
一种基于卷积神经网络的低光照图像增强方法
2020-11-26 03:58:36李江华王坤
江西理工大学学报 2020年5期
李江华,王坤
(江西理工大学信息工程学院,江西 赣州341000)
0 引 言
随着专业数字成像设备的普及,数字图像处理[1]被广泛应用于工业生产、视频监控、智能交通、遥感与监控等诸多领域,且在其中发挥着重要的作用。但是,在图像采集过程中,由于各种不可控因素的影响,特别是在室内照明、夜间照明、阴天等不利条件下,获取的图像往往会出现对比度比较低、动态范围强度低、图像暗区和亮区的细节消失等各种缺陷。因此,如何在低光照条件下获得清晰的静止或移动图像已成为一个需要解决的问题。为此,图像增强技术引起了工业界和学术界的广泛关注和重视,图像增强不仅满足了人们对视觉体验的需求,而且提高了户外视觉系统的可靠性和鲁棒性,使图像处理系统更容易对图像进行分析和处理。
低光照图像增强作为数字图像处理领域的一个经典课题,长期以来一直有着源源不断的研究,这些研究成果也已被广泛应用于各种领域。如Du等提出了一种将对比度增强和边缘增强(EdgeE)结合起来基于区域图像预处理方案用于人脸识别任务[2];Li等提出了一种新的医学图像增强算法,采用对比度限制自适应直方图均衡(CLAHE)来改善全局对比度,并利用低频分量和几个高频分量来增强边缘细节[3];Shi等提出了一种用于单个夜间图像的低光照图像增强方法,该方法利用亮通道获得初始传输值,然后使用暗通道作为补充通道来校正从亮通道获得的潜在的错误传输估计[4];Zhi等提出了一种基于照明调整、引导滤波和“S曲线”功能用于煤矿环境新的非均匀图像增强算法[5];罗会兰等提出了基于三流卷积神经网络模型的图像分类方法[6]。虽然这些图像增强算法在图像质量上有一定的提高,但是仍没能很好地解决一些问题,如:对比度增强算法在处理图像时可能会出现图像过度增强或效果不自然的现象;HE算法增强之后的图像会出现伪像和强饱和度等不好的效果;SSR、MSR、MSRCR等方法在图像像素变化剧烈的边缘处普遍存在会出现光晕伪影的缺点,且都伴随着色彩失真。如何自适应地增强低光照或不均匀照明的图像,还需要进一步研究。
针对上述常见的当前低光照图像增强算法出现的过度增强、伪影等缺陷,本文提出了一种结合CNN[7]与Retinex算法[8]的自适应低光照图像增强方法,并对日常出现的低光照条件下图像难以辨识的问题进行了研究。
