
基于文本情感分析的电商产品评论数据研究*
2020-12-25 08:41章蓬伟贾钰峰邵小青拜尔娜木沙赵裕峰
微处理机 2020年6期
章蓬伟,贾钰峰,邵小青,拜尔娜·木沙,赵裕峰
(1.新疆科技学院信息科学与工程学院,新疆库尔勒841000;2.新疆科技学院工商管理系,新疆库尔勒841000;3.辽宁生态工程职业学院电气工程学院,沈阳110122)
1 引 言
随着电子商务的普及与发展,海量评论数据爆炸式增长,对电商评论大数据做情感分析研究,不仅有助于消费者及时掌握产品口碑以决定购买意向,对于商家根据产品营销反馈结果及时调整产品服务质量也同样至关重要。如何从具有数据量大、非结构化、含有特定网络用语等特点的电商在线评论进行情感分类、挖掘有意义的信息,已经成为大数据、人工智能、机器学习等交叉领域研究的热点。
文本情感分析也叫情感倾向性分析,是对带有情感倾向的主观性文本进行分析、处理、归纳、推理的过程[1]。情感分析的方法一般有两种,一种是通过机器学习的方法,把情感分析当成分类问题来解决,要求有分好类的训练数据集,一般是有监督学习;另一种是基于情感词典的方法,计算句子的情感得分,推测出情感状态,多用于无监督学习的问题。基于词典的方法需要大量标注,基于机器学习的方法在选择带有特点语义信息的分类问题上表现更好,但机器学习在特征研究方面泛化能力较差,数据训练不足可能导致分类器失衡[2]。从已有研究看,通过电商评论的文本情感分析取得了一定成效。如HU 等[3]通过情感分析挖掘出用户对产品的情感倾向;Dasgupta等[4]在2016 年通过对三星手机用户评论的情感分析,得到消费者对手机信息特征的反馈;李琴等[5]在2018 年基于情感词典对在线景区评论进行情感分析得到情感类别倾向性与门票波动之间客观存在的联系。
基于现有研究成果,在此采用基于情感词典的方法对新疆特产若羌红枣的评论信息进行情感分析,对数据进行挖掘,客观反映消费者的评价信息和关注点,并采用SnowNLP 库对评论数据进行情感分数可视化。
2 电商评论研究
2.1 电商评论数据采集
要对电商平台在线评论数据进行情感分析与数据挖掘,首先需要爬取相应的评论数据。可编写爬虫脚本或采用常用的数据采集工具,比如火车采集器、京东智商、生意参谋、八爪鱼、淘数据等。
逐一试用各种网络爬虫工具,通过实际对比,发现八爪鱼采集器具有更优良的方便易用性,能用来模拟真正用户行为进行数据采集。因此实验采用八爪鱼采集器来爬取京东电商平台下的若羌红枣在线评论数据。
2.2 电商评论数据预处理
爬取到的电商评论数据集存在很多无意义或重复的数据,如果不进行数据清洗预处理,把这些数据进行分词、词频统计及情感分析等,会增加很大工作量,甚至影响实验结果的准确性。因此首先需要对原始数据进行去重、机械压缩去词、短句删除等预处理。
2.3 基于词典的情感分析
2.3.1 分词与高频词统计
将一个汉字序列按照规范切割成一个一个单独的词语进行中文分词。中文分词难度要比英文大得多。在特征选择过程中,不同的分词效果直接影响着词语在文本中的权重,从而影响数据挖掘的效果。此处采用简单且高效的中文分词包Jieba 分词,分词后去除停用词,采用哈工大停用词表、四川大学机器智能实验室停用词库、百度停用词表等,最终进行词频统计,获得关键词汇和高频情感词汇。实验具体步骤如图1 所示。

