
基于深度学习的光学遥感图像目标检测方法综述
2020-11-11 02:58:42刘天颖李文根关佶红
无线电通信技术 2020年6期
刘天颖,李文根,关佶红
(同济大学 计算机科学技术系,上海 201804)
0 引言
遥感图像多指通过人造卫星等对地面观测得到的图像,优点是能在非常短的时间内获取大空间范围的数据。光学遥感是遥感中的一个分支,主要通过可见光、近红外及短波红外等传感器进行观测。由此得到的遥感图像分为可见光遥感图像、红外遥感图像以及高光谱图像等,其中可见光遥感图像是应用最为广泛的遥感图像之一。目标检测是光学遥感图像的一个热门应用,它要求从图像中检测出感兴趣的物体,例如船舶、飞机、车辆、建筑、耕地及水体等,在判断物体类别的同时给出其在图像中的位置。
早期,由于卫星图像的空间分辨率较低,研究者们无法检测到较小的物体,因此主要致力于提取某一区域的地理空间属性,如森林、湖泊等。近年来,光学遥感技术发展迅速,一些新型光学遥感卫星相继发射成功,获取的图像空间分辨率可以达到亚米级,能够提供非常精细的空间和纹理信息,这使得检测独立的目标个体成为可能。在受益于高质量数据的同时,光学遥感图像的目标检测也面临新的挑战:图像背景变得更加复杂,目标的尺度变化剧烈,小目标的数目变得更多等。这些挑战使得光学遥感图像的目标检测更易出现误检、漏检。
在海量高分辨率遥感图像数据的支持下,大量光学遥感图像相关的目标检测技术涌现出来,而其中基于深度学习的技术更是发展迅速,取得了非常不错的检测效果。因此,系统性总结领域内发展情况的综述文献就变得很重要。此前已有一些早期的相关工作,它们对一些特定类别的目标检测技术进行了总结,如Wang等[1]聚焦于图像中的船只检测,Mayer[2]则致力于检测建筑,而Mena等[3]专注于道路提取。此外,也有一些较新的多类别目标检测综述,如Cheng等[4]介绍了多种目标类别的检测技术。但是由于时间限制未能包含现在应用非常广泛的基于深度学习的技术;Li等[5]总结了深度学习给光学遥感图像的目标检测带来的影响,提出了一个新的大型光学遥感图像目标检测数据集,不过对相关技术分析不够;李晓斌等[6]从现代目标检测器的算法流程出发对相关技术进行了梳理,但是文中深度学习相关的方法仍然比较缺乏。与以上相关工作不同,本文着重梳理和分析近年来深度学习对光学遥感图像目标检测技术的影响,对基于深度学习的检测方法进行了分类分析。
从发展历史来看,面向光学遥感图像的目标检测技术发展离不开通用目标检测技术的发展。因此,本文首先简要介绍通用目标检测技术的发展脉络,然后归纳总结基于深度学习的光学遥感图像目标检测方法,最后分析目前仍存在的问题,并对未来可能的发展趋势做出了展望。
1 通用目标检测
现有通用目标检测模型可以分为传统模型和深度学习模型两大类,传统模型通过手工设计和提取图像特征进行目标检测,而深度学习模型通过自动学习数据特征进行目标检测。
1.1 传统目标检测模型
最早期的目标检测主要是基于模板匹配技术的模型和基于简单结构的模型,能够处理一些空间位置关系较为简单的物体。之后的主流方法经历了基于几何表示的方法和基于外观特征的统计分类方法,例如神经网络[7]、SVM[8]以及Adaboost[9]等。20世纪90年代之后,目标检测有了突破性的进展,两个里程碑分别是尺度不变特征转换算法(Scale-Invariant Feature Transform,SIFT)[10]和深度卷积神经网络(Convolutional Neural Networks,CNN)[11],前者革新了传统方法,后者则引领了深度学习的热潮。从SIFT算法开始,局部特征描述符受到了研究者的青睐,此后出现了许多相关的工作,例如Haar-like特征[12]及梯度直方图(Histogram of Gradients,HOG)[13]等。这些局部特征通常会经过简单的级联或者特征池编码器集成,例如空间金字塔匹配(Spatial Pyramid Matching,SPM)[14]及Fisher矢量(Fisher Vector)[15]等。之后提出的DPMs模型(Deformable Part based Models)[16]达到了传统目标检测模型的巅峰,连续取得了2007—2009年VOC[17]检测比赛的冠军。该方法是一种基于部件的检测方法,对目标的形变具有很强的鲁棒性,成为了众多机器视觉算法的核心部分。
