
基于逻辑回归模型的缺血性脑卒中发病率预测研究*
2020-11-25 03:07李鹏
医学信息学杂志 2020年6期
李 鹏
(1湖南中医药大学信息科学与工程学院 长沙410208 2中南大学湘雅三医院 长沙410006 3医学信息研究湖南省普通高等学校重点实验室(中南大学) 长沙410006)
闵 慧
(湖南信息职业技术学院软件学院 长沙410200)
瞿昊宇
(湖南中医药大学信息科学与工程学院 长沙410208)(医学信息研究湖南省普通高等学校重点实验室(中南大学) 长沙410006)
罗爱静
(中南大学湘雅三医院 长沙410006)
1 引言
缺血性脑卒中是指由于脑的供血动脉(颈动脉和椎动脉)狭窄或闭塞、脑供血不足导致的脑组织坏死的总称。近年来缺血性脑卒中[1]已经成为危害人类健康和生命安全的重大疾病,如何有效地对缺血性脑卒中发病率进行预测,识别可能导致缺血性脑卒中疾病的高危因素,提高高危患者风险意识,具有十分重要的意义[2]。目前临床上用于脑卒中筛查或预测复发的相关方法较多,例如汪仁等[3]采用全国脑卒中筛查数据作为训练和测试数据,构建一种基于决策树的脑卒中分级预测方法。朱千里[4]从脑卒中致病原因(是否存在心房颤动)出发,采用人工神经网络对脑卒中发病率进行预测,预测结果可用于指导脑卒中患者的个性化治疗。陈莉平等[5]根据收集的脑卒中数据,构建脑卒中大数据应用平台,开发基于AdaBoost的脑卒中复发预测模型对脑卒中初患人群进行复发风险预测。本文针对现有方法的不足提出一种基于逻辑回归模型的缺血性脑卒中发病率预测方法。通过收集和清洗数据、提取面向缺血性脑卒中预测特征、构建基于逻辑回归的模型等过程来实现缺血性脑卒中发病率的预测,最后通过仿真实验验证方法的有效性。
2 基于逻辑回归的缺血性脑卒中发病率预测
2.1 具体流程(图1)

