
Ceph 云存储网络中一种业务优先级区分的多播流调度方法
2020-12-10 11:31:16柯文龙王勇叶苗陈俊奇
通信学报 2020年11期
柯文龙,王勇,叶苗,3,陈俊奇
(1.桂林电子科技大学信息与通信学院,广西 桂林 541004;2.桂林电子科技大学计算机与信息安全学院,广西 桂林 541004;3.桂林电子科技大学认知无线电与信息处理省部共建教育部重点实验室,广西 桂林 541004)
1 引言
全球范围内数据规模的高速增长已成为信息产业界所面临的巨大挑战。根据国际数据公司(IDC,International Data Corporation)的数据统计,全球数字领域数据量将由2018 年的33 ZB 增加到2025 年的175 ZB[1]。这种数据爆炸式增长所带来的挑战可以使用云存储技术来应对,云存储系统采用数据中心网络技术将大量存储设备集成为统一整体,进而提供海量且可扩展的存储能力[2]。目前,已有多种云存储系统投入商业使用,包括Ceph[3]、OpenStack Swift、Dropbox 以及Google Drive 等。其中,Ceph 因其稳定的架构、开源的思想和统一存储的设计模式,得到了越来越多云存储系统使用者的青睐。
随着云存储系统规模的不断扩大,网络问题逐渐成为云存储系统的主要问题。云存储网络中的流调度问题,作为影响用户体验的关键问题之一,正受到越来越多的关注。相比一般网络环境下的流调度问题,云存储网络下的流调度更加复杂。首先,云存储网络中流量的传输机制更加多样。为了提高数据存储的安全性与可靠性,云存储系统常使用多副本存储机制。在多副本存储机制下,用户上传的数据首先被存储在主存储节点,再由主存储节点分发至多个从存储节点。这使云存储网络中不仅包含一对一的单播传输,还包含大量一对多的多播传输以降低数据分发时产生的冗余流量。其次,云存储网络中流量的类型也更加多样。除了用户执行上传下载时所产生的业务流量,作为一个大规模的分布式系统,云存储系统本身也包含丰富的背景业务流,不同类型的背景业务流对网络性能的需求也不相同。如心跳数据流用于监测系统各模块是否工作正常,需要的传输带宽较少,但对时延相对敏感;而迁移业务流用于各存储节点之间的负载均衡,对时延要求不高,但需要较大的传输带宽。
因此,针对更加复杂的云存储网络环境,如何制定高效的云存储网络流调度方法以提高用户的使用体验,已成为云存储系统管理者所面临的巨大挑战。首先,不同类型的业务流对网络性能的要求不同,如何在一个共享的云存储系统中满足不同业务流的服务质量需求是流调度所面临的一个挑战。其次,网络的整体利用率同样重要,如何在提高不同业务流服务质量的同时尽可能地实现网络的负载均衡以提高整体利用率,是设计云存储网络流调度方法所要面对的另一挑战。最后,在云存储网络存在大量多播传输任务的背景下,如何构建流调度的多播树,并最大化降低数据分发时产生的冗余流量,也是制定云存储网络流调度方法所要面临的挑战之一。
因此,迫切需要设计一种云存储网络环境下的多播流调度方法,以实现在降低冗余流量、提高系统负载均衡性能的同时提高不同业务流的服务质量性能。虽然云存储系统采用数据中心网络技术整合存储设备,但现有的数据中心网络流调度方法大多针对流量模式符合长尾分布的数据中心网络环境,即90%的数据流为小流;剩余10%数据流为大流,却占据了90%的网络带宽[4]。在这种数据中心网络环境背景下,部分研究者提出针对所有数据流的通用调度方法[5-7],即不考虑不同业务流之间的差异性,对所有数据流采用通用的调度策略。也有研究者按数据流的大小将其分为“大象流”与“老鼠流”,并分别采用不同的调度机制[8-10]。这些方法虽然在设计的应对场合取得了较好的效果,但难以应对云存储网络环境中针对不同业务的多播流调度需求。
对此,本文在Ceph 云存储网络环境下,给出一种针对多业务场景的多播流调度方法,主要贡献如下。
1)提出Ceph 云存储网络中业务优先级区分的多播流调度优化模型。模型根据不同业务流对网络性能的不同需求以及当前网络的状态信息,为各业务流定制最佳的传输路径。通过最小化全网流量、最小化累积加权时延以及最小化最大链路带宽利用率来提高系统的服务质量性能。
2)提出基于理想解法(TOPSIS,technique for order preference by similarity to ideal solution)与最大公共子路径的多播流调度方法(MFSTM,multicasting flow scheduling method based on TOPSIS and maximum common sub-path),将多播调度任务分解为多个单播调度的多属性决策问题,并结合寻找最大公共子路径的方法,设计求解多播流调度问题。
3)Mininet 搭建模拟Ceph 云存储网络环境,验证MFSTM 的有效性与适用性。模拟平台验证表明,MFSTM 多播流调度方法可以在降低冗余流量、提高网络负载均衡性能的同时,减少高优先级业务流的传输时延。
2 相关工作
在大规模云存储网络环境中,网络流调度技术对云存储网络的性能具有重要影响。它是指对于云存储系统中各项服务产生的数据流,通过调度这些数据流在云存储网络中的传输路径、传输优先级等,来优化网络流量的传输,提高用户的使用体验[11]。在优化传输路径方面,ECMP(equal cost multipath)[12]为所有数据流随机选择一条可达目的节点的传输路径,其目标是充分利用数据中心网络中存在多路径的特点,利用哈希的方式将数据流均衡地分配到各个传输路径之上。Hedera[13]是一种集中控制式的流量调度方法,它将数据流按大小分类,并将大流分配到剩余带宽较多的传输路径上。在优化传输优先级方面,PDQ(preemptive distributed quick)[14]是一种以抢占方式执行最小任务优先的启发式流调度方法,以数据流的剩余时间为传输优先级的评判依据,剩余时间越小的数据流具有越高的传输优先级。pFabric[15]将数据流的剩余量大小作为传输优先级的评判依据,剩余量越小的数据流具有越高的传输优先级。
上述流调度方法大多针对点对点的单播传输环境,然而随着网络业务越来越复杂,一对多的多播发送场景也越来越多。交互式网络电视业务的视频音频分发[16]、云存储系统的多副本复制[17]、传感器监视数据的分发[18]等业务都伴随大量的多播传输需求。现有的多播流调度技术大多结合软件定义网络(SDN,software defined network)技术,通过对网络状态信息的采集以及采用集中控制的思想提高对网络的管理效率。RMMR(robust multipath multicast routing)[19]针对视频流的分发场景,通过使用基于SDN 的多路径多播流调度机制,获得了比传统网际互连协议(IP,internet protocol)多播机制更低的分组丢失率以及更好的网络负载均衡能力。BCMS(multicast scheduling with bounded congestion)[20]是针对胖树拓扑展开讨论的数据中心网络多播流调度方法,它根据多播业务流的网络带宽需求以及当前网络各链路的剩余带宽情况,为每个多播业务流计算最佳的传输路径,以实现网络拥塞控制与负载均衡。MSaSDN[21]针对基于胖树拓扑的数据中心网络,提出了基于最小化链路拥塞开销的多播树构建方法,提高了网络的负载均衡性能。MSaMC[22]针对目前SDN 网络状态测量的滞后性问题,通过结合马尔可夫链,利用当前时隙的拥塞概率来预测下一时隙的拥塞概率,提高了网络的吞吐量并降低了数据流的平均传输时延。DuSM[8]针对数据中心网络的多播流调度问题,将数据流按大小分为“大象流”与“老鼠流”,针对“老鼠流”,将其多播任务转化为多个单播任务,以降低交换机所需的流表数量;针对“大象流”,构建多个共享树,以实现其在多链路上的负载均衡。
上述多播流调度方法大多针对所有数据流给出通用的调度策略,或是仅按数据流的大小进行分类并给出2 种调度机制。然而在云存储网络环境下,出于成本的考虑,一个云存储系统往往由多业务所共享。不同业务产生的数据流对网络性能的要求不尽相同。如在以视频业务为主的网络环境下,网络带宽是需要考虑的重点因素[23]。在以游戏业务为主的网络环境下,时延是用户考量的重点[24]。而在以分布式计算任务为主的网络环境下,不仅需要考虑一对多发送带来的多播传输问题[25],还需要考虑多对一发送所带来的TCP-incast 问题[26]。因此,在云存储网络这种较为复杂的环境下采用单一的调度策略往往难以取得理想的效果。
因此,网络流调度方法需要根据不同业务场景下各业务流对网络性能的不同需求给出定制化的解决方案。本文针对现有网络流调度方法难以处理云存储网络中多业务流的不同多播调度需求问题,以Ceph 云存储系统为代表,结合SDN 中的集中控制思想,给出一种支持业务优先级区分的云存储网络多播流调度方法。
3 云存储网络多播流调度问题的建模
本节首先简单介绍基于SDN 与胖树拓扑的Ceph 云存储系统基本工作机制并分析其流量构成,然后对云存储网络环境下的多播流调度问题进行分析与建模。建模目标是在降低系统冗余流量、提高系统负载均衡性能的同时,减少高优先级业务流的传输时延,从而提高系统的服务质量性能。
3.1 基于SDN 与胖树拓扑的Ceph 云存储系统
对数据流的传输路径进行合理调度需要基于当前的网络状态信息。SDN 作为一种新的网络模式,采用集中控制的思想,将控制平面与数据平面相分离,提高了网络状态测量以及网络管理的灵活性。本文采用前期工作中基于SDN 的网络状态测量方法[27]实时更新并维护系统网络中各链路的状态信息,为流调度工作提供数据支撑。胖树拓扑是当前数据中心网络中最常见的多根树拓扑之一,它为网络内部各源目的节点之间构建多条并行路径,提高了网络内部东西向流量的吞吐量并降低了单点故障与网络热点的出现概率。图1 展示了基于SDN 与4 叉胖树的Ceph 云存储系统,其中pod 表示一组直接互联的汇聚及边缘交换机。

