
基于社区专家用户权威度的微博推荐算法研究
2020-12-16 09:05郑承宇
云南民族大学学报(自然科学版) 2020年6期
马 倩,王 新,郑承宇,王 婷
(云南民族大学 数学与计算机科学学院,云南 昆明 650500)
在科技进步、因特网发展的背景下,出现了各种社交媒体应用,用户能够利用社交媒体分享自身心得,推荐自己喜欢的东西,发表自己的观点,和别人交流各种经验等,从1个信息接受者成为了信息发布和接受者.微博是1种很有代表性的可以分享图片、文字、视频的社交媒体.2020年微博发布首季度财报,其中数据显示,微博用户规模首季度增长再创新高,月活人数均值已经达到5.5亿,日活人数均值也超过2.41亿,尤其是新冠疫情之后,越来越多的用户利用微博获取全球各种新闻,使得民众以最快的速度了解到当前的疫情发展趋势,同时微博也开始成为各国各地防疫新情况、防疫新措施的重要平台,每天登陆浏览、发布微博的用户也更加活跃,平均每天超2亿,其日均流量已经持续一、二月,超过2019年同期五成之上.因此,如何能够更好更迅速地搜索到自己喜欢的微博,甚至不用搜索就可以被微博自主推荐越来越受到关注.
针对微博推荐算法主要分成以下几类:①协同过滤推荐.基于用户或项目的类似性进行推荐.②在协同过滤的技术的基础上延伸和发展出来的推荐方法,研究引入不同的属性,譬如,专家信息、用户间的社交关系等;或改善协同过滤中的模型,如矩阵分解等.Manca M等[1]针对社交交互超载,在社交书签领域通过挖掘标记系统中的用户行为,分析用户标记的书签以及每个使用的标记的频率进行推荐.He Y等[2]利用关注关系,引入推特热因子和用户权限因子,使用RS和线性回归的方法来确定参数平衡推特热因子值和用户权限事实,从而建立了基于语义网络的新浪推文及时个性化推荐模型,实现个性化、实时的推荐.Lu X等[3]通过改进简单的正、反关系模型中定义了相似公式,提出了基于结构平衡的交互式朋友推荐系统的构建方法,但是交互信息考虑得并不完善.学者们对于加入重要用户的信息也展开了深入的研究.张凯涵等[4]通过划分社区,确定各个社区的专家,引入信任关系和专家信息对专家评分矩阵进行填补,对新用户产生推荐,可以对冷启动问题进行一定弱化.王建芳等[5]学者在对专家信任度进行量化时,引入了评价偏差度、活跃度、可信度等指标,从而对专家算法进行优化,同时和用户、项目偏置算法结合,得出更客观的预测评分,但是信息融合的不够完善.刘国丽等借助于jaccard相关系数,与加权处理的pearson相关系数、用户平均评分因子等,对相似度算法进行相应优化,并在预测评分时在传统的同社区内专家信任的基础上,引入不同社区专家信任,显著提高推荐准确性[6].
将目前的推荐算法应用到微博推荐中,可能会有以下问题:①社区划分.一般社区划分算法都是根据内容进行划分.这种划分可能使得划分的社区过多,数据稀疏.②专家的确定.微博用户的影响力除了需要考虑根据用户的粉丝数,平均被转发数,平均被评论数,平均被点赞数几种因素以外,微博用户是否进行认证、用户的认证类型以及发布的微博的质量也是很重要的1个影响因素.但目前进行微博推荐的文献中,较少反映了这一点.③社交关系的引入.大部分文献中引入的社交关系都是用户的信任关系,但是仅考虑信任关系不太符合现实生活,且容易忽略其他因素的影响.不同社区专家的信息的引入,再计算用户和专家集合的相似性为用户进行推荐预测,这使得推荐结果的准确率得到一定的提升.但是专家信息形成的相关矩阵有些稀疏,且社区间的专家之间的关系也没有考虑.以文献[7]所给出的社区划分法为基础,通过改进的规则计算用户权威度得出专家用户,将专家兴趣作为目标来对用户加以推荐.
