
一种基于数据的GitHub项目个性化混合推荐方法
2020-11-26 00:36:34何锴琦马宇骁刘华虓
吉林大学学报(理学版) 2020年6期
何锴琦, 马宇骁, 张 炎, 刘华虓
(1. 吉林大学 研究生院, 长春 130012; 2. 美国东北大学 工程学院, 美国 波士顿 02115;3. 吉林大学 计算机科学与技术学院, 长春 130012)
GitHub是目前知名的软件项目托管平台之一, 在该平台上开发人员可通过账户共享自己创建(Create)的项目、 派生(Fork)他人的项目或关注(Watch)其他开发者的项目. 其提供了搜索功能, 在不提供任何自动建议的情形下允许用户对平台中的项目进行手动检索. 传统的搜索引擎通常侧重于对检索内容的文本匹配, 但对于开源软件代码库的用户, 搜索合适的项目是一项困难的任务: 一方面, 用户通常很难用几个关键词准确地描述软件项目的特征, 导致难以获得理想结果,此外, 由于搜索结果较多, 待选项目的质量通常参差不齐, 只能依靠星级等有限评价体系; 另一方面, 由于不同项目的参与难度不同, 会导致缺乏经验的新用户无从下手. 因此, 如何利用数据分析方法, 根据不同用户的专业方向和专业水平的差异, 提供个性化项目推荐方法研究已成为目前的热门问题[1].
本文基于内存的协同过滤方法, 提出一种基于数据的面向领域入门的GitHub项目个性化混合推荐方法, 通过将基于用户和基于项目的协同过滤方法进行混合, 并利用倒排表和K均值分类方法, 在一定程度上解决了传统方法在面对GitHub用户及项目数量级较大但交叉度较低的数据集时数据稀疏和冷启动问题, 并通过对比实验验证了本文方法的有效性.
1 基于内存的协同过滤方法
协同过滤方法是一组用于推荐系统设计和实现的方法, 具有实现简单且推荐结果准确的特征. Tapestry[2]作为第一个手动协作过滤系统, 允许用户通过参考其他用户的操作查询信息域中的项目. 文献[3]提出了自动协作过滤系统GroupLens, 其能自动定位具有相关性的信息, 并聚合为目标用户提供建议. 用户只需执行可观察到的操作, 系统将收集到的信息与其他用户的相关操作结合, 提供个性化的结果. 协同过滤技术中最常见的是基于内存的技术, 基于内存的技术使用已有的评价数据计算用户或项目之间的相似度[4], 根据计算出的相似度值做出推荐, 其又可分为基于用户的方法和基于项目的方法两种.
基于用户的协同过滤算法(user-based collaborative filtering)是目前应用较多的算法. 该算法通过计算目标用户与邻居用户之间的相似性, 根据邻居用户对某个资源的评分, 预测目标用户的评分, 预测评分最高的若干项目作为对用户的推荐呈现给目标用户. 其核心思想是计算用户间的相似性, 寻找与用户相似度最高的邻居. 而基于项目的协同过滤算法(item-based collaborative filtering)则关注目标用户评分的项目与其邻居项目的相似性, 将预测评分高的若干项目作为对用户的推荐呈现给目标用户.
1.1 基于用户的协同过滤方法
对于目标用户u, 基于用户的协同过滤方法首先在用户群中找到与用户u存在相似性的用户, 然后通过对其感兴趣的项目进行筛选, 结合他们对某一项目r的评分预测用户u对该项目的评分, 从而得到用户u对未知项目的评分排序列表, 进而达到推荐目的. 算法步骤如下.
1) 将获取的数据集进行预处理, 为不同操作赋予不同的分数权重, 然后利用处理好的数据集构建用户-项目矩阵. 结果表示为一个m×n的用户评价矩阵M, 其中m是用户数,n是项目数,M[i,j]表示第i个用户对第j个项目的操作; 若用户未对某个项目进行过操作, 则记为0分. 表1为用户-项目矩阵的一个示例.