图1 基于SDN 与4 叉胖树的Ceph 云存储系统
本文主要探讨处于多副本工作模式下的Ceph集群,即用户上传一份数据至某个Ceph 节点后,该Ceph 节点会将数据复制并以多播传输的方式分发至其他Ceph 节点进行多副本存储,以提高数据的安全性与可靠性。除了用户执行上传/下载操作产生的业务数据流之外,作为一个大规模的分布式系统,Ceph 集群也包含了心跳数据流和迁移数据流在内的背景业务流。虽然Ceph 的数据迁移一般发生于系统空闲时,但由于数据迁移的时间常长达数小时,因此会出现迁移数据流与业务数据流同时存在的场景。在这种场景下,Ceph 云存储网络中主要包含如下3 种类型的流量。
1)心跳数据流,用于监测Ceph 各节点是否正常工作。其拥有最高的传输优先级,对时延高度敏感,需要的传输带宽较少。
2)用户业务数据流,由用户执行的上传/下载任务产生。其完成时间直接影响用户的使用体验,具有较高的传输优先级,对时延较为敏感,需要的传输带宽较多。
3)系统迁移数据流数据流,由Ceph 系统的负载均衡机制产生。其时延不会影响系统的正常运行以及用户的使用体验,传输优先级最低,但需要的网络带宽较多。
3.2 业务优先级区分的多播流调度问题建模
云存储网络可以表示为G=(V,E),其中,V表示网络中的顶点,对应物理环境中的SDN 交换机;E表示顶点之间的边。e=(εe,δe)表示从顶点εe到顶点δe的链路。第一个目标函数f1为找到使全网流量最小化的多播传输路径。

