
基于知识图谱的抗疫意见领袖热点话题检测与分析
2020-12-01 03:15任东亮林绍福黄鸿发付钰
软件导刊 2020年10期
任东亮 林绍福 黄鸿发 付钰

摘 要:新型冠状病毒(COVID-19)疫情爆发期间,涌现出了众多的抗疫意见领袖。通过对意见领袖话题传播和演化进行分析研究,可以为网络舆情治理和疫情防控提供理论和知识支撑。采用N-Gram语言模型和Shingling相似度算法相结合的方式进行话题检测,再通过Neo4j图数据库存储与检索意见领袖、话题、事件等多维实体特征,构建以意见领袖为核心的话题图谱。实验结果表明,话题准确率达82.3%,召回率达81.6%,与传统Single-Pass聚类相似度算法相比均有所提高。通过对图谱分析,能够简单直观地展示出不同实体间多维舆情关系。同时,可以提高检索速度和分析效率,符合舆情传播客观规律。
关键词:新冠疫情;意见领袖;网络舆情;知识图谱;话题分析
DOI:10. 11907/rjdk. 201625
中图分类号:TP301 文献标识码:A 文章编号:1672-7800(2020)010-0020-05
Abstract:Many anti-epidemic opinion leaders emerged during the outbreak of COVID-19 period. Through the analysis and research on the topic dissemination and evolution of opinion leaders,it can provide theoretical and knowledge support for network public opinion governance and epidemic prevention and control. This paper first uses the combination of N-Gram language model and shingling similarity algorithm for topic detection. Then by storing and retrieving the multi-dimensional entity characteristics such as opinion leaders, topics, events and so on, Neo4j graph database is used to build topic graph with opinion leaders as the core. The results show that topic accuracy reaches 82.3% and recall rate 81.6%, which are improved compared with the traditional Single-Pass clustering similarity algorithm.Through the analysis of the Graph, the multidimensional public opinion relationship between different entities can be displayed simply and intuitively.At the same time, it can improve the retrieval speed and analysis efficiency, and conform to the objective law of public opinion dissemination.
