
基于MFCC特征的被动水声目标深度学习分类方法
2020-11-14 07:17杨路飞章新华吴秉坤李兰瑞
舰船科学技术 2020年10期
杨路飞,章新华,吴秉坤,李兰瑞
(1.海军大连舰艇学院,辽宁大连116018;2.海军装备部驻上海地区第一军事代表室,上海200120)
0 引言
被动声呐目标识别[1]一直是水下对抗与反潜研究领域的热点和难点。传统的被动声呐分类模型有基于专家系统的,如支持向量机,有基于浅层机器学习的,如BP(Back Propagation)神经网络[2]。支持向量机具有所需训练样本数量少,泛化性能好的优点,但存在着大样本处理复杂等缺点。BP神经网络具有大规模样本处理能力,鲁棒性好的优点,但存在容易过拟合,学习不到样本的深度特征等缺点。
将深度学习应用于被动声呐目标分类问题已经是研究的趋势[3–9]。近些年,深度学习[10–13]在语音识别领域取得了突破性进展,长短时记忆网络[14](Long Short Term Memory Network,LSTM)处理时序数据能力强,基于感知机理的语音梅尔频率倒谱系数(MFCC)的LSTM模型应用最广泛。已有研究者将MFCC与LSTM应用于被动声呐目标分类,取得较好识别能力,但LSTM模型预训练收敛速度慢,循环次数多且需大量的样本,预训练准确率才能趋于平稳。卷积神经网[15](Convolutional Neural Network,CNN)可以学习到样本数据的空间深度特征,通常研究者会提取被动声呐目标的二维图像特征进行分类。研究表明一维卷积神经网络(1DCNN)比二维卷积神经网络(2DCNN)更适合处理语音信号,收敛速度更快。本文通过提取水上和水下被动声呐目标的MFCC特征,结合1DCNN提取空间深度特征的能力与LSTM提取时序深度特征的能力,构建一个Conv-LSTM深度学习网络架构的分类模型,用于被动声呐目标分类。
1 被动声呐目标MFCC特征的提取
在语音识别方面,常用到的特征是梅尔倒谱系数(Mel-scale Frequency Cepstal Coefficients,简称MFCC)。根据人耳机理的研究发现,人耳对不同频率的声波有不同的听觉敏感度,对低频敏感度较高,对高频敏感度较低。MFCC[16]是在Mel标度频率域提取出来的倒谱参数,Mel标度描述了人耳频率非线性特性,它与频率的关系可近似表示为:

参数MFCC提取过程如图1所示。
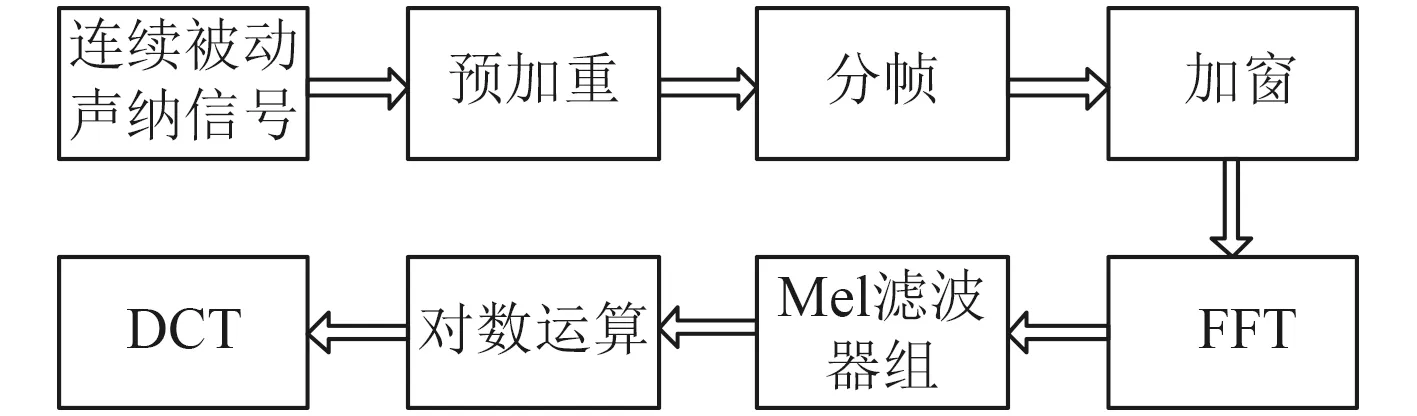
图1 MFCC系数提取过程Fig.1 MFCCcoefficient extraction process
预加重可以提升信号的高频部分,使信号的频谱变得平坦,能用相同的信噪比求频谱。语音信号一帧s(n)一般取20~30 ms,为避免相邻两帧变化较大,要取一段重叠区域,一般取一帧的0.3~0.5。将每一帧乘以一个汉明窗,即带通滤波器:
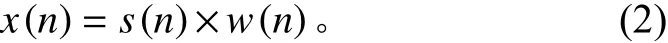
s(n)w(n)x(n)
式中: 为分帧后信号; 为窗口函数,为加窗后的信号。
将每帧进行快速傅里叶变换得到每帧在频谱上的能量分布:

式中,N为采样点的个数。
将能量谱通过一组Mel尺度的三角形滤波器组。三角形滤波器组的作用是对频谱进行平滑,消除谐波,还可以降低运算量,三角形滤波器的频带宽度随级数的增大而变宽。
三角形滤波器的频率响应为:

计算每个滤波器组输出的对数能量:

最后经离散余弦变换(DCT)得到MFCC系数:
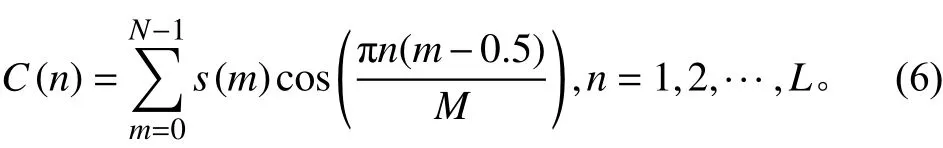
式中,L阶指MFCC系数的阶数。
标准的倒谱参数MFCC只反映了信号参数的静态特性,信号的动态特性可以用这些静态特征的差分谱来描述。差分参数的计算公式为:
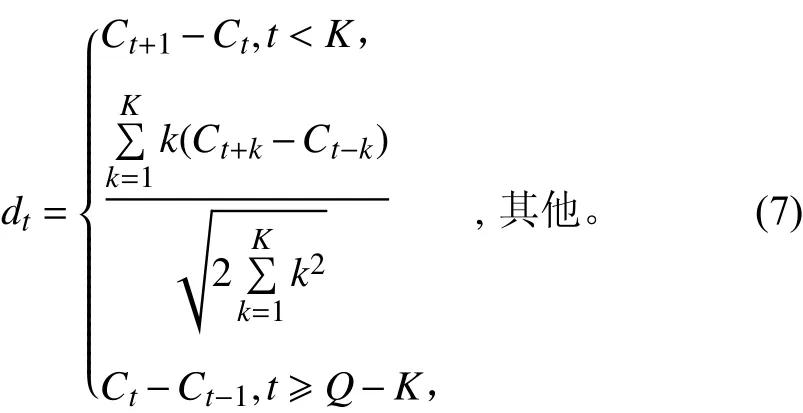
式中:dt表示第t个1阶差分;Ct表示第t个倒谱系数;Q表示倒谱系数的阶数;K表示1阶导数的时间差,可取1或2。将上式中结果再带入就可以得到2阶差分的参数[17]。
本文提取被动声纳目标的静态特性(MFCC系数)和动态特性(1阶差分,2阶差分),作为被动声纳目标分类的特征,即MFCC特征。
2 深度学习分类模型
2.1 一维卷积神经网络模型
卷积神经网络(CNN)可以较好识别数据中的简单模式,从而生成更复杂的模式,是一种监督学习的判别模型,其具有局部连接、权值共享、下采样的特点。二维卷积神经网络(2DCNN)主要用于图像识别,一维卷积神经网络(1DCNN)主要用于处理语音的任务。无论几维的卷积神经网络,都具有相同的特点和相同的处理办法。CNN主要由输入层、卷积层、池化层、全连接层和输出层组成。1DCNN基本结构如图2所示。

