
基于随机森林算法的复杂碳酸盐岩岩性识别
2020-11-19 06:26:16杨添微刘永震张占松
工程地球物理学报 2020年5期
王 啟,杨添微,刘永震,聂 昕,2,张占松,2,万 宇,2
(1.长江大学 地球物理与石油资源学院,湖北 武汉 430100;2.长江大学 油气资源与勘探技术教育部重点实验室,湖北 武汉 430100)
1 引 言
随着世界石油和天然气的不断深入勘探和开发,具有良好物性的储层日益减少,油气储量日益下降,复杂岩性的储层开始进入人们的视线,其中碳酸盐岩储层油气藏已发展为国内重要的新型油气资源[1],也是目前中国石油化工企业在海内外投资主要的油气藏类型[2]。复杂碳酸盐岩储层具有非常强的非均质性[3,4],因此在岩性识别上十分困难。地层岩性最直接的识别方法是采用钻井取芯,但是由于井式取芯成本高昂,所以一般不采用这种方法。现有岩性识别方法主要为通过少量测井岩芯来标定测井曲线,并利用所得测井曲线数据进行全井段的岩性识别。常见的测井岩性识别方法有:测井资料交会图法、聚类分析识别方法及模式识别分析方法[5-7]。但是采用测井资料交会图法仍然存在难以准确识别矿物复杂,储层的岩性条件变化多样等问题,而聚类分析识别方法也同样存在着在岩性识别中无法有效保证精度的重要缺陷[8]。因此为了解决复杂碳酸盐岩储层强非均质性所带来的测井曲线多解性的问题,目前人们常常采用支持向量机法[9]、神经网络及其衍生的方法[10]等非线性的智能信息处理技术来进行复杂碳酸盐岩储层岩性的识别。但是由于支持向量机法在分类时过于依赖核函数和惩罚参数的选取,所以对缺失的数据非常敏感,因此在解决多分类问题存在缺陷;而神经网络及其衍生的方法则存在易于陷入局部最小和收敛速度慢等问题,其参数选取和网络拓扑结构对识别结果的准确率影响很大,常常不能得到理想的结果[11]。
随机森林算法是利用多棵树对样本进行训练并预测的集成算法[12],具有训练高度并行化,对于大数据的大样本训练速度快,采用随机抽样,训练出来的模型方差小,泛化能力强,对部分特征缺失不敏感和实现比较简单等优势。且随机森林会通过在每个节点处随机选取特征值进行分支,使得每棵分类树间的相关性最小化,从而提高分类精确度[13-15]。本次研究利用随机森林算法的特性与优势,将其应用到复杂碳酸盐岩储层岩性的识别工作中。周雪晴等[16]将基于粗糙集-随机森林算法运用于伊拉克东南部某省的复杂岩性识别中,证明了该算法可提高复杂岩性储层的岩性识别精度,在测井解释问题中具有潜力。
本次研究首先从目的层中取得9口井的常规测井资料和岩性样本数据并进行整理,然后对测井曲线敏感性进行分析,采用Matlab的机器学习算法,选用随机森林算法分类器建立岩性预测算法模型,最后将训练好的随机森林算法模型对每口井进行全井段岩性分类预测。通过对研究区实际资料的处理结果进行分析可知,该方法稳定性高、回判率强,符合地层真实情况。
