
TBM关键参数智能掘进系统的设计与实践
2020-12-14 09:50徐剑安李建斌荆留杰徐受天游宇嵩
隧道建设(中英文) 2020年11期
徐剑安, 李建斌, 荆留杰, 3, 徐受天, 游宇嵩
(1. 中铁工程装备集团有限公司, 河南 郑州 450016; 2. 中铁高新工业股份有限公司, 北京 100000; 3. 中国矿业大学 深部岩土力学与地下工程国家重点实验室, 江苏 徐州 221116)
0 引言
当前,我国已成为世界上隧道修建需求最大、修建速度最快、修建难度最高的国家。预计未来10年,我国采用TBM施工的隧道总计超过6 000 km,需要各类TBM超过200台[1]。但TBM在运行过程中时有发生卡机,甚至造成人员伤亡等事故[2-3]。因此,智能掘进技术已成为TBM领域的重要研究课题。
针对TBM智能掘进技术,国内外许多专家学者做了大量的研究,开发了相关的系统平台。国内,江玉生等[4]针对盾构施工参数自动预警进行了研究,提出了参数预警的判断准则及判断方法,并将参数预警整合于盾构风险监控系统;华振[5]通过开发盾构集群化监控与异地决策管理系统,实现了盾构的集群化监控;刘杰[6]完成了矩形盾构施工实时数据采集系统远程交互软件研制;高文学等[7]实现了隧道施工掌子面可视化实时显示与分析;王俊彬等[8]开发了盾构施工信息监控管理系统;陈文远等[9]实现了盾构集群式远程监控与管理,应用可视化技术将盾构施工中的三图一表进行了展示。国外,文献[10-12]将非线性回归、神经网络、粒子群算法等人工智能算法应用于TBM掘进速度预测,从而对TBM的工作状态进行评价;文献[13-14]利用大量已建TBM隧道掘进数据建立了知识库及数据库,研究了不同类型TBM掘进参数预测方法;文献[15-16]提出了一种基于异构现场数据和数据驱动技术的动态负荷预测方法,采用自适应神经模糊推理系统(ANFIS)和支持向量回归(SVR) 开发了较为可靠的预测模型。
