
两种高吞吐量低延迟光数据中心网络架构研究
2020-12-10 09:14:30熊丽婷张绍彪揭吁菡
光通信研究 2020年6期
熊丽婷, 张绍彪, 揭吁菡
(华东交通大学 理工学院,南昌 330100)
0 引 言
能耗、延迟和可扩展性是光数据中心网络[1](Data Center Networks, DCN)架构的关键属性。传统的DCN(例如Fat-tree[2]、Bcube[3]和VL2[4]等)使用多层方法构建,难以解决大规模集群上的功耗、延迟和吞吐量等问题。光DCN使用微机电系统(Micro Electro Mechanical System, MEMS)交换机和阵列波导光栅路由器(Arrayed Waveguide Grating Router, AWGR)等,能减少能耗和延迟,但依然难以适应DCN中的快速分组交换。
目前,AWGR光交换架构已有一些研究成果。如文献[5]提出了一种数据中心光开关(Datacenter Optical Switch, DOS)架构;文献[6-7]也是DOS架构,但其基于电缓冲器,能耗较高;文献[8]提出了512端口的AWGR,覆盖了C、S和L波段的所有波长,但无法扩展至大规模DCN(数千个机架),且成本较高;文献[9]以“天河二号”超级计算机的拓扑结构为基础,提出了一种低延迟的光电混合交换互联网络结构;文献[10]的架构基于快速可调波长激光器(Tunable Wavelength Converters, TWC)和光波长AWGR;文献[11]提出了一种低功耗和低成本架构,由集群内和集群间网络组成,其主要缺点是架构中的服务器数量不能更改。
上述很多基于AWGR的架构采用了TWC,成本较高,有些架构的延迟和能耗也较高,因此,本文提出两种高吞吐量低延迟的无源光DCN架构。仿真结果表明,所提方法可实现低于18 μs的分组时延和100%的吞吐量,且能够适应各种不同的架构参数。
1 系统模型
本文采用了分层式架构,一组机架组成一个集群,一组集群组成整个DCN。假定每个集群包含M个机架,即S/P=M,式中:S为总机架数;P为AWGR的总端口数。W为可用波长数,设W=P·F,式中,F≥1为整数。AWGR以循环的方式将波长从输入端口路由至特定输出端口:
式中:i为AWGR的端口序号;w为波长索引序号;mod为求余运算函数。
本文假定分组传输由一个中央控制器调度,对于大规模DCN,可将其替换为分布式调度[11]。由于系统是时隙化的,一个时隙包括分组传输时间(假定所有分组均为相同大小)和发射机调谐时间。在每个时隙中,控制器对下一个时隙的传输进行调度。每个时隙中,所提方法遵循公认约束条件最大限度增加分组传输数量,如一个发射机每次最多可发送一个分组。公认的约束条件可参阅文献[12]。本文中的一些符号及其含义如表1所示。
