
社交媒体数据可视化分析综述
2020-12-15 09:18何巍
科学技术与工程 2020年32期
何 巍
(中国人民警察大学智慧警务学院, 廊坊 065000)
随着移动互联网技术的发展,越来越多的人利用微信、微博等社交媒体发布、浏览和共享信息,由此产生了大量开放的社交媒体数据[1-2]。这些社交媒体数据包含时间戳和文本,有的还带有地理位置信息,大体可以分为社交网络、文本和时空信息3类[3]。通过数据挖掘技术,可以发现这些数据背后隐藏的信息,例如人们的观点、情感倾向和社会行为方式等[4-6]。
可视化分析是一种高度跨学科的数据挖掘方法,它通过将各类信息以人类可以利用视觉直观理解的方式进行呈现,提高了人类对抽象信息的理解和综合研判能力。同时,可视化分析还支持人类与数据之间进行交互式探索,促进了对数据采集流程和数据挖掘模型的评估、纠正和改进,将改善人类最终获得的知识和决策。可视化分析可以用于可视化监控、特征提取、事件检测、异常检测、预测分析和情况感知[3,7],在新闻、灾害应急反应、政治、经济、反恐与危机管理、娱乐、城市规划等领域有非常广泛的应用[8-9]。
为此,首先介绍可视化分析的步骤,在此基础上阐述如何利用可视化技术分析社交媒体数据,最后讨论分析过程中遇到的问题与挑战。
1 可视化分析的步骤
1.1 数据采集与治理
根据应用需求,用于可视化分析的数据类型将会是多种多样的,包括结构化数据、半结构化数据和非结构化数据。首先,需要将采集来的数据融合成符合应用需求的形式,并根据应用需求进行数据变换和清洗。因为不同领域的数据通常具有不同的表达方式、不同的分布、不同的规模和不同的密度[10],所以数据融合的难点在于跨界数据的集成,通常可以采用基于阶段的方法、基于特征的方法或基于语义的方法等。
1.2 数据管理
除了传统的关系数据库,为了适应大数据时代数据量巨大、数据类型复杂的特点,分布式文件系统、NoSQL(not only SQL)数据库、SQL on Hadoop系统得到了广泛的应用。它们可以用来存储音频、视频和各类图纸组成的非结构化数据,并且很容易实现横向扩容。
1.3 数据分析
