
基于并行计算的抛光轴表面缺陷检测研究*
2020-12-24 07:50:48姜庆胜李研彪计时鸣
机电工程 2020年12期
姜庆胜,李研彪,计时鸣
(浙江工业大学 机械工程学院,浙江 杭州 310023)
0 引 言
轴是机械行业普遍使用的零部件,其表面缺陷对其的使用性能和寿命有重要影响。一般情况下,轴的表面缺陷检测依靠工人肉眼观察完成,人工判断缺陷并剔除次品,检验人员的劳动强度大,长期工作对眼睛有伤害,并且检测结果一致性差,易发生漏检。而利用机器视觉自动检测轴的表面缺陷,可有效提高检测效率、检测质量,保护检测人员健康,是未来技术的发展趋势。
在轴的在线检测中,图像处理的速度是提高检测效率的重要因素之一。随着被处理的图像数量的增加,以及图像分辨率的不断提高,处理速度会变得越来越慢。由于计算机硬件系统的限制,会造成对复杂数据的处理速度的限制。根据摩尔定律[1],CPU的主频已经发展到了极限,无法仅靠提升硬件性能来提高运算速度。
近年来,超级计算的计算方法已应用到生产实践中。超级计算的最基本方法就是并行计算。并行计算的方法和硬件的结构有着密切的关系,但是其基本的原理和模型就是串行问题并行化。按其硬件形式可分为两类:(1)多机并行集群方式;(2)单机多核,例如GPU系统。
并行计算目的是为了加快运算速度,追寻并行架构的演变轨迹[2],经历了向量、分布存储[3]、共享存储、异构几个阶段。与之对应的程序设计语言有:面向向量的VFortran、面向分布存储的PVM和MPI、面向共享存储的OpenMP和面向异构的OpenCL[4]。当前应用更广泛的是Nvidia公司的使用CUDA C语言的显卡和专用计算卡。
Spark是近几年最流行的也比较成熟的多机并行的分布式集群运算架构[5-9],随着并行数量的增加,其运算速度明显加快。而对于基于面向异构的CUDA的单机多核并行计算也已经有了大量的研究和应用[10-14],这种方式加速非常明显。另外其他的并行方式有MPI[15]、OpenMP[16]等,但应用不多。
本文研究两种典型的并行计算方式,并提出一种将两种架构结合的方式,实现实时和大数据检测。
1 抛光轴表面缺陷检测
1.1 抛光轴表面缺陷检测系统
