
NVIDIA GeForce RTX 3080全球首发评测
2020-11-16 07:13《微型计算机》评测室
微型计算机 2020年19期
《微型计算机》评测室

RTX 30系列产品综合概述
RTX30系列首发产品有三款,也就是前文介绍的GeForceRTX3090、GeForceRTX3080和GeForceRTX3070。其中最先上市的是RTX3080,国内上市时间为9月17日,价格为5499元起。随后是RTX3090,上市时间为9月24日,国内定价11999元起。最晚上市的是RTX3070,上市时间是10月15日,国内定价仅为3899元起。从参数对比来看,RTX30系列最显著的变化便是换用了三星的8nm工艺,同时CUDA核心的数量大幅度增长,单精度计算性能、张量核心性能暴增。另外,RTX30系列的功耗也显著增加,顶级的RTX3090和高端的RTX3080在TDP功耗上均突破了300W,难怪NVIDIA建议玩家为RTX3090、RTX3080配备750W以上的电源。
RTX30系列在工艺上采用的是三星的8nm工艺。和之前NVIDIA在顶级产品上偏爱台积电的工艺不同的是,Ampere显卡所使用的制程工艺的确有点出乎大众预料。三星8nm工艺在实际的工艺代次上是属于10nm工艺的改进版本,属于典型的半代工艺。其存在两个版本,分别是8nmLPP和8nmLPU。但是三星没有给出更多有关8nmLPU的数据,可能和三星之前宣布的高密度库有关。NVIDIA本次RTX30系列显卡,有可能选择的是三星8nm工艺的LPU版本,但是目前没有更多消息可供证明。
在采用了三星8nm工艺后,相比上代同为面向图形的TU102核心,GA102核心的晶体管数量增加了大约50%,但是整体芯片面积却降低了17%。RTX30系列GPU所使用的8nm工艺的晶体管密度为4458万/mm2,之前RTX20系列使用12nmFFN工艺的晶体管密度为2467万/mm2,新工艺的晶体管密度是之前工艺的1.8倍。
性能飞跃式增长,RTX30系列GPU架构解读
RTX30系列GPU在架构上最大的变化是改用了全新的安培(Ampere)架构。有关安培架构的内容,本刊在之前的《来自540亿晶体管的力量—全新NVIDIA安培架构和A100GPU深入解读》一文中已经做出了比较详细的解读。不过,之前NVIDIA在发布A100GPU的时候,无论是GPU本身还是架构设计都更偏向于计算,在面向图形应用时,偏向计算的架构显然是无法适应图形计算的需求的,因此NVIDIA在同为安培架构、面向不同计算场合的芯片设计上,采用了针对性的改进。可以这样理解,目前我们看到的RTX30系列显卡,采用的是面向图形的安培架构,它和面向计算的安培架构有一定的相似之处,但是侧重点完全不同。
GA102和GA104的宏观架构
NVIDIA给出了完整版本GA102芯片的信息。根据这些内容显示,GA102芯片前端设计PCIe4.0总线控制器和常见的极线程分发器(GigaThreadEngine),数据通过这两个端口进入GPC中。GA102内部一共包含了7个GPC,每个GPC内部包含6個TPC,一共拥有42个TPC。每个TPC包含2个SM模块和一个PolyMorphEngine(几何处理引擎,用于曲面细分计算),也就是84个SM模块和42个PolyMorphEngine。在安培架构上,NVIDIA定义一个SM模块内拥有等效128个CUDA核心或者流处理器,那么完整版本的GA102就包含了等效10752个CUDA核心。显存控制器方面,GA102拥有12组显存控制器,每组32bit,组成了384bit的规格,后端还包括用于全局连接的高速Hub和4通道NVLink总线。