在TBM智能掘进技术方面虽然取得了一些研究成果,但较少涉及智能掘进系统插件式开发及算法集成,且传统TBM智能掘进系统往往通过定制化开发,无法实现系统的快速开发和算法的便捷集成。本文设计了一种TBM关键参数智能掘进系统插件开发框架,基于该框架可快速搭建TBM智能掘进系统,并且以低耦合方式集成算法模型,以期推动TBM智能掘进技术的发展。
1 总体方案设计
1.1 系统技术框架设计
TBM关键参数智能掘进系统集TBM施工过程实时监控、分析以及决策于一体。结合系统的功能设计,根据系统中数据的处理流程,将整个系统技术框架划分为数据采集层、数据分析层、实时决策层,如图1所示。
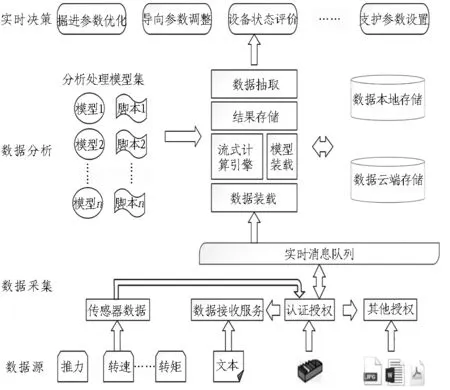
图1 TBM关键参数智能掘进系统技术框架
其中,数据装载模块负责接收传感器等装置传输的实时流数据,数据抽取模块负责批量抽取历史数据,模型装载模块负责将分析处理模型集中的计算模型和脚本加载到系统中,该系统能够根据分析处理模型在完整大数据集上实时计算出相应的指标,并进行判断,最终将结果反馈给实时决策层,从而对系统关键参数进行调整。
1.2 技术架构选型
TBM关键参数智能掘进系统最终应用于工业控制环境,具有响应速度快、与现场设备通信频率高等特点,故采用C/S架构进行开发。相对于B/S架构,C/S架构具有如下优点:
1)充分利用客户端硬件资源进行数据处理和计算,响应速度更快,且更适合于实时控制。
2)方便访问本地资源,如文件系统、打印机、串口等,能够高效地与施工现场各类仪器仪表建立通信。
3)较易实现随操作系统自动启动;实现后台服务进程;防止意外关闭和实现关闭后自动重新运行。
C/S的缺点是部署、版本升级较困难;跨平台(操作系统、底层设备等)功能差,可能需要对不同平台单独开发和测试。但考虑到本系统仅应用于工业生产,能够保证平台的统一性,且其用户数量及装机数量远远不及普通B/S,故这些缺点对本系统的影响并不显著。