1 Retinex算法
Retinex是一个合成词,它的构成是Retina(视网膜)+Cortex(大脑皮层)。美国物理学家Edwin Land认为人类的视觉系统在视觉信息的传导过程中对接收到的信息进行了某种处理,所以提出了把光照不均匀问题和光源强度等多个不确定的成分分离的方法,只保留了反映物体本质特征的信息。其表达式如式(1)所示:

其中,x 表示像素;S(x)是人眼观察到的图像;R(x)是图像的反射分量;L(x)是光照分量;点“·”表示按像素相乘。其物理意义可以简单地描述为:人类观察到的低光照图像可以分解为图像R(x)的反射分量和光照分量L(x)的乘积,即物体本身颜色因素与光照分量是无关的,只由物体表面的反射属性来决定的。意味着从输入图像中去除低光照分量可实现低光照图像增强。本文的目标是通过预测图像 S(x)的光照分量 L(x)来求得反射分量 R(x)。 其原理图如图1所示。
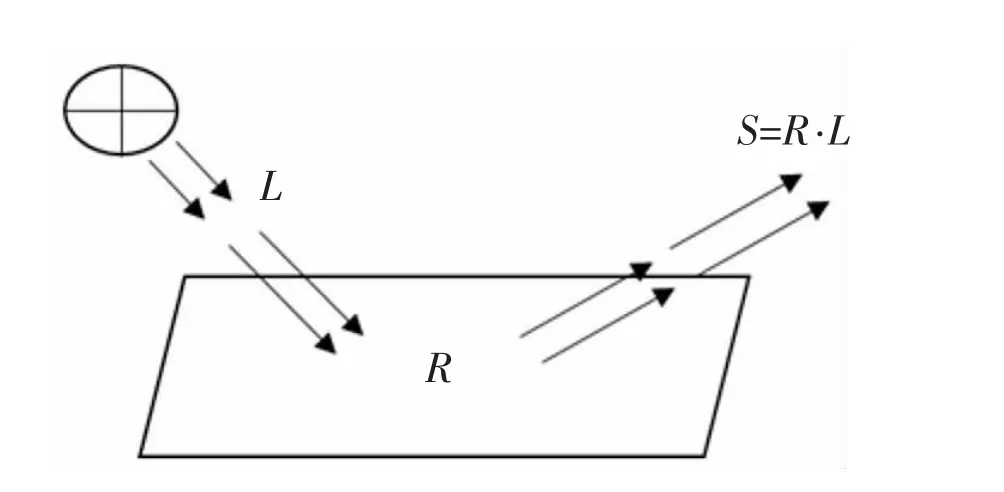
图1 Retinex理论中图像的构成
2 本文方法
针对Retinex算法对图像进行增强过程中有时会出现图像偏色等缺陷,本文提出了结合CNN和Retinex算法对低照度图像进行增强的方法。该方法以低光照图像为输入,利用CNN学习预测低光照图像与相应亮度图像之间的映射关系并输出其光照图,然后通过Gamma校正[9]调整优化估计的光照图,最后利用得到的光照图结合经典的Retinex算法从而对低光照图像进行增强。
2.1 CNN结构
本文CNN包含4个具有特定任务的卷积层,不同的卷积层对最终的光照图有不同的影响。例如,前两层主要是针对高光区域,第三层主要是针对低光区域,而最后一层则是重构光照图。对卷积层的具体描述如下:
Step1:特征提取。为了学习低光图像和其光照图之间的关系,首先从低光图像中提取重叠的像素块,并通过n1个滤波器用高维向量表示每个像素点,其表示为:
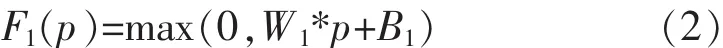