1 相关研究
1.1 用户社区划分
社交网络中的社区划分主要是对节点(即用户)的属性进行划分,譬如用户相似度、社交关系等.将具有一致属性节点分派到相同社区之中.分到同一社区之后,根据需要进行好友推荐,兴趣爱好推荐等.张继东根据这一特性提出了基于用户交互级别、用户专业知识水平、信任程度的算法对社区进行划分[7].用户的交互程度可以用用户之间的连线来表示,连线的粗细分别代表着用户之间交互的强弱.这种社区划分的算法有别于其他的社区,进行推荐时精确度会更高.
用户交互级别(LoI)(指一段时间内用户交互的程度) 如公式 (1)所示.
(1)
其中,NoI(x,y)t是用户x与朋友y在一段时间t内的交互次数,NoIall(x)t是同时段内用户x与其所有朋友的交互的总次数.
文献[7]中为了算出不同用户之间的信任度,还进一步提出用户专业知识水平概念.专业知识水平(LoE)(指目标用户的好友中同一类型的好友可能有多个,为了有更好的推荐,需要选择专业领域中专业知识水平更高些的用户,判别水平高低的概念即为专业知识水平),如式(2)所示.
(2)

信任值 (LoE) 通过对用户交互级别和用户的专业知识水平的加权和计算得到,如式(3)所示.
LoT(x,y)=α×LoI(x,y)t+(1-α)×LoE(x,y).
(3)
文献[7]中为了避免使用静态信任阈值丧失的部分真实性,还提出了动态信任阈值ø ,如式(4)所示.
(4)
H是x对其所有朋友的信任等级列表,而∑Distinct(ti) 是H中不同值的列表.如果LoT(x,y)≥ø,则可向用户x推荐用户y.
在进行社区划分时,文献[7]将单个用户表示的节点作为初始的独立社区,然后通过与其他节点计算用户之间的交互级别、专业知识水平、用户间的信任程度等,来确定是否用户可以添加到原始社区,重复以上步骤,至所有节点都可以规划到某一社区内,即社区划分结束;但是过多的特征并不一定会得到更精确的结果.
本文利用了文献[7]中的社区划分方法,缩小网络范围,在其基础上引入了专家信息,对数据稀疏问题进行缓解,提升推荐效果.其中信任度和阈值比较之后剩余的用户人数成为专家候选集U1;然后根据改进的用户权威度的方法选出专家候选集U2,对专家兴趣相似度进行计算,从而向目标用户开展推荐.
1.2 用户权威度的计算
微博用户的权威度是微博用户通过自身的影响力直接或间接地影响微博的传播效率以及传播范围.学者们对于用户的权威度度量也进行了一些研究.张凯涵等通过计算用户可信度、权威性、评分多样性确定专家[4].文献[8]中学者提出微博用户权威度定量评价模型,而且这种模型是以多特征融合作为基础,主要是定量计算用户信息完整度、用户活跃度、信息传播影响力、平台认证指数这几个特征来实现.文献[9]在用户权威度算法基础上引入了用户博文的传播率挖掘用户的潜在影响力,结合用户的好友质量,以优化的PR算法为基础,成功搭建用户权威度评估方法.
1) 用户平台的认证指数UPI.微博用户在经过官方认证之后,会成为加V用户,受到更多的来自其他用户的关注和认可,从而影响用户的权威度.根据文献[8]定义的认证计算公式(5).
UPI(x)=δ·A(x)+τ·G(x)+γ·V(x).
(5)
其中,x为用户,其是否为认证用户则用A(x)表示,值为0或1,认证为1,非认证为0;G(x)代表用户x的微博账号等级;V(x)代表用户x是否为VIP用户,值为0(不是VIP用户)或1(VIP用户).但是由于微博的等级查询功能已经下架,因此,引入用户等级的计算方法无法使用,因此本文在认证指数中引入认证类型的分配权重,如式(6)所示.
UPI(x)=(δ·A(x)+γ·V(x))·wij.