系统客户端安装于TBM主控制室,服务器端分为通信服务器和后端大数据平台,均位于总部机房。多种数据库与大数据集群通过通信服务器间接通信。通信服务器与客户端之间通过TCP套接字(Socket)或HTTP通信,其系统架构图如图2所示。

图2 TBM关键参数智能掘进系统架构图
2 通信方式与数据库设计
TBM关键参数智能掘进系统客户端安装于TBM主控制室,通过光纤与外界连接;在地面和TBM上安装专用路由器,使客户端所在工业电脑直接连接到互联网,与通信服务器建立连接;通过路由器权限设置实现TBM所在局域网内的相关设备与外界隔离,确保设备和数据的安全性。
通信服务器将大数据分析、图像处理、模型最优参数等结果传送给客户端。客户端向服务器传送现场各类数据和请求信息,如图3所示。

图3 TBM关键参数智能掘进系统通信方式
2.1 PLC通信设计
TBM设备主要通过PLC完成动作指令的下达和传感器数据的读取,故主要考虑如何与PLC进行通信。
工业电脑主要通过MPI、工业以太网、PROFOBUS、MODBUS、RS232/485、CAN、CC-LINK等方式与PLC建立通信。不同PLC提供的通信接口不尽相同。为了提高兼容性及降低开发难度,OPC基金会制订了OPC工业标准,提供了PC访问不同PLC的软件开发接口。
目前PLC最常用的通信方法是通过OPC、OPC UA读取数据。但PLC厂商的OPC服务器通常只能在Windows平台上运行,体积庞大,占用资源多,故宜选用能直连PLC的内部协议,通过以太网进行连接,实现数据的交互。
在TBM关键参数智能掘进系统开发的第1阶段,涉及PLC的只有西门子S7-300/400系列,采用S7协议完成TBM关键参数智能掘进系统与PLC的通信。PLC数据读取结构如图4所示。