表1 用户-项目矩阵示例
2) 得到用户-项目矩阵后, 要完成对目标用户最近邻居的查找. 通过计算目标用户与其他用户之间的相似度, 得到与目标用户最近的邻居集. 假设R(u)为用户u进行过操作的项目集合,R(v)为用户v进行过操作的项目集合, 如果将用户-项目矩阵中的每行记录视为一个向量, 则在推荐问题中计算u与v的相似度常用Jaccard相似度算法[5]和余弦相似度算法[6], 计算公式分别为
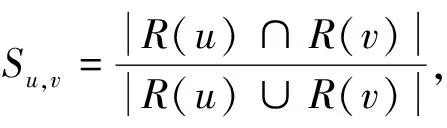
(1)

(2)
Jaccard相似度算法用于计算两个集合之间的相似程度, 但集合中的元素取值是二元的, 只能是0或1; 而余弦相似度算法在这方面则没有限制.
3) 先从已计算完相似度的用户集中筛选出与目标用户u最相似的k个用户, 用集合S(u,k)表示, 其中k是预设的相似用户窗口尺寸. 然后提取S中用户的所有评分项目, 并删除目标用户u进行过评分的项目, 将保留下的项目视为候选项目, 对每个候选项目r, 用户对其预测评分(感兴趣程度)为
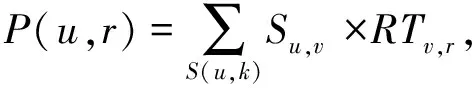
(3)
其中RTv,r表示用户v对项目r的评分. 最后根据预测的目标用户评分结果进行排序, 取前N个作为最终的推荐结果.
1.2 基于项目的协同过滤方法
与基于用户的协同过滤方法相反, 基于项目的协同过滤方法[7]通过计算项目之间的相似度找到最相似的项目, 直接执行协同过滤. 该算法步骤如下:
1) 对于每个项目, 算法通过使用余弦相似度计算相似度, 得到k个与其最相似的项目,k也称为邻居数;
2) 该算法从k个最相似的项目中删除待推荐用户已评分(进行过操作)的项目集合R, 即删除用户已经创建、 派生或关注的所有存储库, 将结果保存在集合U中;
3) 计算集合U和集合R中每个项目之间的相似度, 即计算用户已评分的项目与其k个最相似项目之间的相似度, 结果是一个按相似度递减排序的项目列表.
2 混合推荐方法设计
通过对两种基于内存的协同过滤方法比较可见: 基于用户的协同过滤方法具有易实现、 准确率高、 移植性强等特点, 但随着用户量的增加, 推荐过程的计算量呈线性增加, 对于千万级的用户和项目, 存在严重的可扩展性问题; 而基于项目的协同过滤方法则可通过建立以项目为基础的推荐模型, 解决高计算成本的问题, 且在多数情形下推荐结果甚至优于传统的基于用户的协同过滤方法. 但这两种方法也存在数据稀疏、 高维度、 冷启动等问题; 此外, 在推荐结果上, 基于用户的方法偏向于推荐流行度高的项目, 而基于项目的方法则偏向于推荐更具个性化的项目.
基于上述分析, 本文将两种基于内存的协同过滤方法相结合, 提出一种混合推荐方法, 不仅可动态计算相似用户以保证推荐的个性化, 而且只用很小规模的相似用户便可得到与基于项目方法相近似的推荐质量. 本文混合推荐方法如下:
1) 利用基于用户协同过滤方法中计算用户相似度的方法, 计算目标用户u与其他所有用户的相似性, 确定u的邻居用户. 可采用两种方法: 一是预先确定相似度阈值, 与目标用户相似度大于该阈值的用户作为其邻居; 二是预先确定邻居数k, 选择相似度最高的前k个用户作为邻居. 本文使用第二种方法确定目标用户的邻居.
2) 根据上述确定的邻居用户, 利用基于项目协同过滤的方法进行预测评分及项目推荐, 即通过计算项目之间的相似度, 找出与目标用户及其邻居已评分项目中的相似项目, 并根据相似度顺序进行Top-N推荐.
