
基于改进的用户协同过滤算法的高校个性化图书推荐系统*
2020-12-07 05:26:12刘佳奇王全民
计算机与数字工程 2020年10期
刘佳奇 王全民
(北京工业大学计算机学院 北京 100124)
1 引言
当今时代信息过载严重,人们从海量信息中获取自己感兴趣的信息的难度越来越高,因此推荐系统作为解决这个问题的有效手段得到了广泛的应用。目前主流的推荐系统所采用的技术包括协同过滤、基于内容、关联规则和混合的推荐[1]。其中协同过滤推荐算法是由Goldberg[2]等人在文献中提出。基于协同过滤的算法主要包括基于用户的协同过滤和基于物品的协同过滤算法。
传统的基于用户的协同过滤算法的思路大概可以分为两步:1)找到和目标用户兴趣相似的用户集合。2)找到这个集合中的用户喜欢的,且目标用户没有听说过的物品推荐给目标用户。以上基于用户的协同过滤算法设计的方式在实际的应用中会存在一些问题。比如计算用户的相似度时需要有用户的历史行为数据,没有历史行为的用户则无法进行推荐,这就造成了推荐的冷启动问题。用户的兴趣随着时间的推移会出现衰减的现象[3],而传统的协同过滤算法无法捕捉到用户兴趣的时间维度的信息,从而造成无差别的用户兴趣推荐结果。由于热门的图书会被很多人借阅,所以传统的协同过滤算法的推荐结果中会有较多占比的热门商品,但是用户对于热门商品的熟悉程度往往会很高,推荐系统的目的主要是为用户推荐其不熟知的商品,所以热度商品的打压也是传统的协同过滤算法需要解决的问题[7]。
针对以上基于用户的协同过滤算法存在的问题,论文针对高校图书借阅的使用场景和高校产出的日常数据对以上问题作出改进。分别通过多维度数据的加权来定义相似用户,基于时间衰减的用户行为模型和热门图书的打压策略对协同过滤存在的问题进行改进。
2 相关工作
2.1 时间衰减的用户形似度计算模型
协同过滤算法(User-cf)首先需要根据用户的历史借阅信息来为用户计算与其相似度最高的用户,然后再为用户推荐其相似用户借阅过而他没有借阅过的图书。
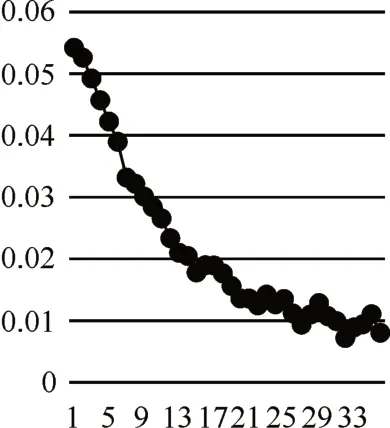
图1 兴趣随时间衰减统计图
首先,我们需要计算用户对其历史借阅图书的评分,生成基于历史行为的用户-图书的评分矩阵。论文使用用户对图书的累积借阅时长来表示用户对图书的兴趣值。但是用户的兴趣会随着时间的推移而发生变化,用户近期的借阅兴趣应该被赋予更高的权重,因此论文在计算用户对图书的评分引入了时间衰减因素。
上图是统计的用户兴趣衰减模型,本文使用了用户近一个月的借阅记录作为准确率的测试集,在最近一个月内用户借阅过该图书则判定为正样本。其中,横坐标代表用户还书日期节点距离当前时间节点的周数,纵坐标是基于不同时间节点用户的借阅图书记录通过User-cf算法计算的用户可能感兴趣图书的top20的推荐准确率。论文使用了贝叶斯平滑对计算的准确率结果做了平滑处理。从上图可以看出,随着借阅日期距离当前时间节点的增加,用户的兴趣呈衰减的趋势,结合到图书借阅场景的意义是用户距离当前时间越接近的借阅行为越能代表用户近期的兴趣。从图像可以看出,使用指数函数可以对用户兴趣随时间的衰减曲线进行较好的表示,所以本文使用了指数函数去拟合时间衰减系数。论文基于兴趣衰减的计算公式为
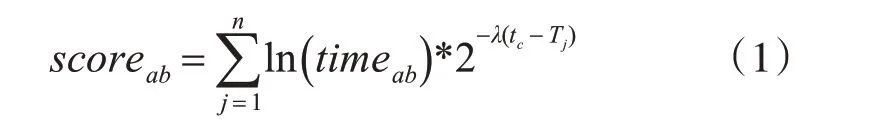