其中,p是大小为n×n的输入图像块;W1和B1是滤波器的权重和偏置。 W1的大小为 f1×f1×n1,其中 f1是滤波器的空间支撑度,n1是滤波器的个数。B1是一个n1维向量,其每个元素都与一个滤波器相关联,“*”表示卷积运算。Max(0,x)是一种修正线性单元(RELU),用于加速训练收敛并且提高网络性能。
Step2:特征增强。受减少压缩伪影中使用的特征增强层的启发[3],采用特征增强层将“噪声”特征映射到相对“干净”的特征空间,因为弱光照图像通常会受到噪声的影响。表示为:
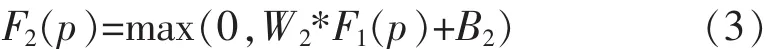
其中,W2包含大小为 f2×f2×n2的 n2个滤波器, 并且B2是n2维向量。
Step3:非线性映射。将每个高维向量映射到另一个高维向量,即将 F2(p)转换为 F3(p):
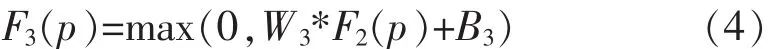
其中,W3包含大小为 f3×f3×n3的 n3个滤波器, 并且B3是n3维向量。
Step4:图像重建,最后,设计一个卷积层来聚合图像块表示,以生成学习的光照图。F3(p)被变换成 F4(p),表达式为:
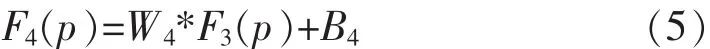
其中,W4包含大小为 f4×f4×n4的 n4个滤波器, 并且B4是n4维向量。
这些未知的网络参数 Θ={W1,W2,W3,W4,B1,B2,B3,B4}是通过监督学习方式,以最小化均方误差(MSE)[10]损失函数实现的。MSE损失函数表示为:
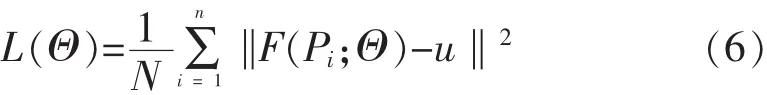
其中,N是训练批次中的图像块个数;Pi表示低光照图像块;u是对应于Pi的光照图的图像块;F是学习的映射函数。
2.2 Gamma与校正
通过Gamma校正来调整估计的光照图,以更清晰地展现图像中的低光照区域,表示为:

其中,L(x)′是估计的光照图;L(x)γ是经过 Gamma校正的光照图。γ=1.7是一个启发式的值。在优化映射时,假设输入的图像中大小的局部区域具有相同的光照强度。在经过Gamma校正后,需要通过引导图像滤波来细化光照图,以消除光照遮挡的影响。在引导图像滤波中,将输入图像的红色通道作为引导图像,滤波窗口大小为16×16。增强图像以通过公式获得:

其中,x 表示像素;S(x)表示低光照图像;Lr(x)表示细化的光照图。