通过对两种推荐方法的结合, 使推荐结果的流行度与个性化兼备, 且降低了推荐成本, 提高了推荐效率.
2.1 数据稀疏性问题
在协作过滤技术中, 通常需要构建用户-项目矩阵, 其中每个条目都是未知值或用户对项目的评分. 本文在构建用户-项目矩阵中的用户评分建模时考虑用户对项目的Create,Fork和Watch三个操作, 并根据操作中所隐含的用户与项目的关联程度, 为三种操作指定评分值5,3和1, 即如果开发人员是该代码库的创建者, 则其评分值为5; 如果开发人员派生了该代码库, 则其评分值为3; 如果开发人员关注了该代码库, 则其评分值为1, 否则为0(未知评分).
定义1设U={u1,u2,…,un}是所有用户的集合,R={R1,R2,…,Rn}是所有项目的集合, 则用户-项目矩阵(开发人员-代码库矩阵)为Mn×m, 其中,


图1 用户与项目的关系Fig.1 Relationship between users and items

图2 项目-用户倒排表Fig.2 Inverse table of item-user
设相似度矩阵为C[u][v], 令C[u][v]=R(u)∩R(v), 即在倒排表中假设用户u和用户v同时属于倒排表中K个项目对应的用户列表, 则有C[u][v]=K. 如图1所示, 只有在项目a对应的用户列表中同时出现了用户A和用户B, 则在矩阵中将C[A][B]赋值为1. 综合图2的项目-用户倒排表, 相似度矩阵赋值如图3所示. 用余弦相似度算法对相似度矩阵进行优化处理, 可得如图4所示的相似度矩阵, 从而降低了数据的稀疏性.

图3 相似度矩阵赋值Fig.3 Similarity matrix assignment
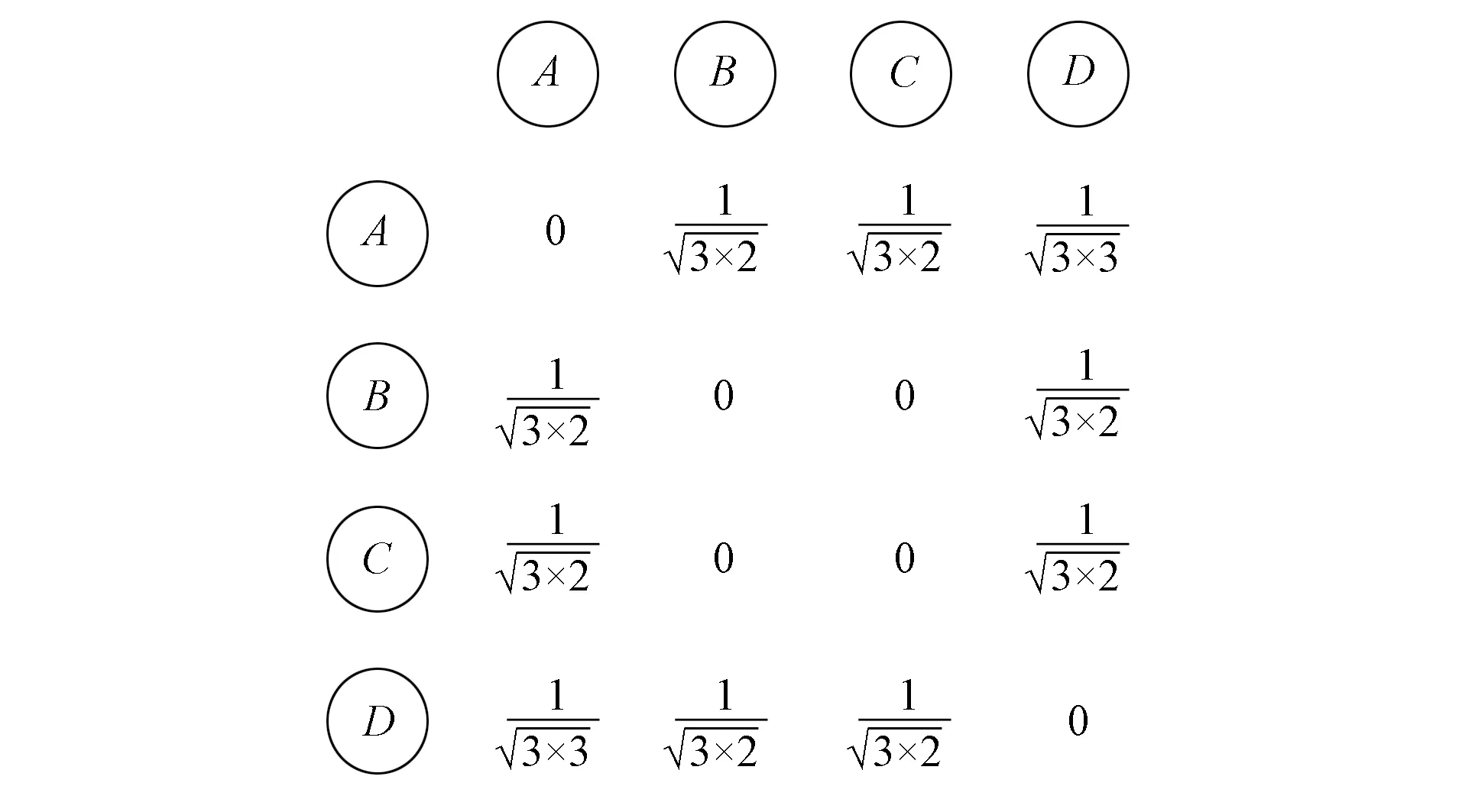
图4 余弦相似度计算后的相似度矩阵Fig.4 Similarity matrix after cosine similarity calculation
2.2 冷启动问题
