其中一个网格赋予一条边,生成一个稠密且没有方向的有权图,通过利用深度优先算法获取有权图的连通分支,从而得到一个稠密网格簇集合;过渡网格处理必须先计算稠密网格中的所有点距网格中心距离的标准差。令任意一个网格单元为gm,其标准差为:
1.3 设计时序数据相似性检测程序
在完成并行传输程序中时序数据空间网格划分的基础上,采用二元正态密度核函数,来计算时序数据在任意一个单元格的密度估计值,计算公式为:
根据上述的计算过程,将并行传输程序中的异常区域看作是满足一定条件的相邻密度值相同,或者是近似单元格连成的区域,并行传输程序中异常区域的判断为:
其中,d (δ1)和d(δ2)分别表示并行传输程序中两个相邻单元格的密度估计值,ε表示并行传输程序中异常区域的判断阈值。
根据上述步骤检测,获得并行传输程序的异常区域之后,需要进一步检测并行传输程序中异常区域的时序数据活动位置随时间的变化情况,完成时序数据的检测。假设Oi和ARi分别表示并行传输程序中任意一个时序数据和异常区域,将异常区域转换为二进制序列,即:
B=b1b2…bi…bn
(8)
由于并行传输程序中时序数据频谱泄露或其他原因得到了一系列候选周期图,为了避免并行传输程序存在不正确和虚假报警现象,通过引入自相关函数来检验得到的候选周期图,确定并行传输程序中异常区域时序数据变化周期,并行传输程搜索空间,得到了动态弯曲距离。由于动态时间弯曲影响因素较多,算法的时间复杂度为线性时间复杂度。此外,还提出了一种满足动态时间弯曲下要求的测距方法——快速计算相似度搜索法。
1.1.3其他距离度量方法
时序数据的长度往往超过了正常时序数据的维度,为了进一步提高时序数据的搜索效率,需要对时序数据特征进行变换,通过降维法来提高相似性搜索的效率;在建立时间序列模型的基础上,计算一段时间序列数据产生另一段时间序列数据的相似度,得出相似度度量结果。
1.2聚类时序数据
并行传输程序中时序数据的聚类分为时序数据的在线处理和离线处理两个过程,时序数据在线处理过程中,对各块时序数据进行处理,以动态的方式生成聚类网格,并将时序数据逐个映射到相应聚类网格上。采用密度门限将在线处理算法生成的聚类网格分为稠密聚类网格、过渡聚类网格和稀疏聚类网格[9]。对密集聚类网格、过渡聚类网格和稀疏聚类网格分别采用不同的处理方法得到时序数据聚类集,并将其存储到时序数据库中。离线时序数据处理过程中,根据不同用户对时序数据的需求,抽取一定时间范围内的时序数据聚类集合,通过判断两个时序数据集合是否具有相似性,再对数据进行聚类,得到最终的聚类结果。
传统意义上的固定划分网格方法不能适应并行传输程序中时序数据的相似性特征,而且固定划分网格一旦划分就不可以发生改变。为了避免这一问题产生,本文在聚类时序数据时引入了动态生成网格方法,根据时序数据的特征生成相应的网格[10]。