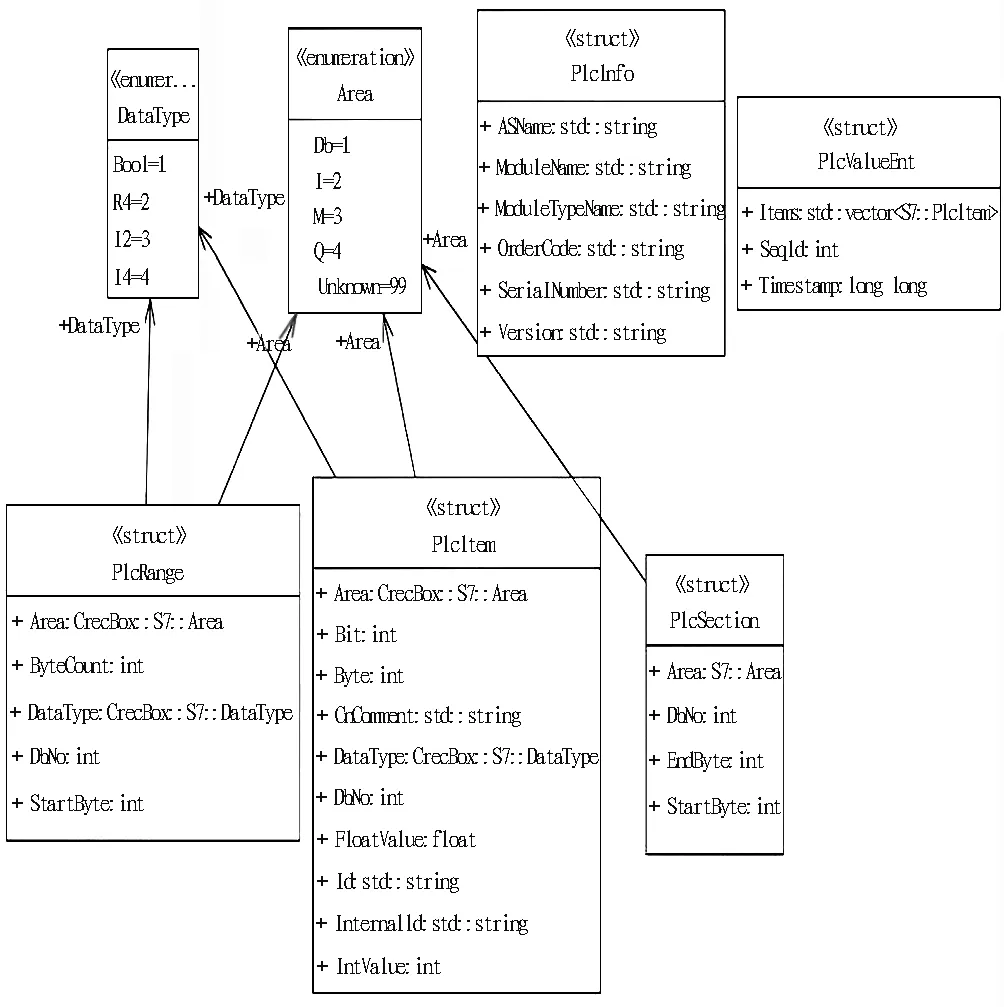
图4 PLC数据读取结构图
2.2 C/S通信设计
客户端与服务器之间的通信采用TCP方式。TCP连接方式为短连接,故无法保持会话。在实际应用中,客户端每次可通过向服务器出示Session ID的方式来确认身份,保持会话。Session ID由首次登录客户端时服务器随机生成。当客户端长期无活动(通常表明网络中断)时,会话失效,需要重新登录认证。
通信服务器将大数据分析、图像处理等结果传送至系统客户端,客户端向服务器传送现场各类数据和请求信息。通信协议头采用二进制形式,提高传输效率,通信协议定义表见表1。

表1 通信协议定义表
2.2.1 服务器数据库设计
服务器除现有系统的MongoDB、Redis数据库外,需设计额外的MySQL数据库表,数据库名TBM Server主要包含以下内容:
1)用户信息(见表2)。每台TBM有单独的用户名和密码,以区分不同的数据源。不同角色具有不同的管理权限,可依据权限完成所需操作设置。
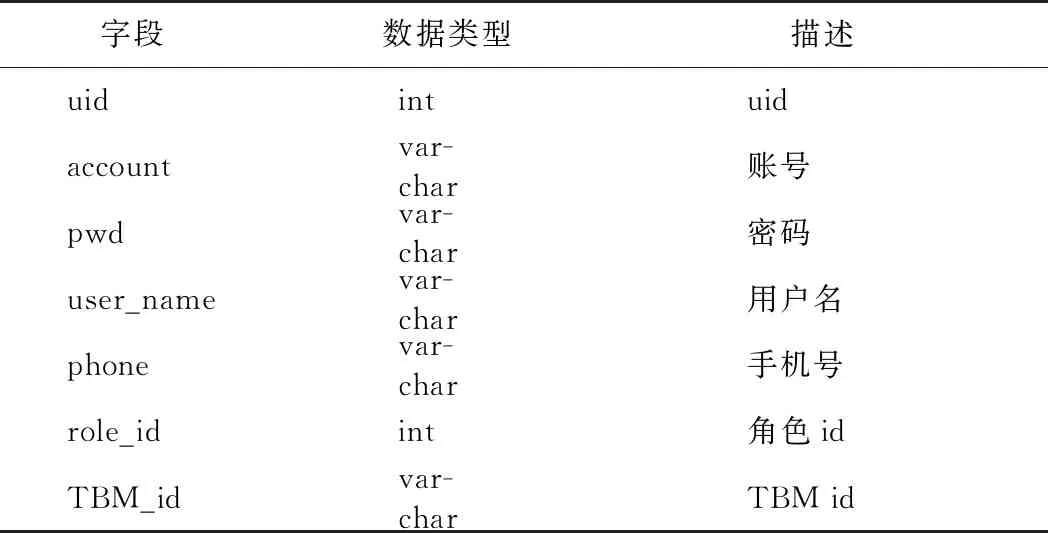
表2 用户信息
2)客户端通信连接状态(见表3)。记录客户端的在线状态;记录客户端与服务器通信的数据传输状态,特别是需要数据续传的情形。

表3 连接状态
3)服务器日志(见表4)。记录服务器的运行日志;记录客户端的登陆、数据提交等重要请求。
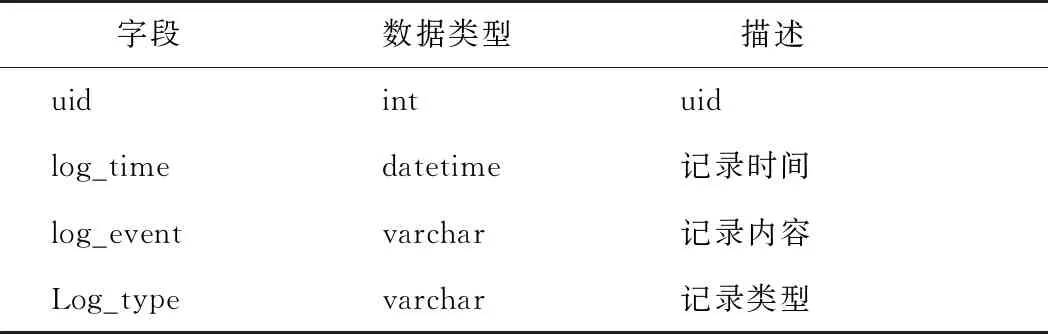
表4 服务器日志
2.2.2 客户端数据库设计
客户端数据库采用本地运行形式,选用开源的MySQL。根据系统具体的应用需求,将数据分3类:地质数据、设备及设备感知数据、日志与缓存。共建立多张数据表,用于存储地勘数据、超前预报数据、不良地质数据、设备实时数据、设备常量数据、系统及操作日志。地勘表和实时数据表如表5和表6所示。

