
基于Charm++的并行FMM实现
2020-12-02 05:12:50丁磊王武姜金荣赵莲
数据与计算发展前沿 2020年3期
丁磊,王武,姜金荣,赵莲
1. 中国科学院计算机网络信息中心,北京 100190
2. 中国科学院大学,北京 100049
引言
N 体问题[1](N-body problem)是已知多个粒子的初始位置、速度和质量,求解出其在经典力学下的后续运动的问题,属于高性能数值计算的七类典型应用之一[2],在宇宙学模拟[3]、分子动力学研究[4]等诸多领域有十分重要的应用。
常用的N 体求解方法有直接法[5](Particle-Particle, PP)、粒子-网格法[5](Particle-Mesh, PM)、树方法[6](Barnes-Hut, BH)、快速多极子方法[7](Fast Multipole Method, FMM)等。FMM 采用长程力近似计算方式,基于树结构的多层递归盒子划分策略,使用核心函数的级数展开,将远程力的作用近似为粒子与盒子的作用及盒子间的作用,极大降低了场中粒子相互作用的计算复杂度。由于可以指定划分的层数和展开阶数,FMM 能有效平衡执行时间与计算误差[8]。与BH 相比,FMM 基于高阶展开,因此精度可以达到更高,同时可以控制计算量。
近年来,国内外有许多FMM 相关研究与应用成果。如曹小林[9]等基于JASMIN 框架实现了FMM 的求解器;Cruz[10]等基于PETSc 框架实现了PetFMM 软件;Winkel[11]等基于MPI 实现了N 体计算软件PEPC。随着异构系统的不断发展,学者开始针对特定体系结构进行研究。Lashuk[12]等使用256块GPU 在NCSA Lincoln cluster 上对KIFMM 进行加速;Yokota[13]等在TSUBAME 2.0 系统上使用4096块GPU 来计算各向同性湍流;王武[14]等基于申威众核处理器进行FMM 优化。此外,还有基于FMMPM 方法在GPU 上进行N 体模拟实现[15]等。
Charm++是一种基于消息驱动的编程框架,具有过分解(Over-decomposition)、可迁移(Migratability)、异步消息驱动(Asynchronous Message-Driven Execution)等特点,可以提供运行时的动态负载均衡与容错机制[16]。近年来,有许多工作利用Charm++的动态负载均衡特性,取得了不错的效果。如中国科学院计算机网络信息中心研发的并行框架SC_Tangram[17]、基于Charm++的非结构网格[18]等。本文中,我们将基于Charm++实现FMM 程序的并行化,并与MPI 版本的并行实现进行对比分析,结果表明整体性能有10%左右的提升。
1 并行FMM 介绍
1.1 FMM 的计算流程
FMM 是一种区域划分的计算方法,其核心思路在于对位势函数在远场进行多极展开,再将多极展开转化为近场的局部展开,继而通过位势计算出粒子在引力场所受到的作用力。
FMM 使用球坐标的多极展开来近似多个粒子形成的引力场对外界的作用,用局部展开来近似外界引力场对区域内粒子的作用,包括P2M、M2M、M2L、L2L、L2P、P2P 六个计算步骤。
下列公式中,α、β、ρ分别表示球坐标的极角、方位角与径向距离,mi为粒子质量。P为展开阶数,球谐展开中的系数m、n与P正相关。
(1)P2M (Particle to Multipole Expansion)
P2M 操作只发生在计算区域的最底层,也就是最小的盒子区域内。主要的思想是根据盒子里面的粒子位置,计算出这个盒子的多极展开系数。
P2M 的计算方法如下[19]:
其中,k 为盒子中的粒子数,Mnm是多极展开系数,Ynm(θ,φ)是球谐函数,计算公式为:
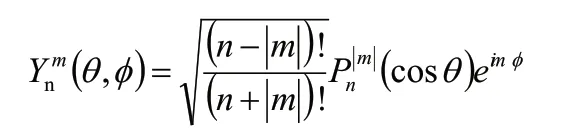
式中Pn(x)为Legendre 多项式。