2 地质概况和资料收集
研究区目的层为中-下奥陶统碳酸盐岩,包括中奥陶统一间房组,中-下奥陶统-鹰山组(鹰一段、鹰二段、鹰三段和鹰四段)、下奥陶统-蓬莱坝组。一间房组几乎全部为灰岩,其中亮晶颗粒灰岩最为发育。鹰山组一、二段几乎全为灰岩,大量发育亮晶颗粒灰岩。鹰山组三段上部以灰岩为主,下部以白云岩为主,或白云岩夹薄层灰岩。鹰四段、蓬莱坝组以白云岩为主,夹灰岩,局部出现硅质交代或硅化作用。本地区岩性复杂,为测井岩性分类带来了困难。
本次研究工作共取得9口井的常规测井资料,包括无铀伽马(CGR)、钍(TH)、铀(U)、钾(K)、自然电位(SP)、自然伽马(GR)、补偿中子(CNL)、密度(DEN)、深侧向(LLD)、浅侧向(LLS)以及光电吸收截面指数(PE)、声波时差(DT)和MgCO3、CaCO3测井曲线,以及9个岩心薄片岩性鉴定结果。分别将9口井的岩性样本数据整理好,对各个岩心样本深度下对应的测井曲线进行整理,再按不同的岩性进行归类整理,分为三大类共10种岩性分类,整理结果见表1。

表1 目的层岩性分类
3 测井曲线敏感性分析
不同的测井曲线对不同的岩性响应敏感性不同[17-22],因此在开始岩性分类之前,必须要进行测井曲线敏感性分析。通过观测分析不同岩性对不同测井曲线值的影响,选取碳酸镁(MgCO3)/碳酸钙(CaCO3)、无铀伽马(CGR)/钍(Th)、铀(U)/钾(K)、自然电位(SP)/自然伽马(GR)、补偿中子(CNL)/密度(DEN)、深侧向(LLD)/浅侧向(LLS)以及光电吸收截面指数(PE)/声波时差(DT)这7组曲线制作交会图(图1~图3)。由图1~图3的交会图可知,CGR、Th、U、K、GR、PE、LLD、DEN、CNL、DT、MgCO3、CaCO3这12条测井曲线对岩性识别较为敏感,可利用其作为输入曲线进行岩性识别预测。
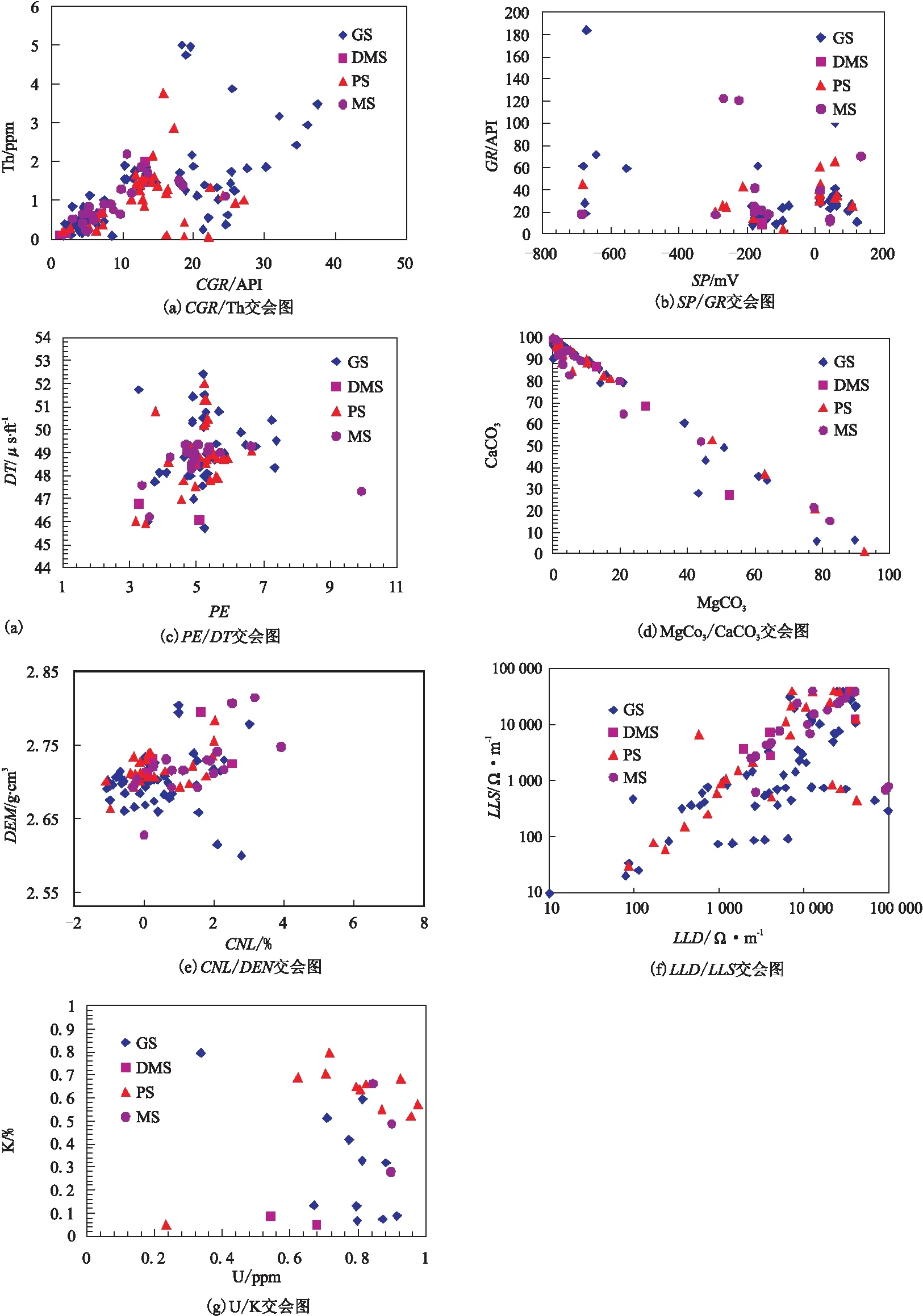
图1 灰岩类交会图Fig.1 Crossplots of limestone
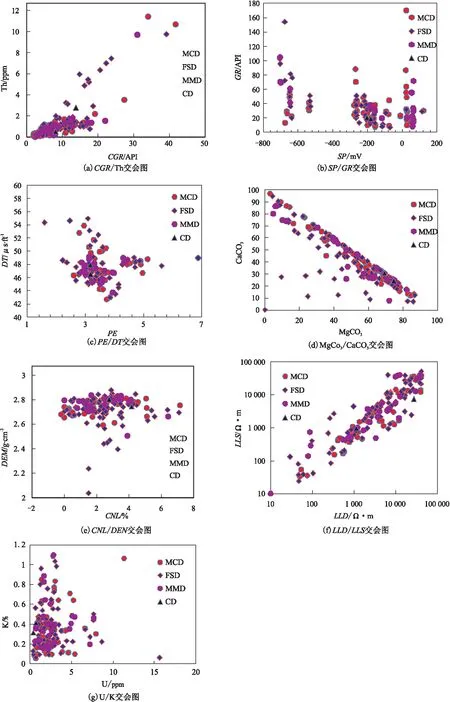
图2 白云岩类交会图Fig.2 Crossplots of dolomite
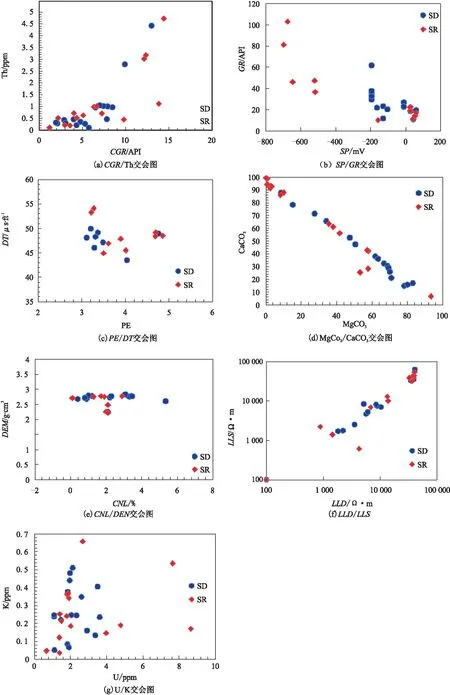
图3 硅化岩类交会图Fig.3 Crossplots of silicified rocks
4 随机森林及岩性预测模型的建立
