
基于百度指数的传染病预测精准性探索
——以广东省H7N9亚型禽流感为例
2020-12-08 02:21:46黄泽颖
中国人兽共患病学报 2020年11期
黄泽颖
新世纪以来,我国不仅面临传统传染病的持续威胁,而且SARS、H7N9亚型禽流感、MERS、新冠肺炎等新型传染病的连续出现,使我们不断反思传染病预测的精准性。同一传染病在不同地区表现不同特征,若不划分区域展开研究,可能削弱预测能力[1]。H7N9亚型禽流感严重危害居民的生命健康,引发全球的广泛关注[2]。广东省是人感染H7N9亚型禽流感的高发省份,2013年8月份至 2018年2月份,共发生病例数264起(占全国18.84%)[3]。不同的是,广东省的H7N9亚型禽流感与本地H9N2禽流感重配组合,传染能力更强,具有典型区域性[4-5]。虽然H7N9亚型禽流感在广东省得到有效控制,但尚未净化和消灭,其潜在的威胁不可忽视,故有必要加强精确预测,提高防控决策的科学性。
大数据的“数据密集型科学”研究范式极大提高了科学发现概率[6],也为传染病预测提供了一种新的技术和手段[7]。随着互联网技术的迅速发展,来自雅虎、谷歌、百度等知名互联网公司的搜索引擎网络大数据越来越多地应用到传染病发展趋势的预测,例如,Polgreen PM等[8]分析雅虎搜索引擎上的流感搜索次数与实际流感发生之间的关系,预测美国的流感发展趋势。 Ginsberg J等[9]通过监测谷歌搜索引擎上与疾病相关信息的搜索行为预测美国季节性流感动态。Yuan Q等[10]使用百度指数预测我国流感走势。王晶晶等[11]基于百度指数预测以广东省为中心的全国登革热疫情。Li Z等[12]结合百度指数、气象和人口因素开发了广州市登革热预测模型。Bu Y等[13]利用百度指数预测我国流感情况。Zhao Y等[14]结合百度指数构建时间序列元特征的预测模型,对全国及典型地区的手足口病发病率进行即时预报。白宁等[15]基于百度指数分波段预测福建省的H7N9亚型禽流感疫情。梳理文献可知,包括百度指数在内的搜索引擎网络大数据与传染病的流行病学有紧密的联系,有充分的证据预测疫情的发生或流行。然而,就如何进一步提高搜索引擎网络大数据预测的精准度方面,大多数研究一方面忽视了公众搜索行为随疫情发展变化的特征,不分疫情波段进行预测研究,另一方面忽视了疫情期间公众通过搜索引擎查询身体不适的原因和治疗方法,未将公众对传染病临床症状相关关键词的搜索频率考虑在内。