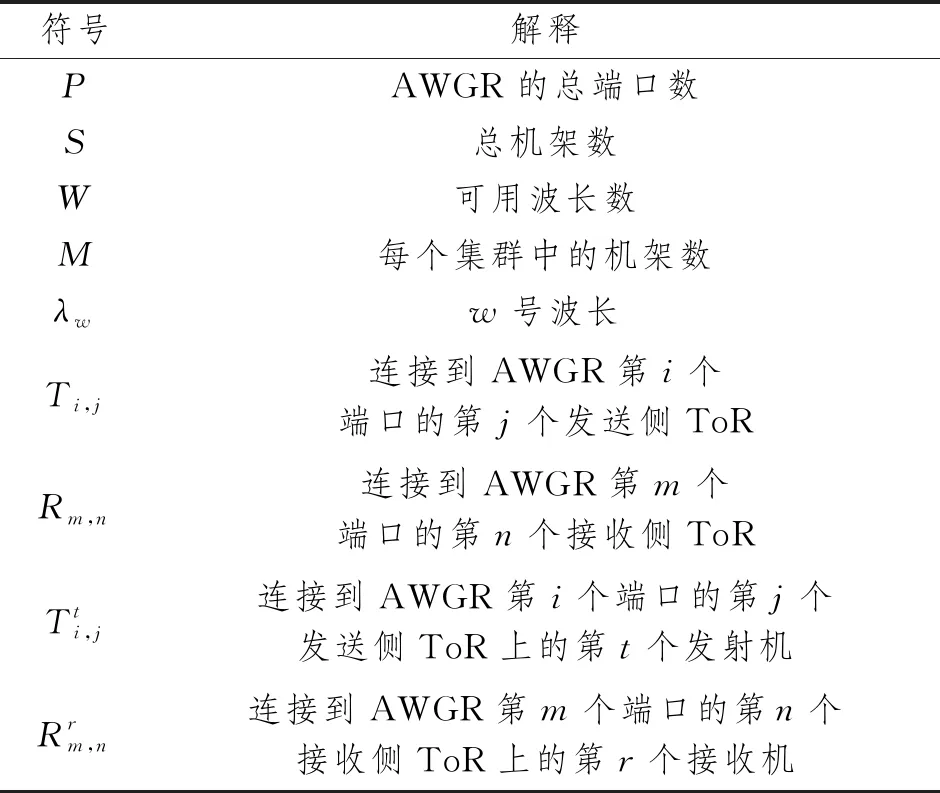
表1 符号定义说明
2 提出的架构算法
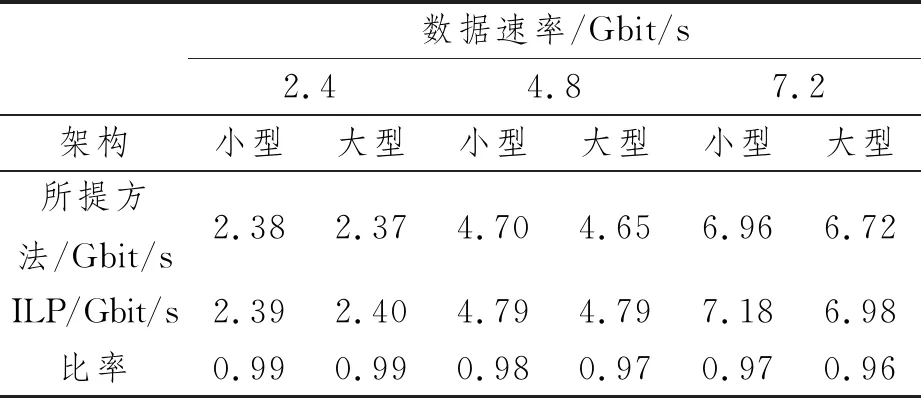
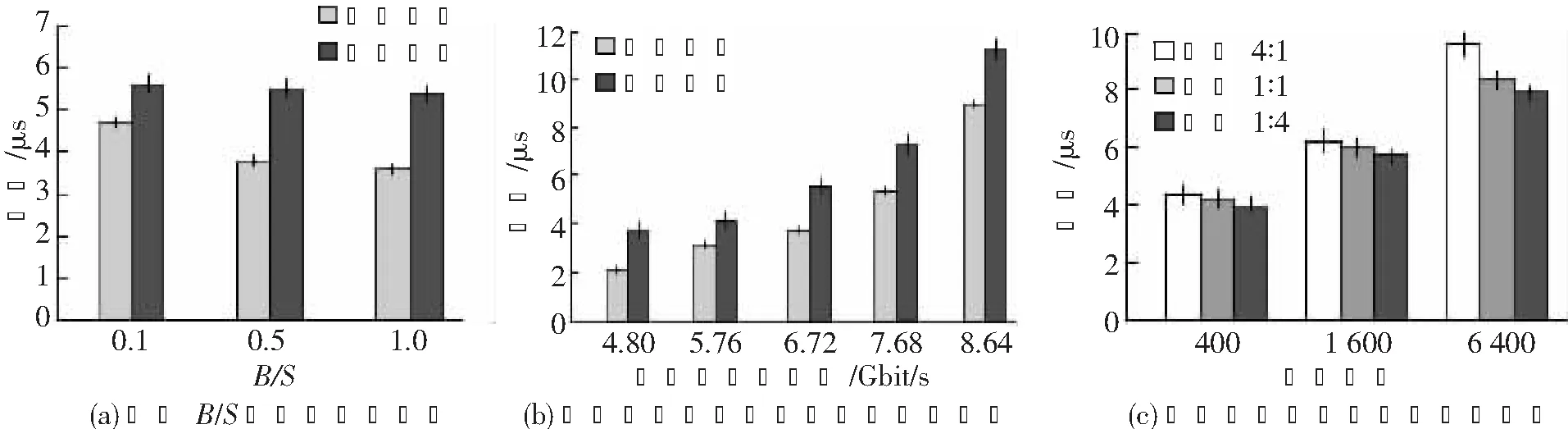
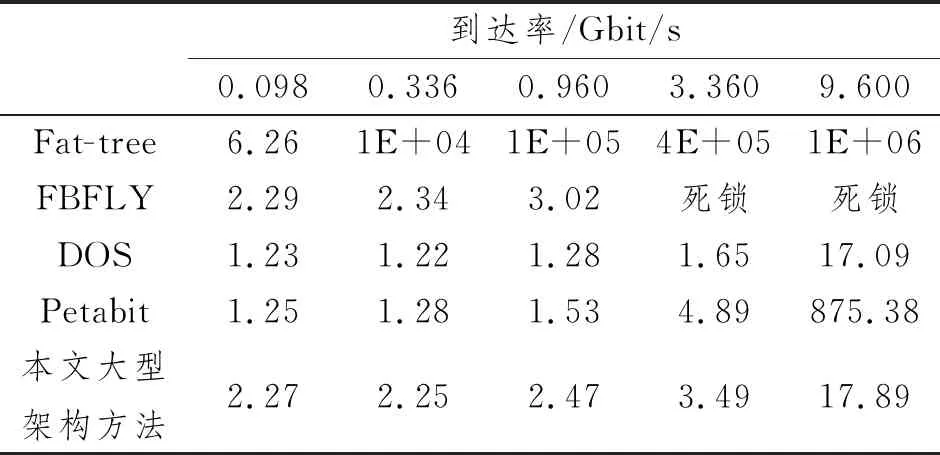
本文给出了基于不同规模DCN的无源光DCN架构:(1)小型DCN:S≤P,P一般约为50,最高可至512;(2)大型DCN:P 该场景中,S≤P,且每个集群均为单个机架。每个机架连接至AWGR的一个端口。设W为N的整数倍,即W=α·N,其中α≥1为整数。该架构如图1所示。解复用器输出端口的信号可以是固定波长或固定波长范围。由于解复用器的每个输出端口都连接至一个宽带接收机,后者在同一时间仅能接收一个分组。 图1 小型DCN架构示意图 由于先考虑的机架在分组调度中的优先级更高,本文使用循环方法来选择起始机架,并从该机架开始依次进行分组调度。换言之,在序号为τ的时隙,本文方法从机架Ti,1开始选择分组,其中i为 式中,%为求余符。 现在解释如何对分组传输进行调度,以及调度分组传输的波长。假定一个分组等待从Ti,1传输至Rm,1,ci和cm分别为第i个发射机和第m个接收机。若Ti,1(ci)和Rm,1(cm)上调度的分组数量均不超过N,且从Ti,1至Rm,1(ci,m)的调度分组数量不超过F,则调度该分组从Ti,1传输至Rm,1。由式(1)推导可知,波长分配由AWGR的输入端口数和输出端口数决定。若i≤m,则可将波长调至式(3)中的某个波长以成功传输分组: 式中,f为一个乘数,f≤F-1,可用波长最大数量为W=F·P。若i>m,则将波长调至式(4)中的某个波长以成功传输分组: 耦合器对来自可调谐发射机的不同波长进行组合,并将组合信号输出到AWGR。将AWGR的输出信号均匀地解复用为N路,即将第1个波长解复用到输出端口1,下一个波长解复用至端口2,依此类推。小型DCN架构中分组调度的伪代码如下所示: 1.γ=τ%S+1 ;i=(int)γ/M+1 2. forTi,1中的每个共享缓冲器do 3. 缓冲器中的分组要从Ti,1传输至Rm,1 4. ifci 5. then 选定发射机ci和接收机cm传输的分组 6. ifi≤m 7. then将波长调至:m-i+ 1+fi,m·P 8. else 9. 将波长调至P+m-i+1+fi,m·P 10. end if 11.ci++;cm++;fi,m++; 12. end if 13.γ=γ%S+1 14. end for 伪代码中:(int)表示取整;fi,m为发射机ci到接收机cm传输分组时的一个乘数。 图2所示为大型DCN的架构示意图。该场景中,P 图2 大型DCN的架构示意图 设W为连接到解复用器的可调谐发射机数量的整数倍,即W=β·N·M,式中,β≥1为整数。