表5 地勘表
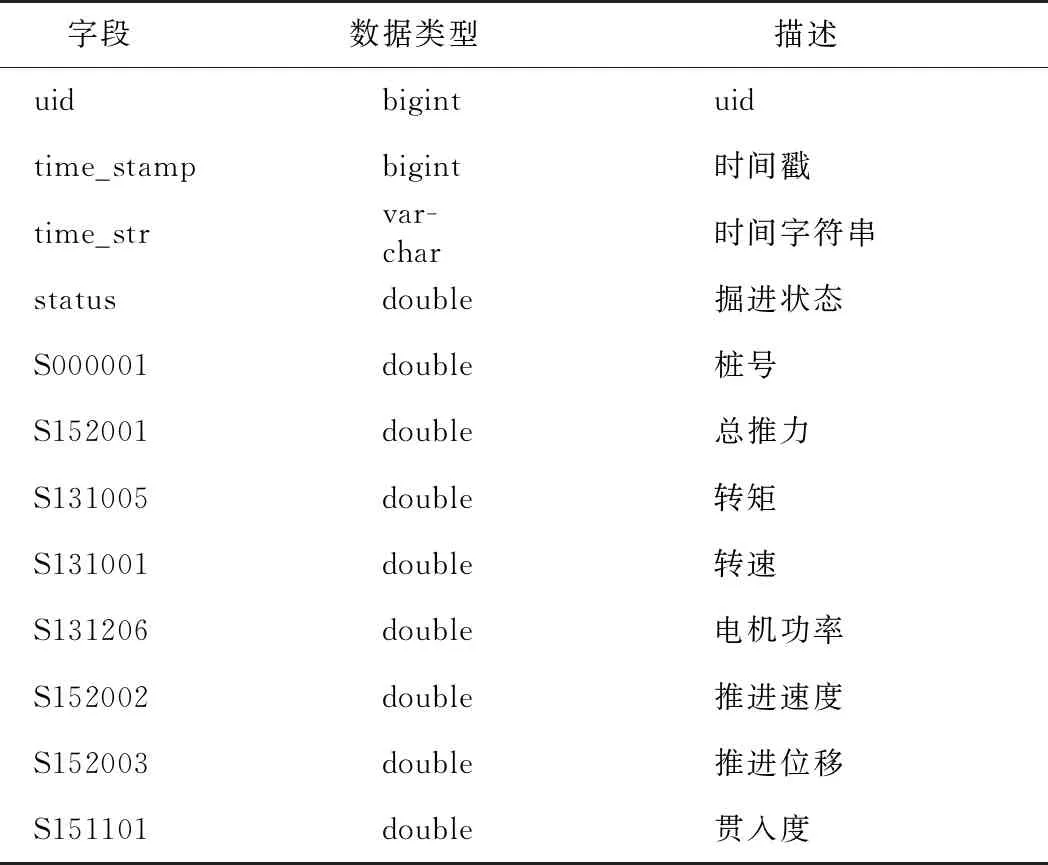
表6 实时数据表
3 智能控制模型与集成
3.1 关键参数预测模型
选取吉林引松供水工程几千个掘进循环的岩机信息作为样本数据库。
从样本数据库中提取岩体状态参数,建立岩体状态参数矩阵N,N=[U,Jv,W],其中U为岩石抗压强度,MPa;Jv为岩体单位体积节理数,条/m3;W为围岩等级(I~V)。通过循环均值的方法得到掘进循环上升段与稳态段的分界点,截取掘进循环上升段数据组成上升段掘进参数矩阵M1,M1=[F,T,P,R],其中F为刀盘推力,kN;T为刀盘转矩,kN·m;P为贯入度,mm/r;R为刀盘转速,r/min。
从样本数据库中筛选出上升段岩机信息数据,分别采用神经网络net、支持向量机svm和最小二乘回归reg 3种方法对岩机数据进行训练和预测,输入量为上升段掘进参数矩阵M1,输出量为岩体状态参数矩阵N,分别得到相应的神经网络模型Ynet1、支持向量机回归学习机模型Ysvm1和最小二乘回归数学模型Yreg1。
Ynet1是以掘进参数为输入层,以岩体参数为输出层的3层神经网络模型,如图5所示,选取S型正切函数和对数函数分别作为隐含层和输出层神经元的激励函数,网络训练函数为traingdx,性能函数为mse。
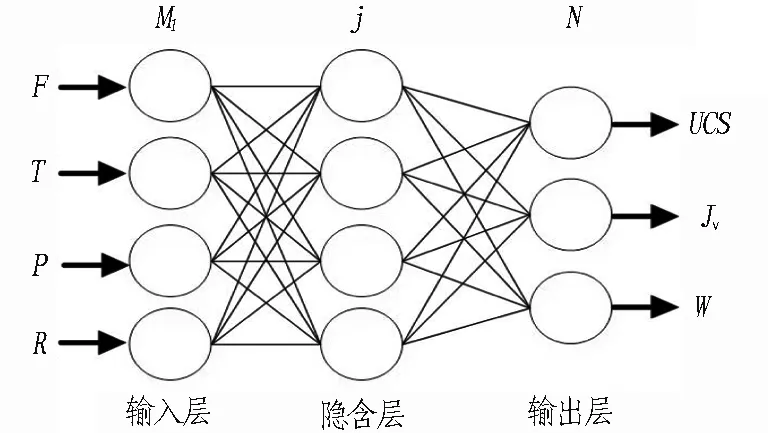
图5 3层神经网络模型Ynet1
Ysvm1的表达式如式(1)所示,Φ1(M1)是支持向量机核函数,采用径向基核函数描述。
N=ω1·Φ1(M1)+b1。
(1)
式中:Φ1(M1)为从输入控件到高维特征空间的非线性映射;ω1为权重向量;b1为偏差项。
Yreg1的数学方程形式如式(2)-(4)所示。
(2)
(3)
(4)