(6)
wij是特征词ti在认证类型文档Dj中的基本权重,是经典TF-IDF的变形,用文档频率的对数代替TF,减少TF的线性增长,具体计算公式如(7)所示:
(7)
2) 用户活跃度.影响力较大的用户发布的微博一般比较多,因此用户的活跃度可以通过计算用户在一段时间内的发表的微博的数量来度量,在这里引入一个时间效用函数,降低计算的复杂度,如式(8)所示.
(8)

f(t)=(1+θ)-t.
(9)
是1种时间效用函数[10].微博的f(t)的取值范围为(0,1],值越大,活跃度变化趋势越大,意味着微博的发布时间对用户活跃度的影响越大.θ(θ>0)是调整因子,是一个表示微博新鲜度的数值,值越小,新鲜度变化趋势越小,意味着微博发布时间对微博新鲜度的影响越小;如果值为0,意味着任何时间发布这个微博完全不影响微博的新鲜度.t为微博的发布时间与爬取时间的间隔天数.
3) 用户的传播影响力.用户的传播影响力和用户的粉丝数、用户发布微博的被转发数、用户发布微博的被评论数有关,用户的传播影响力如式(10)所示.
(10)
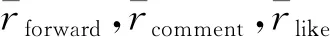
由于用户的不同属性的特征之间的区间差距很大,因此,属性特征值区间差异较大,不能直接进行线性相加计算,需要进行归一化处理,如式(11)所示.
(11)
通过归一化处理之后,其特征值用F0表示,F表示原始的特征值,Fmin表示所有用户的该特征的最小值,Fmax对应的是全部用户所对应此特征的最大值.
本文对微博用户自身特征信息进行归一化处理后,定义了用户自身影响力分数,计算公式如式(12)所示.
(12)
其中,Auth(x)表示用户的权威度值,为了减少计算难度,权威度值为用户的认证信息,用户的活跃度,以及用户的传播影响力的平均值.
按照用户权威度,并遵循由大至小的次序进行排列,选择权威度排名前120名的用户为专家用户候选集U2;而专家用户候选集U1和U2两个专家用户的合集为最终的专家用户集.
2 基于社区专家用户权威度的微博推荐算法
2.1 用户相似度计算
2个用户之间的相似度可以从用户兴趣相似的和用户关系相似度等方面来计算.基于用户兴趣的相似度能够充分挖掘用户间的兴趣爱好,可以给拥有相似兴趣爱好的用户推荐其感兴趣的项目.基于用户关系的相似度计算,能够给用户的信任好友进行推荐.运用专家兴趣爱好完成相似度计算,并将潜在专家向感兴趣用户进行推荐,在一定程度上可以降低计算难度,缓解信息过载的问题[7].因为专家用户发布的微博中一般原创微博的数量远超转发微博的数量,能够从原创微博中找出专家用户兴趣爱好,①借助于TF-IDF来对专家用户原创微博兴趣爱好关键词加以提取;②计算这些关键词的权重;③在计算兴趣相似度时,应用是余弦相似度方法,如式(13)所示.
(13)
其中,ui,vi表示专家用户u,v的第i个兴趣关键词的TF-IDF值,m是兴趣爱好关键词的总数.
结合算出的专家用户兴趣相似度、用户信任度,得到最终推荐度,进行推荐.
Pu,i=LoT(x,y)+sim(u,v).
(14)
2.2 推荐算法描述
通过对算法各阶段的介绍,本文基于社区专家用户权威度的微博兴趣推荐算法流程如图1所示,首先对于爬取到的微博数据按微博内容的性质进行分类,对每个类别中的用户按照粉丝数,收藏数,评论数,点赞数之和排名选择用户,获取其互关好友列表,通过计算用户交互强度、用户专业知识水平、用户信任度来判断用户是否可以加入专家候选集U1.然后对原始微博数据按照其评论数是否大于50进行一个预处理,通过计算用户平台认证指数、用户活跃度、用户传播影响力来判断用户权威度的大小,组成专家用户的候选集U2.对U1、U2合集的专家用户的原创微博通过TF-IDF提取兴趣关键词,并计算其权重;最后借助于余弦相似度,算出专家用户的兴趣相似度,结合用户的信任度进行推荐.