值得注意的是,GA102内部还有168个FP64单元(每个SM内有2个),但是在宏观架构图中并未显示。FP64的计算性能是FP32单元的1/64。在这里加入少量FP64单元的目的主要是考虑到部分程序中有少量FP64计算任务,以及张量核心也有部分FP64数据需要计算。当然,相比A100GPU中庞大的FP64规模,这里的FP64单元仅仅是为满足基本计算需求而设定。
继续向下深入探讨的话,安培核心的SM,除了包含等效128个CUDA核心外,还包含4个第三代Tensor Core张量核心、256KB的寄存器、4个纹理单元、1个第二代光线追踪核心以及128KB的L1/共享缓存。另外核心内部还为每个显存控制器配备了512KB的L2缓存,总计6144KB。
再来看GA10 4。RT X 3070使用的芯片代号是GA10 4-300- A1,按照惯例,NVIDIA会使用GXXX- 400作为比较接近完整版芯片的产品代号。根据NVIDIA数据,GA104的完整版本有6个GPC、24个TCP和48个SM,等效6144个CUDA核心。GA104-300-A1则屏蔽了1个TPC,最终只包含了6个GPC、23个TCP和46个SM,以及等效5888个CUDA核心,所以RTX 3070SUPER或RTX 3070 Ti理论上应该是有空间的。
总的来说,从宏观架构来看,安培架构和之前的图灵架构存在非常相似的地方,这也是NVIDIA使用多年的、GPC-TPC- SMCUDA核心四级层级的继承和发展。今天我们看到的面向图形的安培架构和面向计算的安培架构其差别之大甚至接近两代GPU的架构差异,虽然部分技术可能来源相同,但由于最终目标不同,因此两者的差异鲜明。
SM模块解析
SM(Streaming Multi- processer,流式多处理器模块)模块一直是NVIDIA GPU的计算核心。在之前面向计算的A100上,SM模块的基本配置情况是1个完整的SM模块包含了64个INT 32单元、64个FP32单元(也就是CUDA核心)以及32个FP64单元、4个第三代张量核心,分别针对传统的数据处理、双精度计算和AI计算三种任务。不过,在新的GA10X核心的安培架构上,由于计算任务的变化,和A100的SM模块相比,GA10X的SM模块也有了巨大的变化。
NVIDIA从RTX 20系列开始,就将图形计算部分划分为三个类型,那就是传统图形数据计算、光线追踪计算和AI计算。在图灵架构上,这三个部分使用的分别是图灵架构SM、第一代RTCore以及第二代Tensor Core,后两者都是NVIDIA的独家方案。在新的面向图形计算的安培架构中,这三个计算任务依旧被完整地保留了下来,并共同组成了全新的安培SM模块。
面向图形的安培SM模块的基本配置和之前的图灵架构在宏观结构上是基本相同的。整个SM中都包含了4个计算单元,128KB的L1缓存和共享内存以及4个纹理单元、RT核心等。其主要变化发生在计算单元内部。
在之前的图灵SM模块的单个计算单元配置上(4个SM计算单元组成一个SM模块),每个SM模块中的计算单元拥有1个warp调度单元和1个派遣单元,16384×32bit寄存器、16个FP32内核和16个INT32内核,2个张量核心以及后端的LD/ST单元、特殊功能单元(Special Function Unit,简称SFU)等。
在新的GA10X安培SM的计算单元内部,依旧配置了1个warp调度单元和1个派遣单元、16384×32bit寄存器和后端LD/ST、SFU单元,但是在计算的部分却包含了1组16个可自由执行FP32和INT32计算的双功能计算单元(ALU)—它们既可以完成FP32计算,又可以完成INT32计算,另外还包含了1组16个FP32计算单元和1个新的第三代张量核心。