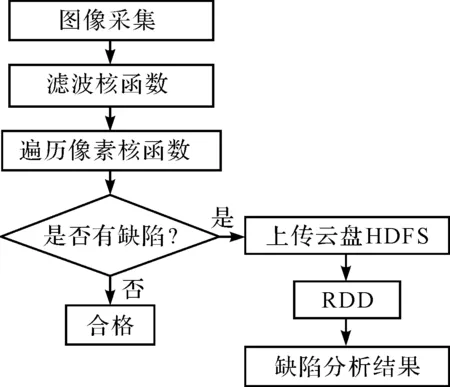
抛光轴表面缺陷检测系统不但需要实时识别出产品是否合格,而且也需要缺陷分析。
比较典型的轴表面缺陷检测系统如图1所示。

图1 缺陷检测系统
1.2 图像采集
由于轴是属于有规则型旋转曲面,而且经过抛光,具有高光反射特性,对于这种具有镜面特点的曲面上的缺陷,当前比较流行的图像获取方式是线扫描。在线扫描装置中,相机采用线阵相机,光源采用线光源。为了防止由于镜面的高光反射,而拍摄不到缺陷,必须先确定相机和线光源的角度。同时,轴的转动时间也必须和拍摄时间保持一定的比例关系,否则缺陷会失真。
轴的线扫描装置如图2所示。

图2 轴的线扫描装置
线扫描图像采集主要设备型号如表1所示。

表1 图像采集主要设备型号
1.3 图像特征
根据被检测轴缺陷的尺度,某些情况下需要采集较高分辨率的图像。笔者研究的检测对象活塞轴,其长度为200 mm~400 mm,直径约20 mm左右,表面经抛光处理,表面最小缺陷的直径约0.1 mm。根据缺陷尺度识别要求,采集图像的分辨率至少要达到16 384×4 096,即6.7×107像素,这就意味着处理时需要比较长的时间。
活塞轴和部分缺陷图如图3所示。

图3 活塞轴和部分缺陷图
针对高分辨率图像,图像处理的耗时直接影响到机器视觉自动检测系统效率。因此,要选择合理的图像处理平台和算法。
活塞轴表面图像具有像素多、被检测缺陷点小的特点,一般情况下6.7×107像素的图像中的缺陷是仅有数十个互相连通的像素团。根据统计分析,16个像素以下的像素团应作为噪声滤除,而且生产要求在线识别是否合格时间要小于1 s。
16 384×4 096线扫描图像如图4所示。

图4 16 384×4 096线扫描图像
1.4 表面缺陷检测的处理方法
对于物体表面缺陷的检测,常用的处理方法有[17]:统计法、频谱法和模型法。(1)统计法又可以分为直方图法[18]、灰度共生矩阵法[19]、自相关法[20]、数学形态学法[21];(2)频谱法可以分为傅里叶特征法[22]、Gabor特征法[23]和小波特征法[24];(3)模型法可以分为分形体法[25]、随机场模型法[26]和新模型法[27]。