(2)M2M (Multipole Expansion to Multipole Expansion)
M2M 操作的计算方法如下[19]:

其中,Mkj是转移中心之后的多极展开系数,Okj是下一层盒子的多极展开系数。
M2M 是一个自下向上的过程,不断地收集下层的多极展开系数,计算本层的多极展开系数,再到更高一层进行计算。
(3)M2L (Multipole Expansion to Local Expansion)
P2M 操作与M2M 只进行多极展开系数的计算,目的是计算出盒子对空间的作用效果。而M2L 操作是计算相互作用。
M2L 是一个多极展开转化为局部展开的过程,计算方法如下[19]:
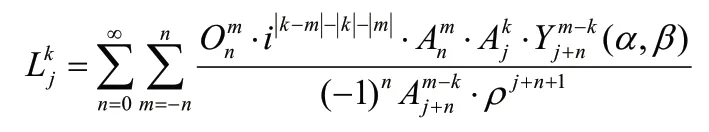
其中,Lkj为局部展开系数,Onm为多极展开系数。
在计算M2L 的过程中,需要找到当前盒子的次相邻盒子,即与当前盒子不相邻,但是父盒子与当前盒子的父盒子相邻的盒子。根据这些盒子的多极展开系数,计算出局部展开系数。
(4)L2L (Local Expansion to Local Expansion)
L2L 的计算公式如下[19]:
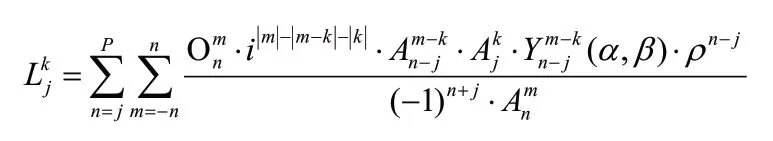
其中,Lkj为局部展开系数,Onm为局部展开系数。
L2L 是一个与M2M相反的过程,完成了相互作用的中心转移。在M2L 中只考虑了本层的相互作用,那些来自父盒子的作用力是通过L2L 来计算。这样,就可以计算出来自非邻居盒子的作用。
(5)L2P (Local Expansion to Particle)
L2P 是P2M 的逆过程。经过L2L 操作后,已经在最底层盒子中获取来自非邻居盒子的作用,而L2P 就是把这些局部展开系数转为盒子中粒子所受到的作用力。
L2P 的计算公式如下[19]:
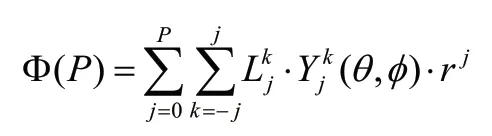
(6)P2P (Particle to Particle)
由于近似计算需要两个区域有一定的距离,无法使用近似的方式求解出最底层盒子来自邻居盒子的作用力。因此,只能依照万有引力公式,求解出邻居盒子中粒子的作用力。
1.2 并行FMM 算法
FMM 的并行分解即为空间分解。如算法1 所示,每个并行单元负责一个区域,在区域中按照预定分布初始化全局粒子的位置,通过partition 操作将粒子划分给处理区域,并依照希尔伯特编码建立树。此后执行粒子到盒子以及盒子到盒子的P2M 和M2M 操作,获得多极展开系数。

算法1 并行FMM
鉴于P2P 操作和M2L 操作需要了解相邻和次相邻盒子的信息,需要进行一次全局通信,将这些信息保存在本地关建树(local essential tree)中。最终执行树的自上而下的遍历,完成L2L 与L2P 操作。因此,在并行FMM 中需要进行两次全局通信,分别发生在partition 和local essential tree 处。
2 Charm++介绍
Charm++是基于C++的面向对象并行编程框架,由UIUC 并行编程实验室开发,具有过分解、可迁移、异步消息驱动的特点[20]。过分解指并行计算对象的数量多于实际的处理器数量。可迁移指并行计算对象可以在处理器间移动,完成动态负载均衡。异步消息驱动指每个处理器上的并行对象的执行流由消息驱动,计算对象间的消息传递采用异步方式,不阻塞执行流。
Chare 是Charm++的基本计算单元,其本质是分布在不同的处理器上的C++对象。代理(Proxy)是一种特殊的C++对象,用以表示一个远程的Chare。Chare 间的通信通过调用代理的特殊成员方法来实现,由Runtime 负责将本次调用的参数封装成消息,并发送到对应的远程Chare,该过程通常被称为远程调用。