图1 分词统计流程图
Jieba 分词有三种模式:全模式(Full Mode)、精准模式(Default Mode)、搜索引擎模式(Search Mode)。全模式分词试图把句子中所有可以组成词的词语都拆分再组合起来,但结果有可能重叠,不能解决歧义问题;精准模式分词试图将语句最精确地分开,结果无重叠词汇,适合做文本情感分析;搜索引擎模式在精准模式的基础上,把长词进行再分词,适用于搜索引擎分词。此处采用Jieba 分词的精准模式,调用cut方法,能较准确地实现评论语句的分词,但对于一些新兴的随意的网络用语进行分词会存在误差。比如商品评论信息“若羌红枣再一次来盘他”,用三种模型的分词结果是:
全模式:若羌/红枣/再一/一次/来/盘/他;
精准模式:若羌/红枣/再/一次/来盘/他;
搜索引擎模式:若羌/红枣/再/一次/来盘/他。
发现每一种分词都没有准确识别出2020 年新兴的网络用语“盘他”这个词,准确的划分应该是:若羌/红枣/再/一次/来/盘他,表示喜爱红枣。从这条评论语句中得知消费者是回头客,又一次购买了红枣。统计的高频词汇生成图云和关键词柱形图能更直观反映出京东平台消费者对红枣最关注的问题。根据整体词云进行分析,高频词汇有:味道、物流、个头、卫生、京东、包装等。回看评论数据发现,消费者的关注点集中在3 个方面:1) 对若羌红枣的味道、包装、物流非常满意,给出好评;2) 对红枣的卫生情况总体情感值是积极的;3) 对红枣的个头大小不满意,表现消极情绪。
采用Python 类库对高频词可视化展示处理,得到的高频词云如图2 所示,高频词统计柱形图如图3 所示。处理程序的核心代码如下:



图3 关键词频统计柱形图
2.3.2 基础词典整合
情感词典是标注了带有感情强度的词或短语的集合,这些词语的词性不限,可以是名词、动词或形容词等。情感词通常会带有感情极性,一般分为积极情感词和消极情感词。比如词语“喜爱”的情感倾向是积极的,词语“厌恶”的情感倾向是消极的。目前大部分的通用情感词典是通过人工构建的。人工构建方法主要是通过阅读大量相关语料或借助现有词典,人工总结出具有情感倾向的词,标注其情感极性或强度,构成词典[6]。电商产品评论中的情感极性经常以短语和网络化用语形式存在,因此基础词典不能满足需求,还需特定的领域词典。在本次实验中,情感词典整合了台湾大学NTUSD 简体中文情感词典,知网HowNet 情感词典,清华大学李军中文褒贬义词典TSING,并加入从网上搜集的电商评论相关的情感词语集合。HowNet 词典由情感词语和评价词语组成,其中情感词语由836 个积极情感词和1254 个消极情感词组成,评价词语由3730个积极评价词和3116 个消极评价词组成。NTUSD词典由2810 个积极情感词和8276 个消极情感词组成。TSING 词典由5568 个褒义词和4470 个贬义词组成。将这三部分词典和电商评论相关词语情感集合整合去重后,得到新的基础情感词典,其中正向情感词级性为1,负向情感词级性为-1。通过程序来统计积极、消极词汇个数,部分代码如下:

2.3.3 否定词构建
一条语句否定词的出现往往会改变情感倾向,因此需要构建否定词库。对评论语句进行情感分析是根据情感词前面的否定词个数,如果是奇数,将情感词的强度乘以-1,如果是偶数,乘以1。整合常用的否定词如下表所示。比如“我不喜欢红枣的包装”,喜欢是积极情感词,情感词前面有一个否定词“不”,因此整体极性相反,变成了消极情绪。常用的否定词归纳为表1。

表1 常用否定词表
2.3.4 程度副词构建
句子中的程度副词能影响情感的强度。比如“红枣味道特别好”,“特别”是程度副词,加强了喜爱情感的程度。本实验中对程度副词采用HowNet 程度副词表,该表中含有219 个程度级别词语。程度副词分成5 个级别,代表着情感程度的强弱。根据具体情况按照梯度下降公式分别对每一级别赋予不同的权重值[7]。梯度下降公式为:

式中,k=1,2,3,4,5,T1为第一级别程度副词的权重值;常数为梯度的下降率。
2.3.5 算法规则构建
使用整合后的情感词典,经过分词处理,计算评论句子的情感得分,采用如下方法:使用Python 对情感词典、否定词表和程度副词库进行读取。遍历每一条评论,对于情感词汇并没有为每个词采取加权处理,分词后比对整合的情感词典,如果是积极词,分值为1,如果是消极词汇,分值为-1。如果句子中出现程度副词,分数乘以权值指标。对于出现否定词,采取偶数得分乘以1,奇数得分乘以-1。具体算法模型如图4。