Key Words: COVID-19 epidemic; opinion leader; network public opinion; knowledge graph; topic analysis
0 引言
抗疫意見领袖是指在疫情中作出贡献,并且在社交媒体平台上能够因传播信息和表达意见而影响多数人态度倾向的公众人物。他们通过积极制造或参与话题,引起网友的关注和讨论,从而产生较大影响力[1]。新型冠状病毒 (Corona Virus Disease 2019,COVID-19)疫情爆发并迅速蔓延,在这一突发公共卫生事件背景下,涌现出了众多的抗疫意见领袖,如钟南山、马云、韩红等。他们发表的观点具有强大的舆论号召力,他们本人也成为此次疫情事件中的意见领袖。在微博平台上,网民们对意见领袖的话题及相关热点事件发表自己的意见和看法,从而产生海量的文本信息。从这些文本信息中进行话题挖掘抽取,可以了解网民对突发公共卫生事件的观点,探索事件发展全过程的舆情演变规律。充分利用文本信息、发挥网络平台民意采集作用,可以预测突发公共卫生事件宏观发展走向,对协助网络舆情引导具有重要意义[2]。
在大数据环境下,传统话题分析技术的应用远远不能满足网络舆情管理实际需要,因此必须开拓创新,研究更为科学的知识组织技术和智能知识处理技术[3]。知识图谱具有结构规范、语义丰富以及支持高效查询和复杂知识计算等特点,能够为舆情主题发现、热点跟踪、影响分析、传播分析等提供有力支持[4-5]。从我国疫情防控阶段和舆情发展特点分析,2020年1月中旬至3月底是疫情防控的关键阶段,舆情爆发,互联网上充斥着各种各样的观点,对该时期舆情数据分析有重要意义。本文采用网络爬虫技术,从中国最大的社交媒体——新浪微博采集1月20日—3月25日共66天不同领域影响力较大且有一定代表性的10位抗疫意见领袖的文本信息。通过对这些信息中的短文本非结构化数据进行话题检测,再与结构化数据结合,进行语义关系设计,构建出针对抗疫意见领袖的热点话题舆情知识图谱。完成图谱构建后,从意见领袖、话题影响力和基于时间的话题走势3方面进行话题分析。本文研究能为有关机构应对突发公共卫生事件和网络舆情有效治理提供参考。
1 相关研究综述
1.1 话题检测与分析
1996年,美国国防高级研究计划局(DARPA)迫切需要一种能够实现新闻数据流话题判断的全自动技术,于是话题检测与跟踪技术的概念应运而生[6]。一种方法是基于LDA主题模型或者改进的LDA主题模型,通常是将文档理解为多个隐式主题的组合,这些主题由文档中的特定词汇表示;另一种是基于改进聚类算法的话题检测。其中,增量聚类是有效的文本数据流聚类算法,而Single-pass单向聚类算法是最简单和应用最广泛的算法。基于分层聚类的K-means算法是简单实用的分区聚类算法,但是K值和初始聚集中心点的选择是K-means算法的关键和难点。根据主题的周期性特点,饶浩[7]介绍了基于时间窗的原始指标,并基于主成分分析和两层隐层BP神经网络对微博主题舆情进行分析;黄贤英等[8]利用微博短文的发布、转发和评论时间等信息实现其语义相似度修改,形成一种新的多维微博短文本相似度算法。基于对相关话题提取算法的分析研究,本文采用N-Gram语言模型和Shingling相似度算法相结合的方式,实现了微博话题检测。