图1 基于逻辑回归的脑卒中预测流程
2.2 数据收集和平台构建
首先利用数据接入及导入工具对分散在基地医疗机构、社区卫生中心、保健机构、体检机构和三甲医院等各级机构中的患者信息进行采集和集成,最终形成缺血性脑卒中患者病历信息库。采集内容涉及患者个人信息、既往史、家族史、住院诊疗数据、阶段性随访数据、体检数据等。在数据收集的基础上,采用Hadoop[6]作为基本的分布式执行架构,在该架构上配置Python与Spark等分析工具,构建集脑卒中患者数据采集、存储、分析、模型学习、疾病诊治等功能一体化的大数据平台,见图2。
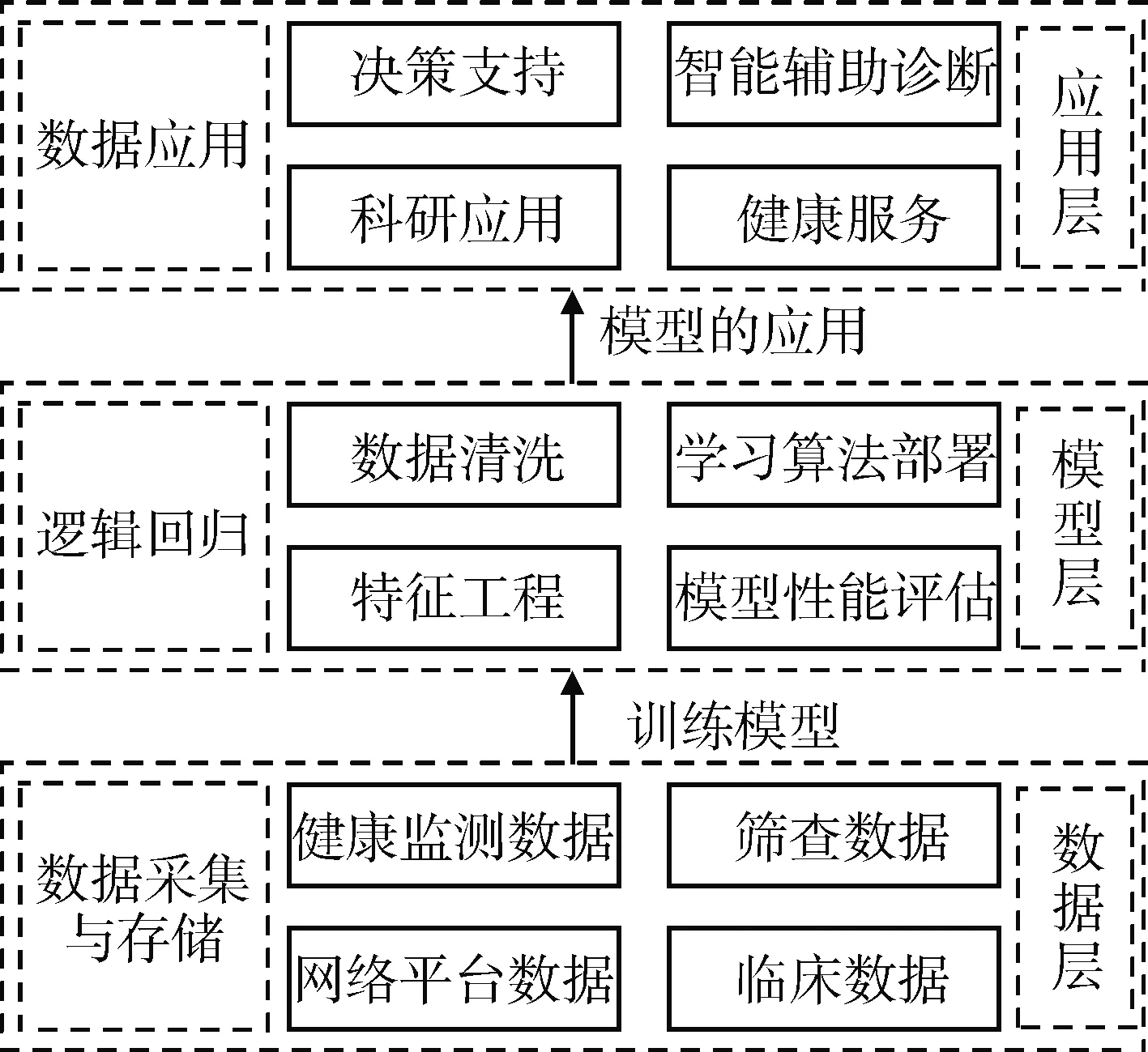
图2 缺血性脑卒中大数据平台
2.3 数据清洗
脑卒中管理数据来源广泛,形式多样,涉及种类很多,且由于受到筛查对象主观性、时间限制、信息获取成本高等因素影响,收集到的脑卒中大数据经常存在空值、不一致、噪声数据等。因此需要对这些数据进行预处理以提高后续预测方法的准确性。其中空值数据对于算法的影响很大,采用删除包含空值的记录、自动和手工补全缺失值等方法处理;对于不一致数据,则在分析产生原因的基础上利用各种变换、格式化、汇总分解函数实现数据清洗;对于噪声数据,采用分箱、计算机与人工检查相结合和聚类3种方法处理。
2.4 特征提取
2.4.1 概述 实证研究和相关统计表明[7]目前影响缺血性脑卒中发病的高危因素包括:年龄、遗传、高血压、高血脂、高血糖、心脏病、不良饮食、缺乏运动、吸烟、酗酒。从预处理后的脑卒中数据集中提取上述10种因素作为特征来进行模型训练。考虑到基于逻辑回归模型的输入一定是数值类型,而提取的10个特征中大部分是字符串类型,需要将字符串类型转换成数值类型,如向量、矩阵或张量形式。一般而言常见特征可以分为类别和数值型特征两大类。其中对于类别特征,使用独热编码[8]技术将其转换为数值类型后再作为模型的输入。对于数值型特征,直接对其进行特征归一化后将其作为模型的输入。
2.4.2 特征编码 将分类特征表示为二进制向量,又称一位有效编码,其方法是使用N位状态寄存器来对N个状态进行编码,每个状态都有独立的寄存器位,在任意时间其中只有一位有效。提取的10个特征中遗传、心脏病、不良饮食、缺乏运动、吸烟和酗酒6个特征属于类别特征,需要对其进行独热编码后再作为模型的输入。编码过程,见图3。

图3 独热编码
2.4.3 特征归一化 提取的10个特征中年龄、高血压、高血脂和高血糖4个特征属于数值类特征,对其进行特征归一化处理,以提高模型精度和训练过程中算法的收敛速度。采用两种常见的特征归一化方法:线性归一化和标准差标准化。其中线性归一化是指将特征值范围映射到[0,1]区间,见公式1;标准差标准化的方法是指将特征值映射到均值为0、标准差为1的正态分布,见公式2。
(1)
(2)
其中min(x)指x的最小值,max(x)指x的最大值,mean(x)指x的平均值,std(x)指x的标准差。以10个样本的年龄特征为例,根据上述公式对其进行特征归一化的结果,见图4。