由于SM设计的变化,因此安培架构相比图灵架构显示出巨大的功能性和性能导向差异。最典型的就是CUDA核心的数量方面,NVIDIA一直以来都将1个FP32单元作为1个CUDA核心来计数和宣传,但是在本次使用了INT32和FP32双功能设计、并额外增加了FP32单元后,可宣传的CUDA核心数量就大大增加了。比如同为4个SM计算单元组成的SM模块,GA10X安培架构拥有等效128个CUDA核心、面向计算的A1xx安培架构拥有64个CUDA核心,图灵架构也拥有64个CUDA核心,这也是NVIDIA宣传GA10X安培架构SM模块2倍于图灵架构的数字计量来源。
但是,这并不意味着安培架构在FP32计算性能上随时都能保证达到图灵架构的2倍,毕竟安培架构的每个SM模块中只有64个“纯粹”的FP32单元,其余64个是双功能单元。这意味着当计算任务的数据格式以混合INT和FP格式占据这些单元时,安培架构的SM模块每周期所呈现的FP计算能力就会根据计算任务而变化,最极端情况下会降低至和图灵架构相同(假设INT32占据了所有64个双功能单元),或者呈现图灵架构的2倍(全部都是FP32计算)。
考虑到目前复杂的图形计算任务,采用FP32+INT32混组核心的设计的优势是能够带来每晶体管性能的显著提升。毕竟计算任务并不会老老实实地按照设计规范出现。举例来说,一个计算任务中包含了20个INT計算和80个FP计算时,在图灵架构下,20个INT计算任务在1个时钟周期内就可以完成,但是80个FP计算就需要2个时钟周期才能完成。其中部分INT32核心在此时就会被闲置,每晶体管性能就会降低。换到安培架构,20个INT计算任务会分配20个双功能核心的INT32功能完成(剩余48个双功能核心),其余80个计算任务中的64个可以交给固定FP32核心,另外16个可以交给双功能核心的FP32功能完成。那么,1个时钟周期就可以完成所有的计算任务,效率自然能得到大幅度提升。
总的来看,在计算任务全部都是FP32的情况下,新的安培架构的1个SM可以视同拥有128个FP32计算单元、4个第三代张量核心和1个RT核心。因此,NVIDIA特别提到,现代游戏工作负载具有广泛的处理需求,许多工作负载混合使用FP32算术指令(例如FFMA、浮点加法FADD、浮点乘法FMUL等),以及许多更简单的整数指令,例如用于寻址和获取数据算法,或者用于处理结果等。因此,在图灵架构上,NVIDIA增加了新的计算路径后,大幅度提升了这类算法的自由度和工作效能,从而带来了不错的性能优势。在安培架构上,这样的设计被强化了,浮点计算可以根据需求选择任何一组计算单元(计算路径),根据Shader指令和应用程序设计的不同,性能将有所变化,具体取决于指令的应用方式。比如光线追踪降噪计算全部都是FP指令,能够充分利用新的双功能计算单元和传统的FP32单元,显著提升性能。
此外,在L1缓存部分,安培架构的SM L1共享缓存应用下的带宽相比图灵架构翻倍,安培架构的SM共享缓存带宽为每时钟周期128bytes,而图灵架构为每时钟周期64bytes。这样一来,RTX 3080的总L1带宽为219GB/s,RTX 2080 SUPER仅有116GB/s。
在缓存方面,安培架构的SM缓存容量从之前的96KB提升到了128KB,容量增大了33%,这有助于存放更多的数据在L1缓存中,减少数据不断地从外部存储调用的频率,能提高性能并降低功耗。完整的GA102包含10752KB的L1缓存,对比TU102为6912KB。此外,NVIDIA还给出了L1和共享缓存的容量配置表,L1和共享缓存的可配置方案如下:
128KB L1 + 0 KB共享内存
120KB L1 + 8 KB共享内存
112KB L1 + 16 KB共享内存
96KB L1 + 32 KB共享内存
64KB L1 + 64 KB共享内存
28KB L1 + 100 KB共享内存
NVIDIA特别提到,对于图形工作负载和异步计算,GA102将分配6 4KB L1数据纹理缓存(相比之下图灵架构仅能分配32KB)、48KB共享内存和16 KB保留用于各种图形管线操作。
光线追踪模块
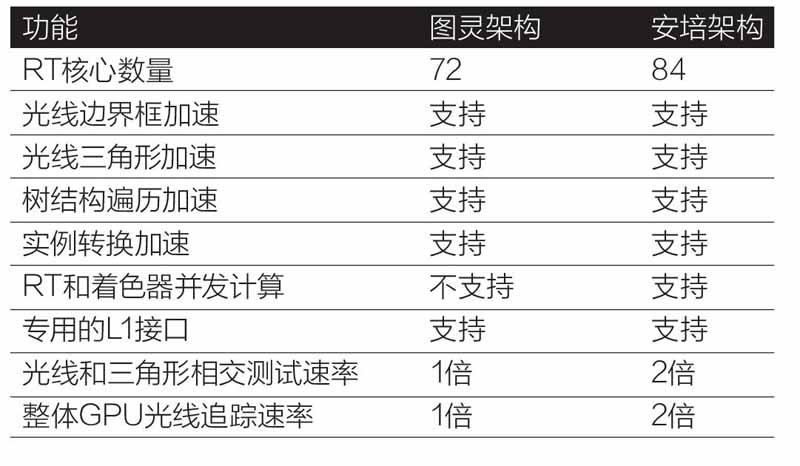
在之前的图灵架构上,NVIDIA引入了光线追踪模块(下简称为“RT模块”)。RT模块的主要作用是针对光线追踪计算中最耗费时间的加速边界体积层次(BVH)遍历和光线/三角形(基元)交叉测试(光线投射)过程进行加速,将整个光线追踪计算的时间降低至可接受的范围内。
有关光线追踪计算的基本情况,我们在2018年的《生而为光—NVIDIA“图灵”架构解析》一文中有非常详细的介绍,因此本文仅作简单回顾性介绍,有需要的读者可以翻看之前的内容。
光线追踪计算的过程,是通过图像平面中的每个像素从相机(观察者的眼睛)射出一条或者多条光线,然后测试光线是否和场景中的任何基元相交。由于光线和基元在场景中的碰撞检测非常重要,因此一种流行的算法就是使用基于树的加速结构,其中包含了多个分层排列的边界框,边界框包围或者围绕着不同数量的场景几何体,大的边界框可能包含了较小的边界框,较小的边界框内再包含实际的场景物体。这种分层排列的边界框被称为边界体积层次结构,或者BVH。BVH通常被列成具有多个级别的树形结构,每个级别都有一个或者多个节点,从顶层的单根节点开始,向下流入不同级别的多个后代节点。
光线追踪计算更适合多指令多数据流形式的计算,因此需要专门的MIMD执行单元。此外,在硬件计算上最好也能够为其进行优化。在这种情况下,NVIDIA设计了专门的BVH遍历计算器以及三角形交叉测试单元,能够以极高的效率完成整个场景的光线追踪计算,这就是图灵核心上开始出现的RT模块中包含的RTCore。而在新的安培架构上,NVIDIA又对RT模块的性能进行了增强。面向图形的安培架构GPU加入了新的增强异步计算效能的功能,该功能允许在每个安培架构GPU的SM中同时处理光线追踪计算和图形计算,或光线追踪计算和数学计算工作负载。在这种情况下,安培架构的SM可以同时处理两个计算工作负载,并且不限于像以前的GPU那样只能同时进行数学计算和图形处理(光线追踪计算需要等待),从而使基于計算的降噪算法等方案可以与光线追踪计算可以同时运行,极大地提高了代码执行效能。
除了上述性能提升外,NVIDIA在安培架构的光线追踪模块中还带来了比较重要的技术创新,那就是光线追踪动态模糊加速。动态模糊是一种非常流行且重要的计算机图形效果,可用于电影、游戏和许多不同类型的专业渲染应用程序中。动态模糊的本质和胶片摄影相关,因为胶片摄影时,图像不是立即创建的,而是通过将胶片在有限的时间段内曝光来创建的。这意味着目标物体在胶片快门时间内的高速移动将带来模糊的曝光效果。对GPU来说,要创建类似效果,必须模拟相机和胶片工作流程。动态模糊对于电影是非常重要的,它能够避免画面出现断续卡顿的效果,对游戏来说亦是如此。