当期望以用户或项目的历史行为作为研究对象时, 不可避免地会遇到冷启动问题, 即当用户或项目作为新数据进入数据库时, 其历史行为集为空集, 使得研究方法无法应用. 在推荐问题上, 冷启动问题表现为: 对新用户推荐结果的合理性和有效性无法得到保障, 以及新项目无法被推荐给用户. 本文对前者进行一定程度的缓解, 将分类结果作为项目的一个属性留存, 在系统对领域入门的用户进行推荐时, 将参考该属性对其做出推荐, 步骤如下:
1) 将项目的文本信息矢量化, 将其转换为高维度向量, 同时, 利用词频-逆文件(TF-IDF)频率方法, 在矢量化过程中计算各词语的TF-IDF值, 以便后续分析与处理;
2) 按照提前设置好的类别数K, 将K均值聚类算法应用到步骤1)中的矢量结果中, 不断运行直至聚类结束;
3) 输出每个项目的所属类别结果, 并输出每个类的关键词信息.
本文改进方法的思想: 当用户在GitHub中拥有一定量对项目的操作历史后, 推荐系统可根据行为历史对用户作出推荐; 但当用户行为历史不足时, 如领域入门的开发者, 期望通过对其仅有的行为历史得到一些项目信息, 并为其推荐拥有相似信息的项目, 使推荐结果尽可能合理、 有效, 从而在一定程度上缓解协同过滤方法的冷启动问题.
本文选取的项目信息是项目文本信息. 在GitHub中项目具有多种文本信息, 如名称、 简介、 代码、 ReadMe文件等, 从中选取最能快速区分项目间差异的项目名称、 项目简介, 并遵循用户友好的原则, 同时考虑项目的编程语言种类因素. 本文用K均值聚类算法对项目文本信息进行分析, 确定其之间的相似关系. 在将文本信息矢量化的同时, 直接利用词频-逆文件频率方法[8]对矩阵进行优化.
3 实 验
3.1 数据收集
为方便研究人员对GitHub进行研究, 平台开放了GitHub rest API, 用以提供GitHub的用户及项目数据. 但GitHub的数据量非常庞大, 且5 000个/h请求的API速率限制使完整下载数据几乎是不可能的. 为鼓励研究者对GitHub数据进行更深入地挖掘, Gousios等[9-11]创建了GHTorrent, 本质上是GitHub rest API所提供数据的一个可伸缩、 可查询的离线镜像.