1.2 舆情领域的知识图谱研究
知识图谱(Knowledge Graph)最初由Google[9]提出,这项技术使得其搜索服务更加智能化。此后,学术界和企业界纷纷跟进,使得该技术在智能搜索、情报分析、自动问答等领域的应用显示出强大优势。在舆情领域,Kim等[10]提出一种基于知识图谱可视化工具的社交网络舆情挖掘方法,他们以韩国方便面事件为例,验证了该方法可用于社交网络舆情分析,成为采用知识图谱分析热点事件的开端;Chen等[11]利用BICOMB和SPSS软件,收集了1986-2016年中国知网290篇教学论文,构建出热点问题和发展趋势主题图谱,并参与舆情调查研究,为查阅教学文献提供了方便的可视化图谱。在分析网络舆情信息组织技术的基础上,国内学者如娄国哲等[12]给出网络舆情知识图谱结构的定义,分析网络舆情管理知识需求,阐述网络舆情知识地图构建方法,提出基于知识图谱的网络舆情知识组织结构;马哲坤等[13]通过突发词项筛选、突发事件话题图谱构建、语义补充和改进,提出基于知识图谱进行网络舆情突发事件主题内容监控,有效地提高了网络舆情监测的准确性和全面性,使知识图谱技术运用得到进一步发展。通过以上文献可以得出,大部分舆情知识图谱是基于文本构建研究,关于以人物为研究对象的网络舆情知识图谱较少。本文通过构建以意见领袖为核心的知识图谱,结合疫情期间的热点话题进行分析,为网络舆情治理和疫情防控提供理论和知识支撑。
2 热点话题检测与图谱构建
2.1 博文话题检测
本文主要采用N-Gram语言模型和Shingling相似度算法相结合的方式,实现微博话题检测。微博数据本质上是一系列独立的短文本,每个文本中的单词数通常不超过140字,并且文本可能包含一些特殊的格式,表示公共主題和用户之间的交互关系。例如“@user”、“rt”表示转发、“# subject #”表示参与某个特定主题的讨论。同时,文本还具有一些其它属性,例如发布者的发送时间、来源、地理信息和用户信息等。本文使用NLPIR-ICTCLASE中文分词系统对每个微博文本进行分词,以删除文本中的停用词。单词分割效果如图1所示。
处理停用词后,进行N-Gram处理,该处理涉及由N个单词组成的集合。各单词不仅具有先后顺序,而且允许单词相同[14]。N-Gram模型根据条件概率式(1)和乘法式(2)得到推导式(3)。
其中,P表示由n个词组成的句子,每一个单词wi都要依赖于从第一个单词w1到它之前一个单词wi-1的影响。将每条微博转换成若干词语集合,每个集合中包括从该集合的起始词语开始,连续出现的n个词语。每个集合的起始词语不同,第i个集合的起始词语是原文本中第i个词语。
每条微博经过处理后,任意两个微博文本之间的相似度R(A,B)都是用Shingling算法计算而来,并将相似度大于阈值E(0.6)的微博文本都放入同一个文本簇中,如式(4)所示。
其中,S(A)表示微博A的若干词语集合,[|S(A)?S(B)|]表示S(A)和S(B)的交集中包含的词语集合数量,[|S(A)?S(B)|]表示S(A)和S(B)的并集中包含的词语集合数量。通过以上方法,统计每个文本簇所有微博文本的词语出现在话题词典中的数量,将每个文本簇划分到出现的词语数量最多的一类话题中。基于对微博中话题影响力最大的前7个热点话题共500条微博分析,本文采用DT会议制定的比较规范的话题检测评价标准[15],经过实验,准确率达82.3%,召回率达81.6%,与传统Single-Pass聚类相似度算法[16]相比,准确率和召回率均有所提高,如表1所示。