当时序数据块内有n个时序数据单元时,先采集时序数据块内部的时序数据单元特征,通过计算时序数据单元在每一个维度属性的均值δj,确定网格单元内每一个维度空间的划分长度hi。时序数据每一个维度属性的均值为:
网格单元的处理方法有两种,包括稠密网格处理及过渡网格和稀疏网格处理。稠密网格处理是以网格的中心点作为顶点,如果选取的任意两个网格都是相邻的,就为其中一个网格赋予一条边,生成一个稠密且没有方向的有权图,通过利用深度优先算法获取有权图的连通分支,从而得到一个稠密网格簇集合;过渡网格处理必须先计算稠密网格中的所有点距网格中心距离的标准差。令任意一个网格单元为gm,其标准差为:
1.3 设计时序数据相似性检测程序
在完成并行传输程序中时序数据空间网格划分的基础上,采用二元正态密度核函数,来计算时序数据在任意一个单元格的密度估计值,计算公式为:
根据上述的计算过程,将并行传输程序中的异常区域看作是满足一定条件的相邻密度值相同,或者是近似单元格连成的区域,并行传输程序中异常区域的判断为:
其中,d (δ1)和d(δ2)分别表示并行传输程序中两个相邻单元格的密度估计值,ε表示并行传输程序中异常区域的判断阈值。
根据上述步骤检测,获得并行传输程序的异常区域之后,需要进一步检测并行传输程序中异常区域的时序数据活动位置随时间的变化情况,完成时序数据的检测。假设Oi和ARi分别表示并行传输程序中任意一个时序数据和异常区域,将异常区域转换为二进制序列,即:
B=b1b2…bi…bn
(8)
由于并行传输程序中时序数据频谱泄露或其他原因得到了一系列候选周期图,为了避免并行传输程序存在不正确和虚假报警现象,通过引入自相关函数来检验得到的候选周期图,确定并行传输程序中异常区域时序数据变化周期,并行传输程
序中时序数据相似性检测。
2 实验对比分析
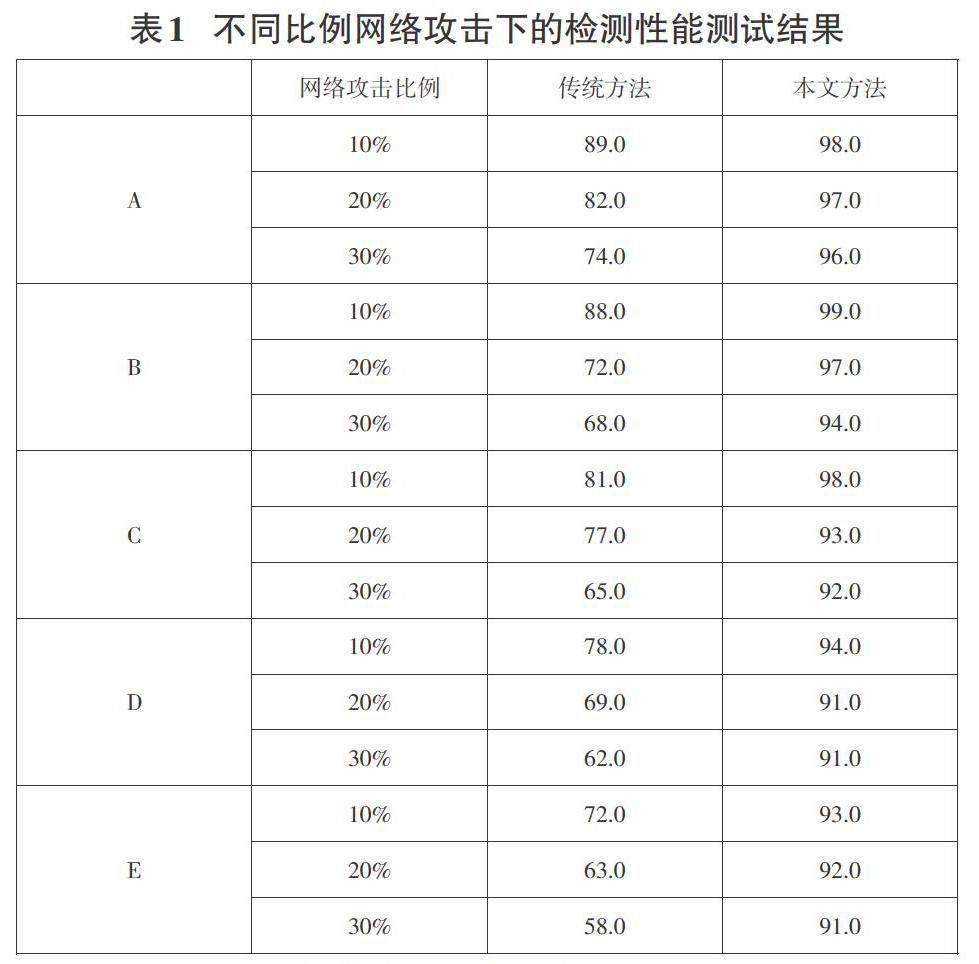
为了进一步验证并行传输程序中时序数据相似性检测软件的可行性,采用传统时序数据相似性检测软件做对比,对比测试注入不同比例的网络攻击时,两种时序数据相似性检测软件的检测准确率,对比结果如表1所示。
猜你喜欢
数学物理学报(2022年5期)2022-10-09
世界科学技术-中医药现代化(2021年9期)2021-12-31
河北画报(2020年8期)2020-10-27
浙江大学学报(工学版)(2016年2期)2016-06-05
核科学与工程(2015年3期)2015-09-26
电子设计工程(2015年3期)2015-02-27
电测与仪表(2014年6期)2014-04-04
燕山大学学报(2014年1期)2014-03-11
计算机工程(2014年6期)2014-02-28
俄罗斯问题研究(2013年1期)2013-03-11