图2为图像的细化处理过程,从图2所示的效果可以看出,此方法准确地估计了图像中代表光照强度的光照图部分。本文方法产生的结果自然且真实,其中暗区域被增强,而亮区域(例如光源)被保留。
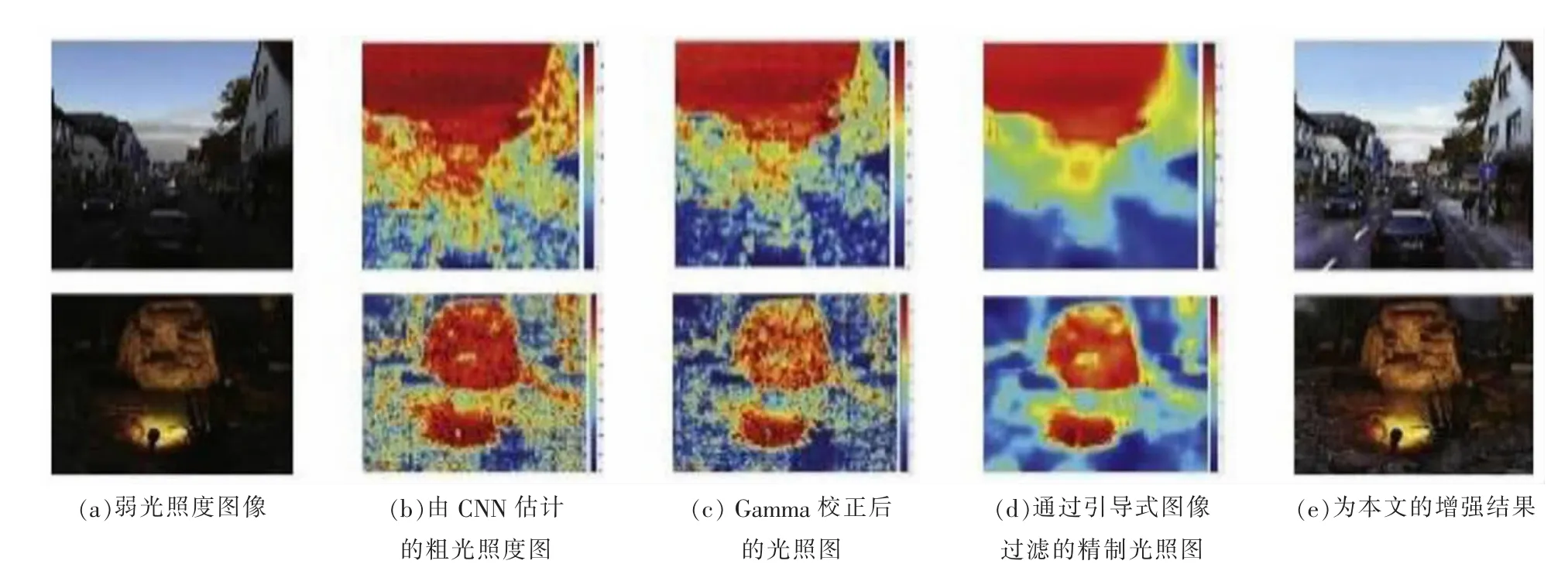
图2 细化的处理过程
2.3 CNN的训练
本文的参数设置如表1所示。在CNN训练阶段,各层的滤波权重由高斯分布随机初始化,偏置值设置为 0,初始学习率为 0.05,每 1,000,000 迭代一次,学习率递减0.5,动量参数设置为0.9。采用批处理模式的学习方法,批处理量为128个。网络训练是在装有 Intel(R) Core(TM)CPU i5-8300H@2.60 GHz的CPU和NVIDIA GeForce GTX 1050Ti的个人电脑上进行的。
深度学习系统通常需要大量的带标签数据来进行训练。遗憾的是,现如今没有足够的标记数据可用。为了获得更合理、更可靠的性能的增强,因此利用式(1)中Retinex算法综合训练数据。此外,为了使用合成训练数据,本文遵循图像内容独立于光照图,且图像块中的光照图局部恒定 (即局部区域具有相同的光照强度)的假设。为此从互联网收集了300个具有不同内容的清晰照明图像,用于合成样本对(即低光照图像及其照明图)。清晰的照明图像即表示图像具有良好的照明和对比度,且没有噪音和模糊,参阅图3中的示例。这300个清晰照明的图像具有不同的尺寸,并且是常见的JPG、PNG或BMP格式。基于Retinex算法,给定清晰照明的图像R(x)和随机照明值 L,即可以合成为低光照图像 S(x)=R(x)·L。其中,R(x),L 和 S(x)是标准化的。 基于这些合成图像,本文通过重叠裁剪获得训练图像块,重叠像素是10。 最后,共收集了 2,052,864 个大小为 n×n=16×16的训练图像块。其中,假设局部区域(即16×16)具有相同的照明强度,当图像块足够小时,该假设在现实世界中是合理的。图3给出了3个清晰照明图像和相应的合成弱照明图像的例子,自上而下是清晰的照明图像和相应的合成弱照明图像,其中从左到右,照明值L分别为0.5159、0.0088和0.2328。
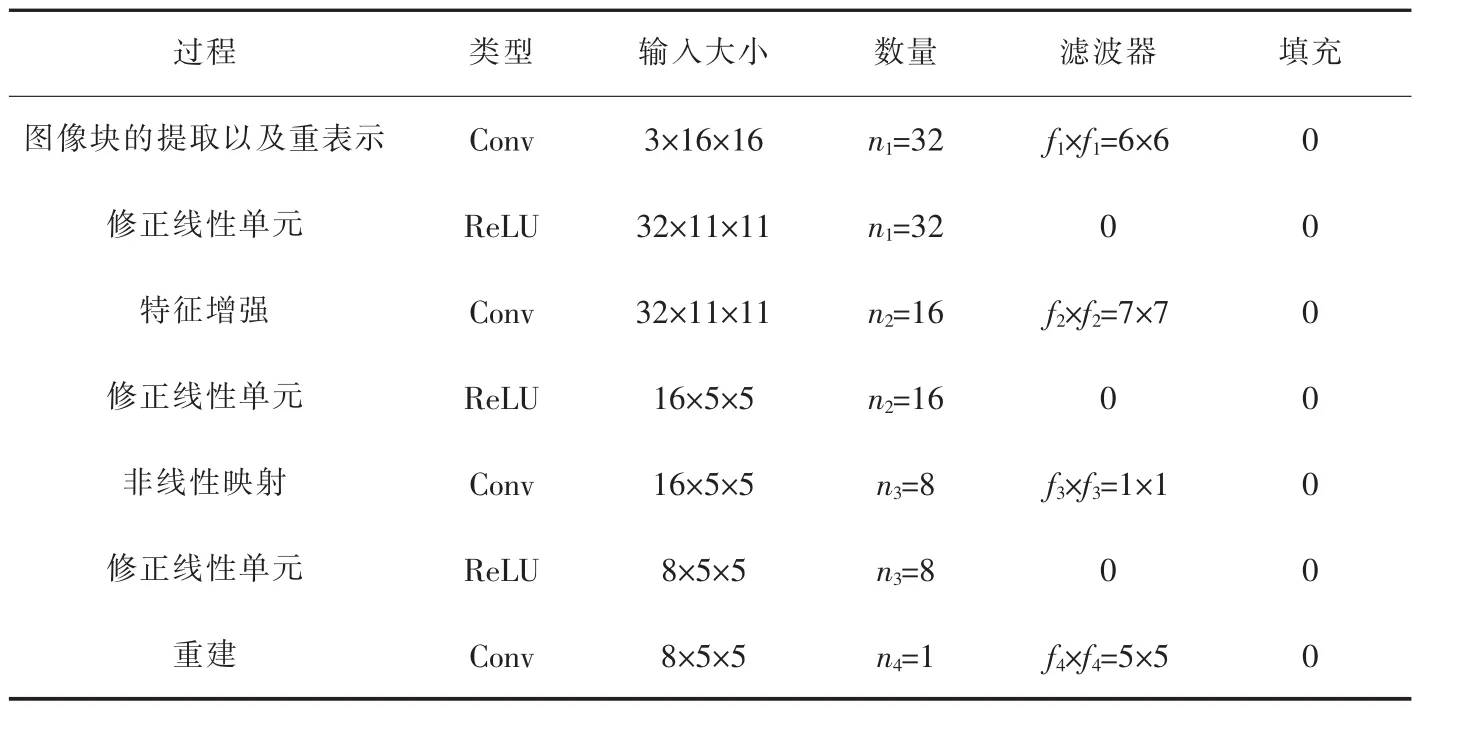
