
改进YOLOv3 的实时性视频安全帽佩戴检测算法
2020-12-07 06:46黄林泉蒋良卫高晓峰
现代计算机 2020年30期
黄林泉,蒋良卫,高晓峰
(南华大学计算机学院,衡阳421000)
0 引言
在如今的工业界中,各种生产安全事故频繁发生,在对近几年全国安全事故数据分析后发现95%的生产安全事故是由于工作人员的不安全行为所导致的,如未佩戴安全帽进入车间。而产生这些现象的原因是由于生产监管不力,因为目前的生产监管工作枯燥且人力物力耗费大。为了解决上述问题,本文提出了一种视频中安全帽佩戴检测方法,可以很好的适用于多种复杂场景,具有较高的准确率且满足实时性要求。将该方法应用于生产车间场景下,仅需一个摄像头和一台服务器便可完成工作车间的管控,实时可靠的检测车间工作人员是否佩戴安全帽,对于不安全行为及时进行报警提示,帮助车间管理人员更好更轻松地监管车间的安全情况,避免安全事故的发生。
1 优化方法
Joseph Redmon 于2018 年提出的YOLOv3[1-3]算法由于其轻量、依赖少、算法高效等优点而十分受欢迎。可是在高准确率的要求下YOLOv3 却很难达到高速率的要求。并且在YOLOv3 算法中,会分别取用特征提取网络DarkNet53 输出的三种尺度的特征图进行特征融合,这三种尺度的特征图分别对应了不同级别的特征信息,而这些特征图之间跨度十分大,经历了多个卷积层之后导致上一尺度的特征信息丢失严重,进而会导致特征融合质量较差的问题。针对上述问题,本文种使用了基于ResNet[4]网络和InceptionV3[11]网络改进的ResNeXt50[5]网络作为新的特征提取网络以增强特征图的表达能力。同时引入CSP Net[6]中提出的梯度分流截断机制,在减少模型运算量的同时进一步的提高卷积网络的学习能力。并且融入了SPP Net[7]和PA Net[8]网络中的思想提高特征融合质量。为了提高算法的整体速度,结合DeepSort[9]多目标跟踪技术实现跳帧检测,对检测到的每个目标进行运动预测,计算出目标的下一帧位置以代替目标检测,减少时耗,进而提高算法处理视频时的实时性。
2 数据集构建
2.1数据采集
目前开源的安全帽数据集只有SHWD(Safety Hel⁃met Wear Dataset)数据集,该数据集一共包含7581 张图片数据,以Pascal VOC 格式进行了标注,共分为per⁃son(未佩戴安全帽)和ha(t佩戴安全帽)两类。通过对该数据集进行研究分析发现,该数据集包括9044 个佩戴安全帽的目标以及111514 个未佩戴安全帽的目标,正负例样本十分不均衡,且存在数据场景种类较单一、拍摄角度多为直拍、缺乏易于安全帽混淆的帽子数据(如防晒帽、贝雷帽等)以及安全帽未正确佩戴数据(如安全帽置于手中或桌面上等情况)。因此本文针对性的采集了上述缺乏的数据和一些复杂难例数据共2400张图片数据并且进行标注,与SHWD 数据集共9981 张图片用于算法的训练以及验证。数据集样例如图1 和2 所示。

图1 易混淆安全帽数据

图2 安全帽未正确佩戴数
2.2 数据增强
针对于安全帽检测,大部分的数据都为远距离的小目标数据,而密集小目标数据对于目标检测算法来说一直都是一个难题,本文使用数据镶嵌(Data Mosa⁃ic)的方法进行数据增强。数据镶嵌技术指的是在指定的图像尺寸下,随机选取4 张图片转换到同一尺寸,接着在图像中随机选取一点p 作为切分点,将图像切分为4 部分并且分别从上述随机选取的4 张图片中进行裁剪得到section 1、2、3、4,最终将这四部分镶嵌在一起得到结果。流程如图3 所示。之后进一步判断各个部分是否包含了检测目标,如果包含了目标就将各sec⁃tion 所包含的目标组合形成镶嵌后图像的标注数据。此外,本文还使用了随机放缩、随机水平翻转、随机通道抖动等数据增强手段。在训练过程当中,采用了0.4-1.6 的图像放缩,50%概率的水平翻转,以及幅值为0.7 的通道抖动等。