可视化分析并不是简单地将原始数据直接进行可视化展示,而是结合分析人员对数据的理解进行解释性可视化。同时,分析人员对数据要进行交互式探索,实现可视化分析的循环过程(图1),直至达到应用需求。在分析过程中,首先应该对数据进行全局性的概要分析,找出重点内容,然后针对重点内容进行细化和筛选,挖掘数据之间的相关关系和因果关系[11]。
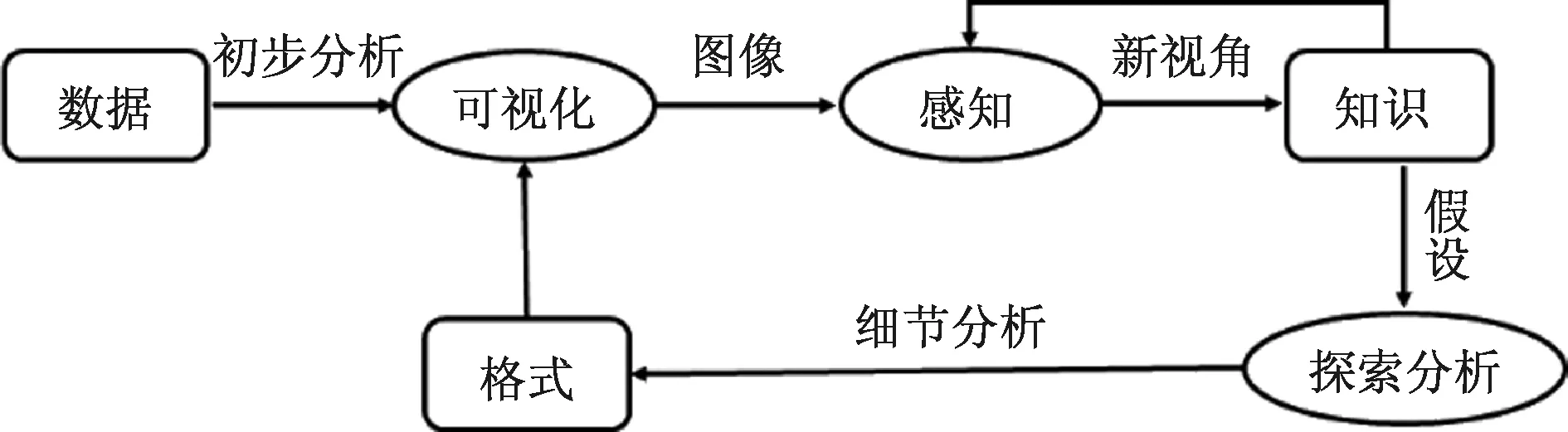
图1 可视化分析循环模型[11]
2 社交网络可视化
在社交媒体平台,不同用户之间通过相互关注、转发和评论建立联系,形成社交媒体消息节点,与社交媒体用户节点一起构成社交媒体网络,可用于探索社会结构、社区关系等[12]。
2.1 基于用户之间关系的网络
基于用户之间关系的网络,一般可以用节点链接图[13]和矩阵图[14]来表示。虽然节点链接图比较直观,但是当节点很多时,相互之间会出现交叉和重叠,给网络分析带来困难。矩阵图却可以规避节点之间交叉和重叠的问题。如果将两者结合起来分析,可以用于查找公共邻居、最短路径、社交网络中最大的集团等[15-16]。
社交网络节点的属性有很多,例如年龄、性别、教育程度、位置、关系、内容和时间等[17]。这些属性会随时间发生变化,所以社交网络一直处于变动之中,可以利用矩阵图对这些信息进行交互式分析[18]。每对用户之间关系的演变可以使用基于格玛斯特的字形矩阵(图2[19])来进行可视化分析,按时间顺序从上到下对关系数据进行编码和叠加字形,可以分析社交媒体上关系的稳定性。图2中的数字是社交网络节点编号,不同的数字代表不同的节点,即不同的用户。
2.2 基于信息传播的网络
随着社交媒体的发展,转载和评论信息越来越方便。如果将源信息和被重新发布的信息都看作单独的节点,随着转载过程的进行,将构建起一个多级层次网络。通常可以采用树型布局、圆形布局、帆形布局和曲线布局来探索信息的传播过程[20],如图3所示。其中,树型布局用于突出分层特征,圆形布局和曲线布局用于突出整体扩散模式和关键点,而帆形布局则突出信息转载随时间的演变过程[3, 20]。此外,还可以使用平行坐标来展示各个节点之间的关系和转载的时间顺序,从而说明事件的演变过程[21]。D-Map可以将源信息传播网络中的相同用户进行合并,采用地图隐喻的方式展示信息传播模式[22]。采用动态流体模型可以检测信息扩散的速度和范围[23]。利用机器学习算法,可以有效识别虚假信息,从而及时阻断谣言的传播[24]。