表1 CNN的参数设置

图3 合成弱照明图像示例
3 实验与评估
3.1 参数评估
基于表1所列的基本网络参数设置,表2总结了不同MSE值的设置结果,其中基本网络参数设置的MSE用黑体标记。
如表2所列,随着滤波器数量的增加,MSE性能随之变得更好。然而,这种改进是有限的,同时也会花费更多的训练时间和处理时间。因此,基于性能和复杂度之间的权衡,需要选择一个中间的网络过滤器数作为本部分的基本过滤器数设置。上面实验还表明,合理的滤波器大小设置可以获得更好的性能。通过对滤波器的对比发现打破1×1的滤波器大小这一约束带来的改善有限,且比较费时。因此,本文的网络中保留了1×1的约束,因为该约束对于本文的网络设计带来更高的效率。最后,随着层数的增加,并没有获得更好的MSE性能。究其原因,可能是:①梯度扩散的影响;②简单的原始架构重复导致网络架构不合理。

表2 不同网络参数设置的平均MSE值
3.2 定性比较
将本文方法与经典的HE[11](直方图均衡化)方法、MSR[12](多尺度视网膜法)方法,以及最近的AWVM[13](自适应权向量法)方法分别对合成的和真实的低光照图像进行定性处理和定量比较。
本文对合成的弱光图像进行定性比较。图4中的图像是基于Retinex算法合成的,图5中展示了不同算法对真实低光照图像处理结果对比。
从图5中可以看出,对于真实的低光照图像,其对比结果与合成图像的对比结果有相同的趋势。具体表现为,对于图像内部照度不均匀的图像(即暗区域和亮区域共存的图像)“鹿”“小孩”“岸边”和“房子”,HE算法产生的结果都是过度增强和不真实的结果(如HE算法的结果中“小孩”图像的手和“岸边”图像的冲浪板)。本文所提出的方法能够产生较为自然的效果,没有出现增强过度或不足的现象,这主要因为对照度图的准确估计,而照度图便是用来增强暗区和保持亮区的。对于光照度极低的图像(即图像“鹿”),HE方法能展示出更多的场景细节,但也同时产生了伪影和过饱和现象。对于非均匀光照的图像和背光图像,MSR方法都表现出偏灰色的结果,而且因为完全去掉了光照度,所以图像显得很不真实。AWVM算法的结果看起来与原图较为贴近,看起来较为自然,但对比度和亮度的增强仍然稍有不足。总的来说,本文所提出的方法对不同环境下拍摄的低光照图像产生了自然合适的视觉效果,场景和物体的细节都得到了很好的还原。