式(2)-(4)中:n为TBM刀盘刀具数量;c1-c18为拟合常数。
为了提高岩体信息感知结果的准确度,对3个模型Ynet1、Ysvm1、Yreg1求取的岩体状态参数结果进行加权平均,如式(5)所示。
Y1=λ1Ynet1+λ2Ysvm1+λ3Yreg1。
(5)
式中:Y1为岩体信息感知模型输出掌子面岩体状态参数;λ1、λ2、λ3为权重系数。

图6 神经网络模型Ynet2
Ysvm2的表达式如式(6)所示,Φ2(N)同样采用径向基核函数描述。
M2=ω2·Φ2(N)+b2
。
(6)
式中:Φ2(N)为从输入控件到高维特征空间的非线性映射;ω2为权重向量;b2为偏差项。
Yreg2的数学方程形式如式(7)-(10)所示。
(7)
(8)
(9)
(10)
式(7)-(10)中p1-p16为拟合常数。
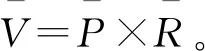
(11)
为提高掘进参数预测准确度,对3个模型Ynet2、Ysvm2、Yreg2的预测值进行数学平均
Y2=λ4Ynet2+λ5Ysvm2+λ6Yreg2。
(12)
式中:Y2为TBM掘进参数预测模型的输出结果;λ4、λ5、λ6为权重系数。
3.2 模型与系统集成
系统可视化程序与算法实现程序分属于不同的服务,彼此通过Socket进行通信,不同的算法模型只需实现可视化程序提供的通信接口,即可实现与系统的集成,通信接口如下。
1)掘进数据接收与自动提取。发送命令: push。
输入参数:总推力、刀盘转速、推进速度、刀盘转矩、刀盘转速设定值、推进速度设定值、贯入度(1×7数组,以","分隔,后期添加其他模型时,输入参数内容会发生一定更改)。
输出参数:state。当前点为有效掘进点时,反馈"0";为掘进终止点时,反馈"1";非掘进点或异常值数据时,反馈"-1";出现报错时,反馈"参数错误"。
2)岩体感知模型。发送命令:ls。
