
基于Hadoop+Hive技术的招聘网站数据分析研究
2020-12-09 06:52叶惠仙
网络安全技术与应用 2020年12期
◆叶惠仙
(福建农业职业技术学院福建3500007)
在大学毕业生数量逐年增加,就业形势较严峻的当下,需建立与市场相协调的人才培养机制,特别是IT岗位人才的市场需求机制。IT行业在未来几年还将产生数百万个新的工作岗位,发展空间极其广阔,选择IT行业的人也越来越多。对于选择哪个专业,今后会有更好的工作和发展前景,是高考学子及应聘人员选择的困惑。建立大数据平台分析人才需求,更深入了解行业招聘的情况,通过对招聘网站用人需求及薪资分析,了解行业招聘的情况,为高考学子及相关业务部拓展市场提供数据参考。
1 研究基础
1.1 Hadoop全分布平台搭建
建设大数据平台是希望通过大数据处理提升网站人才分析功能,更深入了解行业招聘的信息,为相关业务部门拓展市场提供方向,所有的业务分析都基于大数据平台,因此需要熟悉掌握大数据平台的搭建。完成Hadoop全分布部署,Hive组件的安装等,完成数据在Hadoop平台离线清洗,处理并存入到Hive中,实现大数据技术在人才招聘信息数据中的应用。使用 hadoop生态系统方便于管理[1],将一个文件分成多个block存在不同的slaver主机上,避免了因一台主机宕机,而导致文件的丢失。Hive在存储高于百G或T级数据时,写入与读取的速度高于传统数据库。
根据实际应用环境中Hadoop集群,将不同的机器完成网络IP地址的配置,实现集群主机之间网络互通。使用规范集群主机名,使集群方便规范化管理。各个主机安装JDK,实现集群Java环境统一。配置集群机器之间无密码登录,使集群主机软件之间可以进行快速直接的通信。对集群进行安装并配置Hadoop,完成Hadoop集群搭建。分布式集群搭建完成后,根据Hadoop两大核心组成:有效的解决分布式平台下文件分割问题的 HDFS分布文件存储系统与为并行计算提供可能的Map-reduce算法框架。通过监测HDFS和Map-Reduce完成监测工作,通过以上操作完成Hadoop集群搭建。
(1)初始化集群,Hadoop集群节点启动及创建 HDFS文件夹如图1所示。
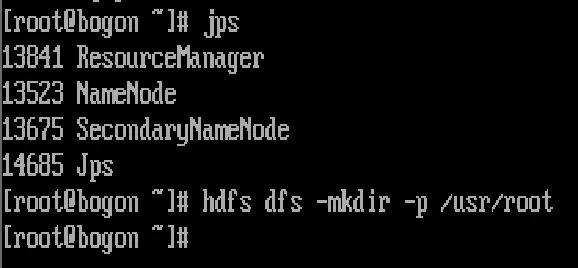
图1 Hadoop集群启动并创建HDFS文件
(2)使用HDFS命令查看文件系统“令查路径下是否存在文件,如图2所示。
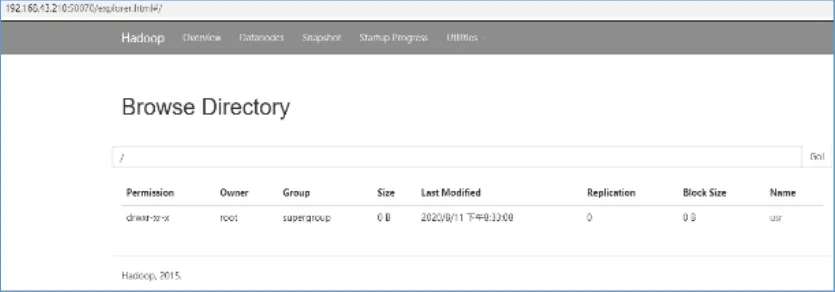
图2 视图方式查看DHFS文件
1.2 Hive技术