图3中,轴表面缺陷点一般是凹坑、压痕、磨损和长条状的划痕。当图像经过均值滤波之后,非缺陷点的像素明显高于某个阈值,所以只要能检测出图片中的阈值小于这个阈值的点数的总数占一定的比例,就可以判断该轴是否存在缺陷。
由于需要检测轴表面非常微小的缺陷,采集的单张图片至少要大于6.7×107像素,并行计算是最好的选择。并行计算可以分为:任务并行性和数据并行性。对于Spark多机分布并行计算适用于任务并行法,而对于单机多核的GPU适合使用数据并行法。
1.5 基于传统的像素逐次遍历的缺陷检测
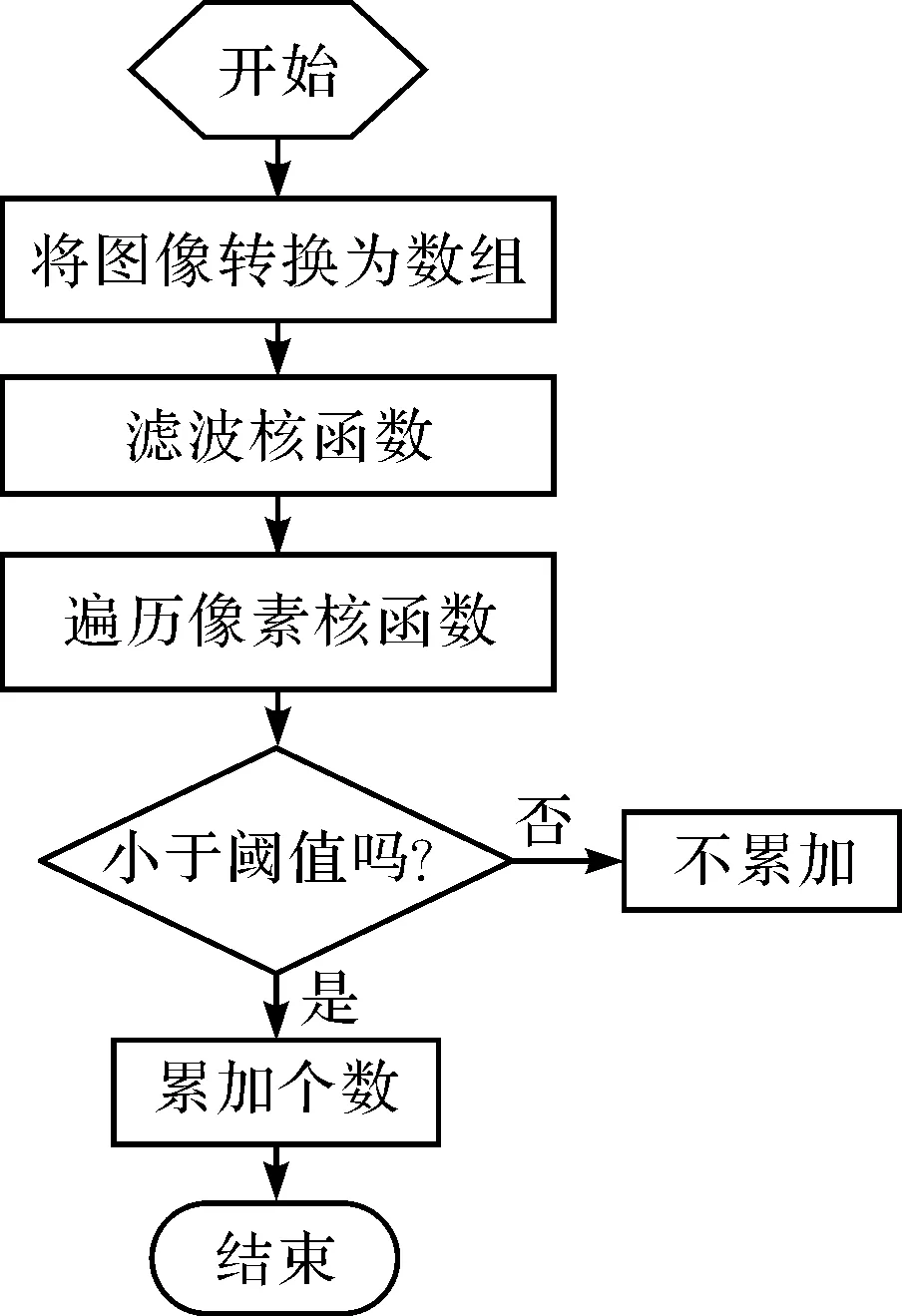
为了便于对比,笔者采纳了基于像素的逐次遍历串行计算方法:采集灰度化图像,通过均值滤波去除16点以下的像素团干扰,再将图像的像素值转换为二维数组,对每个数组元素和选取的阈值进行对比,小于某阈值的就进行统计,全部依次对比完成后,得到总的小于该阈值的像数总数,如果该总数达到某个缺陷的值,就认为存在缺陷,一次性完成图像的特征提取和识别。
普通串行算法的缺陷检测系统如图5所示。

图5 普通串行算法的缺陷检测系统
2 基于并行计算的检测系统
2.1 基于多机并行的Spark分布式并行计算系统
分布式并行处理就是多台具有独立运算功能的计算机并联运行。Spark是在扩展了Hadoop+MapReduce计算模型基础上的通用集群计算平台,其特点是易用性;运算速度快,具有交互功能;通用性,在其基础上可以完成其他各种复杂运算。它可以完成原先需要多种不同的分布式平台的场景的运算。Spark的API接口可以是基于Python、Java、Scala和SQL的程序,可以和其他大数据工具紧密配合。
Spark的核心是Spark core,实现任务调度、内存管理等,但真正的工作是对弹性分布式数据集RDD的API定义,RDD主要的编程对象是分布在各个节点上可以并行操作的元素集合[28]。
Spark是个多任务的操作模式,就是将一个项目通过管理器分成很多个小任务,然后将这些小任务分到各个计算机节点去运算。
应用于轴表面缺陷的处理,主要是针对图像的预处理和像素的检索,利用了Spark的机器学习组件MLib中的函数[29]。
基于Spark的缺陷检测系统如图6所示。
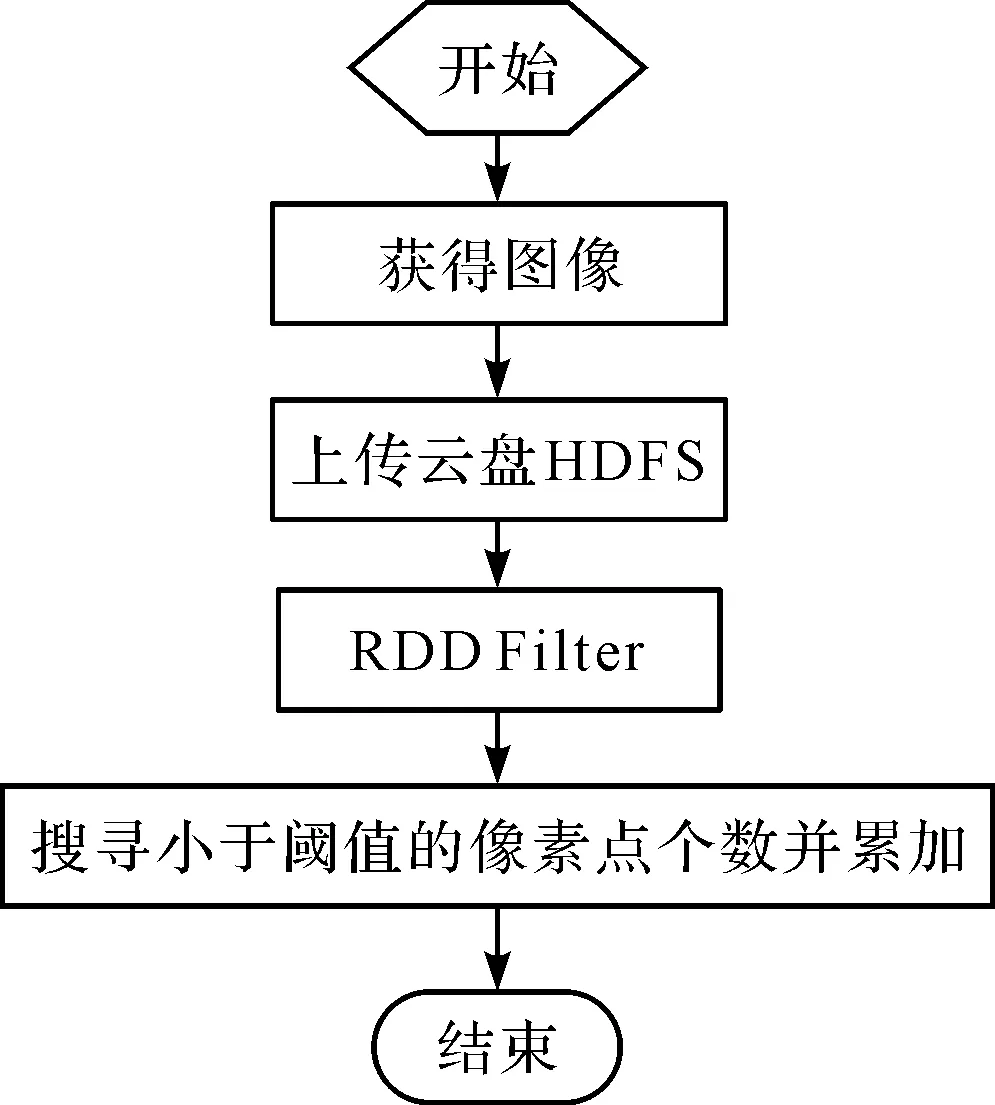