输出参数(字典格式):{"UCS_pre": ucs,"Jv_pre": jv,"W_pre": w }。
3)辅助驾驶模型。发送命令: lle_svr。
输出参数(数组格式): 推进速度、刀盘转速、总推进力、刀盘转矩。
算法模型程序采用Python语言开发,结构如图7所示。

图7 算法程序结构图
4 系统运行
TBM关键参数智能掘进系统运行流程如图8所示,为避免系统软件拷贝至其他上位机上运行,系统软件只允许在已注册的上位机上运行。系统首先会判断上位机之前是否已经注册,若尚未注册,则需要输入注册码;若已注册,则根据XML初始化系统属性,并判断是否加载欢迎界面,再根据Common初始化界面属性,在与算法程序通信后加载Plugins插件,最终实现整个系统的正常运行。

图8 TBM关键参数智能掘进系统运行流程图
辅助驾驶功能模块主要用于关键参数等数据的计算与展现,包含虚拟掘进功能、掌子面岩体状态实时感知、设备状态评价、设备控制参数智能推荐、雷达图/趋势分析图、施工建议措施等单元。系统运行主界面如图9所示。

图9 TBM关键参数智能掘进系统运行主界面
5 现场验证
实际验证依托吉林省中部城市引松供水工程总干线施工四标段项目,现场应用里程范围为53+552~+192,应用地层为花岗岩地层,中等风化状态。TBM关键参数智能掘进系统安装在主控室琴台的上位机上,供TBM操作者使用,系统现场应用如图10所示。

图10 TBM关键参数智能掘进系统现场应用
TBM关键参数智能掘进系统与上位机通过网线连接,TBM操作者在掘进时关注辅助界面数据信息,当辅助界面提示参数有较大波动时,则可切换至设备感知界面或岩体感知界面查看相应的详细信息。
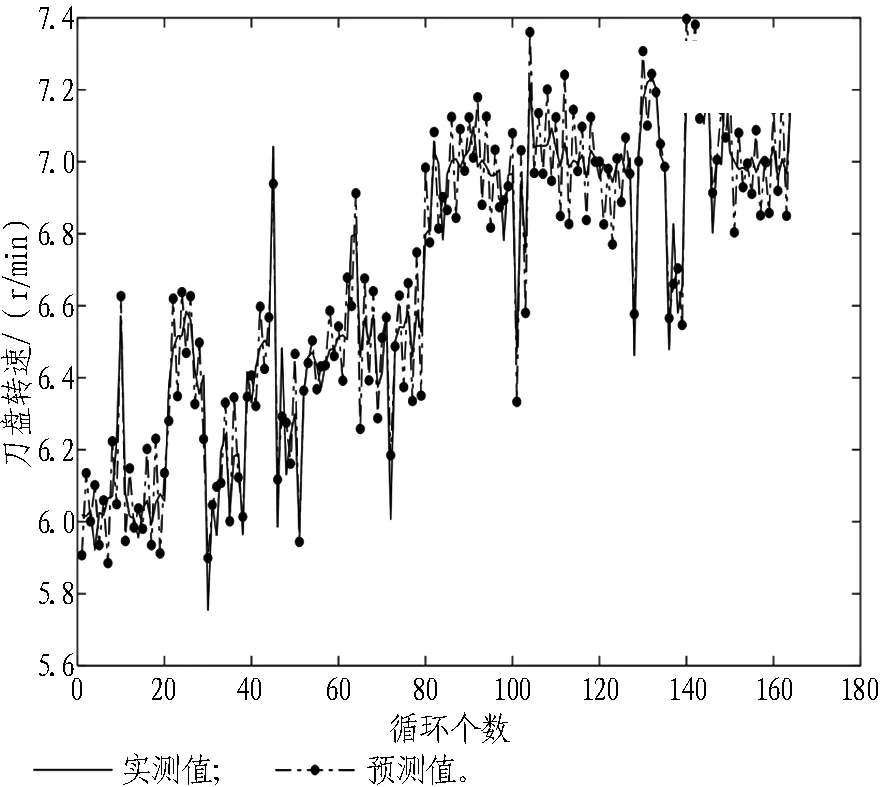