其中,bϕ表示多播流ϕ所需要的传输带宽;be表示链路e的最大带宽容量;式(2)所示约束条件保证了每个链路e上所分配的数据流的带宽之和不大于链路的带宽容量;xϕe为一个二进制的决策参数,xϕe=0 表示多播流ϕ未经过链路e,xϕe=1 表示多播流ϕ经过了链路e。本文所用的符号及其对应的含义如表1 所示。

表1 符号及其对应的含义
除了最小化全网流量以降低云存储网络的整体负载外,为了进一步提高用户的使用体验,需要最小化累积加权时延,对应目标函数f2为

其中,wϕ表示多播流ϕ对时延的敏感系数,它由业务流的特性决定,对时延越敏感的数据流对应的wϕ值越大;k表示一源到多端的多播传输路径;p表示k中源到某一个端节点的单播传输路径;dϕp表示数据流经路径p的传输时延;约束条件(5)保证了每个多播路径k上所分配的数据流的带宽之和不大于多播路径的瓶颈带宽;约束条件(6)确保了每条多播流ϕ必须选择且只能选择一个多播传输路径;约束条件(7)保证了被选择的多播路径需要满足数据流的最大传输时延限制;xϕk为一个二进制的决策参数,xϕk=0 表示多播流ϕ未经过多播路径k,xϕk=1表示多播流ϕ经过了多播路径k。
在提高各业务流服务质量的同时,整体系统的负载均衡性能同样重要。最小化最大链路带宽使用率的目标函数f3为