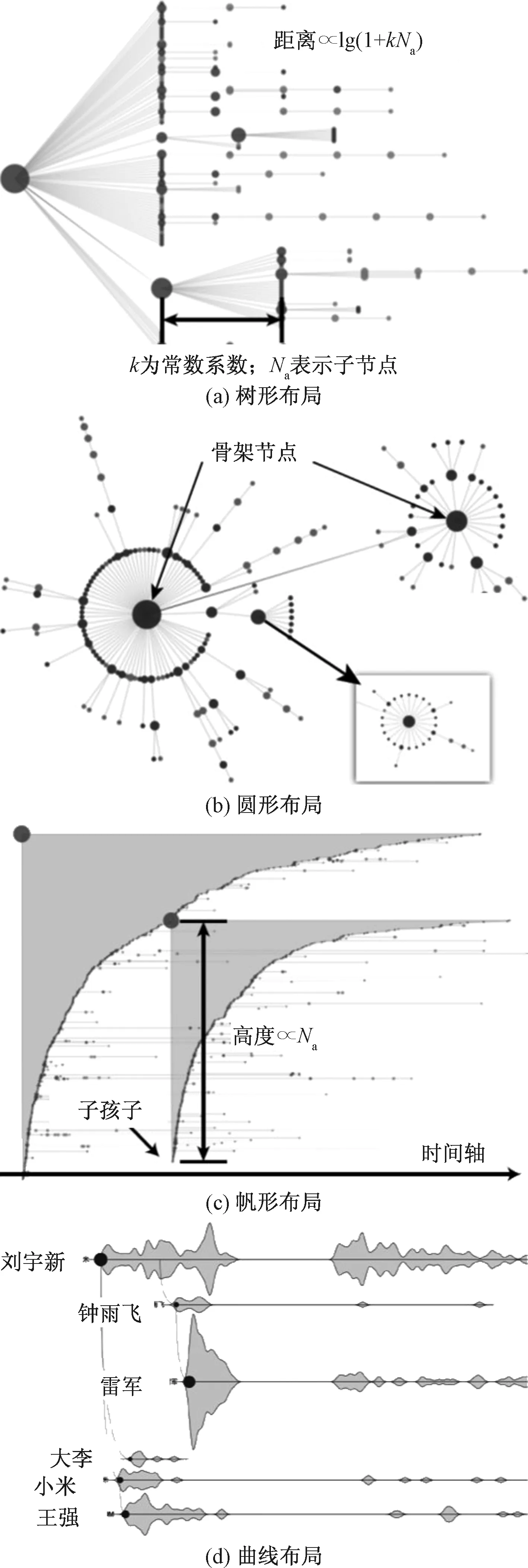
图3 多级层次网络的不同布局[20]
3 时空信息可视化
很多社交媒体用户会在账户中设置自己的地理位置,可能具体到地区、城市,也可能只是宽泛到国家,这可以为分析社交媒体信息提供地理背景[3]。虽然这些地理位置不是很精确,但是在进行信息扩散分析时,可以结合这些地理位置信息进行地域扩散分析[25-27]。
Cao等[25]采用圆形地图隐喻的方式来描述信息在时空背景下是如何传播的。通过进行地理信息扩散分析,可以得到某个特定主题的地理分布,并发现社交媒体参与者的空间分布[20],还可以同时研究不同区域针对某个特定主题的情绪分布情况[26]。
另外一种地理位置信息来自信息本身带有的地理标记,虽然这个比例仅有大约3%[28],但由于信息基数大,所以具有地理标记的信息数量也是很大的。这类信息一般包含时间戳、位置(纬度和经度)和文本信息等。对于带有地理标记的消息,可以采用的可视化类型有散点图[29]、热图[30]、密度图[31]和3D直方图[32]等。将这类信息整合起来,可以用于探索围绕某个社会事件所产生的社交媒体信息的空间、时间分布情况[30,33]。如果将带有地理标记的消息与其他数据融合在一起,还可以支持在一些特定场合的应用,例如用于城市规划[34]。
4 文本可视化
社交媒体的文本可视化一般包括关键字、主题和情绪可视化。其中,关键字是在文本上下文中使用频率较高的词,主题是社交媒体内容的摘要,情绪是根据文本内容提取的用户的态度[35-36]。通过分析用户所发表的文本中的关键字、主题和情绪可以得到丰富的语义信息[37-39]。
词云常用于关键字的提取,一系列的词被排列在平面上,词的字体越大代表相应的词出现的频率越高[40]。在财务模式分析[41]问题上,可以分析关键字之间的相关性[42],或者关键字、用户和标签之间的相关性[43]。此外,采用分层可视化可以分析关键字随时间的动态演变[37],首先将不同的文本按照时间顺序进行分层,然后获取不同层次文本的关键字,最后将这些关键字按照时间顺序排列。但是,词云无法体现对文本内容本身的理解。