《中国互联网络发展状况统计报告》指出,截至2020年3月份,我国网民规模达9.04亿,其中,搜索引擎是搜索信息的主要渠道,用户占总网民的83.0%[16]。百度是全球最大的中文搜索引擎,其推出的百度指数,以网民在百度的搜索量为数据基础,以关键词为统计对象,科学分析并计算出各个关键词在百度网页搜索中搜索频次的加权和,客观地反映网民的主动搜索需求和网民对网络信息的关注程度。因此,本文以提高广东省H7N9亚型禽流感疫情的预测准确度为研究重点,利用回顾性流行病学调查方法,基于“H7N9”关键词百度指数,首先根据疫情整体趋势划分波段预测疫情,然后从中选择预测效果较佳的波段,结合临床症状关键词的百度指数开展预测研究,希冀通过这些方法与理论能更好地支撑H7N9亚型禽流感疫情防控,也为流行病学分析提供参考价值。
1 材料与方法
1.1数据来源 本文使用的数据主要是广东省H7N9亚型禽流感病例数和相关关键词的百度指数:一是根据广东省卫健委的疫情信息[3],整理2013年1月份到2018年12月份的广东省H7N9亚型禽流感月度与周度新增病例数;二是在百度指数平台(http://index.baidu.com),以“PC端+移动端”指数(基于我国居民越来越多使用电脑和智能手机进行信息搜索的趋势)作为搜索指数来源,地区范围设定在广东省,一方面,为提高查全率,以“H7N9”为关键词采集2013年1月份到2018年12月份广东省每月与每周的“H7N9”百度指数,另一方面,根据H7N9禽流感的定义,结合H7N9亚型禽流感高频被引国内外文献[17-19],基于百度指数平台对关键词的收录权限,选取了“发热”“咳嗽”“咳痰”“肌肉酸痛”“呼吸困难”“乏力”“头痛”“咽痛”“胸闷”“气喘”“胸痛”“流涕”12个与H7N9亚型禽流感临床症状密切相关且特异性的关键词。鉴于每年普通流感的流行高峰与H7N9禽流感的流行高峰在时间上有很大重合性,且人感染H7N9禽流感的临床表现也跟一般的普通流感比较相似,但显著的区别在于潜伏期,即流感的潜伏期相对较短,通常1~3 d。而H7N9潜伏期平均是7 d,短的是2~3 d,长的是10~14 d。因此,在利用临床症状关键词的百度指数预测环节中,将预测时间间隔拟定为周,搜集临床症状关键词在2013年1月份到2018年12月份广东省每周的百度指数。
1.2研究方法 本文运用R统计软件,基于广东省H7N9亚型禽流感病例数和百度指数,采用支持向量机回归和多元线性回归对疫情趋势进行预测。
1.2.1支持向量机回归预测 支持向量机回归(support vector machine regression, SVMR)是以支持向量机作为数据挖掘方法处理时间序列分析问题,其拟合优度并非通过常规的二次损失函数(均方差)测量,而是通过非灵敏损失函数(ILF)测度[20]。本文以每个疫情波段中H7N9亚型禽流感每月新增病例数为因变量,以相应的H7N9月度百度指数为自变量,采用径向基(RBF)核函数,利用交叉验证方法寻找最佳的惩罚因子和RBF核函数的方差,然后分波段建立支持向量机回归模型,对每个波段的疫情前半段进行模型训练和对后半段进行模型预测,考察是否可以预测到实际病例数的变化趋势与峰值出现的时间,最后以均方误差小和决定系数大作为预测效果良好的评判标准,选取预测效果较好的疫情波段。
