
基于人工智能的计算机大数据安全技术平台构建
2020-11-30 06:54李咸宁
科学技术创新 2020年34期
王 俊 李咸宁
(军委后勤保障部信息中心,北京100842)
二十一世纪以后,移动互联网和云平台技术的飞速发展,使得数据规模也随之快速增长,现代社会经济的发展已然进入大数据时代[1]。人工智能重点主要集中在对人的逻辑思维、认知意识进行研究,并把人的行为通过数学运算与分析实现机器模拟[2]。海量数据的聚合,一方面提高了用户在隐私泄露方面的危险,大数据内隐含的庞大信息量和潜在市场也吸引众多的网上非法分子的攻击。另一方面大数据在学科应用上多表现跨学科整合应用,内部引进了很多新技术,这在很大程度上会加大大数据在技术和管理上的风险程度。所以,引导大数据内各个角色有序提高数据管理水平,保证大数据服务提供商在符合安全规范的前提下进行高效分析与服务,都是现今亟需解决的重要问题。
1 网络安全数据采集
针对安全技术平台中对网络安全漏洞数据的具体要求,平台必须做好网络安全漏洞数据的采集,确保漏洞数据采集工作可以为安全技术平台提供全方位、立体化、实时精准的服务。采集流程图如图1 所示。

图1 采集流程图
有关漏洞数据的采集目标,通常视为多个网站内的漏洞数据库所编录的全部漏洞数据。数据采集工作中,我们有必要按照各个网站的不同特征,通过随机分配IP 地址、网络代码、用户代理、浏览器等技术,有效规避部分网站对爬虫行为的爬墙[3]。按照平台对漏洞数据安全性、时效性的标准,我们必须着重对数据采集关键程序进行优化升级,定时定期重启模块工作任务,以确保平台数据库内的漏洞数据永远处于更新状态。
爬虫程序在Scrapyd 指引下,为整个平台提供了JSONAPY的方式对爬虫程序进行实时监控。在漏洞网页数据的爬取上,一般会采取队列式的爬取方式。首先对一个初始种子进行事先定义,之后按照网站漏洞数据的不同构造设计出相对应的队列算法。队列内容以网页内的URL 数据为主,最后利用爬虫引擎的下载功能,结合反爬虫对抗技术完成网页数据的下载进库。整个操作过程中,必须将网页数据和定制关键字相对比,以便采集符合关键字搜索有关数据,确保漏洞数据采集工作的准确率。
2 数据特征提取与脱敏
数据维度偏高会造成计算步骤过于复杂或计算时间叠加,不相联的维度特征甚至会造成平台的精确度下降。缓解维度困难的一个关键路径就是降维,即将高维特征中的冗余或互相之间不联系的数据排除,达到降低噪音的目的,实现从原始数据集合中提取关键特征以降维。按照计算逻辑进行探究性分析与初步认定后,对有关性矩阵图进行准确绘制,计算有关系数对其进行显著性验证,通过主体分析、线性区别分析、因子分解等方法对数据特征进行检索、评价、检验、分析,从中筛选出和目标互联性较强的特征。数据特征提取如图2 所示。

图2 数据特征提取
数据脱敏一般有随机法、匿名法、关联规则隐藏法等可供选择。出于保护隐私的需求以及对数据安全的要求,数据脱敏必须综合多种情况,结合诸多方法。因此,本文选择将匿名法与关联规则结合,这在很大程度上既可以保护用户敏感信息,同时还可以有效避免网络非法用户利用数据关联规则对个人隐私数据的反向攻击。比如,数据K 匿名和关联规则隐藏相结合就业在完成K 匿名的同时,实现隐藏关联规则的目的,从而更好地完成数据脱敏。
3 身份认证与精细化访问控制
在计算机网络安全保护之中,身份认证与加密是最普遍的方法,身份认证就是利用对计算机网络用户身份的确认而随之产生的有效方法。加密技术一般视为比较普遍的安全保密方法,通过计算机技术将比较重要的数据进行加密后再传输,到达指定IP 后再以一种相同或类似的手段对其解密。用户身份认证图如图3 所示。
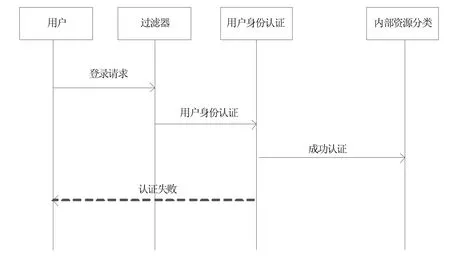
图3 用户身份认证