图2 一维卷积神经网络简单模型Fig.2 Simple model of one-dimensional convolutional neural network
卷积层由多个滤波器组成,学习输入数据的特征表示,不同大小的卷积核可提取出不同的特征信息,而权值共享的方式减少了模型的复杂度,减少了过拟合的风险,提高了模型的泛化能力。池化层一般连接在卷积层之后,对特征进行降维,常用的方法包括最大池化和平均池化。全连接层通过反向传播算法对网络中的参数进行训练,来最小化损失函数[18]。损失函数常使用交叉熵函数。引入Dropout技术,减轻网络过拟合,降低训练模型计算量。
本文处理的被动声呐目标辐射噪声信号属于声音,提取的MFCC特征也具有序列特性,所以本文采用1DCNN处理被动声呐信号的MFCC,获取数据的卷积深度特征。
2.2 LSTM深度学习模型原理
LSTM是循环神经网络[19](RNN)的改进型,是为了解决RNN模型训练过程中存在梯度消失或梯度爆炸等问题提出的。目前,LSTM逐渐取代RNN,成为处理语音任务的主要模型。典型LSTM单元如图3所示。

图3 典型LSTM单元Fig.3 Typical LSTM units
LSTM存在3个门:遗忘门(Forget gate),更新门(Update gate),输出门(Output gate),分别用Gu,Gf,Go来 表 示。输 入 为at−1,ct−1,xt,输 出 为at,ct,yt,。遗忘门和更新门决定ct的值,输出门决定at的值。具体公式为:
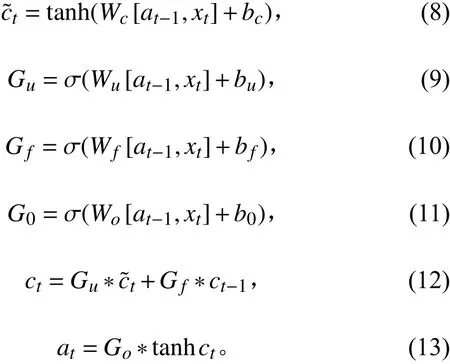
式中:wc,wu,wf,wo为权值;bc,bu,bf,bo为偏置。
本文采用LSTM处理被动声呐信号的MFCC特征,获取数据的时序深度特征。
2.3 Conv-LSTM模型
被动声呐目标信号是一种声音信号,具有时间序列特性。MFCC特征是声音信号经过分帧后处理得到的特征数据,具有空间连续特性以及时序连续特性。1DCNN可以用来处理语音信号,利用其空间特性提取了数据的空间深度特征,LSTM具有提取数据时序深度特性的能力,常被用来处理带有时间序列性质的问题。根据两种模型的特性,本文构造一种1DCNN和LSTM结合的深度学习分类模型Conv-LSTM,充分将被动声纳信号提取的MFCC特征的时空特性用于分类识别。Conv-LSTM模型的网络架构如图4所示。