1.2.2多元线性回归预测 基于支持向量回归预测效果较好的疫情波段,以这段疫情波段的每周新增病例数为因变量,以12个H7N9亚型禽流感临床症状关键词的百度指数为自变量建立多元线性回归模型。第1步,采用皮尔森相关系数(PCC)和斯皮尔曼相关系数(SCC)判断12个关键词与实际每周H7N9亚型禽流感病例数的关系。第2步, 评估模型的预测效果:采用留一法交叉验证法LOOCV(leave-ont-out cross validation),选取上述支持向量回归预测效果较好的疫情波段,假设有n个周的数据,将每周的数据作为测试集,其余n-1个周的数据作为训练集,重复方法使每个周度数据都被作为一次测试集,然后使用逐步回归法去除回归效果不够显著的自变量,建立最优的预测模型,以预测值与实际值的皮尔森相关系数(PCC)评估预测模型实际应用中的准确度。第3步,开展疫情预测:采用反向测试(retrospective test)方法,假设数据集共M条周度数据,用后N条周度数据作测试集,以测试其中的第n条周度数据为例,将前(M-N+n-1)条周度数据作为训练集构建模型,为排除普通流感流行(潜伏期1~3 d)的混杂影响,文章鉴于人感染H7N9禽流感的临床表现一般存在7 d潜伏期,参考一些专家的方法[21],将预测周的前一周H7N9实际新增病例数据作为自变量加入到模型中,预测第n条的周度数值,重复方法N次,也就是说,利用上述支持向量回归预测效果较好的疫情波段作为训练集,预测下一个疫情波段的病例数,并以下一个疫情波段的实际病例数作为验证集进行比较,最后利用预测值和实际值之间的皮尔森相关系数(PCC)检验反向测试的效果以及采用预测值与实际值的平均绝对误差(MAE)判断模型的预测准确度。
2 结 果
2.1广东省H7N9亚型禽流感疫情波段划分与分析 由图1可知,广东省2013年8月份至2018年2月份的月度H7N9亚型禽流感确诊病例数与百度指数的变化趋势具有很高的相似性,总体上,月新增病例数越多其百度指数越高,而且呈现4个波段,波段周期长短相符,大体可划分为:第1波段(2013年7月份至2014年7月份)、第2波段(2014年10月份至2015年4月份)、第3波段(2015年10月份至2016年6月份)、第4波段(2016年11月份至2017年5月份);此外,与病例数变化趋势相比,4波疫情中的居民搜索关键词“H7N9”的行为呈提前现象(提前时间1个月),如广东省首个病例发生于2013年8月份,比居民首次搜索关键词“H7N9”的行为仅晚了1个月;在2013-2018年期间,广东省发生病例数最多(44起)的月份是2014年2月份,而百度指数最高(11 719)的月份是2014年1月份。