本文选择最新的完整数据包, 该数据包中包含了目前GitHub各类数据, 包括用户、 项目、 提交等. 然后将整个数据包导入到MySql数据库系统中, 并对其进行如下预处理:
1) 数据集中共有121 725 743个项目, 将其均匀分为50档, 每档随机抽取100个项目, 共得到5 000个项目;
2) 从2019-01-01—2019-05-31的相关数据中截取5 000个项目, 对这些项目最近5个月的数据进行研究;
3) 从数据集中提取出所有对5 000个项目进行过创建(Create)、 派生(Fork)或关注(Watch)操作的用户;
4) 对项目和用户进行真实性和存在性的筛选, 以确保所有项目和用户是真实的且未注销或删除;
5) 以用户的操作量作为筛选条件, 以10作为筛选阈值, 删除对项目操作数低于10次的用户;
6) 最后将用户和项目的行为关系进行格式化, 使其能被推荐系统成功读取.
经过上述预处理, 本文共获得10 742名GitHub用户面向4 879个GitHub项目的创建、 派生和关注操作数据共计195 850条. 此外, 本文还从GHTorrent数据集中获取到实验所用项目的文本信息, 包括项目名称、 项目简介和编程语言等, 并对其进行如下预处理:
1) 分别得到4 879个候选项目的名称、 简介和所用编程语言(占最大比例), 并将三者在文本层面上进行连接;
2) 删除文本中的标点符号、 特殊字符及乱码等干扰信息;
3) 将项目编号与对应文本进行格式化, 使其能被推荐系统成功读取.
3.2 参数设置
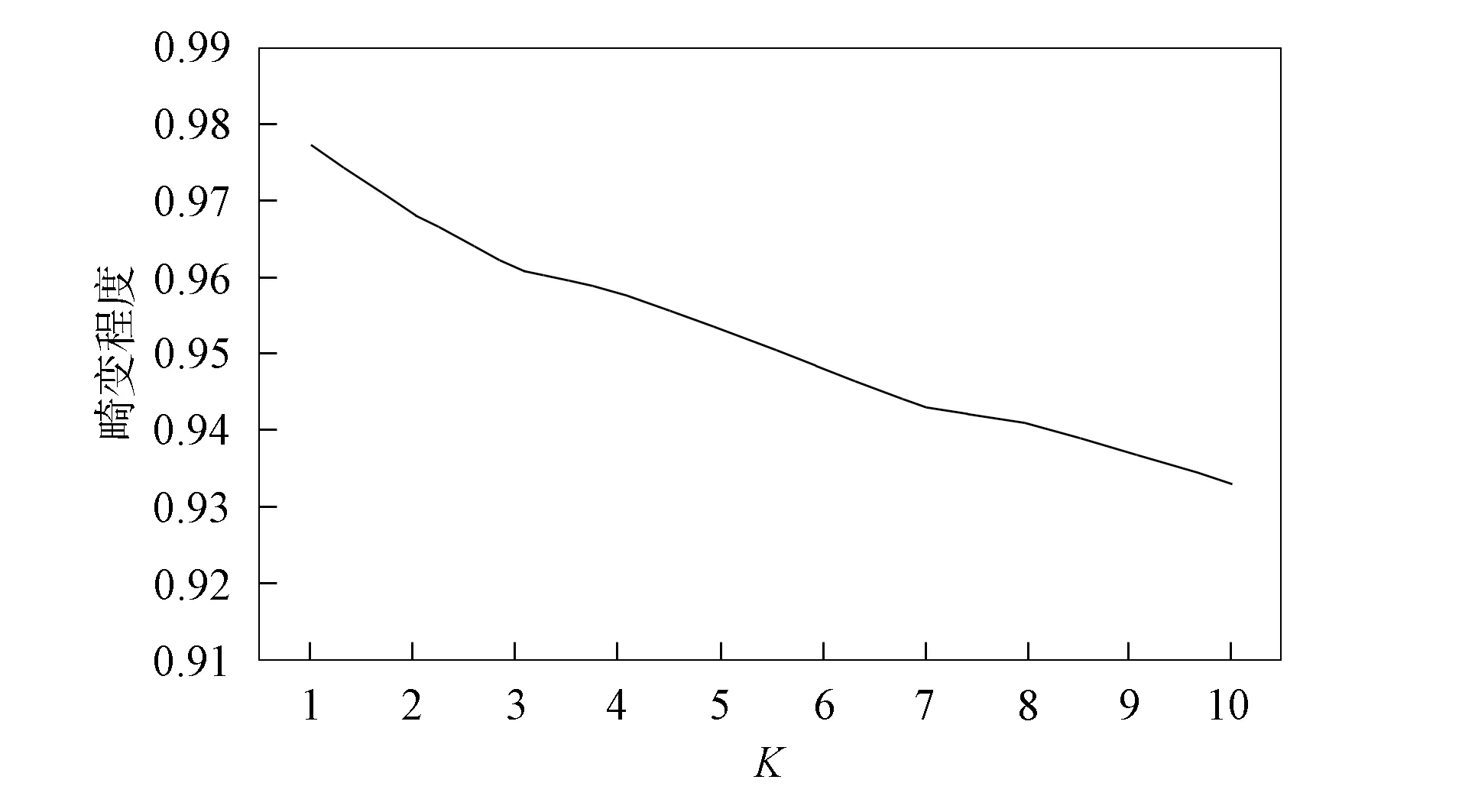
