
基于BERT和方面注意力的方面情感分析方法
2020-12-04 07:49许宋烁张梓光张小芳
无线互联科技 2020年16期
许宋烁,张梓光,张小芳,周 敏
(广东工业大学 自动化学院,广东 广州 510006)
0 引言
作为自然语言处理领域的重要内容之一,情感分析旨在识别和提取文本的主观信息,然后把文本情感极性分类为积极、消极或中性[1]。然而,当一个句子中包含多个方面时,普通的情感分析会遇到情感极性模糊的困难,基于方面情感分析(Aspect-Based Sentiment Analysis,ABSA)则克服了上述局限性。
目前,学术界已经提出很多方法用来处理基于方面情感分析。早期基于特征的机器学习方法[2]大获成功,近年来,基于深度学习的方法在情感分析领域取得了更好的成绩[3]。最近两年,采用预训练形式的模型[4-5]将自然语言处理推向了新的高度,特别是BERT在多项自然语言处理任务上取得了优异的成绩,但上述模型在基于方面情感分析上对方面的注意力并不足。
针对上述问题,本研究提出一种基于BERT和方面信息注意力的编码解码模型。该模型采用句子与方面信息融合输入,通过BERT进行编码后,再次采用方面信息进行解码,增强了模型对方面信息的注意力。
1 BERT-AAtt模型
BERT-AAtt模型由输入部分、BERT部分、方面注意力部分和输出部分4个部分构成,具体如图1所示。

图1 基于BERT和方面注意力的方面情感分析模型
1.1 输入部分与BERT部分
将句子与方面信息合并为句子对,分割为token序列,输入模型。BERT接收token序列后,利用其从大量数据集中训练得到的丰富语义信息,从token序列中提取对应方面的语义特征。
1.2 方面注意力部分
方面注意力部分的输入采用了BERT的“sequence output”,即整个token序列对应编码后的输出序列。
本模型的方面注意力部分共有6层,每层结构相同,均采用了与Transformer解码器类似的结构。
多头注意力部分的输出可表示为:
vl,i=softmax(el,aiHT)·H#
(1)
vl,i将经过一个残差连接和层归一化,计算过程如下:
(2)
再经过一个全连接前馈网络,可获得特定方面的文本表示,即:
(3)
同样经过一个残差连接和层归一化后,可得到当前层的最终输出:
(4)
1.3 输出部分
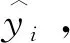
(5)
(6)
(7)
2 实验结果分析
2.1 实验数据
本实验对来自SemEval-2014任务4、SemEval-2015任务12和SemEval-2016任务5中的Restaurants领域数据集进行整理、合并后作为本实验的数据集。
2.2 实验结果分析
在Restaurant-Merge数据集上分别进行了三分类实验后,各模型的查准率、查全率和F1值如表1所示。
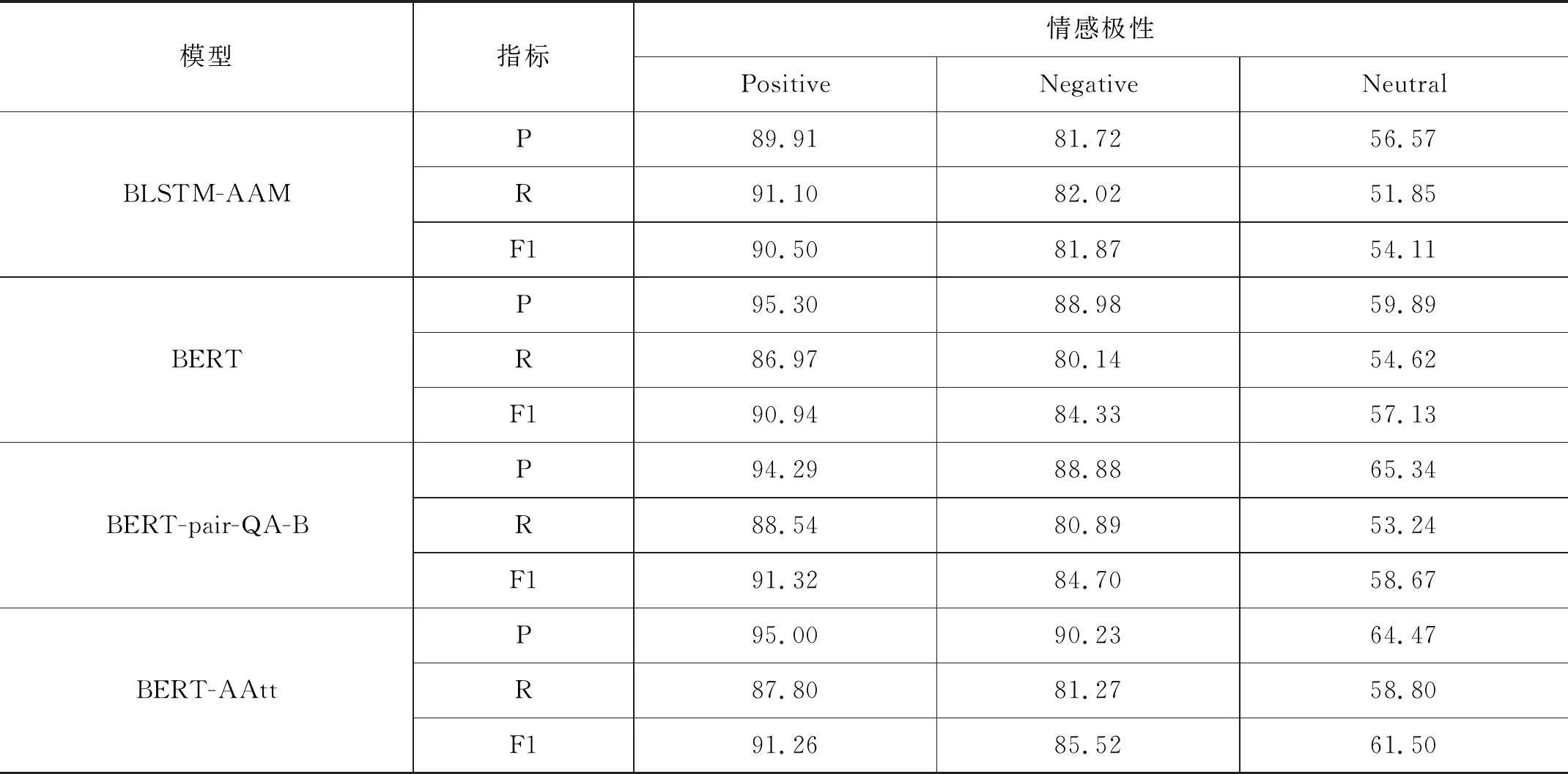
表1 不同模型在数据集上的三分类结果
在积极情感方面,各个模型都能良好地识别,这是因为积极情感的样本在数据集中占比最大,且情感倾向较为明显。在消极情感与中性情感方面,BERT-AAtt模型胜过了其他模型,分别比BERT提升了1.41%和7.65%,相比于更新的模型BERT-pair-QA-B,也有了0.97%和4.82%的提升。这说明BERT-AAtt模型在样本量较少以及方面情感极性比较模糊的场景下对方面的注意力更充分,有更好的方面情感分析能力,验证了本研究所提方法的有效性。
猜你喜欢
小雪花·成长指南(2022年1期)2022-04-09
中国生殖健康(2020年5期)2021-01-18
北极光(2019年12期)2020-01-18
小太阳画报(2019年10期)2019-11-04
小哥白尼(趣味科学)(2019年6期)2019-10-10
中国生殖健康(2018年5期)2018-11-06
传媒评论(2017年3期)2017-06-13
发明与创新(2016年38期)2016-08-22
太空探索(2016年5期)2016-07-12
