
基于时空场景的话语文本数据库构建与应用研究
2020-12-07 08:26关琳
无线互联科技 2020年18期
关 琳
(1.江苏警官学院 公安管理系,江苏 南京 210031;2.南京大学 中国智库研究与评价中心,江苏 南京 210093)
0 引言
对“话语”的研究,一直是各相关学科共同关注的热点领域。随着计算机技术的发展,这一领域逐渐成了交叉研究融合的热点。
人工智能时代,自然语言处理技术可以帮助计算机提升对“话语”的理解程度,而大数据文本技术可为研究者提供丰富的语料资源。二者的有机结合很好地辅助这项研究的实施。爬虫可以方便实时获取固定格式的社交媒体文本内容,以支撑“话语”舆情热点研究。通过爬虫获取英语国家Twitter“话语”,并以此为分析对象开展舆情研究的成果在Web of Science中不胜枚举。然而,“话语”的产生和表达与对象的文化、知识甚至是成长背景密不可分。其“话语”表达的思想存在时空关联性和场景特定性,无法追溯Twitter之外不同时空场景来源的“话语”是爬虫工具视角下欧美“话语”研究的短板。
由于各国社会文化背景的差异,“话语”的表达方式不尽相同。与欧美国家相比,东亚国家“话语”表达更为审慎和含蓄,“话语”传播以正式渠道为主,更容易追溯历史文本并开展宏观时空下的话语研究。当下,随着移动互联网的普及,社交媒体在“话语”宣传中占有重要位置,如何将文本分析与爬虫工具相融合,是东亚“话语”研究的重要议题。
为整合东西方“话语”研究的数据资源,解决“话语”研究的共性问题,本文拟提出一种建构在数据库基础上的融合研究框架,探索建立基于时空场景的话语文本数据库,融合爬虫工具,拓展“话语”历史文本与社交媒体文本内容的融合研究。
1 基于时空场景的文本数据库工具助力“话语”研究
国外收录“话语”的数据库工具较少,我国在这一方面资源相对丰富。这些数据库工具的共同点是具备新闻发布、信息检索、动态交互、资料分享、手机阅读等多重功能。作为我国“话语”面向公众的传播平台,这些数据库的功能十分丰富实用。但是就“话语”研究而言,由于产品定位,从功能上看上述数据库普遍缺乏基本的文本统计、计量、分析手段;从内容上看,其收录的讲稿仅仅局限于十八大以来的若干篇重要讲话;从信息的组织形式上看,也仅仅支持按照主题或时间的分类查询。由于缺少文本语料库的词表、索引等关键组件,未来也无法满足词频分析、文本挖掘等研究需要。因此,上述数据库系统的功能与“话语”研究的实际需求相差甚远,与本文探索建立的基于时空场景的话语文本数据库存在着系统功能、数据内容和数据组织形式上的显著差异。
2 基于时空场景的话语文本数据库设计
以重构“话语”的数字语境为目标,“话语”文本数据库应主要包括3个方面的内容:首先“话语”文献是一类专题文献要尽可能的扩充文本资源;其次从数据挖掘提升机制的角度出发要设计合理的标引策略;最后数据库在设计过程中要引入时间、空间和场景向量,便于后续开展计量研究。按照以上思路设计,基于时空场景的话语文本数据库系统如图1所示。
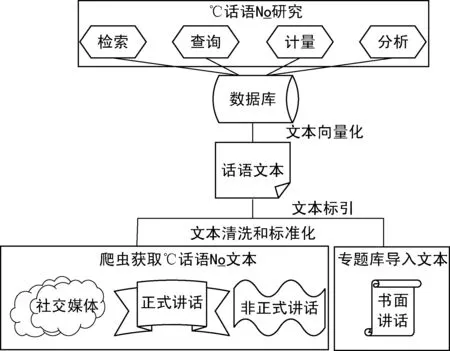
图1 基于时空场景的话语文本数据库系统
“话语”文本存在形式具有多样性特点,按照“话语”文本收集(处理)—保存—利用的流程需求,基于时空场景的话语文本数据库包括3个模块。
2.1 收集(处理)模块