图5 K值对数据畸变程度的影响Fig.5 Influence of K values on degree of data distortion
下面通过控制变量对比性实验的方法对改进方法的参数进行优化. 首先对混合推荐方法的邻居用户数、 邻居项目数和推荐项目数分别进行对比实验. 选取推荐项目数为5, 邻居项目数为15, 取邻居用户数10~20, 观察精确率和召回率指标的变化, 结果列于表2. 由表2可见, 指标随邻居用户数的增多而提高, 为了兼顾推荐效率、 覆盖率和流行度等其他变量, 本文将邻居用户数设为15. 选取推荐项目数为5, 邻居用户数为15, 取邻居项目数10~20, 观察其各项指标变化, 结果列于表3. 观察结果与邻居用户数类似, 因此同理将邻居项目数设为15. 选取邻居用户数为15, 邻居项目数为15, 取推荐项目1~11, 观察其各项指标的变化, 结果列于表4. 由表4可见, 随着推荐项目数的增加, 精确率迅速下降, 而召回率迅速提升, 因此本文取均值, 将推荐项目数设为5.
下面对缓解冷启动问题时K均值聚类算法的K值进行优化. 将K值取1~10, 并分别计算每个K值对应的畸变程度, 即每个类心与其内部数据成员位置距离平方和的平均值, 若类内成员彼此间越紧凑则类的畸变程度越小, 反之, 若类内成员彼此间越分散则类的畸变程度越大, 实验结果如图5所示. 由图5可见, 畸变程度随聚类数K的增大而降低, 但若K值过小, 聚类则失去了实际意义, 无法为用户推荐个性化强的项目, 因此本文取K=6, 期望能兼顾项目的相似性与独特性.