图4 情感得分算法图
按照如图4 的算法模型,经实验,基于情感词典的情感分析最终准确率为0.785。
3 情感分析可视化实验
NLP(Natural Language Processing)自然语言处理算法可以通过传统模型、朴素贝叶斯、神经网络、SVM 等来实现。实验采用简单易用的SnowNLP 进行数据的初步分析研究。SnowNLP 是Python 的第三方库。对其调用进行情感分析时,SnowNLP 有如下情感判断过程:首先,读取已分好类的文本negt.txt和pos.txt,再对所有文本进行分词、去停用词,从而计算每个词出现的频数[8],最后采用贝叶斯定理计算出概率较大的情感类别。
使用Python 调用 sentiment 下的情感分类方法,可以对文本情感进行评分,得到的情感分值在0到1 之间,分值大于0.5,情感较为积极;当分值小于0.5,情感较为消极;越接近0,情感越消极。SnowNLP库中训练好的模型是基于电商产品评论的数据,本次研究调用SnowNLP 库进行情感分析并没有重新训练模型。SnowNLP 情感分析部分代码如下:


用Matplotlib 生成情感分值分布柱状图,实现情感分数可视化,实验结果如图5 所示。
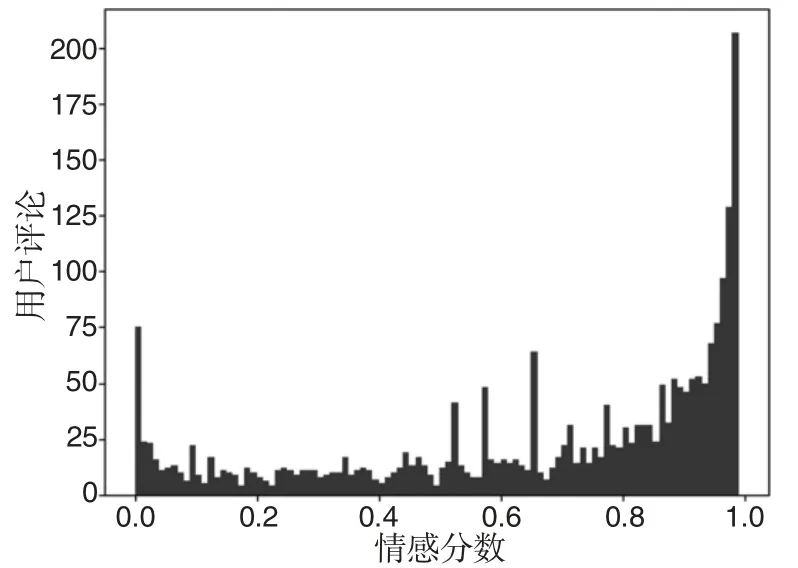
图5 情感分值分布柱状图
4 实验结果分析
采用八爪鱼数据采集器爬取数据,采取Python语言对评论数据进行分析,其中采用了基于情感词典和运用SnowNLP 的方法对若羌红枣评论数据进行了情感分析,获取排前10 位的高频词汇,并把关键词语进行可视化展示。
通过高频词语分析发现,消费者对若羌红枣的评论还是比较积极的,最关注的是味道、包装、京东、物流、卫生等,都给出了积极的情感评价,而对于红枣的个头偏小,部分评价消极。针对反馈的问题商家可以继续在红枣的味道、包装质量、物流的满意度上保持优势;针对消费者对红枣个头的差评,商家需要改进红枣的大小不一的情况,比如进一步加强红枣分级分类,提高产品质量,打造过硬的品牌形象。
基于词典的情感分析结果准确度偏低,分析原因及改进思路如下:
1)情感词典的准确度有待进提高,对于情感词汇应该采取加权训练,而不是同等对待,并在此基础上针对电商产品领域词汇进行优化训练。
2)句子情感分析的算法有待进一步提高,需要增加语气助词的权值。
3)只单纯依靠基础词典来判断情感是不够的,具体的应用环境需专业领域词典的同时,还需要考虑文本上下文的联系。
Python 运用SnowNLP 库进行情感分析中准确率只有0.728,准确度偏低。原因是没有采用训练词库。后续研究可以对SnowNLP 进行优化,采用Jieba分词替换SnowNLP 的分词方法,设置自定义词库,提高情感分类的准确性。也可增设精准率、准确率、召回率等准确的指标衡量情感分析的结果。
5 结束语
研究通过匹配情感词典,对情感词、程度副词、否定词进行遍历,计算评论语句的情感值,用SnowNLP 库进行情感分析,以柱状图直观展示语句情感分数分布情况,并对实验进行了初步验证。人类情感是一个微妙又复杂的带有主观意愿的客体,目前计算机进行的文本情感分析,只是从数学统计学的角度融合机器学习等自然语言匹配的规则进行的情感分类。机器通过算法用量化标准去区分情感极性,很难准确把握住隐含的情感。通过大数据机器学习等方法能够不断提高识别分析的准确度,但是如何训练让机器能像人类一样思维,能区分并把握住人类细腻多变的情感,任重而道远。