图6 基于Spark的缺陷检测系统
2.2 基于单机多核的GPU并行计算系统
由于其强大的图像并行处理能力,图像处理单元GPU被广泛应用于计算密集型计算。CUDA是Nvidia公司在图形处理卡GPU上运行的应用软件,它可以让C或C++代码在GPU上高效运行。
GPU是一种异构架构[30],其运行原理是主程序使用串行方式编程,在CPU中运行,但遇到程序中的计算密集型部分,就把这些数据拷贝到GPU中,也就是显卡或计算卡,让GPU进行并行计算,当GPU计算完成之后,再把数据拷贝到CPU中。
为了具有对比性,此处仍然以串行遍历像素点的方法来确认是否有缺陷,不过采用了CUDA并行计算,并且使用了线程协助管理和共享内存的特性来优化求和计算[31]。
并行计算数学原理为:
当n≫m,且i≤n时,则:
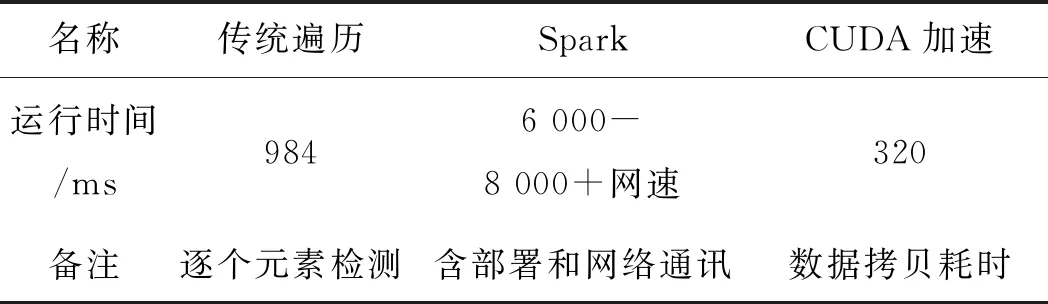
当Pi 当Pi>T时,令Pi=0; 由此可得像素和为: Sn=S1+S2+…+Si+…+Sm (1) 其中: S1=P1+Pm+1+…+Pn-m+1S2=P2+Pm+2+…+Pn-m+2……Si=Pi+Pm+i+…+Pn-m+i……Sm=Pm+Pm+m+…+Pn (2) 但是这样并行求和后,仍然会有m个数据求和,可以考虑再一次使用取半规约算法的数学方法进行并行求解。 根据式(1)有(Sj∈m): (j=1,2,3,……) (3) 此式可写为: (4) 令: (5) 可得和为: (6) 再令: (7) 以此类推,令通式为: (8) 经过k次迭代后,可得最后和为: (9) 式中:i—像素位置;T—阈值;P—像素值;S—像素的和;n—总的像素个数;m—一次并行处理的线程数;k—迭代次数。 检测系统中,图像噪声滤波和像素点判断统计采用不同的核函数,这里充分利用了Nvidia图像卡GPU中已经分配的地址,以减少数据拷贝时间。 CUDA缺陷检测系统如图7所示。 图7 CUDA缺陷检测系统 (1)多计算机集群配置的设备来自阿里服务器,其集群硬件如表2所示。 表2 集群硬件 集群软件配置如表3所示。 