提取社交媒体内容的主题是一件非常重要的事情。这些主题体现了用户对文本内容的理解。在主题可视化研究中,可以采用主题河隐喻的形式展示社交媒体内容主题随时间演变的过程[44]。用平行河流(图4)来表示从同一事件中派生出的多个主题,用河流的波动表示围绕特定主题的消息数量[38,45],可以用于分析某个社交媒体事件爆发的原因,并确定源信息和相关的衍生主题[46]。由于不同用户之间存在相互影响,同一事件的不同主题之间也存在竞争行为,因此随着时间的推移,这些主题会经历出现、发展、替换和消亡的过程[47]。此外,使用树型结构可以展示衍生出的分层主题[48-49]。

图4 平行河流,用于可视化动态事件和主题演变[38]
情绪分析是文本分析的另一项重要内容,通过分析公众对社会事件的情绪,可以评估公众对社会事件的态度。利用一定的算法可以从文本文档中自动提取情绪,并进行交互式可视化,支持用户分析情绪模式,探索关键问题[50-52]。除了简单地将情绪分为愤怒、喜悦、悲伤等类型,还可以根据相关性将不同情绪进行分类,如愤怒-恐惧、期待-惊喜、喜悦-悲伤和信任-厌恶[53]。将情绪随时间推移变化的情况绘制成河流[39],并采用不同的颜色来对不同的情绪进行编码[54],可以形象直观地展示不同情绪随时间的演变,如图5所示。如果要分析群体的综合情绪动态,可以采用高维投影的方式[55]。
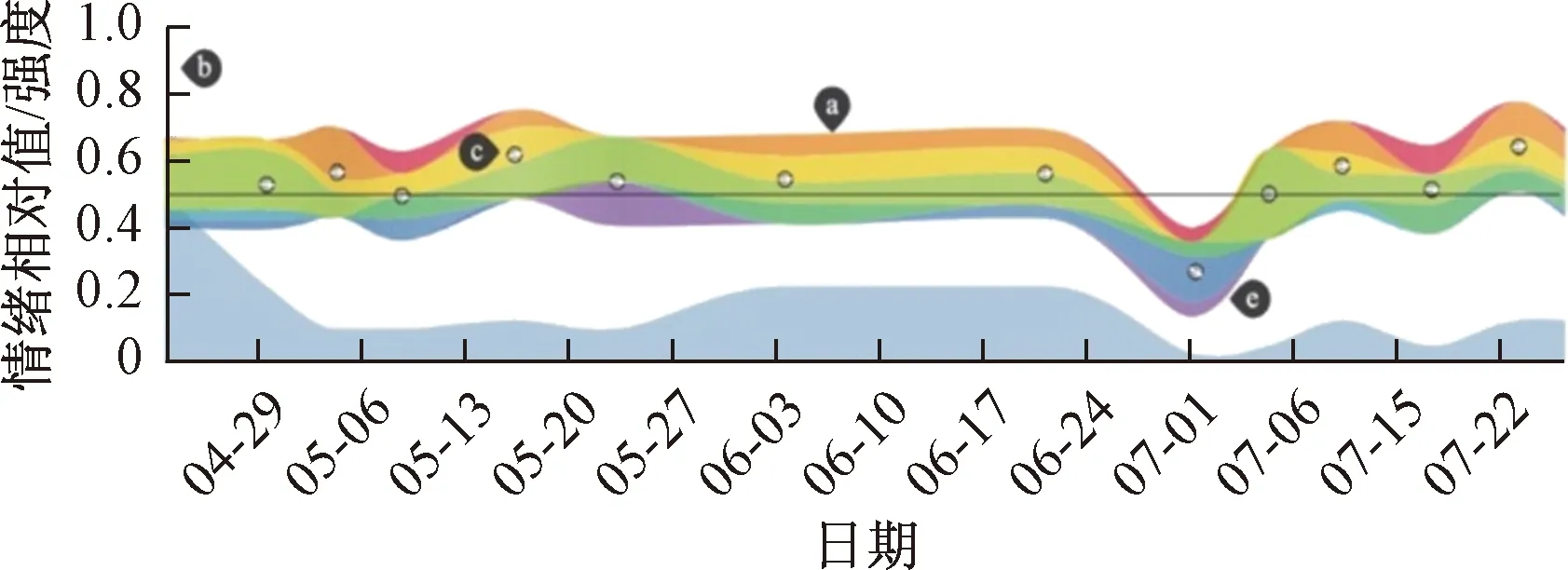
图5 随时间变化的情感可视化[39]
5 分析过程中遇到的问题与挑战
在大数据时代,数据量巨大、数据类型多样的特点尤为显著,除了综合运用可视化交互技术、自然语言处理技术和多媒体技术外,计算机并行处理技术也被用来处理大规模流式社交媒体数据。
在进行数据采集时,应该注意采样数据是存在偏差的。这是因为采样数据来自使用社交媒体的人,这些人更倾向于年轻人和使用智能手机的人。同时,由网络媒体机器人发布的信息也会引起采样数据的偏差。再者,采样数据往往只是某个或某几个社交媒体平台的数据,不能覆盖所有的社交媒体范围[56]。