图3 数据镶嵌示意图
3 改进YOLOV3算法
为了提高算法精度,本文主要针对于YOLOv3 算法的特征提取网络、特征融合以及损失函数三个部分进行改进,改进后的网络结构如图4 所示。

图4 本文算法模型结构
3.1 特征提取网络
3.1.1 ResNeXt
本文使用从ResNet 改进而来的ResNeXt50 作为特征提取网络并且通过梯度分流截断机制以提高特征图的表达能力。两者都属于残差网络,通过残差机制加深网络层次而有效避免梯度弥散和梯度爆炸的问题。两者的区别主要在于ResNeXt 的残差单元引入了cardinality 因子,相当于分组卷积的形式,如图5 所示,这种形式使得每一组卷积网络所学习到的特征具有较大的差异性,分别关注于不同的特征点,因此会具有更强的特征表达能力,并且每组卷积都具有相同的拓扑结构,简化了模型复杂度。对于图5(b)所示的残差单元其计算公式为:

其中σ表示leaky relu 激活函数,C 表示cardinality即集合数,Wi表示每一组卷积的权重参数,x表示上一个单元的输出,f(x,Wi)表示输入经过拓扑结构卷积后的输出。

图5 残差单元对比
3.1.2 CSP Net
上述基于skip connection 的计算方式是相对暴力的,即在激活函数之前就将上一个单元的输出与当前单元的输出进行相加连接。包括ResNeXt 在内的ResNet、DenseNet[15]等基于skip connection 机制的残差网络均存在这个问题。以Dense Net 为例进行论证,这个过程可以用公式(2)表示:

这种方法会导致反向传播过程中,梯度信息重复计算,被多个卷积层重复利用降低卷积网络的学习能力并且增加模型重复的计算,如公式(3)所示:
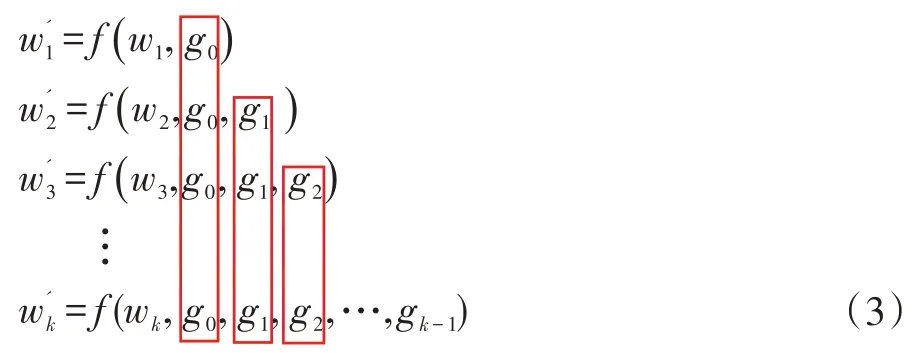
每一层的权重参数都重复使用了上一层的梯度信息。而CSP Net 中的跨层连接和梯度分流截断可以很好的解决上述问题。对于每一个残差单元的输入x0,首先将其分成两部分先经过一个dense block 进行残差映射得到输出然后经过一个跨通道池化操作进行梯度信息截断得到xT,之后直接与没有进行残差映射的进行拼接再经过一个跨通道池化操作得到输出xU。该方法的前向传播和权重更新过程可以用公式(4)和(5)表示。

通过这种方式,最后进行拼接的两部分输出和均不存在重复的梯度信息,很好的避免了梯度重复计算。经实验证明,该方法可以很好地适用于同样基于skip connection 机制的ResNeXt 残差网络,只需对原ResNeXt 残差单元的输入进行切分即可,并且由于切分后的输入仅为原输入的一半,因此不再需要瓶颈层(bottleneck),如图6。