2.2 抗疫意见领袖话题知识图谱构建
分析已有文献可知,大部分知识图谱是基于文本构建研究,关于结合突发公共卫生事件并且以人物为研究对象的网络舆情知识图谱较少,因此以该突破点出发展开研究。知识图谱从逻辑上分为模式层和数据层两部分[17]。其中,模式层是知识图谱的核心,主要存储经过提炼了的疫情语义知识结构,通过本体库管理这一层;数据层存储的是具体实体和关系数据信息,本文存储在Neo4j图数据库中。
2.2.1 模式层构建
模式层建立在数据层之上,是知识图谱的核心,模式层通常使用本体进行管理。本体是结构化知识库的概念模板,所形成的知识库不仅具有层次性,而且冗余度较小。抗疫意见领袖热点话题图谱是指在新型冠状病毒疫情突发公共卫生事件下以意见领袖为研究对象的语义知识结构库和舆情事件库,其基本组成单元是<实体,关系,实体>、<关系,属性,属性值>和<实体,属性,属性值>三元组。其中定义了4种实体类别:话题、用户、事件、意见领袖。模式层中定义的每种实体属性如表2所示。
通过对定义好的实体进行研究,得到<事件,属于,话题>、<用户,发布,事件>、<意见领袖,参与,事件>、<意见领袖,包含,话题>4种实体关系,如图2所示。其中,圆形表示实体类别,连线表示实体类别关系。
2.2.2 数据层构建
本文通过新浪微博的公共数据接口爬取2020年1月20日-3月25日来自医疗专家、社会名人、政府官员3个不同领域博文影响力较大的10位抗疫意见领袖相关的 4 795件热点事件和2 080位微博用户信息。图数据库相较于传统的RDF存储具有查询效率高、搜索快和直观简单等优点,故在存储上选择开源的Neo4j数据库,在平台构建上选择SDN(Spring Data Neo4j),它是开源Spring数据项目的一个子项目。其提供了将带注解的实体类映射到Neo4j数据库的高级功能,为与关系图的交互提供了基础,还可用于高级仓库支持。
设计好实体类别和实体关系后,通过Springboot开发框架和Neo4j图数据库相结合的方式进行数据存储,设计意见领袖热点话题舆情知识图谱并构建平台。基于微博爬取的全部数据,共构建8 387个实例,16 497条关系边。如图3所示,考虑到图谱展示效果,本文截取以韩红、钟南山、马云等5位意见领袖为核心的舆情话题图谱部分结构。其中,不同灰度色和大小的圆形节点代表了不同的实体类别,连线代表了节点之间的关系,整体直观地描述出以抗疫意见领袖为核心的热点话题事件传播过程。
3 抗疫意见领袖热点话题演化分析
关于舆情话题演变,从现有文献看,陈婷等[18]提出基于时间序列话题的网络舆情热点话题演化分析方法,通过添加时间序列标签,直观分析舆情热点话题内容和强度的演化过程。从情感分析角度出发,何天祥等[19]提出一种采用情感分析的网络舆情演变分析方法。因此,本文在前人研究基础上,在Neo4j图数据库中通过Cypher查询语言与相关算法相结合的方式对知识图谱进行分析,以把握疫情突发公共卫生事件下网络话题舆情发展趋势,进而了解事件发展过程[20-22]。
3.1 意见领袖人物分析
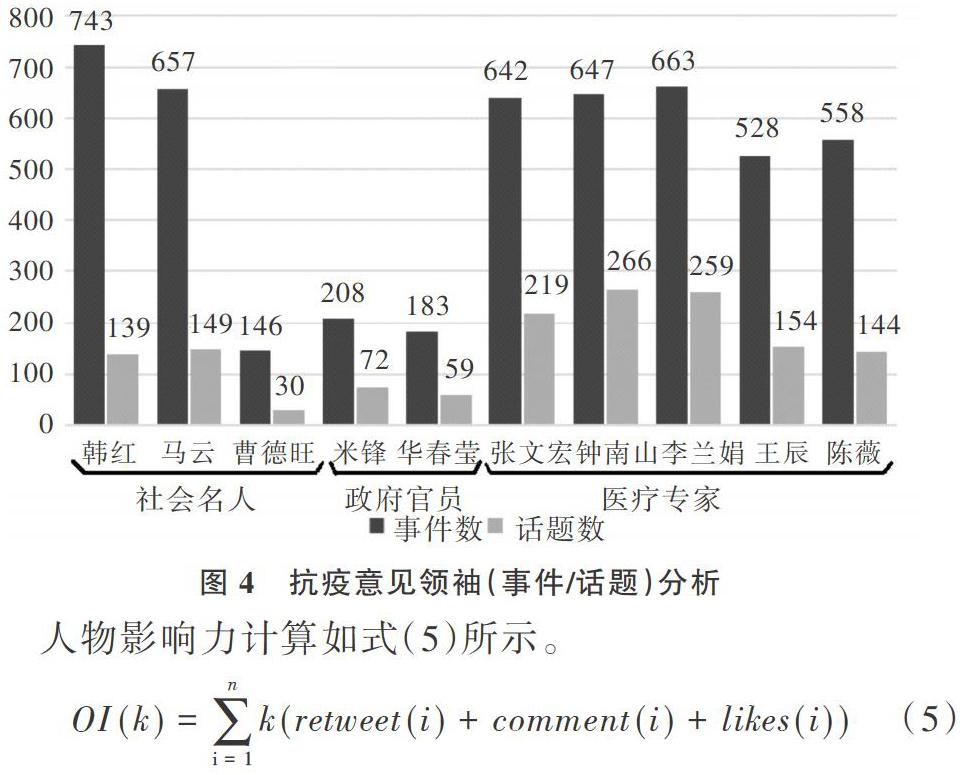
此次新冠疫情突发事件中产生了众多的抗疫意见领袖,如钟南山、马云、韩红等。他们发表了具有强大舆论号召力的观点,成为此次疫情事件中的热点人物。通过对意见领袖、事件、话题三者关系进行Cypher查询统计分析,得到各领域意见领袖的事件报道数量和话题数量,如图4所示。其中,抗疫科学家钟南山参与的事件有647件,引起266条话题讨论。歌唱家、慈善家韩红参与的事件数有743之多,引起139条话题讨论。