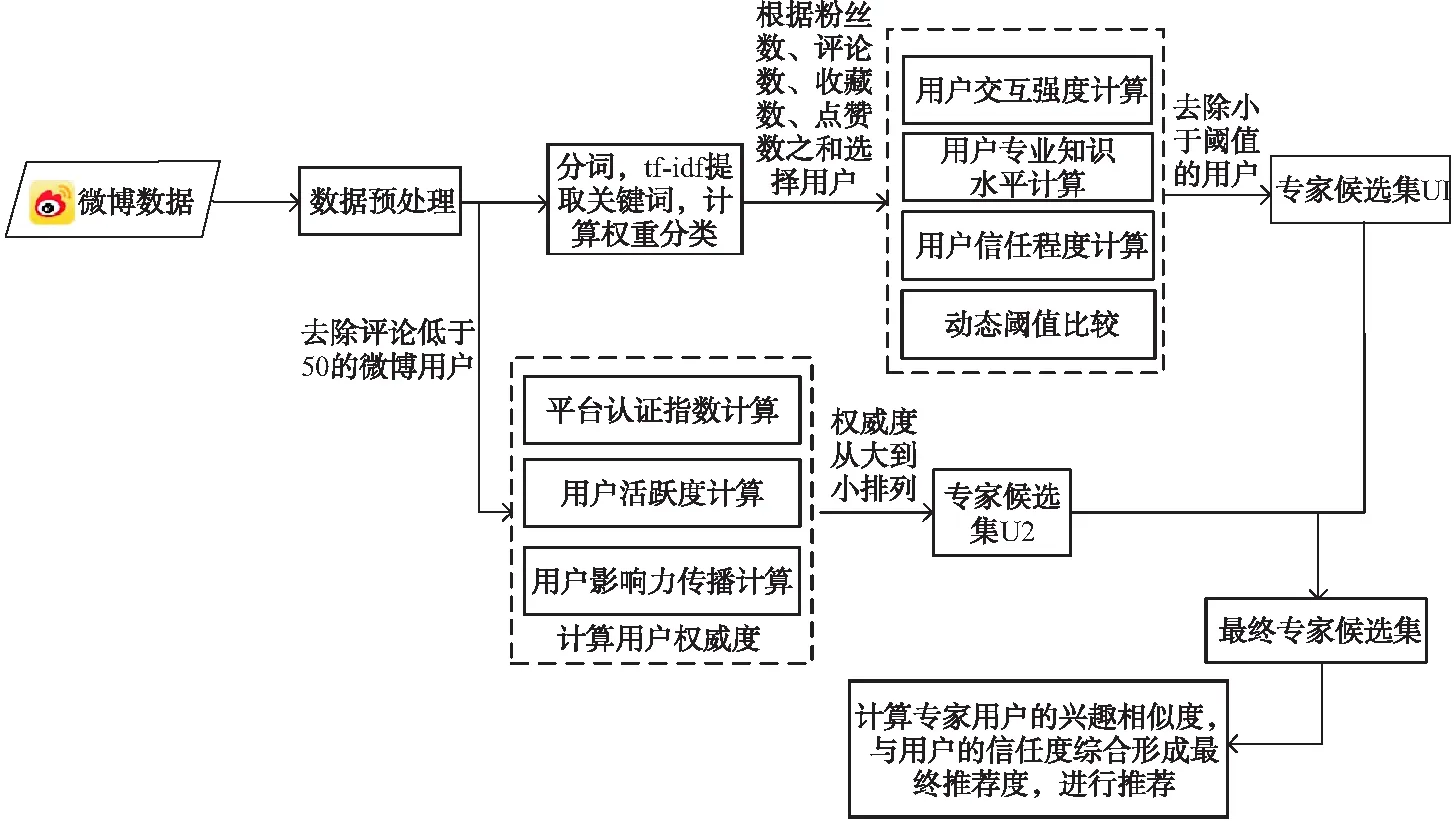
图1 算法流程图
3 实验及结果分析
3.1 数据采集与预处理
通过网络爬虫技术及新浪微博提供的 API 获取 10 525 条微博数据.其中的用户信息包括用户昵称、用户ID、微博内容、转发数、评论数、点赞数、收藏数、总发博数目、关注人数、粉丝数、发布时间、微博类型、是否为VIP、认证与否以及认证类型等一系列信息.
