
基于搜索词条的用户画像研究与实现
2020-12-28 02:10彭梅胡必波章家宝
电脑知识与技术 2020年33期
彭梅 胡必波 章家宝


摘要:随着大数据时代的到来,其应有价值也越来越广泛,特别在“互联网+”商业推广中的“精准营销”更是发挥着重要的意义。该文利用用户的搜索记录文本为数据,进行分词处理、建模,采用SparkSql与hive进行整合(spark on hive)。首先,采用SparkSql对表中的元数据进行读取,再使用Spark引擎进行底层数据的分析处理达到高效为有搜索记录的用户建立标签从而构建用户画像的,达到构建智能推荐目的。最后,利用几种常用的分词工具对本文测试,并使用Bayes模型比较了它们在项目中的效果。
关键词:搜索记录;分词;用户画像;模型
中图分类号:TP3 文献标识码:A
文章编号:1009-3044(2020)33-0014-03
开放科学(资源服务)标识码(OSID):
1 构建用户画像的概述
1.1 构建用户画像的意义
随着大数据时代的到来,大数据在互联网产业中得到广泛应用,特别是电商、广告、服务搜索等方面的个性化和智能化的水平得到很大的提高,近年来大数据技术加快了对传统行业应用的渗透,驱动生产方式和管理模式进行变革,推动各行各业向网络化数字化、智能化发展,使得在“互联网+”这样一个宏观市场背景下,大数据技术对经济发展趋势的影响愈发举足轻重。
用户画像分析是指利用大数据技术的算法根据用户在互联网中行为推断用户特征的过程、手段和方法,同时也是对个体进行精确定位的手段,最后利用网联网web、手机应用等工具进行个性化推荐,个性化的搜索,在互联网+商业推广中的“精准营销”更是发挥着重要的意义。比如,你在某电商平台浏览或购买商品的行为发生时,就足够使得该网络商家掌握了你在该电商平台搜索记录等数据,他就可以利用大数据技术开发的第三方应用软件根据你购买商品的偏好和浏览轨迹进行同类产品精准推荐,这也说明了利用用户画像可以做到“精准营销”,是有非常有商业价值的。
1.2 用户画像的具体作用
1)精准营销,分析根据用户的行为,提取用户喜好标签,然后利用互联网等方式进行营销。
2)用户统计,根据高频用户行为分析全国高薪职业Top10。
3)數据挖掘,利用大数据技术构建智能推荐算法,利用关联规则计算,喜欢二次元的用户通常喜欢什么风格品牌,再使用大数据的聚类算法分析出喜欢二次元群体年龄段分布情况。
4)将传统的用户和市场的调研,利用大数据技术分析定位服务群体,完善产品运营,提供高水平的服务。
5)个性化服务,利用大数据技术通过用户画像进行分析,发现形象、价格区间偏好比重最大,那么就给新产品提供了非常客观有效的决策依据。
6)企业发展战略,利用大数据进行业务经营分析以及竞争分析可以及时调整企业发展战略。
1.3基于查询记录的用户画像难点
1)数据源,用户画像需要有大量的数据支持,并且需要较为全面的数据,基于查询记录的用户画像正是依靠非常多的用户查询记录来进行用户画像,用户繁多的查询记录可以给用户进行较为全面的画像。
2)业务结合,对于用户画像不能只存在于理论阶段,需要笔者团队根据实际的业务跟理论基础结合起来。
3)动态更新,因为查询业务是实时更新的用户数据,因此需要根据用户实时的查询数据来对于用户的画像结果进行实时更新,实现精准推荐。
4)用户画像中的处理细节展示。
5)大家知道,用SparkSql整合hive来进行电商用户画像,即使用Hive将hql语句转化为MapReduce来计算的设计方案很好,但因为Hive原因是基于MapReduce的,它会生成MapRe-duce Job,从而查询提交到结果返回需要查询时间非常长,我们可以利用Spark生成Spark Job的快速执行能力来缩短HiveHQL的响应时间。
6)本项目是利用用户的搜索记录文本为数据,进行分词处理、建模,采用SparkSql与hive进行整合(spark on hive)。首先,采用SparkSql对表中的元数据进行读取,再使用Spark引擎进行底层数据的分析处理达到高效为有搜索记录的用户建立标签从而构建用户画像的,达到构建智能推荐目的。最后,利用几种常用的分词工具对本文测试,并使用Baves模型比较了它们在项目中的效果。
2 数据处理
2.1 停用词处理