图6 应用CSP Net于ResNeXt
使用本文算法其他结构不变,仅更换特征提取网络进行对比实验,实验结果如表1 所示。
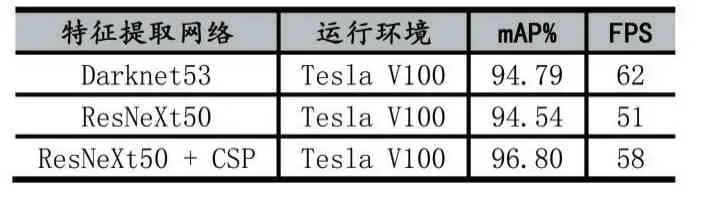
表1 特征提取网络效果对比
3.2 特征融合
3.2.1 PA Net
在YOLOv3 算法中,会选取特征提取网络输出的三种尺度的特征图进行特征融合,它们分别对应了不同级别的特征信息,而这些特征图之间跨度十分大,在经过多个卷积层后导致各层级特征之间分离度较高,每个层级的特征对其他层级的特征信息保留较少。因此本文引用了PA Net 中从下至上(Bottom-Up)的特征融合思想。在高层级特征与低层级特征之间直接建立一个短连接(short connection)进行融合产生新的特征图。对于每种尺度的特征图,首先经过下采样使其与下一级特征图保持尺寸一致(最低层级映射后的结果就是自身),然后与其下一层级特征图进行元素级拼接,之后经过一系列的卷积单元将其映射到新的特征图上完成特征融合,其过程如图7 所示,(a)部分代表的是原多尺度特征图的形成过程即从上至下的过程,(b)部分代表的是Bottom-Up 从下至上的特征融合过程。

图7 Bottom-Up特征融合
3.2.2 SPP Net
为了提高算法在局部特征上的关注度以提高算法的尺度适应能力。本文在最高层级(Y1)的特征图上使用了空间金字塔层级的思想,分别进行三次5×5、9×9、13×13 步长(stride)为1 的最大池化(max pooling)得到三种不同局部的特征图,然后将其在通道维度上进行拼接。这种方式可以很好的关注图像不同尺度的局部特征,并将局部特征与整体特征进行融合,丰富特征图的表达能力。融合过程如图8 所示。

图8 SPP特征融合
3.3 损失函数
在YOLOv3 中使用均方方差(Mean Square Error)作为目标框中心坐标和宽高的损失函数如公式(6):

其中S 表示网格个数,一共S×S 个网格,B 表示每个网格产生B 个候选框。x、y、w 和h 分别表示目标框的中心坐标及宽高,ẋ、ẏ、ẇ和ḣ分别表示预测框的中心坐标及宽高。I 表示当前候选框是否负责预测,若是则为1,否则为0。但这种方法无法区分目标框与预测框之间不同的包含情况,且无法适应尺度上的区别。而交并比(Intersect over Union,IoU)损失函数(公式7)可以较好地解决上述问题。