则集群中第n个机架的可接收波长范围为 1.forTi,1中的每个共享缓冲器 do 2. 缓冲器中的分组要从Ti,j传输至Rm,n 3. ifci, j 4. then选定发射机ci, j和接收机cm, n传输的分组 5. ifi≤m 7. else 9. end if 10.ci, j++;cm, n++;fi,m++; 11. end if 12.γ=γ%S+1 13. end for 所提分组传输方法和整数线性规划(Integer Linear Programming, ILP)的每个机架吞吐量的比较如表2所示。两种架构中,集群间AWGR的大小为40×40。每个ToR上虚拟缓冲器的数量为B,可用波长数量为160。将集群间和集群内的收发器数量均设为1。表2最后一行给出了所提方法与ILP的吞吐量之比。结果表明,所提方法得出的吞吐量与ILP较为接近,差异不超过7%。 表2 所提方法与ILP的每个机架吞吐量比较 本节将通过仿真评价所提方法的延迟性能。分组的到达遵循泊松过程。可调发射机的传速速率(以及波长容量)设为10 Gbit/s,调谐时间为8 ns。分组大小为1 500字节。延迟中包含传输时长和队列延迟。每个机架配置1个8 MB缓冲器,分为1个或多个虚拟缓冲器以存储要传输的分组。 图3(a)所示为本文方法在不同B值下的延迟性能。图中x轴上的数值表示B和S之比。对于两种架构,集群间AWGR的大小为40×40。对于大型场景,集群内AWGR的大小为20×20。每机架的业务到达速率为6.72 Gbit/s,可用波长数量为160。集群间和集群内收发器数量均设为1。每个时隙中,每个发射机检查ToR上虚拟缓冲器排名靠前的分组。使用更多的虚拟缓冲器时,可以检查不同目的地的更多分组[13]。因此,随着B值的提升,每时隙可传输分组的数量也会增加,由此降低延迟。此外,与B和S的比率从0.5增加到1.0相比,该比率从0.1增加到0.5时,平均延迟的降低速度更快。这是因为,当比率从0.1增加到0.5时,平均延迟的主要约束从虚拟缓冲器数量变为发射机、接收机和可用波长的数量。 图3(b)所示为不同机架分组到达率下的延迟性能。随着到达率的增加,缓冲器中等待传输的分组数量也会变多,从而增加了延迟。增加M会造成集群间传输出现更多竞争,因此大型DCN的平均延迟较高,小型DCN的平均延迟较低。 图3(c)所示为随着机架数量S增加,大型DCN的延迟性能变化。随着S的增加,集群内和集群间的传输竞争加大,导致延迟增大。此外,随着P与M之比的下降,每个集群的规模会变大,使得更多分组采用集群内传输。在集群内传输中,机架可与同集群内的其他任意机架通信;在集群间传输中,机架可能需要进行双跳传输。因此,随着P与M比率的下降,平均延迟也会降低。 图3 所提架构方法的延迟性能 表3所示为不同架构下的延迟性能。