在实际的自然语言中,有很多的非实意词语或者其他并没有实际作用的词语,这些词语我们必须在分词环节后进行过滤处理即停用词处理。停用词处理的关键在于停用词的认定,我们可以通过使用停用词表,对停用词进行单独处理可以大大加快词语切分速度以及后续的句法分析归约速度,因此在进行分词处理及使用的NLP技术,如BOW,Count Vectorizer或F-IDF(词频和逆文档频率)特征计算的过程中,均保留了空格、标点以及停用词这些信息。
2.2 分词处理
分词就是将句子、段落、文章这种长文本,分解为以字词为单位的数据结构,方便后续的处理分析工作。由于词是信息载体的最小单位,所以分词处理是关键,分词目前已经有很多开源工具可以使用,比如中科大的ICTCIAS.IKanalyzer. hanlp等等。很多分词原理是用的CRF,即条件随机场,通过对词语的位置标注和词性等特征来进行分词。
3 系统设计
本项目中的文本为用户的搜索词条记录,这些词条长度通常短,使得对样本进行分词效果便显得较为重要。本文测试了几种常用的分词工具,并使用Bayes模型比较了它们在项目中的效果。
在本系统中,笔者团队根据数据所产生的误差对于数据进行后置处理也就是分析法中常说的错误分析,根据用户的查询记录以及笔者团队的算法得出了一些错误的样本,做错误样本分析的好处在于错误样本分析可以给模型优化指引方向。在进行错误样本分析的过程中,我们也找到了一些规律:对于属性值存在空缺的样本,我们首先使用属性值已知的样本作为训练样本,使用LR模型训练分类器,再对这部分属性空缺样本进行预测,从而补全空缺值。但我们发现在最终的两级多模型融合得到的结果中,对于教育属性空缺的样例,它们的年龄和性别预测准确率很低;对于年龄属性空缺的样例,教育预测准确率很低;对于性别属性空缺的样例,教育预测准确率很低。
3.1 用户画像建模
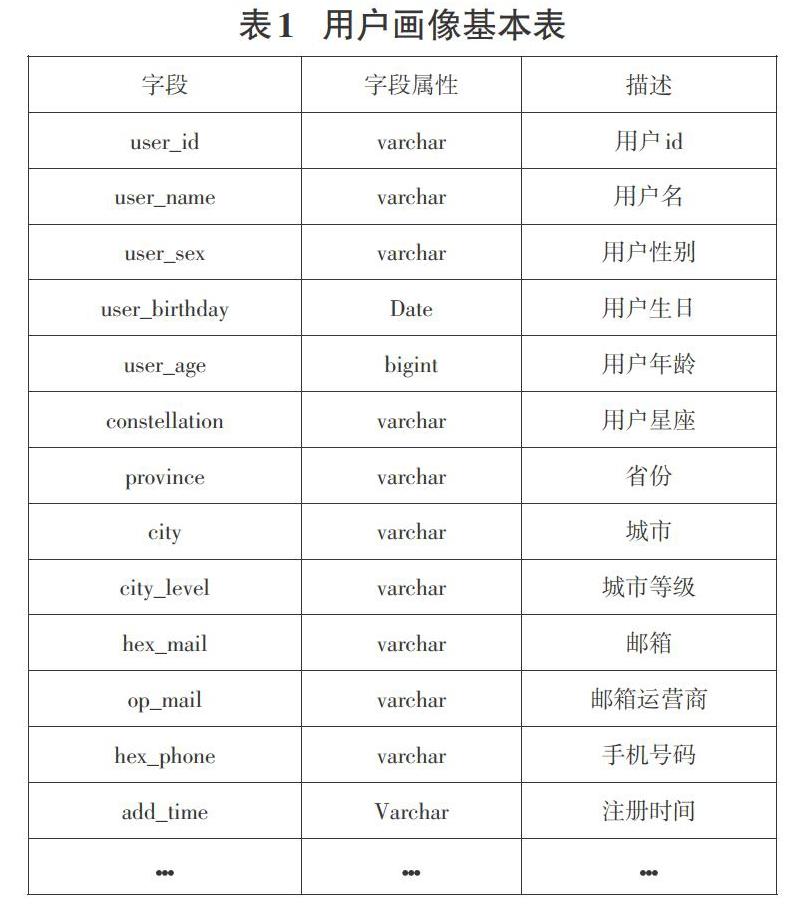
根据互联网上个人用户所填写资料信息如:性别,年龄,喜好等等,我们利用大数据技术进行数据处理,主要包括数据预处理,降维,分类,回归,聚类,模型选择等去掉不用的属性保留有用的数据信息,推算出用户标签,进行精准用户画像。比如大数据精准营销,涵盖用户的忠诚度可以分为忠诚型用户(会购买,并且不会对比其他家)、偶尔型用户(有优惠才会购买)、投资型用户、游览型用户、系统未能识别用户。本项目用户画像基本表如表1所示。
3.3 系统分析流程
系统分析流程如图2所示。
特征构造方式:多角度、多粒度、多维度。
优秀的特征群构建体系:特征表达能力强、自动化程度高、泛化能力强。
3.4 系统所用到的技术
系统用到的技术有:scala、hhase、hive、hadoop、spark、flume、sparksql、python、storm、kafka、mysql等,这里需要用到Sparksql+hive。
Spark SQL主要目的是使得用户可以在Spark上使用SQL,其数据源既可以是弹性分布式数据集或者文本、Hive、Json等外部的数据源。Spark on Hive是Spark SQL的其中一个分支也是使用Hive中HQL的解析、逻辑执行计划翻译、执行计划优化等逻辑,将物理执行计划从MR作业替换成Spark作业。Spark-Sql整合hive就是获取hive表中的元数据信息,然后通过Spark-Sql来操作数据。
具体的整合步骤为:
1)先将hive-site.xml文件拷贝到Spark的conf目录下,系统配置文件就能找到Hive的元数据以及数据存放位置。
2)准备Mysql相关驱动,比如:mysql-connectoI-java-5.1.49.jar。
3)进行整合成功测试,先启动hadoop集群,再启动spark集群确保启动成功之后执行命令:/var/local/spark/bin/spark-sql-master spark://itcast01:7077 -executoI-memory lg -total-exec-utor-coreS。
4)如果可以进入到命令行里面说明可以运行成功了。
4 具体实现