Hive是存储在Hadoop中可用于存储,查询和分析数据的仓库工具,可用于大规模数的提取,转换和加载,可以将结构化数据文件映射到表中[1,2]。Hive的执行语句类似于 MySQL并提供类似 MySQL的查询功能,使用HQL作为查询接口,用户提交任务后,编译器获取用户的任务从元数据存储中获取元数据信息,然后编译任务,选择最佳策略,最后返回结果[2]。使用Map-Reduce计算时本质是将HQL转换为Map-Reduce程序,更加体现程序的灵活性和扩展性。Hive适用于离线的数据处理,兼容 UDF自定义存储格式[3]。Hive封装了Hadoop Map-Reduce任务,不再面临单个MR任务,而是单个SQL语句。Hive的会话状态监视反映在每个任务和作业的状态监视中。当Hive接收到命令语句时,首先去元存储获取元数据,然后将元数据信息和执行计划发送到Hadoop集群以执行任务,然后执行引擎将最终结果返回到Hive接口[4]。
1.3 Hive部署操作
Hive默认元数据表是存储derby中,derby是单个session的,所以需要先修改为MySQL,在Hadoop集群中安装MySQL,Hive同样为Hadoop生态下的一个组件,依赖于Hadoop集群运行并操作[4],所以在安装好Hadoop集群之后,完成Hive的安装,通过修改Hive的配置hive-site.xm|文件,配置连接MySQL的信息,将数据库替换成MySQL等关系型数据库,将存储数据独立出来在多个服务实例之间共享。启动Hadoop集群后,使用Hive初始化命令查看初始化控制台信息,如图3所示。
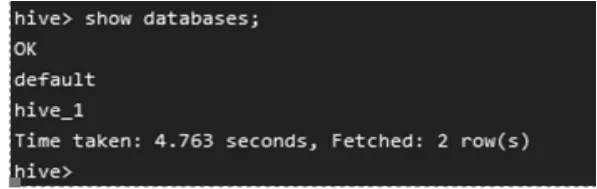
图3 Hive启动
2 招聘大数据特征分析与实现
2.1 数据获取
通过使用python爬虫来获取招聘网站的同一城市不同互联网的岗位薪资[5],同一岗位不同城市的薪资,学历要求等数据。使用base_urls = ,学连接网站地址。
用get_page获取网页代码,用Beautifulsoup解析网页代码结构,并寻找所有的 div及相关属性,并判断相关标签信息,遍历所有的job_all,并用try来检测可能错误代码,并在控制台打印信息。如图4所示获取工作岗位信息。
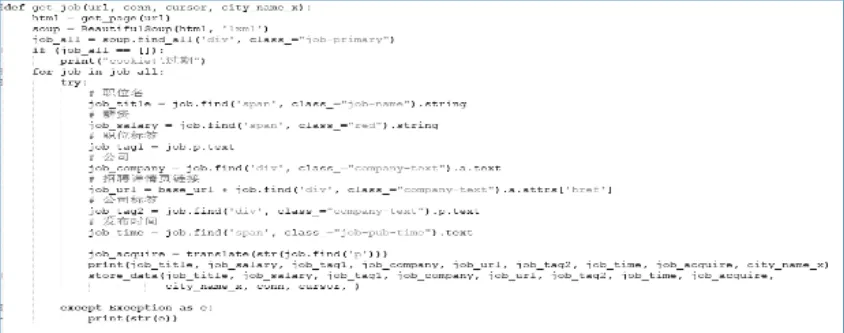
图4 获取工作岗位
2.2 存储数据
将采集数据保存如图5所示。
2.3 数据分析
创建 Hive表,将以上的招聘数据用 secureCRT工具上传到LINUX 平台,并用 hadoop dfs -put < local file > < hdfs file >命令上传到Hadoop平台,在Hive数据仓库中可查询现有的表与数据库,可用show tableses与show databases命令查看,用create table job_data(招聘数据表名)命令建立一个与导入的数据字段顺序一致的招聘信息主表,用show tables查看招聘信息表是否建立成功。
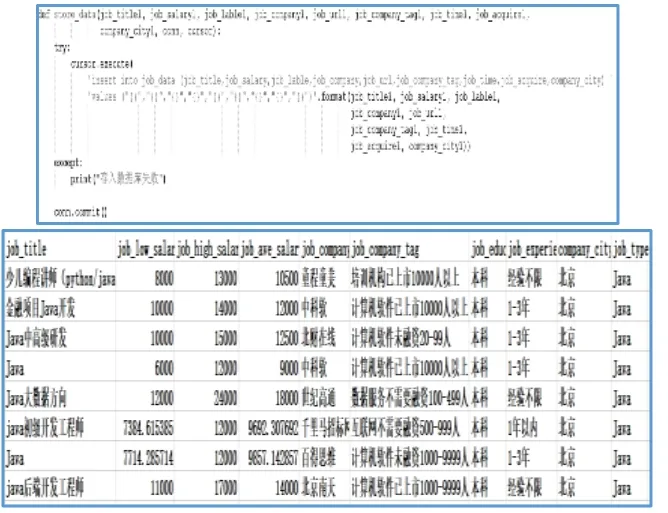
图5 数据存储

图6 用show tables查看招聘信息表是否有建立成功