Charm++提供了Chare array、group、node group等并行数据结构。其中,Chare array 提供一个统一的代理,每个array 的成员Chare 都有一个thisIndex,可以通过proxy[someIndex]来调用编号为someIndex的Chare 上的方法。
PUP (Pack and Unpack)框架是Charm++提供的序列化框架,负责远程调用和Chare 迁移时的序列化工作。
PE (Processing Element)和Node 是Charm++的抽象概念。其中PE 是Chare 的执行实体,其上有许多Chare 和消息。Node 由多个PE 组成,是一种共享内存的抽象表达。Node 上的不同Chare 共享Node的地址空间。在实现上,PE 一般对应线程,而Node对应于进程。
Charm++的各种实体概念如图1所示。
Charm++的项目由ci (Charm++ interface)文件和C++源码构成。其中ci 文件定义了Charm++中的Chare、message、module 等实体。预处理系统解析ci 文件后生成对应头文件和实现文件,使用者需要在C++源码中引入这些文件。
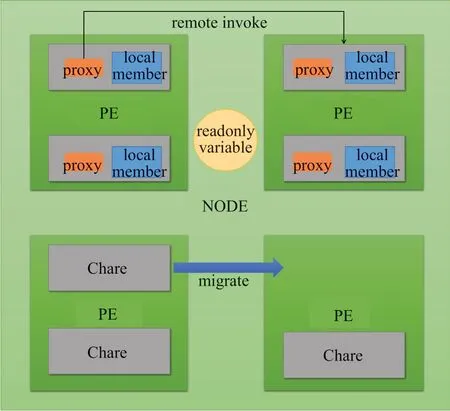
图1 Charm++ 概念示意图Fig.1 Charm++ concept diagram
Charm++不支持全局可变变量,但支持全局只读变量。只读变量在ci 文件中使用readonly 关键字引入,在mainChare 的构造函数中进行初始化。
每个PE 上都有一个消息队列。以PE 的视角看,有一个执行流不断从队列中取出消息。如果消息是种子,将创建新的Chare。如果消息是远程调用,则找到PE 上对应的Chare,将消息解包并调用。在调用过程中可能会产生新的种子和远程调用,由Runtime 决定新消息对应的PE。
因此,Chare 间的消息传递是异步的方式。调用者只知道消息在队列里,但不清楚消息是否已被执行,即调用者无法立即获得执行的结果。使用者可以定义一个远程方法供接收方调用,并在这个远程方法中获取通信结果,执行后续操作。这种风格使代码杂乱且易错。为了方便表示执行流的依赖关系,Charm++提供了SDAG[21](structure dagger)表示方法。
SDAG 的语法采用
Charm++预处理器会分析ci 文件中的SDAG 语法,并生成对应的代码,将SDAG 语句块拆分成许多continuation 函数,即多个阶段。以when 语句为例,Runtime 会在method 被触发后,调用下一个阶段对应的continuation。这样使用者无需自行编写等待、判断以及跳转的远程方法。
3 并行实现
3.1 任务分解与预处理
在本文中,我们定义一个名为master 的mainChare作为并行任务的发起者和规约消息的接收者,定义一个名为slave 的一维Chare array,作为基本的并行计算单元。
鉴于Chare 需要在PE 上执行,而且存在运行时迁移的情况,我们将原始的全局变量保存在slave 的成员中,并以参数的方式传递进去。
对于计算开始前已知且只读的全局变量,使用Charm++提供的readonly 变量表示,并在master 中进行初始化。
3.2 异步通信转化
Charm++采用异步通信的方式,这使得通信的发起方无法了解到消息是否被接收。
在MPI 中,我们可以在一个函数中发起多次通信。对于阻塞通信,操作系统会将函数的实参和局部变量保存在栈中,等到通信结束后再进行调度;对于非阻塞通信,程序中有循环代码对通信结束条件进行判断,控制流始终在该函数中。在Charm++中,用户只能通过消息驱动来触发后续操作,这意味着通信发起时,我们就失去了局部变量和实参的内存分配。为了恢复状态,需要将跨越通信的实参和局部变量保存到Chare 的成员中。