由图2可知,在每波疫情中,H7N9亚型禽流感总病例数与关键词“H7N9”总的百度指数有一定的相关关系。除了第2波疫情外,第1波、第3波、第4波疫情中的百度指数与病例总数近似同步。
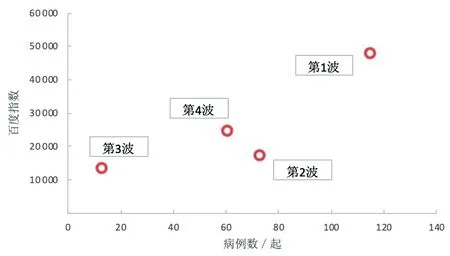
图2 每波疫情总病例数与关键词“H7N9”百度指数的关系图Fig.2 Relationship between the total number of cases in each wave and the keyword "H7N9" in the Baidu index
2.2分波段支持向量机回归预测 在H7N9亚型禽流感疫情的不同波段,居民对于关键词“H7N9”的搜索行为不同,故根据疫情波段选择训练集与预测集开展支持向量机回归预测,见图3~7。
由图3可知,广东省的每波疫情中,2月份是H7N9亚型禽流感的高发月份,以此为界,选择疫情中10月份到次年1月份的病例发生数作为训练集,2月份到9月份作为预测集。

图3 2013年8月份至2018年12月份各波疫情每月H7N9亚型禽流感病例数Fig.3 Number of H7N9 subtype avian influenza cases in each wave from August 2013 to December 2018
第1~3波疫情中(见图1),百度指数峰值出现的时间比病例数峰值提前1个月,故利用第t-1个月的关键词“H7N9”百度指数预测第t个月的H7N9禽流感病例数;在第4波疫情中,百度指数峰值出现时间比病例数峰值滞后1个月,因此利用第t+1个月关键词“H7N9”的百度指数预测第t个月H7N9亚型禽流感病例数。

图1 2013-2018年各月H7N9亚型禽流感病例数与关键词“H7N9”百度指数的变化趋势Fig.1 Change trend in the number of H7N9 subtype avian influenza cases in each month and the keyword "H7N9" in the Baidu index from 2013 to 2018
由图4可知,广东省第1波疫情中预测集是2014年2月份至2014年7月份,除了2014年4月份和7月份外,2014年2月份、3月份、5月份和6月份的预测值均低于同期的真实值。