表2 邻居用户数对精确率和召回率的影响

表3 邻居项目数对精确率和召回率的影响

表4 推荐项目数对精确率和召回率的影响
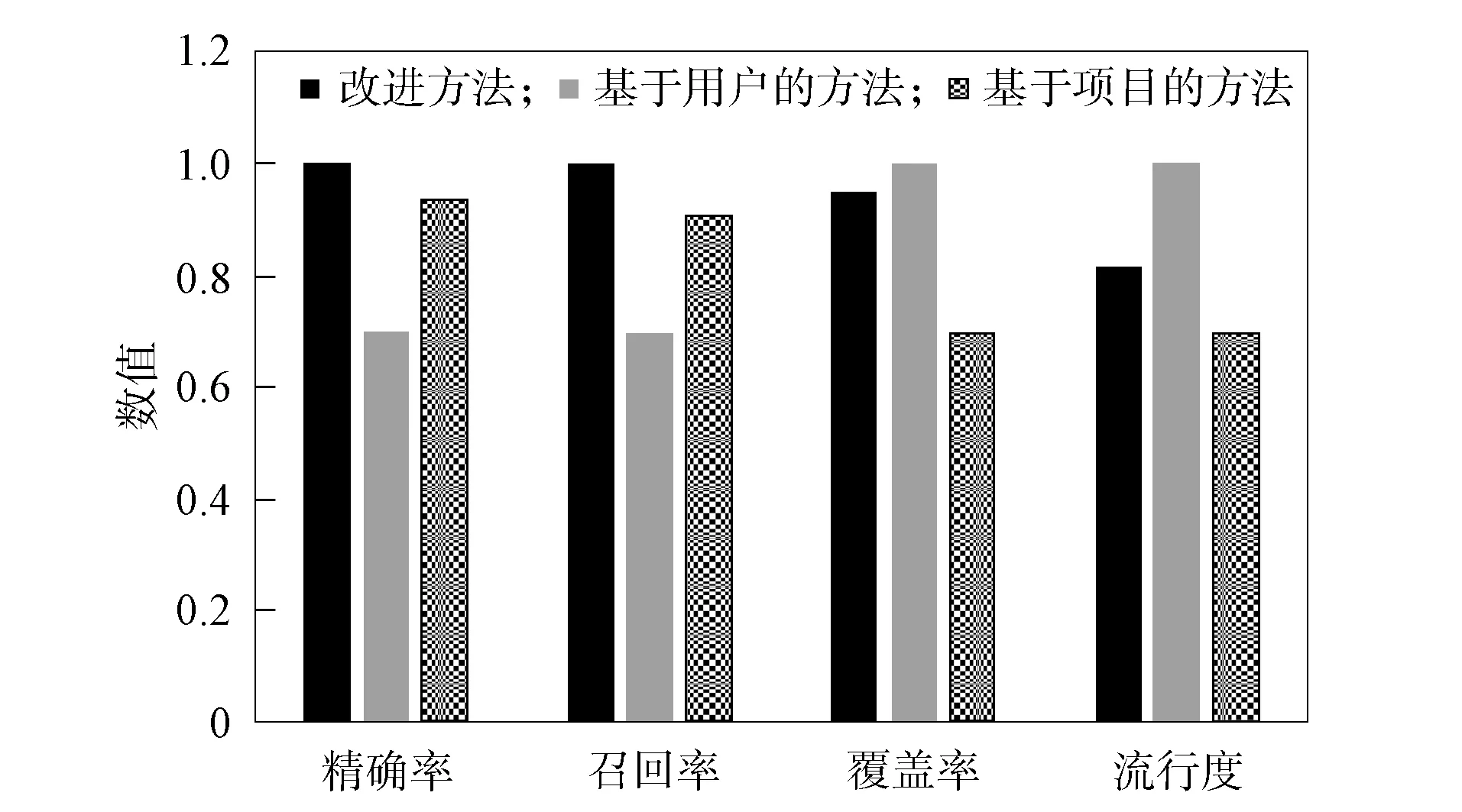
图6 不同推荐方法在4个评价指标上的对比Fig.6 Comparison of different recommended methods on four evaluation indexes
3.3 实验结果及评价
将上述参数应用到改进后的推荐方法中, 并将改进方法与传统的两种基于内存的协同过滤方法进行对比, 以验证本文方法的可行性. 本文对基于改进后的推荐系统进行了实际操作, 针对某个真实用户进行推荐结果分析, 使实验结果更直观.