针对通信函数XXmethod,我们引入结构体XXmethod_param 来保存这些信息。考虑到实参的初始化有传值和传引用的方式,我们只在结构体里保存变量地址。对于传值的方式,需要引入init_XX_by_value 来动态分配内存并保存;对于传引用的方式,引入init_XX_by_ref,来保存已有变量的值,并提供一个release 方法用于释放值初始化时分配的空间。
另一方面,某个通信函数可能被调用多次,结束后跳转到不同的执行流。为了保证通信结束后函数的正常驱动,我们需要保存通信结束后的下一步执行的位置。
本文中,我们将需要通信的函数设置为slave的成员函数,并根据通信将程序划分为多个state。在slave 的成员变量中,使用一个栈来保存通信结束后下一步执行的函数指针以及state 值。通过set_continuation 来将函数指针和state 压栈,do_continuation 来将函数指针和state 出栈,并调用该函数。在每个state 开始时,我们取出函数中需要用到的局部变量和实参。在第一个state 的时候对局部变量进行初始化。实参的初始化发生在函数的调用处。

图2 MPI 风格示例通信函数Fig.2 Example of communication in MPI style
图2是一个MPI 风格的通信函数示例,在Some-Method 函数中,有全局通信global_communication。其中有实参parameter,有局部变量local_variable,这些变量都要跨越通信的。
图3是对应的Charm++表达方式。全局通信将SomeMethod 分成了两个部分。state 是Chare array 的成员变量,用于标识当前处理的状态。CharmSome-Method_param 是我们针对通信函数CharmSome-Method 引入的结构体,其中保存了该函数执行时需要的实参parameter、局部变量local_variable。
在state 为0 的时候,我们调用set_continuation 函数来指定在本次通信后需要执行的函数为Charm-SomeMethod 的下一个state,并调用init_XX_by_value来为局部变量分配内存。实参parameter 的初始化发生在CharmSomeMethod 被调用处。此后,我们通过CharmSomeMethod_param 获得parameter 和local_variable,并执行串行操作do_some_serial_job_1。鉴于通信函数global communication 需要传入local_variable 的引用,这里我们对global_communication_param 使用init_XX_by_ref 进行初始化,记录local_variable 的地址。在执行完global_communication 通信后,执行流到了CharmSomeMethod 的state1,再一次从CharmSomeMethod_param 中获得parameter 和local_variable 变量,执行串行操作do_some_serial_job_2。由于该函数已经执行到最后,可以释放CharmSome-Method_param 中的空间,并调用do_continuation,获取之前保存的下一步执行的函数和state。global_communication 内部实现与CharmSomeMethod 类似。

图3 Charm++风格示例通信函数Fig.3 Example of communication in Charm++ style
本文只对最基本的通信函数使用SDAG。这样对于调用层数较深处发生的通信,只需要提供基本通信的实现,无需将所有包含通信的函数都改写成SDAG 风格,可以较大程度减少代码修改量。至此,除基本通信函数外,所有的MPI 风格的同步通信逻辑都可以转化为Charm++异步通信的表示,且用户修改部分较少。