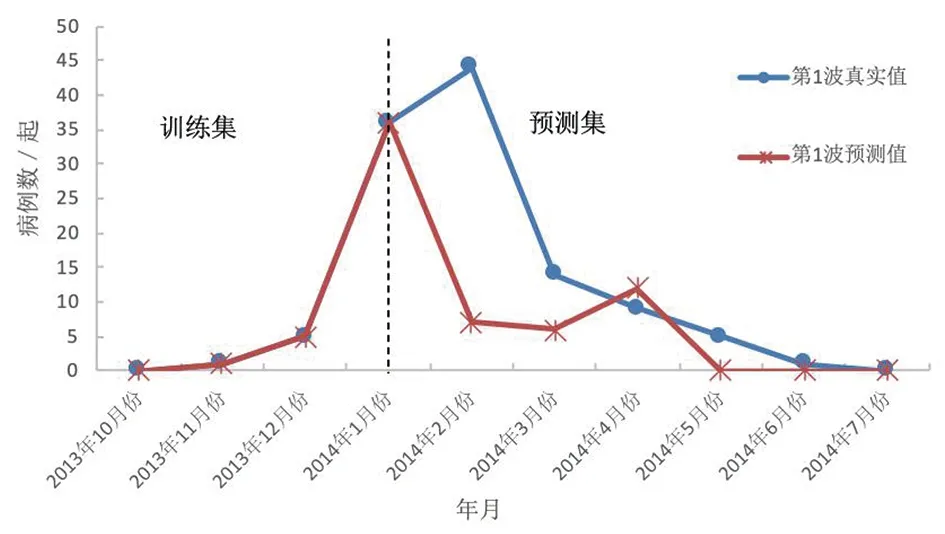
图4 第1波疫情中预测集的真实值和预测结果的对比Fig.4 Comparison of the true values of the predicted sets and the predicted results in the first wave epidemic
由图5可知,广东省第2波疫情中预测集是从2015年2月份到2015年4月份,其中2015年2月份的预测值低于同期的真实值,而3月份的预测值高于同期的真实值。
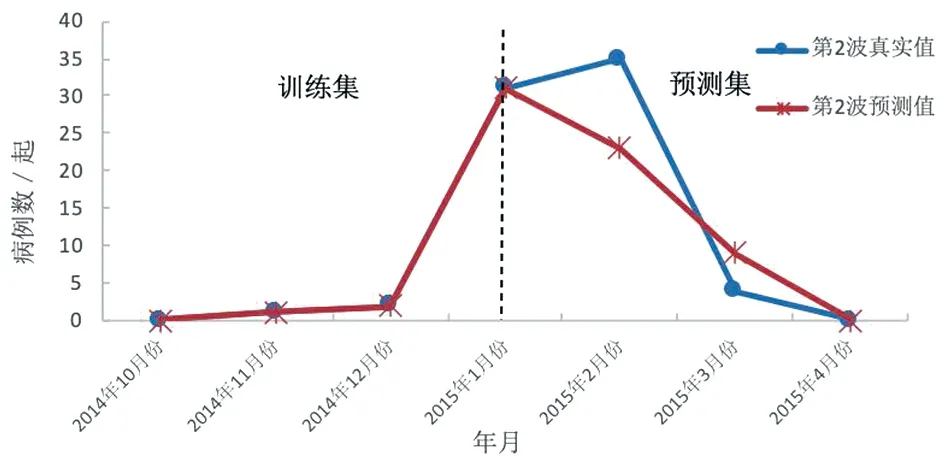
图5 第2波疫情中预测集的真实值和预测结果的对比Fig.5 Comparison of the true values of the predicted sets and the predicted results in the second wave epidemic
由图6可知,第3波疫情中预测集是从2016年2月份到2016年6月份,其中5月份的预测值与真实值一致,但2016年2月份、3月份的预测值低于同期的真实值,而4月份、6月份的预测值高于同期的真实值。
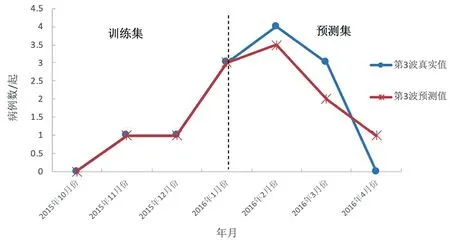
图6 第3波疫情中预测集的真实值和预测结果的对比Fig.6 Comparison of the true values of the predicted sets and the predicted results in the third wave epidemic
由图7可知,广东省第4波疫情中的预测集是从2017年2月份到2017年5月份,这些月份的预测值均高于同期的真实值。

图7 第4波疫情中预测集的真实值和预测结果的对比Fig.7 Comparison of the true values of the predicted sets and the predicted results in the fourth wave epidemic
通过计算图4到图7每波疫情的均方误差和决定系数发现,第1波、第2波、第3波、第4波疫情预测集的均方误差分别为21.68、8.63、11.21、30.97,决定系数分别为0.78、0.91、0.90、0.76,第2、3波疫情的预测值能较好地描述真实病例数的变化趋势。
2.3多元线性回归预测 由表1可知,12个关键词的百度指数与实际每周H7N9亚型禽流感病例数的皮尔森相关系数和斯皮尔曼相关系数有明显的正相关,与实际疫情有较强相关性的关键词是 “肌肉酸痛”(PCC=0.381,SCC=0.472)、“头痛”(PCC=0.326,SCC=0.281)、“发热”(PCC=0.261,SCC=0.377)。由此可知,12个关键词的百度指数可用来预测H7N9亚型禽流感疫情的动态变化。