收集(处理)模块的主要功能为数据采集和处理。“话语”广泛存在于各类专题库、新闻报道和网络媒体,数据采集层需要兼顾各种不同来源的“话语”采集需求。由于中西方“话语”传播方式和渠道的差异,数据库系统需要兼容爬虫和应用程序编程接口(Application Programming Interface,API)多种采集方式,以便于开展对包含社交媒体、新闻和专题库数据的采集。对于收集到的所有网络文献需要将其文本化,即清洗网页中的链接、图片等冗余内容只保留文本,这一步借助成熟的自动化工具完成。对于收集到的纸质文献需要将其标准化,利用光学字符识别技术(Optical Character Recognition,OCR)识别文字内容,将其电子化。
2.2 保存模块
保存模块的主要功能为数据保存和标引。由数据采集层采集到的文本是经过清洗和加工的标准化电子文本,需在数据保存层对其标引。首先,建立以分类词表为核心,其次,针对不同国籍和语种“话语”标引规范。标引工作以人工为主,抽词标引等自动化方法为辅。通过数据保存层的标引模块,可以将文本打上时间、空间、主题、场景、来源、类型等信息标签,便于后续开展研究。
2.3 应用模块
应用模块的主要功能是数据展示。利用前期经过文本清洗和标引的电子文本,可在该模块中开展基于内容分析法和文本计算法的定量研究,计量维度包括面向内容分析的词频统计、面向交叉主题分析的时空场景计量等。应用模块的建立可为社会科学各相关领域的“话语”研究提供工具支撑。
3 基于时空场景的话语文本数据库的应用
新西兰社会语言学家Janet Holmes[1]指出,在任意场景下参与者、话题、场景(社会情境)和功能这4项要素中至少有一个会对人们选择语言造成影响。基于时空场景的话语文本数据库可支持多维度全时空的“话语”研究,采用该工具可以快速分析出“话语”的核心重点。
以新冠肺炎疫情场景下的“话语”为例,对待和处理新冠肺炎疫情,世界各国采取了不同的方式,得到了迥然不同的处理结果。《纽约时报》在2020年4月26日发表了一篇题为“260000 Worlds,Full of Self-Praise,From Trump on the Virus”的文章,该文分析了自2020年3月9日新冠疫情在北美全面爆发以来的相关公开语料,并将这些“话语”分为自我夸耀、同情受害者、指责他人和传播错误信息四大类,通过计量方法指出在总量约为26万词的话语中,自我夸耀的话语达600余次[2]。
以基于时空场景的话语文本数据库收录的“话语”为研究对象[3],自2020年初新冠肺炎疫情暴发以来,系统通过爬虫工具收集新华网报道关于疫情的“话语”文本共62篇。通过文本清洗、去除无意义高频词,开展词频分析可以发现,在抗击新冠疫情期间,“人民”一词共出现32次。可见在“话语”中反复提及的“人民”一词无疑是我国抗击新冠疫情“话语”的核心重点。通过“话语”对比研究,各国的抗疫主题略见一斑,并可以较好地解释当下各国疫情处理的现状差异。
4 结语
“话语”研究在国家政治、经济、外交等方面对政策的解读有重要的意义。本文探索构建的基于时空场景的话语文本数据库,为我国“话语”研究和宣传提供了新的视角,可支撑人文社会科学各领域的基于时空场景的“话语”研究,同时也促进了我国“话语”的宣传和传播。
猜你喜欢
房地产导刊(2022年10期)2022-10-18
四川党的建设(2022年8期)2022-04-28
现代信息科技(2021年21期)2021-05-07
小学生学习指导(低年级)(2020年11期)2020-12-14
资源信息与工程(2019年2期)2019-05-09
作文大王·低年级(2018年10期)2018-12-06
电子测试(2018年1期)2018-04-18
温州医科大学学报(2018年8期)2018-03-03
电子制作(2017年9期)2017-04-17
温州医科大学学报(2016年2期)2016-03-16