其中,约束条件(10)保证了每个链路e上所分配的数据流的带宽之和不大于链路的带宽容量,xϕe为数据流进行链路选择的二进制决策参数。
至此得到了在云存储网络中,针对多业务多播流调度问题的3 个目标函数,分别是最小化全网流量、最小化累积加权时延以及最小化最大链路带宽使用率。由于这3 个目标函数不完全相互独立,无法通过单独处理同时得出各自的最优解,因此整体的优化目标函数Z为
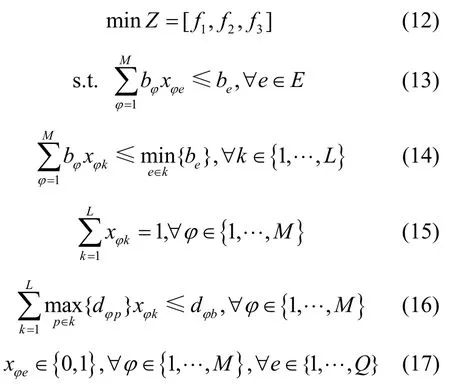

针对上述云存储网络中不同业务流的多播调度问题,本文提出了基于理想解与最大公共子路径的流调度方法。
4 MFSTM 多播流调度方法
Z的3 个子目标函数难以同时取得最小值,即难以同时找到满足3 个子目标的最优解。由于在Ceph 云存储网络中,提高多副本数据多播分发的效率可以有效降低用户业务数据流的规模,进而降低系统负载并提高用户使用体验。因此,MFSTM 将最小化全网流量作为主要优化目标。在找到一组满足最小化全网流量的解集后,MFSTM 再根据剩余的优化目标选择其中的最佳传输路径。具体的求解流程使用基于理想解的多属性决策方法以及最大公共子路径方法来实现。
针对一个多播流的发送请求flowϕ=(τ,T,bϕ,dϕ),其中,τ表示数据流的源节点,T={t1,t2,…,ts}为该多播流的目的节点集合,bϕ、dϕ分别为数据流ϕ传输所需的带宽和最大传输时延阈值。MFSTM 首先使用基于SDN 的网络状态测量技术找出同时满足数据流传输时延以及带宽需求的链路集合;然后针对源节点与目的节点集合中的每个节点分别构建点对点传输路径,基于理想解法找出每个点对点传输的前η个最优传输路径;最后通过寻找各个点对点路径之间的最大公共子路径来确定多播树,多播树的分发节点为最大公共子路径中的最后一个节点。
4.1 网络状态参数的选取及其向量化表示
合适网络状态参数的选取对于理想解这种多属性决策方法的效果起决定性作用。本文针对云存储网络环境下的多播流调度场景,选择传输路径的剩余最大瓶颈带宽、传输路径的平均端到端时延以及核心交换机上的流表数量作为决策参数。这些决策参数表示为

其中,P表示数据流端到端传输路径的集合,每条路径p由多个链路e连接构成。这些路径的集合可以由Dijkstra[28]算法得出,如式(20)所示。

其中,BP表示每条传输路径的剩余最大瓶颈带宽的集合,由于每个路径p由多个链路e连接构成,路径p的剩余最大瓶颈带宽即为构成它的各个链路e中的最小剩余带宽值。这里的链路剩余带宽可以通过基于SDN 的网络状态测量方法[27]得出,如式(21)所示。
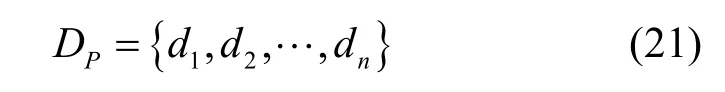
其中,DP表示数据流分别经过每条传输路径的端到端时延集合。这里的端到端时延可以通过基于SDN 的网络状态测量方法[27]得出。
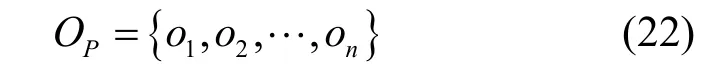
其中,OP表示每条路径所经过的核心交换机中已存在的流表数量的集合。流表数量越多则流表查找时延越高,同时选择通过流表数量较多的核心交换机也会增加数据流冲突的概率。这里的交换机流表数量可以通过SDN 中的OpenFlow 协议获得。
如式(19)~式(22)所示,MFSTM 在程序初始化时即采用Dijkstra 算法计算出任意2 个存储节点之间的传输路径,并存储于专门的数据表中,再使用基于SDN 的网络状态测量方法实时更新这些路径的剩余带宽、平均传输时延等信息。因此,在后续的最优路径计算过程中,可以直接遍历数据表以获得当前的链路状态信息,降低重复路径发现所带来的计算开销。
4.2 基于理想解的最优单播路径计算
MFSTM 在处理一个包含s个目的节点的一对多的多播流请求时,首先将此多播流任务分解为s个点对点的单播任务,并分别使用基于理想解的路径计算方法找到每个单播任务的前η个最优路径。
理想解法是一种有效的多属性决策方案,该方案从归一化的原始数据矩阵中构造出决策问题的正理想解和负理想解。通过计算各方案与正、负理想解的距离作为评价方案的准则。MFSTM 中基于理想解的单播路径计算方法如下。
步骤1基于SDN的网络状态测量与候选路径选取
针对云存储网络G=(V,E),其中,V为网络中的节点,对应物理环境中的 SDN 交换机;E={e1,e2,…,eq}表示节点之间的边。MFSTM 首先利用SDN 对网络链路状态进行周期性的测量,实时维护一张包含所有链路E及其对应链路信息的数据表M=(E,D,B,O),其中,D={de1,de2,…,deq}和B={be1,be2,…,beq}分别对应链路集合E中各子链路的平均传输时延集合与剩余带宽集合,O={o1,o2,…,on}为各核心交换机中当前流表数量的集合。针对一个单播流传输任务flowφ=(τφ,tφ,bφ,dφ),其中,τφ和tφ分别表示单播流φ的源节点与目的节点,bφ和dφ分别表示单播流φ对链路带宽和传输时延的要求。MFSTM 首先根据数据流对传输路径的性能需求来对现有的网络进行过滤,再使用基于Dijkstra 的路径发现算法找到所有的候选路径集P*,如式(23)所示。