本文在社区划分中对用户交互级别进行计算时,需要对单个用户的用户好友列表的互关好友查看共同好友,以便计算共同好友比例;工程较为繁杂,且容易产生重复数据,因此现将爬取到的微博数据经过分词,提取关键词,进行预处理之后,粗略地将将数据分为财经、音乐、电影、综艺、美妆、旅游、新闻、明星、汽车、房产、小说、游戏等12个社区.以12个社区每个类社区点赞数、评论数、转发数、粉丝数之和排名前10 的用户为代表,统计这120名用户在微博上的共同好友列表,计算共同好友的比例,统计用户间的互动次数和总的交互次数,此处的互动数,主要囊括了点赞、评论与转发数量;并应用到后续的用户交互级别计算中.
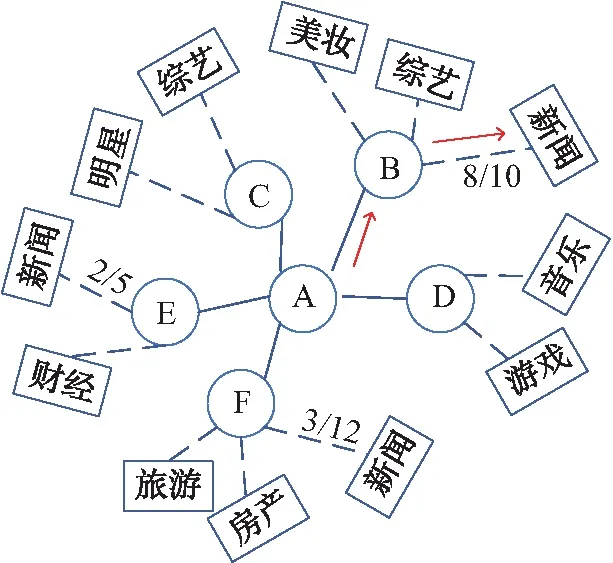
图2 用户专业知识水平网络图
专业知识评价可以根据目标用户的历史行为(比如点赞数、评论数、转发数等),以及有用的文字消息(如认证类型、认证类型描述)进行判别.如图2所示,如果目标用户A想要查询最近好看的综艺方面的信息,可以从用户B,C那里查找,询问;如果想要查找新闻方面的消息,可以向用户B,E,F请求相关信息.假设用户B、E、F提供的信息中的有用新闻信息占新闻总消息的比例(比例即为专业知识水平,实际情况时需要通过爬取到的信息根据公式(2)计算)分别为8/10、2/5、3/12,比例进行比较之后,就可以将用户B的新闻领域的专业知识推给目标用户.
计算用户权威度时,为了减少计算量,先将其中评论数少于50的微博删除.之所以选择以评论数为判断依据而不是转发数或者点赞数,主要是因为评论的操作较其他2种复杂,权重系数偏重;而收藏数,爬取出的数据基本都较少,差距并不大,因此不考虑.利用Python中开源项目jieba分词对认证类型、认证类型描述组成的文本进行分词,去停用词,关键词提取和删除特殊符号,最后根据公式(12)计算权威值.
3.2 参数确定
确定公式(6)中的δ、γ权值系数和公式(10)中的α1、α2、α3系数,利用对最大特征向量与特征值进行计算,并加入一次性校验,最终可以得到5个因素的权值分别为(δ,γ)=(0.634 8,0.365 2),(α1,α2,α3)=(0.261 4,0.501 7,0.235 9).
公式(9)中的通过文献研究得知,微博的保鲜时间为16.8天,所以θ一般取值为0.1~0.3,本文中取平均值0.2.
3.3 实验数据分析
本文爬取到的微博信息中,特意选择活跃度较高的明星社区中一个用户作为目标用户u0,经过统计得到目标用户与社区内其他用户的总交互频次 159 870(即评论 53 442,点赞 104 517,转发 1 327,收藏584),对微博文本进行分析后提取各用户提供给目标用户的信息总数,目标用户所运用的信息总数,见表1.