图4 年龄特征的归一化
2.5 基于逻辑回归的模型训练
2.5.1 概述 逻辑回归又称为logistic回归分析[9],是一种广义的线性回归分析模型,常用于数据挖掘、疾病自动诊断、经济预测等领域。以脑卒中病情分析为例,选择两组人群,一组是脑卒中患者组,一组是非脑卒中患者组,两组人群必定具有不同的体征与生活方式等。因变量为是否患上脑卒中,值为“是”或“否”;自变量为上述影响脑卒中发病的10大特征。自变量可以是连续或是分类的,通过logistic回归分析可以得到自变量最优权重,从而准确预测不同人群患脑卒中的可能性。
2.5.2 确定目标函数 首先基于逻辑回归模型将缺血性脑卒中发病率预测问题采用以下数学表达式进行建模:
(3)
其中y指待观测个体患上缺血性脑卒中的概率,是一个Sigmoid函数[10],采用该函数的意义在于不管影响脑卒中的因素有多少,最终得到的是一个关于缺血性脑卒中发病率的取值在[0,1]之间的概率。x1,x2,...,x10指影响缺血性脑卒中发病的10大特征,θ是权重参数。为使预测结果与真实结果的误差最小化,采用最小化均方误差[11]作为逻辑回归的损失函数,从而得到本研究预测问题的优化目标为:
(4)
其中m是样本的规模;yθ(x(i))是对第i个样本进行训练得到的预测结果;y(i)是第i个样本的真实结果(标签)。要构建准确的缺血性脑卒中发病率预测模型,即要求解得到式(4)中的参数θ的最优值。
2.5.3 模型求解 为求解式(4)的优化问题,常采用最小二乘法,将求解式(4)的优化问题转化为求函数极值问题,但这种做法并不适合计算机。为此采用小批量梯度下降法(Mini-batch Gradient Descent,MBGD)[12]进行模型求解。该方法训练过程比较快,且能保证最终参数训练的准确率。特点是每次训练迭代在训练集中随机采样M个样本,其数学表达式为:

(5)

3 实验
以获取到的全国2012-2018年缺血性脑卒中院外筛查数据作为研究对象,覆盖全国31个省市自治区总计454个筛查点,随机选定城乡社区的40岁及以上常驻人群进行社区整群抽样获得数据。截至目前累计收集并存储近700万人的院外筛查档案。本文从这些档案数据中随机抽样50 000条档案作为数据集。其中70%数据集为训练集,30%数据集为测试集。将本文提出的预测方法与决策树算法[3]、人工神经网络算法[4]和AdaBoost算法[5]进行性能对比,采用查准率来评价各种算法性能。不同方法查准率比较结果,见图5。可以看出随着数据规模的增加,4种方法的预测精度都有不同程度的上升。总的来看,本文方法的预测精度要略高于人工神经网络算法,比决策树算法和AdaBoost算法的预测精度分别高出约18.8%和21.7%。分析原因可知:一是本文预测方法在建模过程中采用多种技术对缺血性脑卒中原始大数据进行清洗,并对影响脑卒中的高危因素进行分析和特征提取,将噪声数据对模型的影响降到最低;二是对每个特征进行特征编码或归一化的分类处理,提高特征对于模型的吻合度;三是采用小批量梯度下降法在降低训练时间的同时进一步保证预测准确性。

图5 不同方法查准率比较
4 结语
本文提出一种基于逻辑回归模型的缺血性脑卒中发病率预测方法并通过实验验证其有效性。下一步工作中将采用深度学习技术自动提取影响缺血性脑卒中发病的重要因素,设计一种基于图卷积神经网络的缺血性脑卒中发病率预测方法,为医生智能诊疗提供更好的技术支持。
猜你喜欢
法律方法(2022年2期)2022-10-20
中学生百科·大语文(2021年11期)2021-12-05
中老年保健(2021年9期)2021-08-24
纺织科学研究(2021年7期)2021-08-14
医学新知(2019年4期)2020-01-02
心肺血管病杂志(2019年9期)2019-12-09
中医眼耳鼻喉杂志(2019年3期)2019-04-13
37°女人(2017年11期)2017-11-14
中国民族医药杂志(2016年5期)2016-05-09
中国卫生标准管理(2015年17期)2016-01-20