两者效果对比如图9 所示。

图9 MSE与IoU对比
MSE 损失函数无法区分上述三种不同的包含情况,而IoU 损失函数表现较好。然而IoU 损失函数依旧存在问题。即当预测框和目标框完全不相交时IoU为0,此时损失函数不可导,无法优化两个框不相交的情况;IoU 无法反映两个框是如何相交的(包括中心点距离、角度、长宽比等问题);因此本文使用更为优化的CIoU[10]作为目标框的损失函数。CIoU 在其基础上充分考虑了目标框与预测框之间重叠比、中心点距离以及长宽比。计算公式为:
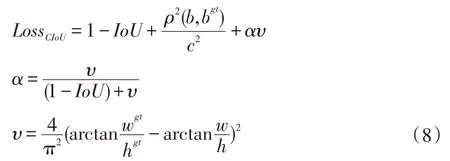
其中IoU表示目标框与预测框的交并比,ρ(b,bgt)表示预测的中心点与真实中心点之间的欧氏距离,用来拟合中心点,υ用来衡量长宽比一致性。使用CIoU作为损失函数,可以很好的提升算法准确率。
4 DeepSort目标跟踪算法
针对视频流数据,本文使用DeepSort 目标跟踪技术对每个目标进行位置预测,代替目标检测结果以实现插帧检测。DeepSort 通过目标的外形特征以及运动特征对目标进行跟踪,两大核心算法是卡尔曼滤波和匈牙利算法分别负责对应目标的状态估计和分配问题。算法通过一个8 维向量(μ,υ,γ,h,ẋ,ẏ,γ̇,ḣ)来表示目标的状态,其中(μ,υ)是目标框的中心坐标,γ是长宽比,h是高,其余4 个变量分别代表目标在图像坐标系中所对应的速度信息。使用一个基于常量速度模型和线性预测模型的标准卡尔曼(Kalman)滤波器对目标运动状态进行预测,预测的结果为(μ,υ,γ,h)。在分配问题上,DeepSort 同时考虑了目标的运动信息以及外观信息以进行关联,以解决跟踪过程中相机运动导致的目标Id 频繁切换的问题。使用目标检测框与跟踪器预测框之间的马氏距离来描述运动关联程度:

其中dj表示第j 个检测框的位置,yi表示跟踪器对目标i 的预测位置。Si表示目标i 的检测位置与预测位置之间的协方差矩阵,即以目标检测位置与预测位置之间标准差的形式对状态测量的不确定性进行考虑。然后使用重识别网络提取目标的特征向量作为外观信息,对每一帧成功匹配的结果进行缓存作为特征向量集,对于每一个目标检测框,将其特征向量与所有跟踪器的特征向量集计算最小余弦距离。如公式(10):

其中rj表示第j 个目标检测框的特征向量,Ri表示第i 个跟踪器的特征向量集。最后使用两种关联方式的线性加权值作为最终匹配度量,λ为权重系数。
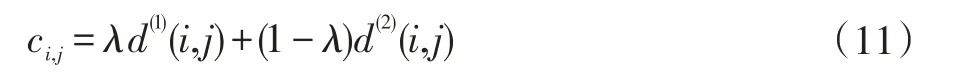
5 实验分析
5.1 生成锚点框
在YOLOv3 算法中锚点框用于大致确定目标位置以及大小以便后续算法进行回归精修。因此锚点框的质量直接影响到目标检测的效果。本文使用K-means聚类算法在9981 张图片数据上进行9 类聚类以确定最适合当前数据集的锚点框,然后根据锚点框大小将其分配到对应尺度的特征图上,得到的结果如表2。

表2 锚点框分配
5.2 训练模型
本文将SHWD 数据集和自建数据集共9981 张图片按照8:2 的比例分成训练集和测试集。在Ubuntu 18.04 操作系统进行模型训练,使用GPU 加速工具CU⁃DA 10.1。 CPU 为 Intel Xeon Gold 6148 CPU @2.40GHz,GPU 为NVDIA Tesla V100@16 GB,内存为32 GB。梯度下降方式为随机梯度下降(Stochastic Gra⁃dient Descent,SGD),动 量 为0.926,权 重 衰 减 为0.00048,使用4×16 小批量训练方式。学习率从0.001开始。整个训练过程一共为20000 次迭代,按需调整学习率在迭代进行到80%(16000)及90%(18000)的时候学习率分别减小10 倍。为了与原算法进行效果对比,在相同环境下训练得到原始的YOLOv3 模型。
5.3 实验结果分析
本文使用目标检测领域常用的平均精度(Average Precision,AP)、平均精度均值(Mean Average Precision,mAP)和每秒检测帧数(Frame Per Second,FPS)作为评测指标来评测本文算法对安全帽佩戴检测的效果。在将IoU 设置为0.5 时在规模为1996 张图片的测试集进行测试,结果如表3 所示。