把前面导入的招聘数据使用load命令导入到Hive 表中,即元数据信息到MySQL,可在任何时候的不同主机上访问Hive表,并把相关文件保存到HDFS上,这样就实现了集群的功能。加载数据到Hive表中操作如下:

导入完成后,可通过 hive查询数据表 job_data_clean_price 中数据在 HDFS 所处的文件位置列表信息。
3 实例可视化分析
3.1 互联网行业发达城市与岗位的平均工资分析
根据hadoop数据平台分析存储于Hive系统的招聘数据可得出,互联网行业发达城市中,北京的高工资平均可达到27000元左右,平均工资可达 22000元,上海、杭州与深圳仅居其次,平均工资可达20000元左右,实现人生梦想的发达城市为北京,上海,广州,通过下图呈现出杭州互联网业的发展迅猛,可多考虑一个实现梦想的工作城市--杭州。从岗位的平均工资分析,互联网热门岗位有 Andrioid,Java,PHP,web前端,IOS,人工智能,数据分析,数据挖掘,算法工程师等,从图6中可以得出,当下对于数据架构师岗位薪资最高,可达到近4万,人工智能是目前发展的最热门的岗位,平均薪资26000左右,基础岗位如Java、PHP等传统岗位平均薪资在10000元左右。
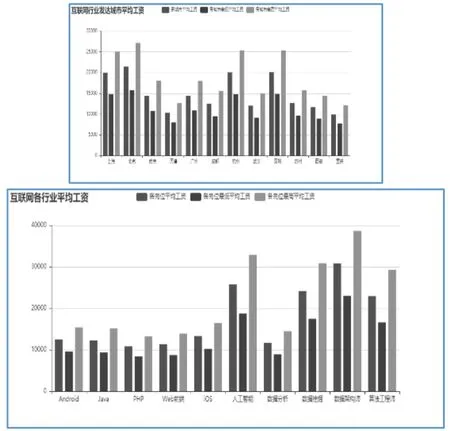
图7 发达城市与岗位的平均工资
3.2 大公司工资待遇与学历分析
通过数据的处理,图形化展示出的招聘的企业来看,大企业如华为、京东、阿里等都是互联网行业从业人员理想的工作单位,平均薪资可达到2万元左右,从数据可以看出,蚂蚁金服,字节跳动、腾讯等都是属于高薪企业,平均高薪资可达4-5万。从学历分析目前招聘岗位对博士的要求占0.74%,对于本科的要求占65.7%,要求大专以上占比为18.88%。如图8所示。
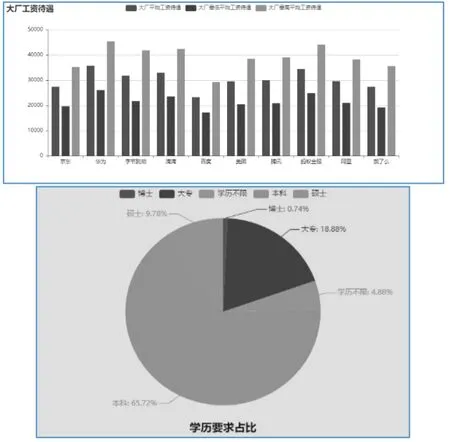
图8 企业平均薪资与学历占比
4 结论
基于大数据分布式并行计算技术,采用hadoop+Hive技术实现了招聘网站数据的采集,分析处理,存储及可视化。根据岗位及城市IT需求数据分析得出:发达城市中IT行业平均工资较高的为北京;互联网各行业的平均工资较高的为数据架构师,其次为人工智能;学历要求上本科要求点 65.72%。学历上博士薪资可达到大专的平均薪资的5-6倍。由此可得出,高校人才培养方案中人工智能,数据分析,数据挖掘,算法工程师这些岗位有更好的就业前景及薪资,明确了IT岗位薪资及各大主要城市发展需求。
猜你喜欢
销售与市场(营销版)(2022年6期)2022-11-13
当代陕西(2022年6期)2022-04-19
疯狂英语·新悦读(2020年1期)2020-02-20
新作文·高中版(2017年5期)2017-06-10
东西南北(2015年9期)2015-09-10
环球时报(2009-04-27)2009-04-27