基本通信函数的实现将在下一节中介绍。
3.3 基本通信的实现
并行FMM 的通信发生在partition 和local essential tree 操作中,包括基本通信Alltoallv 与Allreduce。
Alltoallv 需要每个并行计算单元向其它并行计算单元发送不等长的消息,同时从其它并行计算单元中接收这些不等长的消息。Allreduce 需要对所有并行单元的某个参数进行规约。

图4 message 类型的定义Fig.4 Defination of message
在Charm++中,使用message 比参数序列化快[22],而且用户无需过多了解序列化知识。我们针对不同的类型,定义了对应的message 类型,如图4所示。其中,data 保存信息的本体,size 表示消息的大小,from 表示消息的发送者。

伪代码 1 Alltoallv 的 Charm++实现

serial {sendbuf, sendcount, sdispl = get_data_from (param)for i=0 to Chare_size do message = init_message (sendbuf, sendcount,sdispl)thisProxy[i].send_message (message)end for recv_cnt = Chare_size}while (recv_cnt --){when send_message (msg)serial{recvbuf, recvcount, rdispl = get_data_from (param)set_variable_from (recvbuf, recvcount, rdispl, msg)}}serial {do_continuation ()}
在实现Alltoallv 时,我们使用结构体来保存整个通信过程需要用到的变量。在serial 语句块中,每个Chare 构造消息并发送,同时触发等待消息的when 语句块,从消息中取出数据,放到缓冲区中。Alltoallv 的实现如伪代码1 所示,其中param 保存了alltoalv 调用时的参数,thisProxy 指Chare array 的代理,通过这个代理向自己发送消息。

伪代码2 Allreduce 在slave 上的实现
Allreduce 的实现包括规约和广播。首先在slave上获取到所有的规约数据,指定master 的处理函数来做规约。在规约结束后,master 发布广播消息,触发slave 的when 语句,master 和slave 的实现过程见伪代码2 与伪代码3。

伪代码3 Allreduce 在master 上的实现
3.4 负载均衡与迁移策略
大规模分布式并行系统上动态负载均衡,可以分成分布式、集中式和层次式三种[23]。
分布式策略只考虑相邻处理器,如Cybenko[24]等给出了扩散算法的一般化形式,处理器从高负载处理器中获取负载,并把负载给低负载处理器。Hui[25]等提出了基于水动力学的负载均衡,利用水的连通性特性来控制负载均衡。
集中式策略考虑全局负载,将信息集中到一个处理器上进行计算。如全局随机指派[26],贪心方法[26]等。
层次式负载均衡策略根据拓扑结构建立层次树。如HBM[27]根据网络结构将处理器划分成多个组,在层次结构的每一层都执行负载均衡迁移,直到根节点为止。
Charm++提供了在运行时移动Chare 的方法,使得处理器上的负载可以进行动态调节。本文中,我们利用MigrateMe 函数,使用集中式负载均衡策略,在运行时对slave 的Chare 进行迁移。