并满足P*⊆P,对于∀e∈P*,有be≥bφ且dp≤dφ。
步骤2决策矩阵的构造及其归一化处理
基于上述选取的决策参数,给出决策矩阵M。

其中,矩阵的每一行表示一种决策参数,每一列表示一个候选的端到端传输路径。
为了消除不同决策参数间不同量纲带来的影响,采用极差标准化方法对决策矩阵进行归一化处理。处理方式如式(25)和式(26)所示。
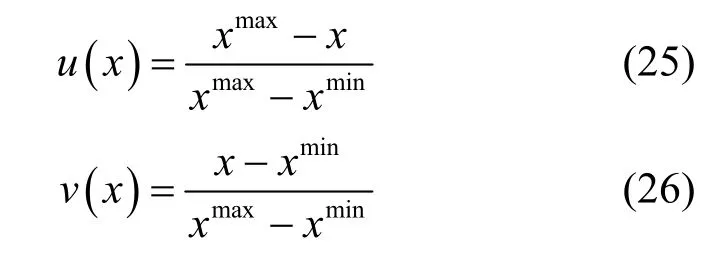
其中,式(25)用于处理成本型决策参数,如链路的传输时延以及交换机中的流表数量,这类决策参数的特点是越小的值对应越好的效果;式(26)用于处理效益型决策参数,如链路的剩余带宽容量,这类参数的特点是越大的值对应越好的效果。
最终,得到经过标准化处理的决策矩阵M*。

步骤3加权决策矩阵的构建及其正负理想解的确定
不同业务的数据流对不同网络参数的敏感程度不同。如在云存储网络中,心跳数据流对传输时延的敏感性较高,但对带宽的敏感性较低;而迁移数据流对时延的敏感性较低,但出于网络负载均衡的考虑,会倾向选择剩余带宽较大的传输路径。为3.1 节介绍的3 种业务数据流分别构建权重系数向量W为

其中,wb、wd、wo分别表示业务流对链路剩余带宽、链路平均端到端时延以及链路中核心交换机上的流表数量的权重系数。各权重系数一般通过实验的方式获取[29],本文设定的权重系数将在实验部分进行介绍。
根据权重系数向量得出不同业务流所对应的加权决策矩阵。以时延敏感流为例,其加权决策矩阵Z的元素Zij为

其中,i∈{1,2,3},j∈{1,2,…,n}。
根据加权决策矩阵得出其正负理想解

其中,P+表示加权决策矩阵的正理想解,由所有候选路径中每种决策参数的最大值构成;P−表示加权决策矩阵的负理想解,由所有候选路径中每种决策参数的最小值构成。
步骤4计算每个候选传输路径到正、负理想解的距离

其中,Zij为候选传输路径[Z1j,Z2j,Z3j]T中的一个元素,分别为各候选路径到其到正负理想解的欧氏距离。
步骤5计算每个候选路径与最优候选路径的相对贴近度为