表3 集群软件配置 (2)单机多核运行的实验设备系统配置是:CPU为Intel(R) CPU E5-2620 v3 @2.40 GHz(2 core)内存32GB,GPU为Nvidia的GTK1080Ti。操作系统是Windows Servers 2012 R2 64位操作系统。使用OpenCV、C++、CUDA C。1.5节的串行传统遍历算法也使用该计算机CPU运算。 实验中使用图4中的被检测图片。由于生产现场被检测的轴是按照流水线逐个检测,每次检测一张图片,并判定是否合格。实验分别按照1.5,2.1,2.2节的方法测定运行时间,运行时间按照有数据传输和无数据传输分别测定。 不含通讯和数据拷贝的时间对比如表4所示。 表4 不含通讯和数据拷贝的运算时间对比 包含数据通讯和拷贝的时间对比如表5所示。 表5 包含数据通讯和拷贝的时间对比 3.3.1 基于Spark的检测 根据2.1节采用Spark框架检测一张图片的运行时间,包括图片拷贝到HDFS上的时间、计算机之间的数据交换通讯时间,以及调度器在不同节点上的工作任务部署时间,至少需要6 s以上,这对于实时系统显然是不合适的。 根据众多文献实验证明,大量图片一次性拷贝到HDFS上进行运算,随着计算机节点数量的增加,运算时间明显减少,适合大数据的批量运算。 3.3.2 基于CUDA检测 根据2.2节,用基于CUDA的单计算机多核并行计算方式,实验表明其完整运算时间为320 ms,可以满足实时要求[32]。如果采用机器学习,得到预测模型会花很长时间。根据文献[33]实验可知,一张512×512单张图片的模型检测时间在2.29 s以上,这对于Spark的分布式计算机集群上是可行的,但不符合实时检测要求。 评估并行加速的指标是加速比,其公式为: (10) 式中:Te—串行计算时间;TP—并行计算时间;Sp—加速比。 由实验可知,GPU在有通信的时候的加速比是3;无通讯的时候的加速比是52,可见数据的通讯和拷贝时间占用比较多的时间。 根据以上分析,对于一个比较完整的轴表面缺陷检测,即要满足实时在线的快速检测,又要进行缺陷分类,宜用人工智能中的基于神经网络的深度学习,所以笔者提出了一种CUDA+Spark的混合模式。 CUDA+Spark模型如图8所示。 