图5是负载均衡的实现时序图。slave 在某个阶段将自己包含的粒子信息发送到master 上。master负责对这些信息进行分析,经由负载均衡策略给出一个Chare 的重新分布,并依次通知相应的Chare。这些Chare 调用MigrateMe 函数来移动到新的PE 上,并向master 汇报迁移的结束。master 收到所有的迁移结束消息后,向slave 发起一个广播,使其继续执行计算。

图5 负载均衡时序图Fig.5 Sequence Diagram of load balance
本文中,负载均衡的执行时期为partition 结束时,此时所有的Chare 都已经拿到自己负责处理的粒子。为了简化负载均衡的实现逻辑,我们假设所有的处理器都是相同性能,仅考虑PE 的计算负载,并用PE 上的总粒子数来近似。
该负载均衡问题被称为相同并行机调度(Identical Parallel-Machine Scheduling)问题,属于NP-hard 问题[28]。本文中,我们采用最长处理时优先策略(Longest Processing Time,LPT)来求解,简述如下:
(1)将Chare 按照粒子数量从大到小排序
(2)依次将Chare 指派到当前粒子总数最少的PE 上。
该策略可以达到4/3 近似[28],即对于该问题的所有情况,近似策略都能给出最优解4/3 倍以内的可行解。
3.5 实现技术
上述message、Alltoallv、Allreduce 等需要针对不同类型实现。此外,对于每个通信函数,都需实现一个XX_param 的结构体,其成员函数需要覆盖到在通信中使用到的变量,且应当区分by_value 和by_ref。在通信函数的最开始部分,都需要获得全部的XX_param 结构体成员。这些代码都是相似的,可以使用脚本语言生成。
本文将需要生成的类型参数写成json 的格式,通过Python 脚本解析,基于模板自动生成了message、基础通信函数、XX_param 结构体的C++代码片段和宏定义。在并行FMM 源码中只需在对应的地方引入这些宏定义即可,无需大量修改源码。
主要的实现流程包括:
(1)全局变量局部化;
(2)基于通信划分state;
(3)Python 脚本生成C++代码片段;
(4)调整通信函数内部风格;
(5)在通信函数中引入XX_param 等代码。
4 数值结果
以下测试均在中国科学院计算机网络信息中心超级计算机“元”上进行测试。每台刀片计算节点配置 2 颗 Intel E5-2680 V2(Ivy Bridge | 10C | 2.8GHz)处理器,64 GB DDR3 ECC 1866MHz 内存。编译环境为Intel Composer XE 2013 编译器,Charm++ 版本为6.6.1,编译时使用-O3 优化选项和C++0x 标准。
4.1 正确性检验
为了验证FMM 的Charm++实现正确性,我们选择了不同分布与参数进行测试,比较了Charm++与MPI 下每个粒子的受力值,结果完全一致,这表明我们的计算精度和已有的MPI 实现的精度相同。
4.2 性能检验
以16384 万个粒子为例,采用均匀的立方体分布作为粒子的初值分布,分别对MPI 和Charm++实现进行测试,保证Chare 数量和PE 数量相等(即不使用过分解),结果如图6所示。可以看出,随着处理器规模从32 核增加到1024 核,两种实现的速度基本接近,Charm++实现相比MPI 实现在千核规模上有提升。
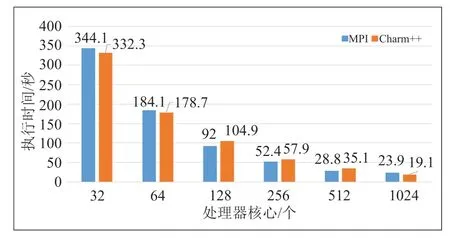
图6 16384 万粒子的执行时间Fig.6 Execution time of 163,840,000 particles
在上述测试中,以32 核规模的执行时间作为基准,计算了Charm++和MPI 版本的加速比,结果如图7所示。可以看出,与理想情况相比,FMM 的Charm++实现在256 核以下的强扩展性能较好。随着核数增加到千核规模,全局通信会扩大,扩展性有一些下降。与MPI 实现相比,Charm++实现在1024 核规模的加速效果较好,但在64 核至512 核规模的加速效果较为逊色。这一现象是因为千核规模下,通信占比增大,而MPI 实现使用全局通信,在partition 阶段的通信时间远大于使用点对点通信的Charm++实现。