其中,相对贴近度越大表示该传输路径越适合当前的单播流任务。
4.3 通过最大公共子路径构建多播树
多播传输路径的数据分发节点应尽量靠近接收节点,以最小化系统的冗余流量。针对一个具有s个目的节点的多播流发送请求,MFSTM 根据前述基于理想解的单播流路径计算方法,为每个单播流计算出η个符合其对网络性能需求的最优单播路径,得到{η1}+{η2}+…+{ηs}共η s个单播路径。每个路径p由一组有序的链路e连接构成,其中e=(εe,δe)表示从相邻节点εe到δe的链路。
定义1若路径p满足如下条件,则称p为一组单播流路径{η1}+{η2}+…+{ηs}中的最大公共子路径。
条件1p同时分别为路径集合{η1}、{η2}、{ηs}中某单播路径的子路径。
条件2没有其他符合条件1 的路径p'包含比p更多的链路e。
若ex为从发送节点出发的最大公共子路径p中的最后一个有序链路,则MFSTM 选择ex=(εex,δex)中的节点δex作为多播树中的数据分发节点,并分别根据原单播路径建立从δex出发至各接收节点的多播分发路径,从而完成多播树的构建。若存在多个满足最小化全网流量这一条件的多播树,则从中选择具有最大累计相对贴近度Ctotal的多播树,具体计算如式(35)所示。

其中,s表示多播流的接收节点数量,φ表示发送节点至某一个接收节点的单播任务流,j表示每个单播流φ可以选择的候选路径,表示单播流φ根据式(34)在各候选路径j中可以得到的最大相对贴近度。
最后,通过一个调度实例来进一步说明MFSTM 构建多播路径的基本流程。假设有一个多播任务流{1,(2,3),b,d},表示其发送节点为交换机1,接收节点为交换机2 与交换机3,所需带宽和时延约束分别为b和d。MFSTM 首先将此多播任务分解为2 个单播任务,分别为{1,2,b,d}与{1,3,b,d};其次,利用基于理想解的最优单播路径计算方法分别为2 个单播任务计算满足约束条件的最优单播路径集,这里取每个路径集中包含的路径数量η=2。如图2(a)所示,为单播任务{1,2,b,d}计算得出的最优路径集为{[1,4,7,5,2],[1,4,8,5,2]}。如图2(b)所示,为单播任务{1,3,b,d}计算得出的最优路径集为{[1,4,8,6,3],[1,4,9,6,3]}。最后,找到2 个解集从发送节点出发的最大公共子路径为[1,4,8]。通过将交换机8 作为多播树的分发节点,并按原单播路径建立从交换机8 至各接收节点的多播分发路径,得到如图2(c)中所示的多播路径[1,4,8,(5,6),(2,3)]。

图2 MFSTM 的调度实例
5 实验设置与性能评估
本节对MFSTM 多播流调度方法进行实验设置与性能评估。实验使用Mininet[30]网络模拟器构建实验网络拓扑,并在开源的SDN 控制器RYU[31]上部署 MFSTM 流调度方法的逻辑,最后使用TCPreplay[32]重放真实的Ceph 云存储系统业务数据流[33]以测试流调度方法的性能。整体实验平台搭建于一台曙光A840r-G 服务器上,服务器拥有64 核×2.1 GHz 处理器,64 GB 内存以及600 GB 硬盘。其中,每个处理器核被用于单独处理一个TCPreplay进程,使其能够以恒定速率发送一个长数据流。
在实验拓扑选择方面,由于Ceph 云存储系统中用户业务数据的多个副本常被存储于不同的pod中以提高数据的安全性。因此,图1 所示拓扑可以抽象为图3。实验中利用Mininet 2.3.0 构建图3 中的网络拓扑作为实验系统拓扑,并设定链路带宽为50 Mbit/s。

图3 实验系统拓扑
在数据流选择方面,如前文所述,本文主要探讨多副本工作模式下,Ceph 集群执行数据迁移任务出现用户业务数据时的网络流调度问题。此时,系统中的数据流包括心跳数据流、用户业务数据流以及系统迁移数据流。实验采用本文前期工作中采集的Ceph 云存储集群真实数据流[33],数据流的统计特征如表2 所示。