其中,scoreab代表用户a对图书b 的评分,timeab代表用户a对图书b在第j 天的借阅时长,j 取的是还书日期。是时间衰减因子,它会随着用户借阅图书的日期距离当前时间节点的增加而减小,tc和Tj分别代表当前时间和借阅的时间。n 代表用户a对图书b 的借阅次数。然后对评分做归一化处理即为最终评分。
通过以上方法计算得用户-图书的兴趣矩阵后,计算用户之间的两两相似性,论文选用余弦相似度计算方法来计算用户间相似性,余弦相似度更加注重两个向量在方向上的差异,所以更加适合当前问题的场景,计算公式为
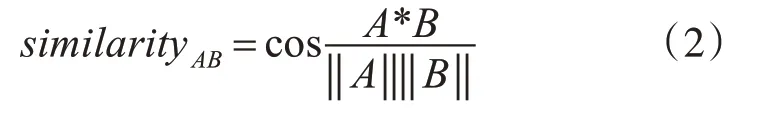
获得用户间相似度后每个用户取与自己相似度最高的top50 用户,获取这部分用户借阅的图书中被推荐用户没有借阅过的图书,按照如下公式计算用户对图书的打分:
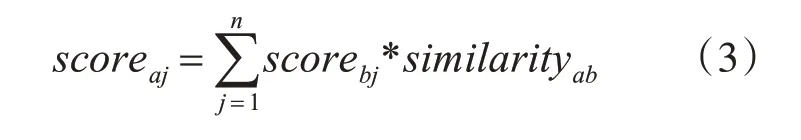
其中scoreaj代表被推荐用户a对图书j 的评分,scorebj代表与被推荐用户相似度最高的top50用户b对图书j 的评分,similarityab是用户a 与用户b 的相似度。
可以看出,论文从用户行为的时间的维度上对用户的兴趣做了重新的判定,从而捕捉到用户近期真正的兴趣,因此本文将改进User-CF 命名为UT-CF。
2.2 基于多源数据的用户相似度计算
2.2.1 基于网络日志的用户聚类
基于用户的协同过滤算法需要被推荐的用户有一定数量的历史借阅记录,通过数据分析发现大多数的用户借阅的图书非常少或者没有历史借阅记录。这样就带来了用户的冷启动问题。论文解决这个问题的方式是试图通过从用户其他的行为数据中的提取用户的兴趣来指导用户的图书推荐。
用户日常产出的能代表用户兴趣的行为数据我们自然能想到用户的上网日志。目前对于用户网络日志(url)的聚类算法已有较多成熟的模型,论文借鉴现有的思路[10],首先对用户的url 记录做分词处理,通过统计词频的方式生成用户上网日志的向量,在用k-means 算法将url 向量进行聚类。我们假定聚类到同一个类簇的用户具有相似的兴趣,因此将聚类到同一类簇的用户进行形似度加权得到用户覆盖度更高,精度更准确的用户间相似性,加权公式如下:
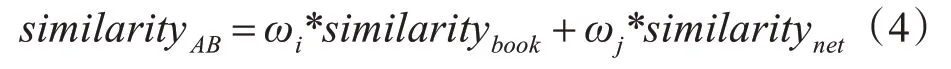
其中similaritybook和similaritynet分别代表通过用户图书的借阅信息和上网日志得出的用户间相似度,ωi和ωj是超参数,用于控制相似度融合的权重。
2.2.2 基于学院信息的用户聚类
网络日志的聚类可以提升用户的覆盖率,同时可以提升用户相似性判定的准确性。但是实验结果发现这种方式没有达到理想的效果,主要的问题表现在通过用户网络日志的聚类的兴趣不能跟用户的图书借阅兴趣很好的匹配。
论文针对以上问题,结合高校用户借阅图书的特点,发现了高校用户借阅图书的一个特点。高校的用户借阅的图书大多是本专业的图书,结合这一特点,论文假定同一专业的用户有相似的图书借阅兴趣。同时结合学校的学部信息将用户的相似性进行更详细的划分,划分的思路是同一学院的用户相比同一学部的用户拥有更高的相似性,基于这种思路可以得到根据用户的学院信息得到的用户间相似性similarityacademy。最终的用户间相似度计算公式如下:

通过以上的方式,我们得到了可以满足100%用户覆盖率的准确性较高的用户间相似度计算方式,这里融合的规则与上一节中上网日志与图书借阅行为融合的方式相同。