随机森林是利用多棵树对样本进行训练并预测的一种分类器。在机器学习中,随机森林是一种包含了多个决策树的分类器,并且其输出的类别是由个别树输出的类别的众数而定的。它是Bagging算法的进化版。首先,随机森林使用了CART决策树作为弱学习器。其次,在使用决策树时,随机森林对决策树的建立做了改进,对于普通的决策树,会在节点上所有的n个样本特征中选择一个最优的特征来作为决策树的左右子树划分。但是随机森林则会随机选择节点上的m个样本特征(m 生成随机森林的具体步骤如下[23]: 1)样本集的选择。每轮从原始训练数据集中通过Bootstrap的方式抽取K个样本集,得到一个大小为K的训练集。在原始样本集的抽取过程中,有被重复抽取的样例,也可能有一次都没有被抽到的样例。共进行n轮的抽取,则每轮抽取的训练集分别为T1,T2,…,Tk。 2)构建决策树。假设特征空间共有M个特征,则在每一轮生成决策树的过程中,从M个特征中随机选择其中的m个特征(m 3)模型组合。因为生成的k个决策树之间是相互独立的,每个决策树的重要性是相等的,因而在将它们进行组合时,无需考虑他们的权值。在分类阶段,分类结果是由所有分类树的结果综合而成,使用的是投票原则; 为了验证随机森林法的效果,选取了贝叶斯分类和集成学习两种方法进行了对比,结果如表2所示。由表2可知,随机森林法的回判率远远高于其他两种方法,可以作为复杂碳酸盐岩岩性识别的优选方法。 表2 各类方法回判率对比 预测模型的建立过程如下:将通过敏感性分析后的12条测井曲线作为输入,样本岩性主要有灰岩、白云岩和硅化岩三类,采用两种方法进行岩性分类建模。第一种方法是直接对所有岩性进行建模,将GC8、GC10、GC13、GC15、GC16这五口曲线完整的井的CGR、Th、U、K、GR、PE、LLD、DEN、CNL、DT、MgCO3、CaCO3这12条测井曲线值作为岩心数据集建模A模型,导入到Matlab中,其余的4口井由于测井资料完整度不一致(GC7缺少PE测井曲线;GC9缺少LLD测井曲线;GC12缺少DT测井曲线;GC14缺少DEN测井曲线),所以分别对4口井(GC7、GC9、GC12、GC14)一一建模,总共5套模型,分别进行回判。第二种方法改进为间接建模,先建模3种大岩性,再建模10种小岩性。将总表按三种大岩性分开为灰岩类、白云岩类和硅化岩类,然后将三种岩性对应的测井曲线数据作为模型进行训练,得到能区分三大岩性的岩性预测模型,再在划分了岩性的总表中分别从GC8、GC10、GC13、GC15、GC16这五口曲线完整的井中提取小岩性数据到Matlab中,建立一套模型,然后将其余的四口井数据分开进行建模,得到总共5套模型,最后分别进行回判。 利用第一种方法直接建模,得到的回判率如表3所示。由表3可知,利用随机森林算法划分的岩性结果回判率非常好。但是由于岩性复杂,岩性小类太多,导致岩性判断的结果波动很大,与地质认识不是十分相符。于是采用第二种方法进行建模,得出的回判率如表4所示。 表3 回判率汇总 表4 建分大岩性后建分小岩性回判率 由表3和表4可见,两种建模方法的回判率都很高,说明该算法稳定性较强。