表2 Ceph 云存储系统中不同业务流的统计特征
表2 中的不同业务流在采集时被分别保存为不同的pcap 文件。在本文的实验过程中,通过使用TCPreplay 重放这些pcap 数据流,以模拟真实的Ceph 云存储系统运行环境,每轮模拟实验的测试时长设定为180 s。对于用户业务数据流以及系统迁移数据流,流量的重放速度与其自身的流速率相同,分别为12.93 Mbit/s 以及4.36 Mbit/s。对于心跳数据流,为了降低模拟实验环境中的分组丢失率,将对它的重放速率设定为1 Mbit/s。同时,受限于模拟实验的测试时长,只重放系统迁移数据流的前40 000 个数据分组,以使其流的持续时间降低至78 s,从而可以在测试时长内完成流的全部发送。
为了进一步测试流调度方法在不同网络负载下的性能,实验设置了3 种流量负载场景。
1)低负载场景:60 条心跳数据流,10 条用户业务数据流,10 条系统迁移数据流。
2)中负载场景:60 条心跳数据流,20 条用户业务数据流,20 条系统迁移数据流。
3)高负载场景:60 条心跳数据流,30 条用户业务数据流,30 条系统迁移数据流。
因为心跳数据流是以恒定周期在不同Ceph 节点之间进行传输的,所以其流数目在测试时长确定时保持不变。在每轮测试过程中,随机选择一个Ceph 节点作为数据的发送节点,并在180 s 内周期性地为每条数据流开启一个TCPreplay 进程以执行数据流的发送。对于心跳数据流和系统迁移数据流,因其点对点的业务特性,TCPreplay 为其随机选择一个剩余Ceph 节点作为数据的接收节点,执行单播发送;对于用户业务流,按常见三副本存储模式下主副本需要向其他2 个从副本进行数据备份的业务场景,TCPreplay 为其随机选择2 个剩余Ceph 节点作为数据的接收节点,执行多播发送。具体的流量调度以及链路选择采用MFSTM多播流调度算法,其中单播流被认为是只有一个接收节点的特殊多播流进行处理。MFSTM 对心跳数据流、用户业务数据流、系统迁移数据流设定的权重系数向量分别为[0,0.5,0.5]、[0.5,0.4,0.1]、[1,0,0]。
实验将本文给出的MFSTM 与ECMP[11]以及BCMS[19]进行对比。其中,ECMP 是数据中心网络中最常见的流调度方法之一,它采用哈希的方式为数据流在多条可达的路径中随机选择一条作为传输路径,以实现负载均衡。当ECMP 处理多播流时,需要将一个多播流分解成多个点对点的单播流分别进行处理。BCMS 是一种有效的针对胖树网络拓扑的多播流调度方法,它根据多播数据流的带宽需求以及当前的网络状态为多播流选择合适的传输路径,以实现网络拥塞控制以及负载均衡。实验的对比项包括总体带宽利用率、不同链路间的带宽利用率标准差、核心交换机上的流表数量以及不同业务流的平均传输时延,每组实验测试5 次,实验结果取平均值。
5.1 链路带宽利用率标准差
图4 给出了在不同负载场景下,实验系统各链路之间带宽利用率的标准差。标准差越小表明各链路之间的带宽利用率越均衡,系统网络的负载均衡性能越好。如图4 所示,3 种方法下的带宽利用率标准差在0~42 s 都呈现快速上升的状态,并在42 s后保持相对稳定。这是由于占用带宽最多的用户业务数据流拥有39.31 s 的流持续时间。在约42 s 处,第一条用户业务数据流完成传输,此后系统网络中的用户业务数据流数目保持恒定,从而使系统的整体负载达到相对稳定的状态。

图4 链路带宽利用率标准差
实验结果表明,在低、中、高3 种负载场景下,使用MFSTM 时带宽利用率标准差的平均值分别比使用ECMP 时降低了30.8%、29.8%以及22.9%,取得了与BCMS 相近的负载均衡效果。这是由于ECMP 在进行路径选择时为所有数据流随机选择路径,若将多条大流分配到同一路径则会造成网络负载的不均衡。而MFSTM 与BCMS 在进行路径选择时会考虑网络当前的状态,为数据流选择剩余带宽较多的路径进行传输。
5.2 总体带宽利用率
系统的总体带宽利用率如式(36)所示。

其中,e表示实验系统拓扑中相邻交换机之间的网络链路,be表示链路e的最大传输带宽,euse表示当前时刻链路e的带宽利用率。图5 给出了在不同负载场景下实验系统的总体带宽利用率。当实验系统处于低、中负载场景下,使用MFSTM 时系统总体带宽利用率的上升速度相比使用ECMP 时更慢,且在所有测量时刻下的总体带宽利用率平均值比使用ECMP 时的总体带宽利用率分别下降了17.8%和12.7%,取得了与BCMS 相近的效果。这是由于MFSTM 与BCMS 为用户业务数据流建立了有效的多播传输路径,节约了网络传输带宽。
然而,在如图5(c)所示的高负载场景下,虽然使用MFSTM 下的系统总体带宽利用率在上升阶段低于ECMP,但在42 s 后的负载相对稳定阶段,使用MFSTM 拥有比使用ECMP 更高的总体带宽利用率。这是由于在高负载场景下,MFSTM 根据链路的剩余带宽对数据流进行了合理的分配,避免了多条大流选择相同传输路径而产生的链路拥塞,提高了系统在高负载场景下的网络吞吐量。MFSTM 与BCMS 拥有相近的总体带宽利用率,因为在实验设计的云存储流量模式下,即多播流的接收节点有2 个且分布在不同的pod 中,MFSTM 与BCMS 同时选择了各核心交换机作为多播路径中的数据分发节点,实现了最大化降低系统冗余流量。
5.3 核心交换机上的流表数量
图6 给出了在完成全部数据流的发送后,实验系统拓扑图中4 台核心交换机上流表数量的标准差。由于实验过程中的数据流都是在不同pod 之间进行传输,因此其传输路径必须通过且只通过一台核心交换机。每当一条数据流被分配到一条传输路径上时,SDN 控制器会向这条路径上的所有交换机下发2 条流表,分别对应数据流的往返传输路径。因此,各核心交换机上的流表数量越均衡,表明数据流在不同传输路径上的调度越均衡。同时,这也避免了多条流表集中于某一台核心交换机,降低了交换机所需的最大流表空间,节约了宝贵的流表资源。