人物影响力计算如式(5)所示。
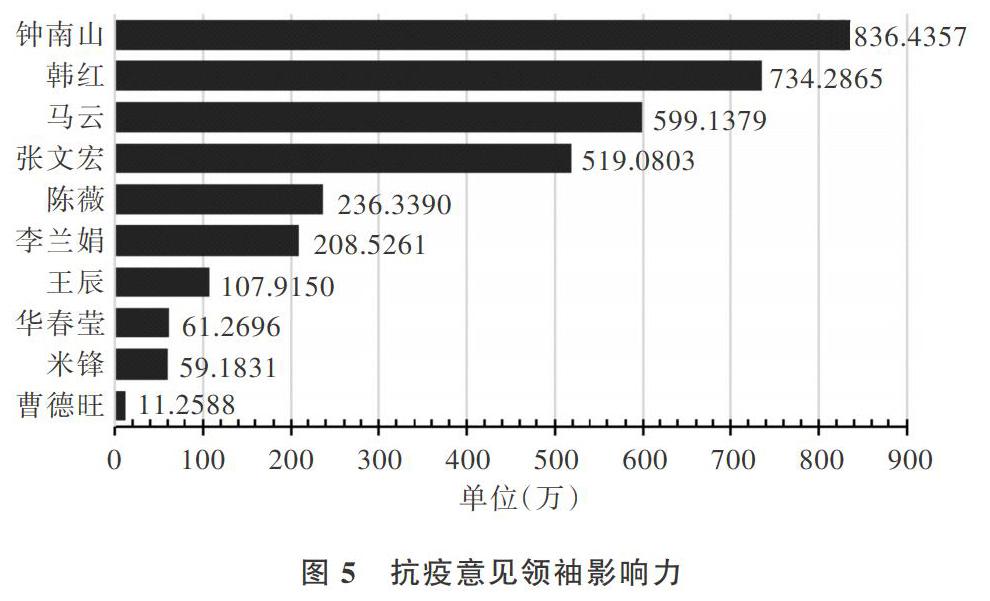
与通过Cypher查询统计分析意见领袖、事件、事件属性三者关系相结合的方式,可以计算出每位意见领袖的抗疫影响力。其中,i表示与意见领袖k相关的事件,retweet(i)表示第i件事轉发数之和,comment(i)表示第i件事评论数之和,likes(i)表示第i件事点赞数之和。将所有事件的影响力求和,可以得到如图5所示的抗疫意见领袖排行榜,可以看到钟南山的抗疫影响力达836万之多,位居榜首。
3.2 热点话题影响力分析
经过初期的话题检测后,共提取到1 323个话题。通过对检测到的话题进行排名,可以快速从大量的话题中检测到抗疫热门话题,有利于网络舆情治理。提取不同话题包含的所有事件实体,话题热度计算如式(6)所示。
与通过Cypher查询统计分析话题、事件、事件属性三者关系相结合的方式,可以计算出话题中每一条原始微博的影响力。其中,w(label(z))表示z文本簇中话题类别对应的权重,retweet(z)表示z文本簇中所有微博文本的转发数之和,comment(z)表示z文本簇中所有微博文本的评论数之和,likes(z)表示第z个文本簇里所有微博文本的点赞数之和。构建的意见领袖热点话题影响力排行榜如图6所示,本文选取前15个热点话题,其中“终南山全程英语分享中国经验”这个话题以164万多影响力位居榜首。
3.3 基于时间的热点话题走势分析
本文选取“韩红爱心驰援武汉”这个热点话题进行分析。通过在图谱中对话题、事件、事件属性三者关系进行Cypher查询统计分析。提取该话题不同时间段包含的所有事件实体的评论、转发、点赞、时间、内容和其它属性,在此基础上,根据上述话题热度计算式(6)计算话题影响力,得出一段时间舆情事件发展过程中话题出现阶段和话题讨论热度等多维特征。如图7所示,本文将舆情事件按潜伏期1月21号—2月11日、爆发期——2月11号—2月25日、衰退期2月25日—3月22日这3个阶段进行话题讨论分析。从话题影响看,在潜伏期内,话题讨论热度不高,影响力较小;随着事件的传播,进入舆论的爆发期,话题影响力呈现显著增加,该时期的舆论事件也受到了很多关注和转发;当处于衰退阶段时,话题影响力逐渐减弱,且这一时期持续最长。
4 结语
随着大数据时代的到来,构建一个准确、完善、实时更新的知识图谱仍然面临诸多挑战。本文通过微博数据采集、话题检测构建抗疫意见领袖热点话题知识图谱,能够简单直观地展示出疫情期间意见领袖、话题、事件等多维舆情关系,同时可以提高检测速度和分析效率,符合舆情传播客观规律,实现较为满意的分析效果,有助于舆情监控相关部门在疫情防控期间的舆情分析与网络治理。
本文基本完成了预期的图谱分析效果,但依然存在以下不足:本文只是从微博上采集抗疫意见领袖热点事件,后期可以从多数据源获取,使图谱分析实验结果更加准确;在话题检测上,本文选择了目前效果相对较好的算法,但是微博文本内容长度短、表达随意、非规范化等特点致使文本向量高维且有效特征稀疏,后续研究中可对相关算法作出改进。本文构建的舆情知识图谱可用于新冠疫情舆情监测和引导等相关研究。
参考文献:
[1] 罗莉,周婷. 意见领袖对网络舆情的作用[J]. 新闻战线,2016,61(8):26-27.