比较的架构有本文所提的大型DCN架构、两种电学架构(Fat-tree[2]和扁平蝶(Flat Butterfly,FBFLY)[14])和两种光学架构(DOS[7]和Petabit[15])。机架数为1 024个,每个ToR上的虚拟缓冲器数量为100个。所有架构的机架收发器传输速率均设为10 Gbit/s。 对于本文所提的大型DCN架构,集群间和集群内收发器数量均设为1。每个ToR上的虚拟缓冲器数量为S,可用波长数量为160个。在Fat-tree中,随着业务到达速率的增加,上行和下行的转发分组在聚合层的交换机中出现拥塞,造成极大的延迟和较大的丢包数。当每机架业务到达率达到3.36 Gbit/s时,FBFLY进入了死锁状态。死锁意味着交换机的所有虚拟缓冲器均被分组填满,无法转发更多分组。当网络进入死锁时,新到达的分组会被丢弃。DOS中,AWGR的每个端口与一个机架相连接,因此分组可通过单跳到达目的地。但其所需的波长数量远大于本文方法。当业务到达速率较低时,Petabit利用高成本设备(即TWC)实现了较小延迟。 但当业务到达速率变大时,多列AWGR的分组调度方法阻碍了低延迟的实现。与其他架构相比,本文所提大型DCN架构的平均延迟更低,分组延迟低于18 μs,且所需的波长数量较少。 表3 各方法在不同到达率下的延迟比较 (单位:μs) 本文提出了无源光DCN架构,其关键组件为AWGR。研究结果表明,所提方法得出的吞吐量与ILP较为接近,差异不超过7%。分组延迟低于18 μs,可实现100%的吞吐量。性能均优于电DCN(例如Fat-tree和FBFLY),与其他光学DCN架构(例如DOS和Petabit)大致相当。未来,本文将使提出的架构具有可重构性,以适应多变的流量模式。2.1 小型DCN架构
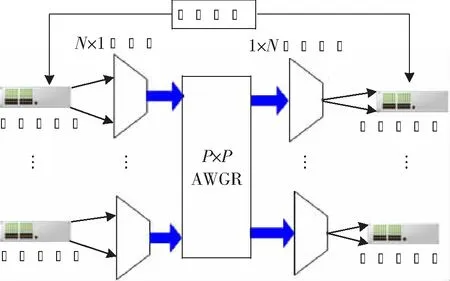
2.2 大型DCN架构


3 仿真分析
3.1 吞吐量分析
3.2 延迟分析
3.3 与不同架构方法的比较
4 结束语
猜你喜欢
轻兵器(2022年3期)2022-03-21 08:37:28铁道车辆(2021年4期)2021-08-30 02:07:14家庭影院技术(2019年12期)2020-01-19 02:07:20电子制作(2018年9期)2018-08-04 03:31:04电子制作(2018年12期)2018-08-01 00:48:02工业设计(2016年4期)2016-05-04 04:00:27西部广播电视(2015年9期)2016-01-18 03:46:07西部广播电视(2015年3期)2016-01-15 02:05:45电子设计工程(2014年19期)2014-02-27 12:00:54上海金属(2013年6期)2013-12-20 07:58:02