大数据安全技术平台主要是以网址的方式接受用户的访问请求,所以每一个用户在大数据安全技术平台内的身份均相同,都是代理网址的临时身份,可是这对于身份权限的管理来说会造成平台无法完全区别不同用户之间在权限使用上的不同。本文设计的平台采取的方法就是将用户的认证身份与授权身份完全分离开来,保证访问平台的均为合法用户。以授权身份对认证用户的访问授权时,保证认证后的操作具备一定的合法权限。
大数据处理必须遵守国家有关制度和法律法规的具体要求,同时还需要遵守安全策略、隐私策略等协议。这些均对数据平台的访问控制提出更高水平的要求。为高效解决此问题,可以采取属性加密的方式对加密数据的灵活性进行灵敏度共享,并降低密钥管理成本和时间。大数据安全技术平台在运行时需要借助复杂的计算环境,用户对数据访问安全性的类型上也面临多样性。针对大数据安全技术平台的数据访问要求和特征,可以在访问控制的基础上完成大数据安全技术平台对数据的安全应用与灵敏共享,利用主客体属性细粒度访问控制的授权方法对用户在共享数据的应用上进行灵活设定,从而实现数据细粒度使用上的安全。同时还可以对大数据访问有关的主/客体、参数指标等进行机动灵活的配置,将对涉密数据的实时访问、隐私事件的发生顺序、数据资源的修改次数等进行精准记录,从而为不法工会、违规处理等突发事件的解决提供一个综合的、完整的、安全的分析控制。
4 实验与效果分析
为了更加清楚、具体的看出本文提出的基于人工智能的计算机大数据安全技术平台的实际效果,特与传统的计算机大数据安全技术平台进行对比,对其隐私泄露风险的大小进行比较。
4.1 实验准备
实验环境总共包含3 台服务器,其中大数据安全技术平台部署在总服务器上,大数据平台则部署在服务器2 和服务器3上。大数据安全技术平台所在服务器一般包含两大IP,一个外网、一个内网。外网IP 通常只对用户显示可见,用户可以利用该IP 地址对大数据安全技术平台进行访问,而内网IP 则划分为大数据安全技术平台和大数据平台间的通信IP。平台部署总服务器 的IP 地 址 为10.59.14.211, 服 务 器2 的IP 地 址 为10.59.13.223,服务器3 的IP 地址为10.59.13.252。
为保证试验的准确性,将两种计算机大数据安全技术平台设计置于相同的试验环境之中,进行隐私泄露风险的试验。
4.2 实验结果分析
试验过程中,通过两种不同的计算机大数据安全技术平台设计同时在相同环境中进行工作,分析其隐私泄露风险的变化。隐私泄露风险度对比如图4 所示。
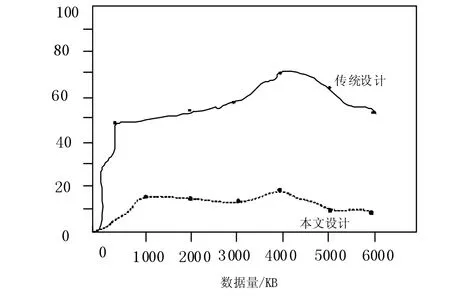
图4 隐私泄露风险度对比
图4 结果表明,本文提出的基于人工智能的计算机大数据安全技术平台相比于传统平台设计,在隐私泄露风险上能够最大限度地保证隐私不被外泄,维护用户信息安全。传统平台中存在诸多问题,基于本论文提出的大数据安全技术平台安全可以有效对底层数据进行保护,可以满足绝大部分场景对安全的现实需求。
5 结论
对基于人工智能的计算机大数据安全技术平台进行分析,传统的数据安全技术早已经无法满足大数据时代下对数据安全的现实需要,大数据平台的数据安全、隐私保护等都均面临着新挑战。依托人工智能的技术要求,在大数据应用背景下,根据计算机大数据的安全需求,对平台设计及时进行调整。希望本文研究内容可以为解决大数据安全等技术性问题上提供一些专业的技术参考和方法指导。
猜你喜欢
今日农业(2022年13期)2022-09-15
自动化与仪表(2022年5期)2022-01-01
电子制作(2019年14期)2019-08-20
电子制作(2019年11期)2019-07-04
当代贵州(2018年21期)2018-08-29
时代英语·高二(2017年4期)2017-08-11
学生天地·小学中高年级(2017年5期)2017-06-09
红领巾·成长(2016年10期)2017-05-10
电子制作(2017年20期)2017-04-26
儿童时代(2016年6期)2016-09-14