最后将训练好的随机森林算法模型对每口井的全井段进行预测,并绘制各井的测井岩性剖面图,达到10余种细岩性的划分(分别为含灰白云岩、灰质白云岩;白云质泥晶灰岩、粉-细晶白云岩、亮晶颗粒灰岩、中-粗晶白云岩、泥-微晶白云岩、泥晶灰岩、泥-亮晶灰岩、含硅白云岩、硅质白云岩;硅质岩、含云硅质岩等),如图4所示。 图4 GC8井岩性剖面Fig.4 Lithologic section of well GC8 由图4可知,即使在岩性较为复杂多变,白云岩、灰岩、硅质岩交替出现的情况下,图中仍能准确清晰地显示结果,因此证明了随机森林方法在薄层识别中具有较大的优势,对岩性的识别较为准确。第二种方法由于有了针对性,最终岩性分类结果与人工精细地质分类的认识吻合得更好,但是基于计算机分类,大大提高了效率,减少了人为因素的干扰。 储层的岩性识别是储层勘探和开发的基础,针对复杂碳酸盐岩的强非均质性,利用随机森林算法,以三种大岩性对应的测井曲线数据作为模型进行训练,分别采用直接建模和间接建模的方法得到了能区分三大岩性的岩性预测模型,再提取小岩性数据建立5套模型分别进行回判。得到如下结论: 1)利用随机森林算法直接建模划分的岩性结果回判率较高。但是由于岩性复杂,岩性小类太多,导致岩性判断的结果波动较大,与地质认识并不相符。采用改进的间接建模的方法。间接建模划分的岩性结果回判率依然较高,岩性分类结果与地质认识吻合更好,可运用于实际工作中。 2)即使在岩性较为复杂多变,白云岩、灰岩、硅质岩交替出现的情况下,岩性剖面图中仍能准确清晰地显示结果,因此证明了随机森林方法在薄层识别中具有较大的优势,对岩性的识别较为准确。 3)随机森林算法预测的结果稳定性强,样本的预测精度及回判率较高,可以有效地提高复杂碳酸盐岩储层的岩性识别精度,在测井解释问题中具有一定的优势和潜力,可以为复杂碳酸盐岩储层的勘探开发提供帮助。
5 模型应用效果分析



5 结 论
猜你喜欢
山东冶金(2022年2期)2022-08-08 01:51:38黑龙江水利科技(2020年8期)2021-01-21 09:27:44成都信息工程大学学报(2019年3期)2019-09-25 08:31:20石油地质与工程(2019年3期)2019-09-10 08:27:42科学导报·学术(2019年21期)2019-09-10 05:22:02电子制作(2018年16期)2018-09-26 03:27:06录井工程(2017年4期)2017-03-16 06:10:28中央民族大学学报(自然科学版)(2016年4期)2016-06-27 08:06:04西南石油大学学报(自然科学版)(2015年4期)2015-08-20 09:05:08郑州大学学报(医学版)(2015年1期)2015-02-27 14:50:26