图5 链路带宽利用率标准差
如图6 所示,MFSTM 在所有负载场景下都拥有最小的核心交换机流表数量标准差。这是由于MFSTM 在对高优先级流进行路径选择时,会优先选择具有更小流表数量的核心交换机所在的路径,可以降低数据流在传输过程中的流表查找时延。

图6 核心交换机之间流表数量的标准差

图7 平均传输时延
5.4 平均传输时延
图7 给出了具有不同传输优先级的业务流在不同负载场景下的平均传输时延。对于单播业务流,实验中记录的是其端到端传输时延;对于具有多个接收节点的多播业务流,实验中记录的是发送节点与最后一个收到数据的接收节点之间的端到端传输时延。在如图7(a)所示的低负载场景下,不同方法之间各业务流的平均传输时延没有较为明显的差异。这是由于在低负载场景下,交换机可以有效处理数据流的转发,即使多条数据流被分配到同一传输路径,传输时延也不会有明显的增加。在中负载以及高负载场景下,MFSTM 与BCMS 因较好的网络负载均衡性能,避免了ECMP 下因链路拥塞而导致的传输时延大幅上升。
更重要的是,对于传输优先级较高的心跳数据流与用户业务数据流,MFSTM 具有更小的传输时延。如图7(b)和图7(c)所示,与BCMS 相比,在中、高负载场景下使用MFSTM,可以使具有最高传输优先级的心跳数据流的传输时延分别下降37.9%和9.0%。对于具有次高传输优先级的用户业务数据流,在中、高负载场景下使用MFSTM 可以比使用BCMS 分别降低14.9%和7.5%的平均传输时延。实验结果表明,本文给出的MFSTM 可以降低高优先级流的平均传输时延,从而为系统提供更好的服务质量性能。
6 结束语
针对Ceph 云存储网络环境中不同业务流对网络性能的差异化需求,本文给出了一种基于理想解与最大公共子路径的多播流调度方法,以实现支持业务优先级区分的多播流调度。首先将多播业务流分解为多个单播任务,给出一种基于理想解法的最优单播路径选择方法,为各单播任务寻找符合其对网络性能需求的最优单播路径集;再通过各路径集间的最大公共子路径确定多播树的数据分发节点以构建多播传输路径。实验结果表明,MFSTM可以在降低冗余流量、提高网络负载均衡性能的同时,降低高优先级流的传输时延,提高了系统的服务质量性能。下一步计划在更大规模的云存储网络环境中测试并优化MFSTM 的性能。在基于SDN 的大规模云存储网络环境中,SDN 控制器需要定期向更多的交换机发送探测分组并处理回复以实时维护全网的状态信息。单个SDN 控制器的集中控制和管理将成为瓶颈,需要使用多个SDN控制器进行协同管理,将涉及SDN 多控制器的控制域划分、协同通信以及数据一致性。这些都是需要后续进行的更有意义的研究工作。
猜你喜欢
计算机研究与发展(2022年12期)2022-12-15 13:18:44
计算机工程与应用(2022年5期)2022-04-09 07:03:42
计算机研究与发展(2022年4期)2022-04-06 06:58:32
汽车维修与保养(2020年11期)2020-06-09 05:42:22
电子制作(2019年23期)2019-02-23 13:21:12
测控技术(2018年6期)2018-11-25 09:50:10
电脑与电信(2018年12期)2018-03-23 02:37:36
系统工程与电子技术(2016年7期)2016-08-21 13:59:18
电测与仪表(2016年17期)2016-04-11 12:38:28
西北工业大学学报(2015年3期)2015-12-14 13:08:48