图4 Conv-LSTM分类模型网络架构Fig.4 Network architecture of Conv-LSTM classification model
卷积层之间添加了BatchNorm层,在预训练过程中,使得每一层神经网络的输入保持相同分布,训练收敛快,加快训练速度。使用GlobalAveragePooling进行均值池化,输出为一维卷积深度特征。MFCC特征经过LSTM模块后,再经过Flatten操作得到一维时序深度特征。将卷积深度特征与时序深度特征经过Concatenate操作得到联合深度特征,最后通过BP算法进行目标的分类。
3 基于MFCC的被动声呐目标信号实测数据的实验
本文使用实测的被动声呐目标信号,提取听觉特征MFCC,对1DCNN,LSTM和Conv-LSTM的分类性能进行实验。
本文实验是水上水下分类识别的二分类问题,选取A,B两类的实测被动声呐目标辐射噪声信号,每类目标信号的采样频率为25 kHz。其中信号A是商船等各种类型的水上目标,信号B为水下目标,且包含了同一艘船、艇在不同工况条件下的信号,保证了样本集的有效性和实用性。提取目标信号的听觉特征MFCC,分帧时长为30 ms,帧移为12 ms,mel滤波器的阶数为24阶,20 ms提取一个36维的MFCC特征向量,取时长1.31 s的被动声呐目标信号的MFCC为一个样本,如图5所示,构建样本集。
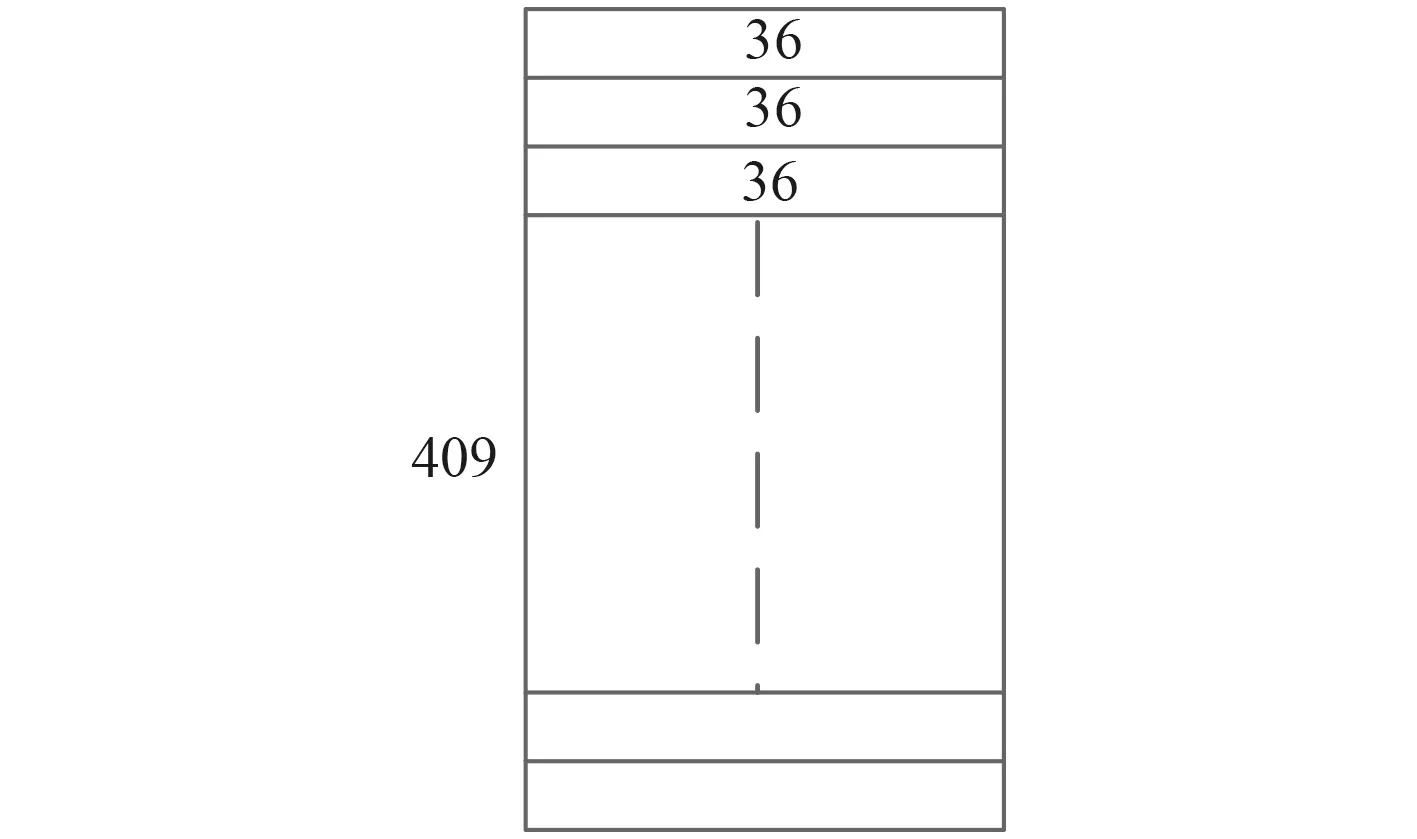
图5 目标MFCC特征的一个样本Fig.5 A sample of the characteristics of the target MFCC
超参数的设置对于深度学习模型训练的效果影响很大,为了保证实验结果的合理性,为了提高目标分类识别的准确率,进行超参数的调整。
对于1DCNN模型,卷积层为3层,滤波器的个数分别为64,128,64,窗口大小为4,卷积层和池化层的激活函数选用Relu,全连接层为2层,每层神经网络单元个数分别是128,64,对于二分类问题,输出层的激活函数选用sigmoid,学习率为0.01,优化器使用Adam,损失函数交叉熵函数选用Binary-crossentropy,分批训练大小为128,训练次数epochs设为100。
对于LSTM模型,LSTM单元个数为64,输出层的激活函数选用sigmoid,学习率为0.01,优化器使用Adam,损失函数交叉熵函数选用Binary-crossentropy,分批训练大小为128,训练次数epochs设为100。
对于Conv-LSTM模型,一维卷积模块中卷积层为3层,滤波器的个数分别为64,128,64,窗口大小为4,卷积层激活函数选用Relu,BatchNorm有3层,循坏模块与LSTM模型相同。输出层使用了’one-hot’编码。
实测数据中,每艘船的辐射噪声信号实测时长不同。其中,B类目标的数据样本少,A类目标的数据样本多。为保证深度学习模型训练过程的泛化能力,防止过拟合,A,B的训练集样本数不能相差太大。本文仿真实验采用2种样本构建方法对水声目标进行分类识别。
3.1 方案1及分类结果
在方案1中,选取A类船28艘,B类船12艘。该方案提取所有船只的MFCC特征,每隔5个MFCC特征选取一个作为训练集样本,其余MFCC特征作为测试集样本。样本构建结果如表1所示。