2.3 热门图书打压策略
由于热门图书是多数用户都会借阅的图书,所以基于用户的协同过滤算法为用户推荐的图书中会有较大占比的热门图书。这部分的图书在用户群体中的熟知度往往较高,即使没有为用户推荐用户大概率也会知道该图书,所以为用户推荐热门图书不仅会浪费推荐资源而且会造成用户体验感的下降。
论文通过从图书推荐候选集中将借阅频次最高的5%的图书去除,以达到避免过多的推荐热门图书的目的,从而提升了推荐结果的多样性。
3 实验分析和总结
由于高效用户借阅图书的数据过于稀疏,用户的借阅行为非常不稳定,为了较好地验证实验的效果,论文计算准确率和召回率时使用的测试集是最近一个月内有借阅行为的用户数据。

表1 选取每个用户的相似用户数的实验
其中TopN 是指为每个用户选取的相似用户数量,图书覆盖率指为用户召回的所有图书占图书馆所有图书的比例。根据以上指标,实验选择每个用户相似用户数量为50。

表2 多源数据的相似度融合方法对应的实验效果
从以上实验结果可以看出,优化后的协同过滤算法在准确率和召回率上都有了较大的改进。
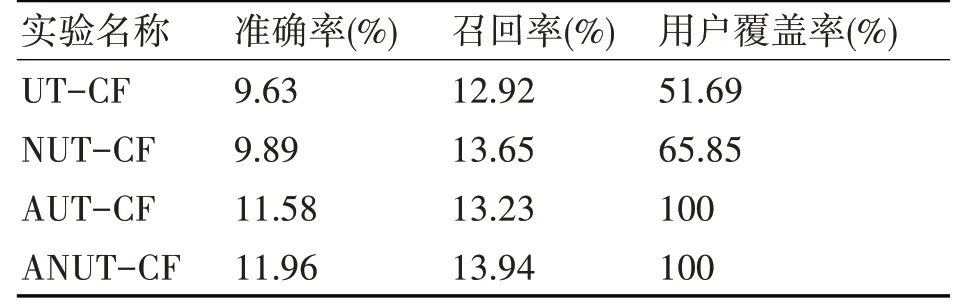
表3 多源数据的相似度融合方法对应的实验结果
其中,UT-CF表示基于时间衰减的基于用户的协同过滤算法,NUT-CF 为融合了用户上网信息和图书借阅的用户相似度算法,AUT-CF 为融合了用户学院信息和图书借阅的用户相似度算法,ANUT-CF 为融合了用户上网信息,学院信息和图书借阅的用户相似度算法。
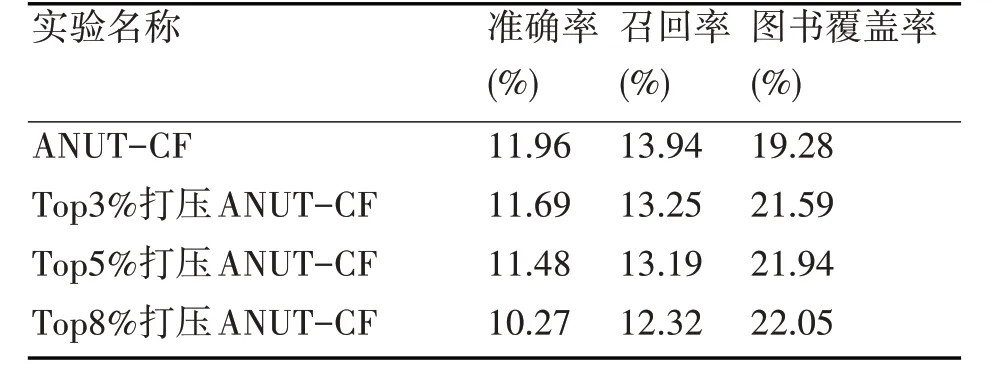
表4 热门图书的打压试验对应的实验结果
从以上实验结果可以看出,随着热门图书打压力度的提升,图书覆盖率在提升,但是去除了top8%的热门图书后,准确率和召回率出现了较大幅度的下降,因此对top5%的热门图书做热度打压。
4 结语
协同过滤算法作为个性化推荐系统的基础算法被广泛应用在各个个性化推荐场景中,冷启动问题和数据的稀疏性带来的精度低的问题一直是协同过滤算法所面临的问题。论文基于改进的用户协同过滤算法,结合高校图书借阅的场景以及用户产出的数据,分别通过多源数据的相似度加权,基于时间衰减的用户兴趣模型对以上问题进行改进,并取得了明显的效果。
论文更多的是从用户角度解决了基于用户的协同过滤的一些问题,但是高校图书馆经常会上一些新的图书,这部分图书由于没有用户借阅过,所以会带来图书的冷启动问题,所以优化的基于物品的协同过滤算法也是可以对当前的推荐场景起有很大帮助的。
猜你喜欢
南风(2020年22期)2020-09-15 07:47:08
小学生优秀作文(低年级)(2019年5期)2019-04-25 13:13:40
小学阅读指南·低年级版(2017年12期)2017-12-26 17:01:14
电子测试(2017年15期)2017-12-18 07:19:27
海外星云(2016年7期)2016-12-01 04:18:00
家庭百事通(2016年5期)2016-05-06 20:48:31
智能系统学报(2015年4期)2015-12-27 09:38:39
电子设计工程(2015年6期)2015-02-27 12:04:53
华东师范大学学报(自然科学版)(2014年6期)2014-02-27 13:40:55
大众创业(2009年10期)2009-10-08 04:52:00