表3 实验结果对比
可以发现,本文算法由于引入了PA Net 和SPP Net 进行特征融合,加大了模型运算量,因此在未结合DeepSort 的时候,运行效率略低于YOLOv3,但在检测精度上,更换了特征表达能力更强的特征提取网络以及优化损失函数等,两种类别的检测精度相比于YO⁃LOv3 都有较大程度提升。具体检测实例如图10 所示,其中绿色方框表示佩戴安全帽,红色方框表示未佩戴安全帽。在图10(a)一般场景下,YOLOv3 与本文算法均具有较好的检测效果。在图10(b)人群较密集存在遮挡的场景下,YOLOv3 漏检了部分遮挡较严重的目标,而本文算法未出现漏检。在图10(c)图片质量较差情况下,图片中间存在一个由于运动而高度模糊的目标,YOLOv3 与本文算法均出现了漏检。图11(d)存在极小目标的情况下,YOLOv3 算法对于小目标出现了较为严重的漏检而本文算法表现优异。

图10 安全帽佩戴检测效果对比
5.4 消融实验分析
为了评测PA Net 和SPP Net 对算法模型的贡献,本文中使用消融实验在相同测试集上进行评测,为了进一步细化实验效果,将尺寸小于32×32 的目标划分为小目标(Small),大于32×32 且小于64×64 的划分为中等目标(Medium),其余为大目标(Large)。最终实验结果如表3 所示。可以发现,在第1 组中,算法对大目标的检测效果较好,相对来说小目标的检测效果不太理想。在第2 组中引入了SPP Net 对三类目标的检测效果均有提升,其中提升最显著的是中等目标为5.28%,并且在检测精度本就较高的大目标上继续提升了2.15%。在第3 组中引入PA Net,其大大提升了算法对小目标和中等目标的检测精度而对大目标的检测精度提升较微弱。在第4 组同时引入SPP Net 和PA Net 的情况下,对小目标、中等目标和大目标的检测效果均取得了最优。证明本文中所使用的方法能够有效地提升算法检测精度。

表4 消融实验结果
5.5 多场景测试
为了验证本文算法可以很好地适用于各种复杂场景。对人群密集场景、低亮度场景、易混淆安全帽佩戴场景、远距离场景、多角度场景、低清晰度场景、背对镜头场景和安全帽未佩戴场景八种复杂场景进行测试验证,实验结果如图11 所示。可以看出本文算法仅在远距离场景下对少数极小目标存在漏检以及低清晰度场景下存在漏检,这也是后续希望进一步优化的方向。而在大多数场景下均具有较好的检测效果,因此本文算法可以很好地适用于各种场景进行安全帽佩戴检测。

图11 多场景测试结果示例
6 结语
本文对YOLOv3 算法进行改进优化,提出了一种对自然场景下视频图像中工作人员是否佩戴安全帽的实时性检测算法。通过使用特征表达能力更强的特征提取网络并且结合PA Net 和SPP Net 中的特征融合技术,进一步增强特征图的尺度适应能力以提高对小目标的检测效果,使用更加鲁棒精确的CIoU 作为目标框的损失函数,提高对目标位置预测的精度。在1996 张图片以及多场景情况下进行实验测试,测试结果表示本文算法均有较高的精度以及稳定性,并且结合Deep⁃Sort 技术,在NVIDIA GTX 1060 显卡环境下检测速率可以达到32 帧/s。以上测试结果均证明了本文方法的有效性。在未来研究中,将对算法结构进行进一步的优化以提高算法对小目标和在低清晰度场景下的检测精度。
猜你喜欢
农业工程学报(2022年12期)2022-09-09
成都信息工程大学学报(2022年2期)2022-06-14
北京大学学报(自然科学版)(2022年1期)2022-02-21
北京航空航天大学学报(2021年9期)2021-11-02
北京航空航天大学学报(2021年9期)2021-11-02
计算机系统应用(2021年9期)2021-10-11
北京航空航天大学学报(2020年10期)2020-11-14
北京航空航天大学学报(2019年9期)2019-10-26
课外生活·趣知识(2019年4期)2019-09-10
今古传奇·故事版(2017年5期)2017-04-08