表1 水上、水下目标样本构建Tab. 1 Construction of water and underwater target samples
以预训练网络对测试集样本进行识别分析。为了使得深度学习模型训练更加均衡化,训练及样本通过shuffle进行了乱序。在每次深度网络模型训练过程,模型的权值与偏置的最终值会不同,损失函数可能落在不同的极小值点,从而使得测试集的准确率发生改变,所以本文所有实验重复5次,结果取平均值,如图6是某次深度学习Conv-LSTM模型预训练的准确率与损失函数变化过程。
分类识别结果如表2所示。
3.2 方案2及分类结果
方案2中同方案1,选取28艘A类船,12艘B类船。该方案分别从A,B类选取一部分船,提取MFCC特征构建训练集,未被挑选的船只提取MFCC特征,构建测试集。样本构建的结果如表3所示。

图6 预训练准确率与损失函数变化图Fig.6 Variation of pre-training accuracy and loss function

表2 水上、水下目标分类准确率Tab.2 Classification accuracy of water and water targets
分类识别结果如表4所示。
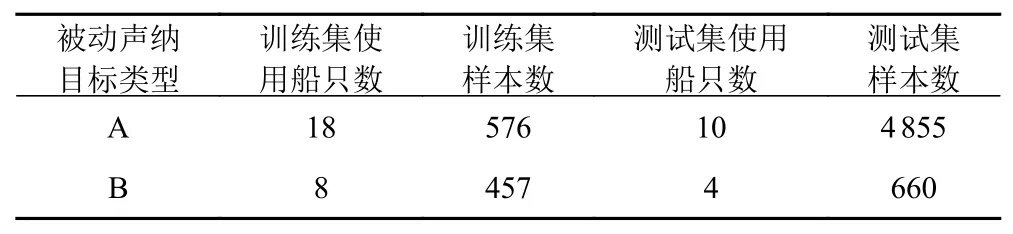
表3 水上、水下目标样本构建Tab.3 Construction of water and underwater target samples

表4 水上、水下目标分类准确率Tab.4 Classification accuracy of water and water targets
4 结语
本文从被动声呐目标分类出发,利用一维卷积神经网络(1DCNN)、循环神经网络(LSTM)以及构建的Conv-LSTM深度学习分类模型,对被动声呐目标的听觉特征MFCC进行提取与识别。根据海测数据处理以及深度学习分类模型的分类效果可得到如下结论:
提取被动声呐目标的听觉特征与深度学习分类模型结合,进行被动声呐目标分类具有可行性。
不同深度学习分类模型对于被动声呐目标分类效果不同。根据实测的被动声呐目标信号构建适合的深度学习分类器,可以提高被动声呐目标分类的准确率,Conv-LSTM相较于LSTM深度学习分类模型的分类准确率提高了4%左右。
深度学习可以从大量的样本数据中学习到目标的深度特征,由于实测样本数量较少。限制了对目标深度特征的挖掘,对于深度学习分类模型的泛化能力还需要进一步研究。
猜你喜欢
农业工程学报(2022年12期)2022-09-09
舰船科学技术(2022年11期)2022-07-15
北京航空航天大学学报(2021年9期)2021-11-02
北京航空航天大学学报(2021年9期)2021-11-02
计算机系统应用(2021年9期)2021-10-11
VOGUE服饰与美容(2020年5期)2020-09-03
现代兵器(2016年12期)2016-12-22
现代兵器(2016年12期)2016-12-22