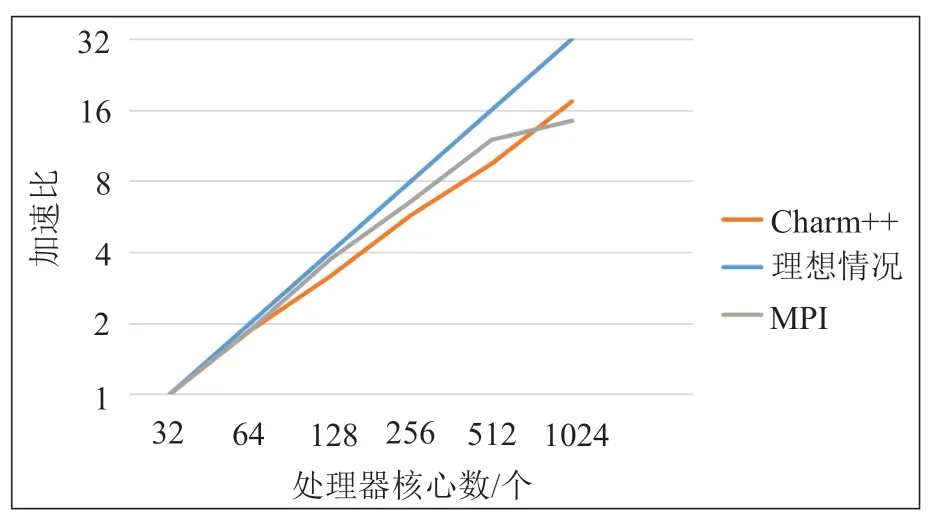
图7 并行 FMM 的加速比Fig.7 Speedup ratio of different implementations
为了验证过分解对负载不均衡情况的优化效果,本文针对65536 万粒子的球壳状不均匀分布,固定处理器数量为64,调整每个处理器上的Chare 数量,从64 增加到512,进行了测试。我们统计了每个处理器上的总粒子数Ni,并计算了所有处理器上的极差(Nmax-Nmin)和标准差
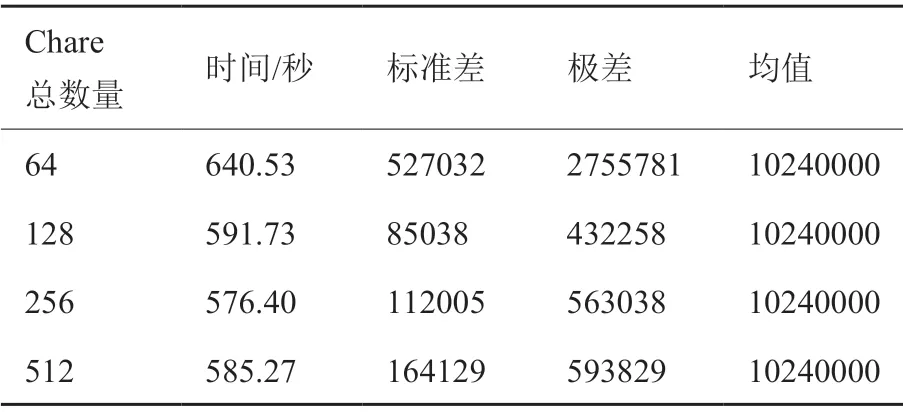
表1 过分解测试结果Table 1 Result of over-decomposition
测试结果如表1所示,在不使用过分解的情况下,可以看出粒子分布的标准差和极差较大。随着Chare 数量增加,LPT 负载均衡策略降低了标准差和极差的数量级,也减少了计算时间。最优情况在使用256 个Chare 时取得,与不采用过分解的情况相比,减少了10%的计算时间。上述结果表明,过分解和负载均衡策略对粒子分布不均匀下的FMM 计算有一定优化效果,可以平衡不同处理器上的计算负载。
5 总结与展望
本文基于Charm++并行编程框架,实现了并行FMM 程序。首先分析了FMM 的并行实现关键和主要通信,介绍了Charm++并行编程环境。在并行实现的过程中,本文讨论了MPI 编程模型和Charm++编程模型的异同,引入了用异步模型表示同步计算的一般性方法,给出了一个通用的MPI 并行程序向Charm++转化的流程,并针对基本通信函数给出了SDAG 的实现方案。最终,本文在“元”超级计算机上对FMM 的Charm++实现进行了检验与测试。结果表明,基于Charm++实现的FMM 具有较好的扩展性,针对负载不均衡的情况,过分解和LPT 负载均衡策略可以减少10%的执行时间。
文本中实现中只利用了Charm++提供的Chare array 类型,即把每个Chare 看作一个独立且内存不共享的个体。如何使用Charm++提供的逻辑节点与本地存储来减少通信量,提高并行效率,将是未来的一个尝试方向。另一方面,本文在负载均衡时仅考虑了PE 上的总粒子数,且假定计算负载与粒子数成正相关,不一定反映了真实的负载情况。因此,使用更贴近FMM 的负载均衡指标也是一个可以考虑的方向。
针对目前高性能计算系统广泛使用异构计算的情况[29],本文提供的Charm++实现也具有一定适应性。只需声明一组绑定PE 的Charm group,在其中执行耗时的P2P 与M2L 操作。异构加速与具体体系结构有关,涉及内容较多,故本文仅提供接口。
利益冲突声明
所有作者声明不存在利益冲突关系
猜你喜欢
娃娃乐园·绘本(2021年4期)2021-04-28 03:06:10
商品与质量(2019年34期)2019-11-29 03:25:51
测控技术(2018年5期)2018-12-09 09:04:46
小学生必读(高年级版)(2017年4期)2017-08-31 12:30:25
信息安全研究(2016年4期)2016-12-01 06:07:05
中国舰船研究(2015年2期)2015-02-10 06:45:47
中国煤层气(2014年3期)2014-08-07 03:07:39
小说月刊(2014年9期)2014-04-20 08:58:07
小说月刊(2014年5期)2014-04-19 02:36:43
中国信息化·学术版(2013年1期)2013-05-28 05:53:24