首先将改进方法与传统方法应用到经过预处理的GitHub数据集上进行评估, 实验结果如图6所示. 由图6可见: 改进方法在精确率和召回率指标上均高于两种传统方法, 改进方法的覆盖率和流行度指标均介于二者之间; 改进方法解决了数据稀疏性问题, 并在一定程度上缓解了冷启动问题, 提高了整体推荐性能.
下面针对实验数据集中的8088号用户“Ajeo”从推荐系统中获取的推荐结果进行分析, 其GitHub主页如图7所示. “Ajeo”在本文实验数据集中共有14条评分数据, 其中包括派生了自然语言处理课程“oxford-cs-deepnlp-2017/lectures”, 关注了数据科学手册“jakevdp/PythonDataScience Handbook”、 著名的自然语言处理工具“google-research/bert”和深度学习论文“terryum/awesome-deep-learning-papers”等; 本文推荐系统根据其项目操作历史, 为其个性化推荐5个项目, 结果列于表5.
图7 “Ajeo” GitHub主页Fig.7 GitHub homepage of “Ajeo”

表5 用户“Ajeo”获得的推荐结果
由表5可见, 在Top-5推荐列表中, 排在第一位的是一个设计工具的插件集, 这是计算机从业者常用的工具, 具有较高的流行度. 可以合理推测, 与其相似的开发者可能很多人都在使用这个工具集. 而剩下的4个项目都与他在GitHub上的项目操作历史紧密相关, 涉及到机器学习、 自然语言处理等内容. 通过对用户“Ajeo”所得推荐结果的分析, 可认为本文推荐系统具有较合理、 有效的推荐能力.
下面在数据集中新加入一名用户“ILOVEJLU”, 并令其派生一个Android UI库“wasabeef/awesome-android-ui”, 然后使用推荐系统为其提供推荐结果, 得到推荐结果列于表6.

表6 用户“ILOVEJLU”获得的推荐结果
由表6可见, 系统提供的推荐结果在文本信息层面与“ILOVEJLU”的项目操作历史相似度很高, 因而内容上也具有很强的相关性, 对于新用户或领域入门的开发者具有一定的指导意义.
综上所述, 针对GitHub平台现有项目推荐功能的缺陷, 本文提出了一种基于数据的GitHub项目个性化混合推荐方法. 首先, 对现有协同过滤方法进行了改进和优化, 通过建立倒排表的方式大幅度降低了基于用户的协同过滤方法在计算用户相似度时的计算成本, 并提高了运行效率, 克服了协同过滤方法存在的数据稀疏性问题; 其次, 通过利用基于用户的协同过滤方法进行用户相似度计算, 并利用基于项目的协同过滤方法进行项目推荐的方式, 将两种基于内存的协同过滤方法相结合成为混合推荐方法, 优化了推荐结果, 兼顾了推荐结果的流行度与个性化, 并保持了协同过滤推荐方法的优越性; 再次, 基于项目文本信息进行聚类, 使评分历史不足的用户能利用仅有的项目历史获得较合理、 有效的推荐, 在一定程度上缓解了协同过滤方法存在的冷启动问题; 最后对该推荐方法进行实证研究, 将其应用到从GHTorrent获取的真实GitHub数据上, 并通过实验对实验结果进行评估. 实验结果表明, 在常见的几个评估推荐系统的评价指标上, 本文方法与两种传统基于内存的协同过滤方法相比, 都有较优越的表现, 证实了该方法在面向领域入门的GitHub项目推荐问题上的可行性.
猜你喜欢
科学大众(2020年23期)2021-01-18 03:09:08
汽车观察(2019年2期)2019-03-15 06:00:50
中国经济周刊(2018年5期)2018-02-01 14:25:45
中国卫生(2016年5期)2016-11-12 13:25:26
中央民族大学学报(自然科学版)(2016年3期)2016-06-27 07:55:32
南都周刊(2015年4期)2015-09-10 07:22:44
南都周刊(2015年3期)2015-09-10 07:22:44
南都周刊(2015年1期)2015-09-10 07:22:44
生物进化(2014年2期)2014-04-16 04:36:26
电力科学与工程(2010年11期)2010-04-04 11:11:16