1) SecondSession该类主要是先读取到元数据,然后切分可用数据,读取到表的结构,创建一个视图,把需要的数据写入到视图里面去。首先先获取到SparkSession类的实例化,需要传人配置文件的信息,也就是如下代码段所示:val spark= Spark-Session. builder(). appName(”FirstSessionAnalysis”). config(”spark.testing.memory”,2147480000”).master(”local[*]).getOrCreate0然后我们需要创建一个rdd来读取元数据。井且创建表结构valschemas=”cookie,event,ispaid, data_date, time”.split(”,”).map(fp=> StructField(fp,StringType》获取到schemas然后运用前面创建的sparksession的实例化对象创建视图,写入关键信息即可。系统所用到的工具类:此类为该项目所用到的时间工具类,该类的第一个方法timeDiff主要是计算时间差,返回值为long类型。第二个方法为一个主方法,主要是测试timeDiff方法是否正确。并且打印出时间差。具体代码实现为:val df= new Sim-pleDateFormat(”yyyy-MM-dd HH:mm:ss”) val st= df.parse(start.toString) val et= df.parse(end.toString) val diff= et.getTime -st.getTime diffSec= diff/1000
2)Hive以及hbase的sc ala类,类描述:运用scala语言来编写hive以及hbase,首先定义一个判断字符串是否为空的方法,也就是def nuIIHandle(str: String):String,返回值为string,然后再创建一个主方法。不需要返回值。需要传人一个字符数组,然后判断字符数组的长度,如果不满足条件那么就会报错,打印出错误的内容。如果满足条件,那么久创建一个SparkSession,需要传人一些配置文件的信息。然后再用spark sql查询,查询之后对于map的结构进行转换,再依次传人到hbase中。(要保证行键,列族,列名的整体有序,必须先排序后处理,防止数据异常过滤)将rdd转换成HFile需要的格式,Hfile的key是Immu-tableBytesWritable,那么我们定义的RDD也是要以Immutable-BytesWritable的实例为key,然后保存到hdfs上面。
5 运行及系统测试
各模型的结果f1值如表所示。
6 小结
国家“十三五”规划纲要里明确提出来要实施国家大数据战略,为我国在大数据领域的未来发展绘制了宏伟的蓝图,开启了我国大数据发展的新时代。随着大数据及人工智能的到来,利用大数据+人工智能技术进行数据收集和分析,并根据需求建立模型,从而进行商业的数据分析与运营将获取更多商用价值。
参考文献:
[1]马超.基于主题模型的社交网络用户画像分析方法[D].合肥:中国科学技术大学,2017.
[2]席岩,张乃光,王磊,等.结合大数据技术的用户画像推荐方法研究[J].有线电视技术,2018,25(5):16-18.
[3]刘蓓琳,张琪.基于购买决策过程的电子商务用户画像应用研究[J].商业经济研究,2017(24):49-51.
[4]李锦锐,章家宝,彭梅.基于大数据技术的求职用户画像系统 研究与设计[J].产业与科技论坛,2019,18(4):75-76.
[5]电商用户画像环境搭建一我是楠楠-5ICTO博客https://blog.5lcto.com/14473726/2439624.
【通联编辑:代影】
作者简介:彭梅(1975-),女,湖南保靖人,副教授,在职硕士研究生,主要研究方向:大数据与人工智能应用开发;胡必波(1979-),男,广东广州人,讲师,在职硕士研究生,主要研究方向:大数据与人工智能应用开发;章家宝(1998-),男,广东揭阳人,在读本科,主要研究方向:大数据数据分析以及Javaweb系統编写。
猜你喜欢
校园英语·月末(2021年13期)2021-03-15
中学生数理化·七年级数学人教版(2020年10期)2020-11-26
数学物理学报(2020年2期)2020-06-02
光学精密工程(2016年6期)2016-11-07
核科学与工程(2015年4期)2015-09-26
外语学刊(2011年3期)2011-01-22