设备掘进参数可通过PLC直接读取,因此对设备参数的预测可以精确地评估。通过对比模型预测值与实际值可发现,掘进参数预测模型对刀盘推力、刀盘转矩、刀盘转速、推进速度4个关键参数的预测准确度均超过84%;预测效果稳定,满足工程使用,对比结果如图11所示。
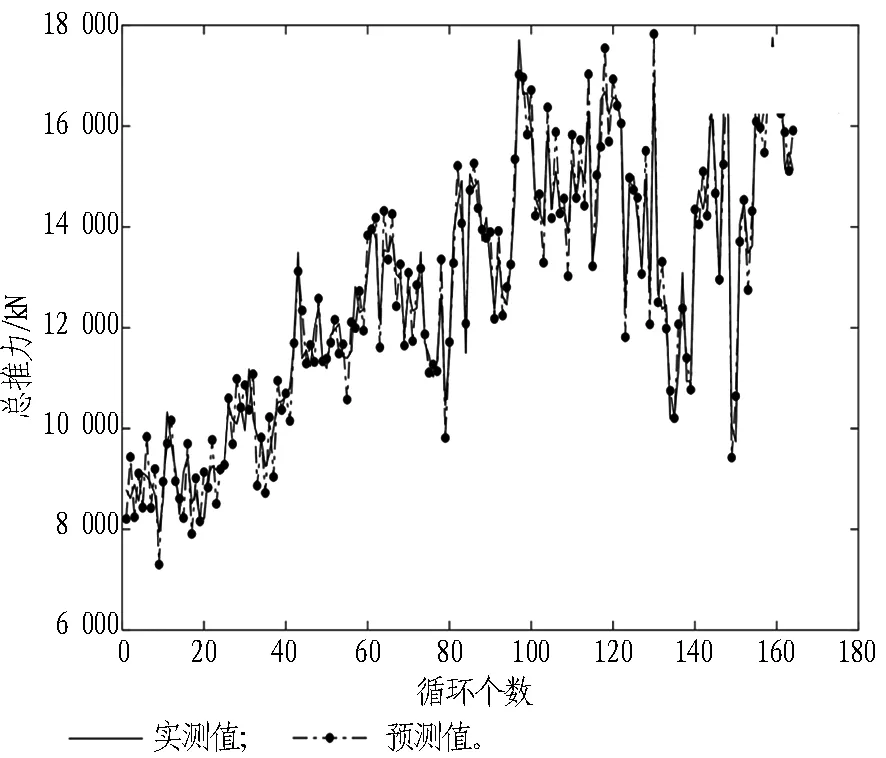
(a) 总推力 (b) 刀盘转矩
6 结论与讨论
和以往研究工作相比,采用插件式方法开发并集成算法模型,可便捷式开发低耦合的智能掘进系统,用于TBM智能掘进过程中关键参数的预测及控制。
通过实际工程实践,对比TBM关键参数智能掘进系统中刀盘推力、刀盘转矩、刀盘转速等关键参数,表明系统预测值和主司机实际使用掘进参数基本一致,可为主司机快速提供掘进参数建议值,为TBM掘进提供智能化服务。此系统已连续运行6个月,具有较好的稳定性,在施工过程中根据算法模型进行实时计算,将结果用于预警或控制,减少了TBM掘进过程中事故的发生,降低了施工方的损失,提高了施工效率。
虽然取得了一定的研究成果并进行了工程实践,但系统尚需应用于更多的项目才能进一步完善,且插件和算法只有不断积累沉淀才能更好地贴合不同项目工程的需要。如何在系统运行过程中保障软件层的安全也是本系统下一步需要努力的方向。
猜你喜欢
新作文·高中版(2022年5期)2022-11-22
新作文·高中版(2022年5期)2022-11-22
人民长江(2022年10期)2022-11-04
——稳就业、惠民生,“数”读十年成绩单
人民周刊(2022年17期)2022-10-21
矿山机械(2022年10期)2022-10-20
中国重型装备(2022年1期)2022-02-11
商品与质量(2021年42期)2021-12-03
有色金属(矿山部分)(2021年4期)2021-08-30
洛阳理工学院学报(自然科学版)(2021年2期)2021-07-14
有色金属设计(2020年3期)2020-12-16