图8 CUDA+Spark模型 根据混合模型,利用CUDA实现快速的实时检测,然后把缺陷图片全部上传到HDFS存储,可以间隔一段时间,对批量数据进行分析处理。 RDD最适合对数据集中所有的元素进行相同的操作的批处理类应用,所以将缺陷分析部分置于Spark架构上是可行的。 两种并行方式的结合使用会有更好的空间,除了租用云服务器外,也可以将云计算改成就地多计算机系统组成就地云网络,以减少数据传输时间,并用于存储超大数据和长时间的复杂计算,使用GPU系统并行计算来作为实时计算,同时利用就地云网络的计算结果来为实时判断提供依据。 当前,基于视觉的缺陷检测已经不仅仅局限于实时检测产品是否合格,也需要分析产生缺陷的原因,而分析产生缺陷的原因需要对大量数据进行存储和处理。 笔者经实验证明了通过数学并行原理优化后的GPU片上多核的并行计算方式,适用于高分辨率图像实时环境;而基于云的Spark架构分布式并行计算方式,不适用于实时环境,但却适合使用在计算和数据密集、大批量数据处理的场合,而GPU却不适合。所以采用GPU和Spark结合模式可以满足对高分辨率图像的实时检测和大数据量分析场合的需求。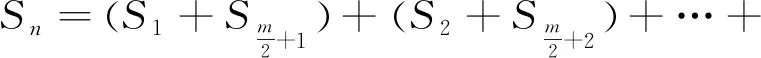


3 实验及结果分析
3.1 实验设备

3.2 实验数据

3.3 实验结果分析
3.4 实时检测和大数据量数据分析的混合结构模式
4 结束语
猜你喜欢
艺术家(2023年8期)2023-11-02 02:05:28
小哥白尼(军事科学)(2022年2期)2022-05-25 13:19:30
中学生数理化(高中版.高考数学)(2022年1期)2022-04-26 14:09:30
数学小灵通(1-2年级)(2020年6期)2020-06-24 05:57:54
军事运筹与系统工程(2019年4期)2019-09-11 06:39:58
红领巾·萌芽(2019年8期)2019-08-27 15:30:15
电子制作(2018年11期)2018-08-04 03:25:40
中国交通信息化(2017年3期)2017-06-08 06:09:28
中学生数理化·八年级数学人教版(2017年2期)2017-03-25 16:12:51
知识就是力量(2017年2期)2017-01-21 18:29:36