现代GPU动态模糊实现上有多种手段,这些技术既可以用于电影中的离线高质量渲染,也可以用于游戏等实时应用。高质量的模糊效果通常需要在某个时间间隔内渲染和混合多个帧,还需要后处理进一步改善结果,因此对算力要求极高。人们需要使用更为真实的模拟来实现动态模糊,比如光线追踪。在使用了光线追踪之后,动态模糊可以看起来更准确和逼真,而不会出现不需要的伪影,但是在GPU上渲染也可能需要很长时间,因此需要硬件加速来快速实现这个结果。
目前有多种算法可以结合光线追踪实现动态模糊。一种流行的算法是将许多带有时间戳的光线随机发射到场景中。具有动态模糊功能的BVH会针对在一段时间内移动的几何图形返回光线的命中信息,该几何图形的采样点是光线相关的时间函数。然后将这些样本着色并合并以创建最终的模糊效果。NVIDIA自2017年推出OptiX 5.0以来,就已经能够支持这项技术。
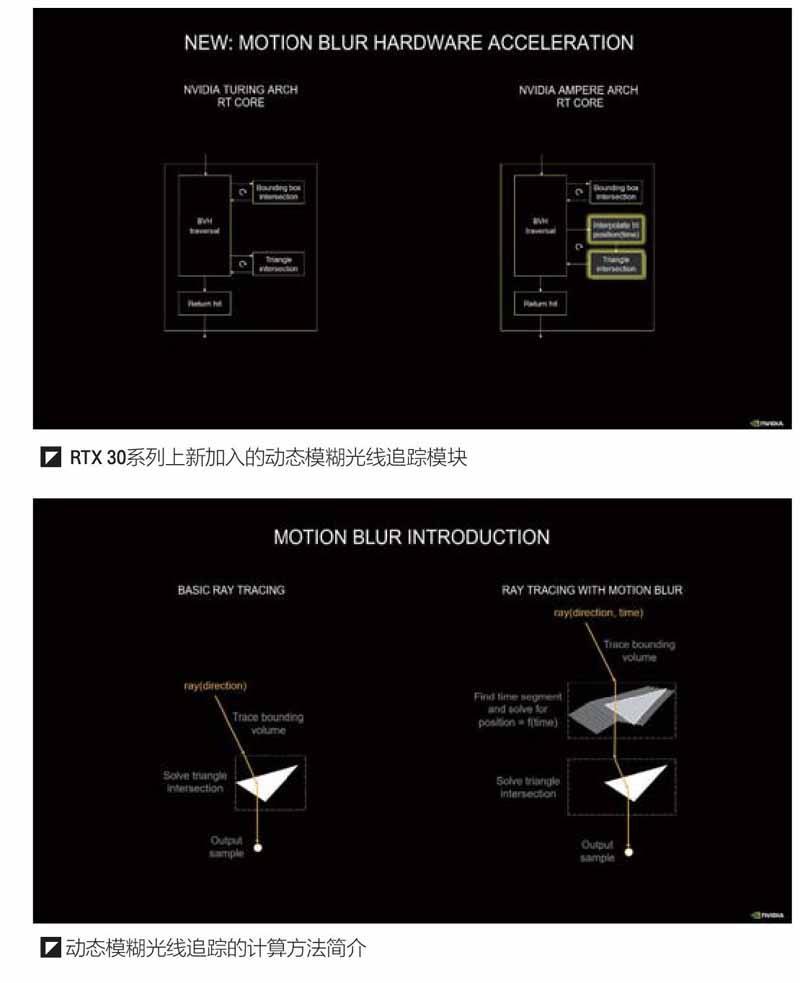
在动态模糊计算方面,之前的图灵架构可以很好地加速运动相机类型的运动模糊,它能够在一定时间间隔内将多束光线射入场景,光线追踪核心可以加速BVH遍历,执行光线和三角形相交测试并返回结果以创建模糊效果。但是,图灵架构在遇到BVH信息随对象移动而变化的情况下,就很难在给定的时间间隔内对移动的几何体执行运动模糊计算了。现在,新的安培架构的光线追踪核心通过加入新的加速功能,和经过修改的BVH配合使用,可以显着加速运动的几何形状的动态模糊计算。
NVIDIA给出了2个对比图用于解释这个过程。首先来看单个光线的计算过程。在单光线的基础的光线追踪计算中,光线只是方向的函数,通过跟踪给定的目标体积边界,解决了三角形相交问题,从而能够输出光线的追踪采样值。在加入了动态模糊后,单个光线的计算将拥有2个变量,分别是方向和时间,同样是通过跟踪给定的目标体积边界,然后查找此时物体运动的时间,求解位置有关的时间函数f(time)后,得到物体在此时的位置,再解决三角形相交问题,最终再输出光线的追踪采样值。
在实际的计算中,光线计算会以多方向的形式进行输出,在没有动态模糊的情况下,不同光线匹配不同的方向,通过和单光线计算一样的方式,输出多个结果,碰撞测试,返回结果,完成光线追踪采样。在加入了动态模糊后,每个入射光线将被分配一个时间戳,这样一来多光线、多方向和多个时间组成了复杂的计算阵列,此时需要同时计算物体在不同时间戳f(time)的位置后,再进行后续计算。比如图中橙色光线尝试在不同的时间点与橙色三角形相交,绿色和蓝色光线分别尝试与绿色和蓝色三角形相交,如果命中则报告位置和结果。根据NVIDIA的介绍,安培架构中加入的全新“Interpolate Triangle Position unit(内插三角形位置单元)”能够在BVH过程中,基于对象运动现有位置和动态方向插入新的三角形,以便光线可以在时间戳指定的时间内,在对象空间中的期望位置处与插入的三角形相交。这个新单元可以进行精确的光线追踪运动模糊渲染,其渲染速度比图灵架构的光线追踪单元快8倍。当然,最终的结果输出将采用滤波计算后的结果,结果是一个模糊的状态,正如图中显示的那样。
猜你喜欢
消费电子(2022年5期)2022-08-15
江苏安全生产(2021年12期)2021-03-08
环球时报(2019-07-16)2019-07-16
中外文摘(2019年8期)2019-04-30
小猕猴学习画刊(2017年12期)2017-12-26
商界·时尚(2016年5期)2016-07-15
自动化学报(2016年5期)2016-04-16
创新作文(小学版)(2016年28期)2016-02-28
发明与创新(2015年39期)2015-12-29
故事作文·高年级(2015年5期)2015-09-08