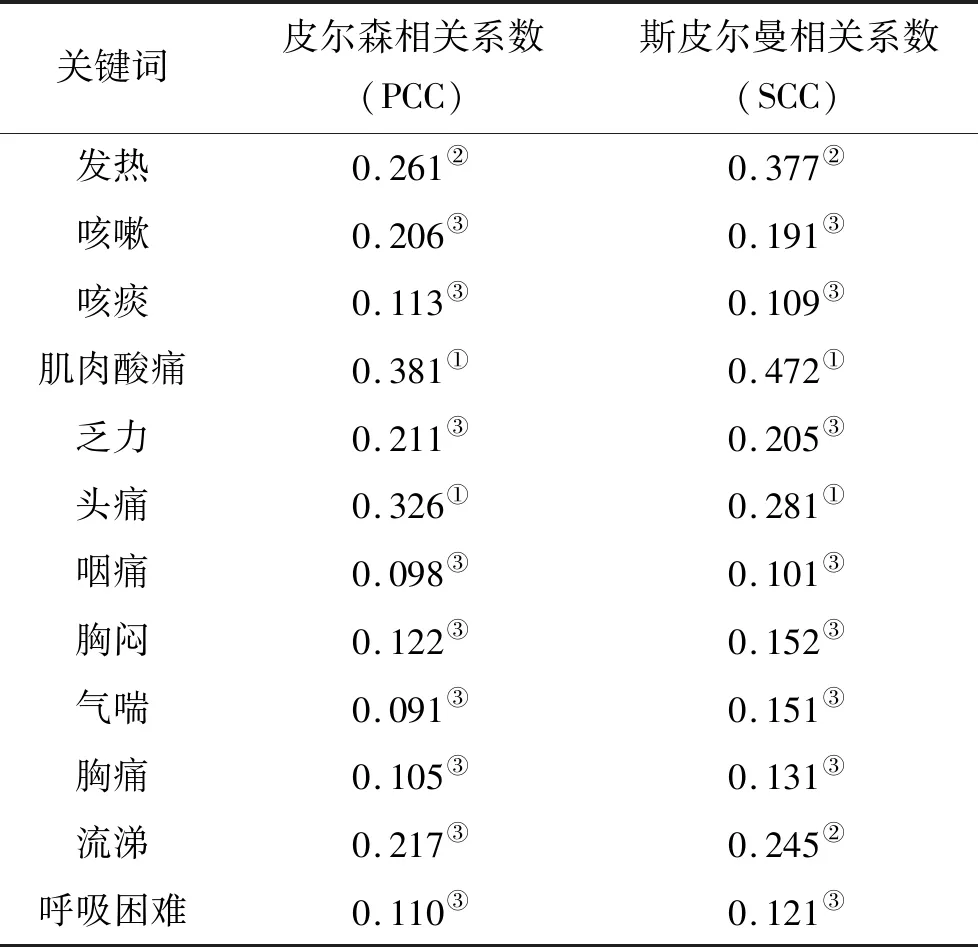
表1 各关键词的百度指数与实际病例数的相关性系数Tab.1 Correlation coefficients between each keyword in the Baidu index and the actual number of cases
以广东省2014年10月份到2016年6月份每周新增H7N9亚型禽流感病例数作为因变量,以上述12个关键词的百度指数作为自变量建立多元线性回归模型,依次选取2014年10月份到2016年6月份中的一个周的数据为测试集,其余的数据为训练集,通过逐步回归方法,结合AIC信息准则数值最小化作为选择模型拟合数据较优的标准,最终形成自变量为“肌肉酸痛”、“发热”、“头痛”、“流涕”、“乏力”的预测模型。通过留一法交叉验证(LOOCV)评估发现,预测值与实际值之间的PCC为0.805(P<0.01),这说明,模型在测试数据上的效果较好。
采用反向测试方法,以76周(2014年10月份到2016年6月份,共19个月,累计76周)的数据作为训练集,预测第4波段(2016年11月份到2017年5月份,共7个月,累计28周)的疫情走势,以28个预测周的前1周H7N9病例新增数据(即2016年10月25-31日)作为自变量加入到模型中,消除普通流感的混杂影响,并以第4波段的实际病例数作为验证集。为了便于比较,将多元线性回归模型得出的周度预测值转换为预测值,研究结果见表2,第4波段疫情的预测值与实际值比较接近,两者之前的PCC为0.885(P<0.01),相关性强,预测值与实际值的平均绝对误差(MAE)为2.83,预测的准确度较高,很好地捕捉到真实病例数峰值出现的时间。在2017年2月份到2017年5月份这段时间内,支持向量机回归的预测值与实际值之间的PCC值为0.791(P<0.01),MAE=10,而多元线性回归的预测值与实际值之间的PCC值为0.987(P<0.01),相关性更明显,MAE=2.25,相比之下,多元线性回归的预测效果更优。
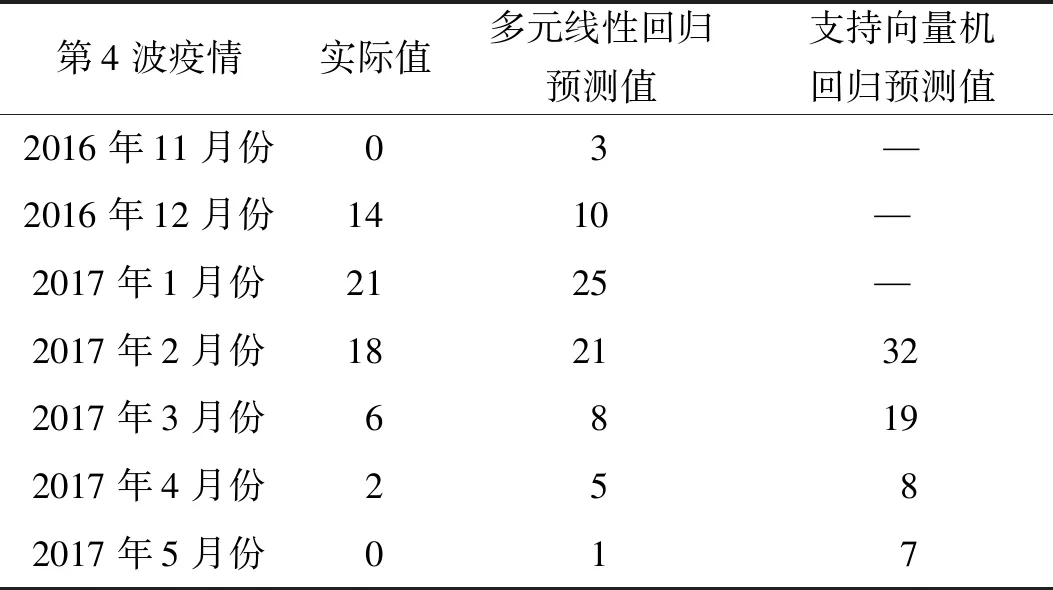
表2 第4波段疫情的病例数预测值与实际值Tab.2 Predicted values and the actual number of cases in the fourth wave of the epidemic
3 讨 论