[2] 刘雅姝,张海涛,徐海玲,等. 多维特征融合的网络舆情突发事件演化话题图谱研究[J]. 情报学报,2019,38(8):798-806.
[3] 王兰成,娄国哲. 基于知识图谱的网络舆情管理方法与实践研究[J]. 情报理论与实践, 2020,43(6):97-101.
[4] 王晰巍,韦雅楠,邢云菲,等. 社交网络舆情知识图谱发展动态及趋势研究[J]. 情报学报,2019,38(12):1329-1338.
[5] 袁立庠. 微博的傳播模式与传播效果[J]. 安徽师范大学学报,2011,55(6):678-683.
[6] 张仰森,段宇翔,黄改娟,等. 社交媒体话题检测与追踪技术研究综述[J]. 中文信息学报,2019,33(7):1-10,30.
[7] 饶浩,陈海媚. 主成分分析与BP神经网络在微博舆情预判中的应用[J]. 现代情报,2016,36(7):58-62,70.
[8] 黄贤英,陈红阳,刘英涛. 短文本相似度研究及其在微博话题检测中的应用[J]. 计算机工程与设计,2015,36(11):3128-3133.
[9] SINGHAL A. Introducing the knowledge graph: things, not strings[Z]. Official Google Blog,2012.
[10] KIM Y,JEONG S R.Opinion-Mining methodology for social media analytics[J]. KSII Transactions on Internet and Information Systems,2015,9(1):391-406.
[11] CHEN X D,SUN Y,HE T Z. Historical retrospect and future prospect of research on effective teaching in China——knowledge map‐ ping analysis based on the research over the past three decades (1986-2016)[J]. Advances in Higher Education,2018,2(2):1-10.
[12] 娄国哲,王兰成. 基于知识图谱的网络舆情知识组织方法研究[J]. 情报理论与实践,2019,42(1):58-64.
[13] 马哲坤,涂艳. 基于知识图谱的网络舆情突发话题内容监测研究[J]. 情报科学,2019,37(2):33-39.
[14] 周水庚,俞红奇,胡运发,等. 基于N—gram信息的中文文档分类研究[J]. 中文信息学报,2001,16(1):34-39.
[15] 洪宇,张宇,刘挺,等. 话题检测与跟踪的评测及研究综述[J]. 中文信息学报,2007,22(6):71-87.
[16] 李倩. Single-Pass聚类算法的改进及其在微博话题检测中的应用研究[D]. 济南:山东师范大学,2016.
[17] 林萍,黄卫东. 基于LDA模型的网络舆情事件话题演化分析[J]. 情报杂志,2013,32(12):26-30.
[18] 陈婷,王雪怡,曲霏,等. 基于时序主题的网络舆情热点话题演化分析方法[J]. 华中师范大学学报(自然科学版),2016,50(5):672-676.
[19] 何天翔,张晖,李波,等. 一种基于情感分析的网络舆情演化分析方法[J]. 软件导刊,2015,14(5):131-134.
[20] SOHN D,GEIDNER N. Collective dynamics of the spiral of silence:the role of ego-network size[J]. International Journal of Public Opinion Research,2016,28(1):25-45.
[21] BLEI D M,NG AY,JORDAN M I. Latent Dirichlet allocation[J]. Journal of Machine Learning Research,2003(3):993-1022.
[22] 王义真,郑啸,后盾,等. 基于SVM的高维混合特征短文本情感分类[J]. 计算机技术与发展,2018,28(2):88-93.
(责任编辑:孙 娟)
猜你喜欢
新丝路(下旬)(2020年4期)2020-04-23
中小学心理健康教育(2020年10期)2020-04-13
新闻界(2016年13期)2016-12-23
新教育时代·教师版(2016年27期)2016-12-06
今传媒(2016年10期)2016-11-22
中国教育信息化·基础教育(2016年9期)2016-10-18