表1 目标用户u0的用户交互以及用户专业水平信息表
用户权威度的计算出的结果基本符合实际情况,部分用户的权威度如表2所示.
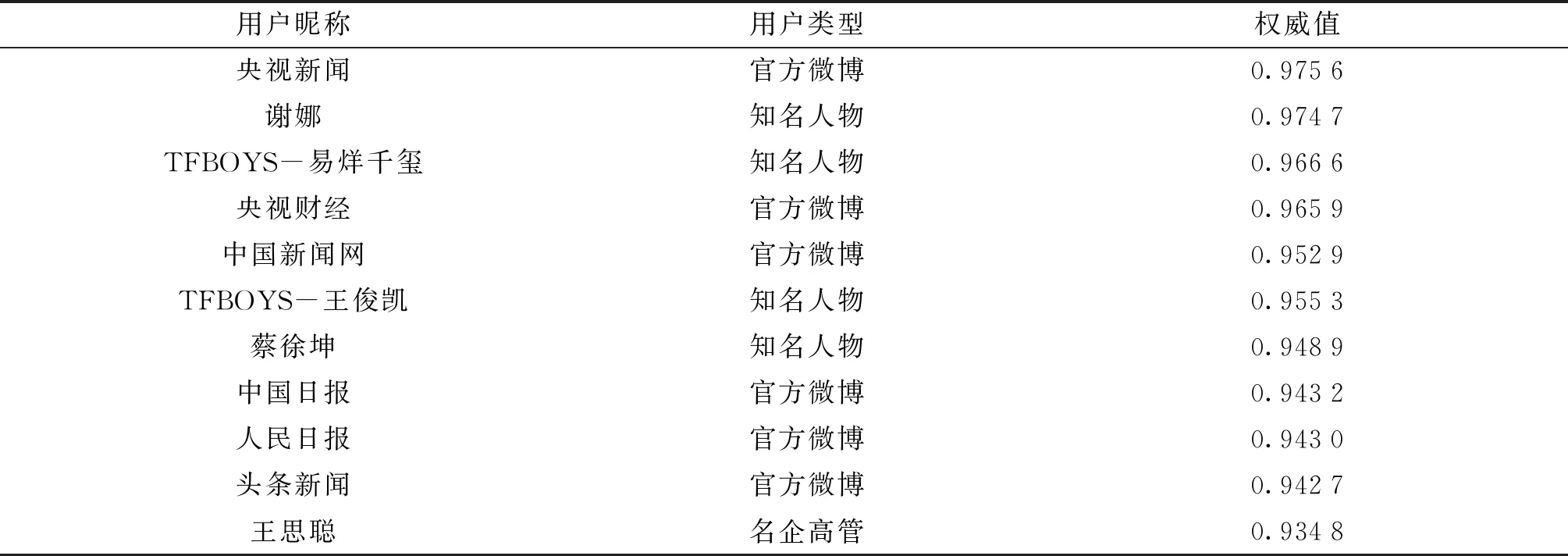
表2 用户权威度计算结果
从表2中可以看到,权威度高的用户大多是知名人物,其中娱乐明星占大多数,而官方微博会偏低些.主要是因为知名人物的更新微博频率较高,且粉丝数庞大,用户交互频率、传播影响力较高;官方微博的专业知识水平较高,微博质量高,粉丝领域非常广泛,常常会就某一实事引起热议,潜在影响力远大于一般明星.