图4 合成图像的定性比较

图5 不同算法对真实低光照图像处理结果对比
3.3 定量比较
目前还没有为低光照图像增强方法设计的专有定量评价指标,因此,不同的研究者利用不同的方法来评价其成果,以往的方法大多采用无参考或全参考的图像质量评估指标。为了公平地比较,本文使用 MSE(均方误差)、PSNR[14](峰值信噪比)和SSIM[15](结构相似度)来衡量结果与原始图像的差异,如表3所列。
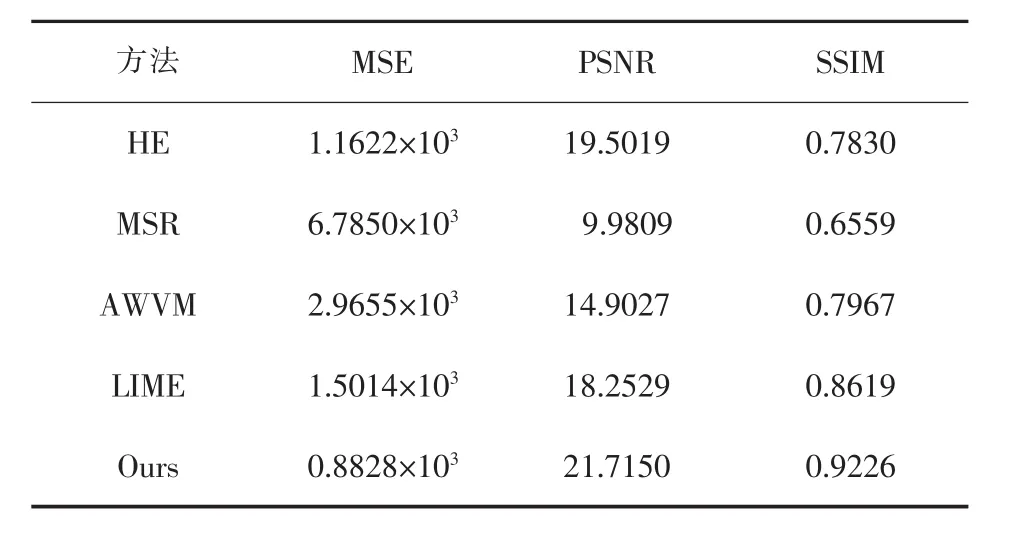
表3 定量比较
从表3中可以看出,在对比的方法中,本文提出的方法在MSE、PSNR和SSIM值上都比较突出。本文方法的结果最接近于真实情况,证明了该方法的有效性。此外,有趣的是,尽管本文方法通过MSE损失函数进行优化的,但是该方法在SSIM评估度量上获得了最好的性能。
4 结 论
针对经典Retinex算法对图像增强有时会出现图像偏色等缺陷,本文提出了结合CNN和Retinex算法对低照度图像进行增强的方法。以低光照图像为输入,利用CNN学习预测低光照图像与相应亮度图像之间的映射关系并输出其光照图,然后通过Gamma校正调整优化估计的光照图,最后利用得到的光照图结合经典的Retinex算法从而对低光照图像进行增强。通过实验对比结果表明,所提出的方法在定性和定量比较上取得了较好的表现。
猜你喜欢
中国机械工程(2022年8期)2022-05-09 12:32:02
燃气涡轮试验与研究(2021年6期)2021-08-01 03:09:10
中国机械工程(2021年8期)2021-05-07 05:49:10
海洋信息技术与应用(2020年4期)2021-01-18 06:21:36
中国生物医学工程学报(2019年5期)2019-07-16 07:56:50
音乐教育与创作(2019年8期)2019-05-16 04:06:34
北京航空航天大学学报(2017年3期)2017-11-23 05:14:58
电脑知识与技术(2016年22期)2016-10-31 20:38:41
江西通信科技(2015年3期)2015-12-05 05:52:05
河南科技(2014年4期)2014-02-27 14:06:59