为了更好地预测广东省H7N9亚型禽流感疫情的动态变化,本文基于2013-2018年广东省的“H7N9”与12个H7N9亚型禽流感临床症状等关键词的百度指数,结合2013年到2018年的广东省H7N9亚型禽流感月度新增病例数,划分了4个疫情波段,首先,通过支持向量机回归预测筛选第2、3波段的疫情时间(2014年10月份到2016年6月份),然后,在这个疫情的周度时间范围内,12个H7N9亚型禽流感临床症状的关键词与实际病例数有明显的正相关,结合临床症状关键词建立多元线性回归模型对第4波段疫情预测发现,预测值能更好地拟合实际疫情动态趋势,比支持向量机回归的预测精度更高。
“有事问百度”已成为我国居民利用其检索服务功能关注新型传染病以及查询和获取健康信息的重要渠道,随着网民的逐年增加和5G时代的到来,搜索引擎的使用率会愈加频繁,基于百度指数预测传染病的发生率具有良好的应用前景。本文以广东省H7N9亚型禽流感疫情为例,创新性地从分疫情波段和临床症状关键词两个方面试图改进现有研究的预测性能,得到的结论具有流行病学意义,进一步肯定了搜索引擎网络大数据预测传染病的可行性。
然而,本文预测的结果与实际疫情发生尚不完全吻合,预测模型及参数方面仍存在不尽人意的地方。尽管百度公司对百度指数进行不懈的完善,使之更接近实际,但传染病预测模型的建立,还有不少影响精准度的噪音:一是指数本身受制于搜索者的知识层面、所在地区的限制,对于预测结果存在一定的干扰,例如,非广东省地区发生了疑似疫情,可能导致广东省对H7N9亚型禽流感搜索量的上升;二是疫情态势已发生变化,当前我国人感染H7N9禽流感呈散发态势,大规模与集中暴发的可能性较低,如果以集中暴发期的新增案例预测,则与实际相差甚远。因此,利用好搜索引擎网络大数据开展精准预测除了要进一步了解公众的搜索习惯,揣测搜索动机,还应根据气候、环境、社会、经济、防控政策等新变化对构建的模型进行年度调整。
利益冲突:无
猜你喜欢
ELLE世界时装之苑(2024年5期)2024-05-14 09:45:39
启蒙(3-7岁)(2017年4期)2017-06-15 20:28:55
高师理科学刊(2016年8期)2016-06-15 20:27:45
中国病理生理杂志(2015年8期)2015-12-21 12:38:10
西藏科技(2015年4期)2015-09-26 12:12:58
中国当代医药(2015年30期)2015-03-01 02:08:19
癌变·畸变·突变(2014年2期)2014-03-01 04:39:41
河南科技(2014年18期)2014-02-27 14:14:53
当代畜禽养殖业(2014年7期)2014-02-27 07:59:17
当代畜禽养殖业(2014年6期)2014-02-27 07:59:07