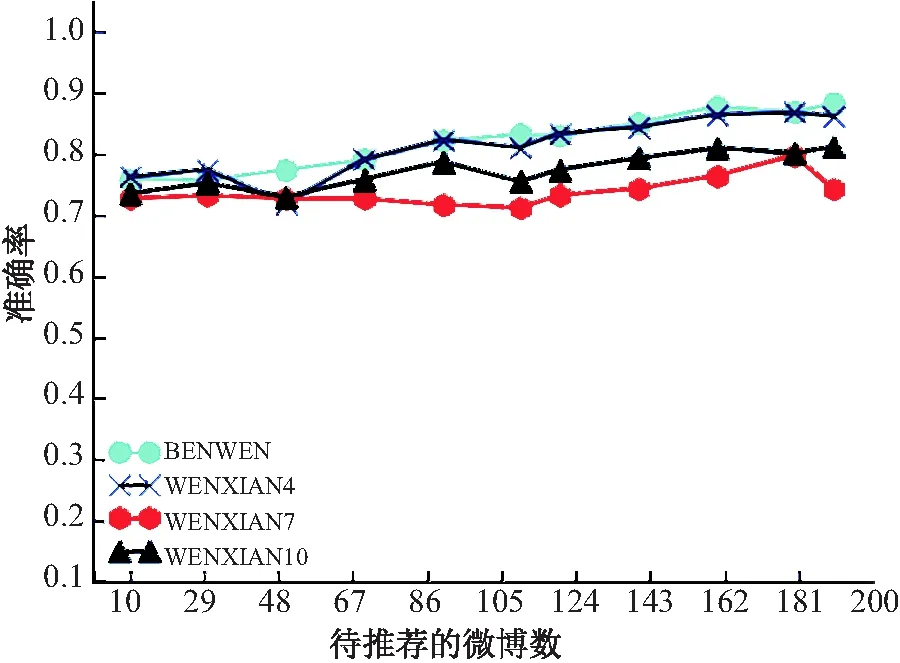
图3 不同算法的准确率对比结果
3.4 实验结果比较
大部分进行微博推荐研究的数据集从大小,内容,时间等都不相同,并且方法、评价指标也各有组合,本次研究在评估实验结果时,主要是对比分析召回率与准确率.
在进行对比实验之时,先后与文献[4,7,10]中的推荐算法加以对比,其中文献[4]中为了保证算法性能占优,按照原文中实验得的专家占比设置为0.2.各个算法的准确率、召回率以及F1值的对比结果如下图所示 .
从图3可以看出,4种算法的准确率都是1种上升的状态,但是相较于其他算法来说,本文的算法较为平缓,起伏不会过大.
图4中,召回率刚开始最高的是文献[4]中的算法,但是在一定程度时,另外3种算法下降幅度太大,整体来看,本文的算法召回效果稍好一些.
对于F1值而言,它是1个综合性指标,可以衡量出召回率与准确率,4种算法虽然综合指标差距不大,但是依然能从图中看出整体而言,本文的算法还是稍好一些,在F1值、准确率、召回率这几个指标方面都有一定改善.
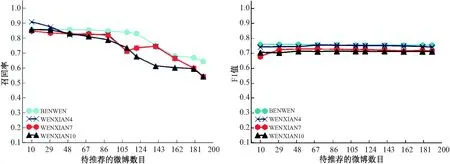
图4 不同算法的召回率对比结果 图5 不同算法的F1值对比结果
4 结语
本文中的推荐算法通过结合已有的由用户交互强弱和专业知识水平组成的信任关系进行社区划分,选出专家候选集,并融合了改进的用户权威度选择极具代表性的专家用户候选集,计算专家用户的原创微博的兴趣作为推荐的依据,对目标用户进行推荐,同时以真实数据集为基础,和已有推荐算法进行实验结果对比,结果显示,进行社区划分之后的专家推荐在提高推荐率的同时,还为用户感兴趣的领域推荐更专业的专家好友.但是,在本文中的实验在进行社区划分时,过于粗糙,没有进行多项数目选择的对比实验,且很多参数直接根据多篇文献的参数估算得到,实验有待进一步完善.今后的任务是继续研究如何在进行更精确地社区划分后,提高微博的推荐的实时性,提高推荐算法的各项指标及应用到实际的推荐系统中,对推荐算法进行优化.
猜你喜欢
计算机应用(2022年2期)2022-03-01
今日农业(2020年24期)2020-03-17
今日农业(2019年11期)2019-08-15
人大建设(2017年7期)2017-10-16
电影(2017年6期)2017-06-24
宠物世界·猫迷(2016年3期)2016-04-23
航天工业管理(2016年5期)2016-03-28
少儿科学周刊·少年版(2015年3期)2015-07-07
小说月刊(2015年1期)2015-04-19
海外英语(2013年8期)2013-11-22