由于社交媒体用户之间的关系一直处于变动之中,所以社交网络具有明显的时间特征,分析时应该关注动态图的演变[57-58]。
基于河流的视觉隐喻可用于动态文本、主题和情绪可视化[59-60],但是这种方法是存在局限性的。它将时间作为一个维度,而将其他所有信息都集成在另一个维度上,这会增加对除时间外的信息解读的难度。所以,需要深入研究采用何种可视化的形式进一步表示文本信息与时间、地理信息的复杂动态特征。同时,如何将图片和视频所隐含的语义同文本信息的语义结合起来[61-62],需要进行深入的研究。
不同的人对用户行为的理解也是不同的。对用户行为的理解将改进可视化方式和数据分析方法[63-64]。但是,现在可视化分析和社会科学研究中缺少相应的研究内容[65-66],所以应该在这方面进行一定的工作。
6 结论
可视化分析是近年来一门新兴的数据分析技术,集成了可视化、人机交互和数据挖掘等多个领域的知识,可以增强人类对复杂数据的分析和探索能力。对社交媒体数据进行可视化分析可以用于可视化监控、特征提取、事件检测、异常检测、预测分析和情况感知,应用前景广阔。现实世界的数据是充满噪声和不确定性的,利用可视化分析可以将这些展示出来,有利于分析人员进行判断。首先从数据采集与治理、数据管理和数据分析的角度阐述了可视化分析的步骤。然后,具体阐述了社交网络可视化、时空信息可视化和文本可视化实现的方式。最后,对可视化分析过程中遇到的问题与挑战进行了讨论。未来,可视化分析技术将向着能处理更大规模的数据集和更复杂的数据类型的方向发展。
猜你喜欢
食品科学与人类健康(英文)(2022年2期)2022-11-28
世界科学技术-中医药现代化(2022年3期)2022-08-22
北京测绘(2022年6期)2022-08-01
自动化学报(2022年4期)2022-05-28
意林彩版(2022年2期)2022-05-03
师道·教研(2022年1期)2022-03-12
好日子(2021年8期)2021-11-04
北京测绘(2021年7期)2021-07-28
河南科技学院学报(自然科学版)(2020年2期)2020-05-22
小型微型计算机系统(2020年5期)2020-05-14