传统方法虽然取得了不错的检测效果,但是往往设计得较为复杂,且缺乏提取图像高层次语义特征的能力,这限制了模型的检测精度。
1.2 基于深度学习的目标检测模型
2012年深度卷积神经网络AlexNet[11]在图像分类领域获得巨大成功,证明了深度学习模型的可行性。之后目标检测领域的学者也开始积极探索深度学习方法,由此诞生了基于深度学习的经典目标检测模型R-CNN[18]。该方法使用手工方法生成可能存在目标的候选区域,再对其进行筛选和调整,将目标检测问题转化为了分类和回归问题,使之可以被深度神经网络训练。R-CNN的性能大幅优于其他传统目标检测模型,开创了基于深度学习目标检测的时代。紧跟其后的工作,YOLO[19]去掉生成候选区域的步骤,直接对原图进行回归和分类,牺牲了一定精度,但大大加快了检测速度。以上两种方法后来发展为现代目标检测的两大分支:两阶段模型和一阶段模型,它们的框架分别如图1(a)和图1(b)所示,可以看出最大的区别是有无候选区域生成的步骤。两阶段模型以R-CNN系列为代表,包括Fast R-CNN[20]、Faster R-CNN[21]、Mask R-CNN[22]等;一阶段模型则以YOLO系列(YOLO v2[23]、YOLO v3[24]等)和SSD系列(SSD[25]、DSSD[26]等)为代表。值得一提的是,Faster R-CNN[21]提出了锚点(Anchor)机制用于自动生成目标候选区域,此方法相比于传统的生成方法速度和性能都有很大提升,之后不仅被两阶段模型广泛采用,也在一阶段模型中证明了有效性。因此,之后的目标检测模型基本上都采用了锚点这一机制。其他具有重要影响的研究成果还包括解决多尺度检测问题的FPN[27]和解决正负样本不平衡问题的RetinaNet[28]等。
锚点机制虽然被广泛应用,但是也存在一些缺点,如不同形状特点的目标需要针对性地设计一些超参数,并且该机制会产生许多不包含目标的负样本框,从而导致严重的正负样本不平衡问题。针对这些问题,CornerNet[29]将目标边界框解构为左上角和右下角两个点,摆脱了锚点的限制,提出了一种无锚点(Anchor-Free)方法,其框架如图1(c)所示。之后许多学者也在这方面进行了研究,由此诞生了一系列的Anchor-Free模型,例如CenterNet[30]、FCOS[31]和ExtremeNet[32]等,都取得了比较不错的效果。虽然Anchor-Free方法受到了研究者们的青睐,但是目前还无法取代基于Anchor的方法,在很长的一段时间里二者会是共存的关系。

图1 基于深度学习的目标检测模型框架比较Fig.1 Comparison among deep learning based object detection model frameworks
2 面向光学遥感图像的目标检测
光学遥感图像的主要特点包括空间跨度大(单张图像可覆盖超过64 km2[33]、目标尺度差异大(小目标居多)且方向任意。这些特点导致通用目标检测算法难以直接应用在光学遥感图像上,需要对算法进行针对性的设计和优化。本文先介绍目前已有的光学遥感图像目标检测数据集,然后对各类基于深度学习的检测方法的优缺点进行分析比较。现有基于深度学习的检测方法大致可以按照检测步骤分为四类,分别是基于人工提取候选区域的方法、基于候选区域生成网络的方法、基于回归的方法和其他方法。表1总结了这些类别方法的特点。
2.1 面向光学遥感图像的目标检测公共数据集
公共数据集是支撑领域发展一个很重要的基石,能够让研究者们方便地对不同算法进行比较。在过去的十几年中,涌现出了一批用于光学遥感图像目标检测的数据集,表2对它们进行了一个对比,包括数据集规模、检测的目标类别数目及标注方式等。
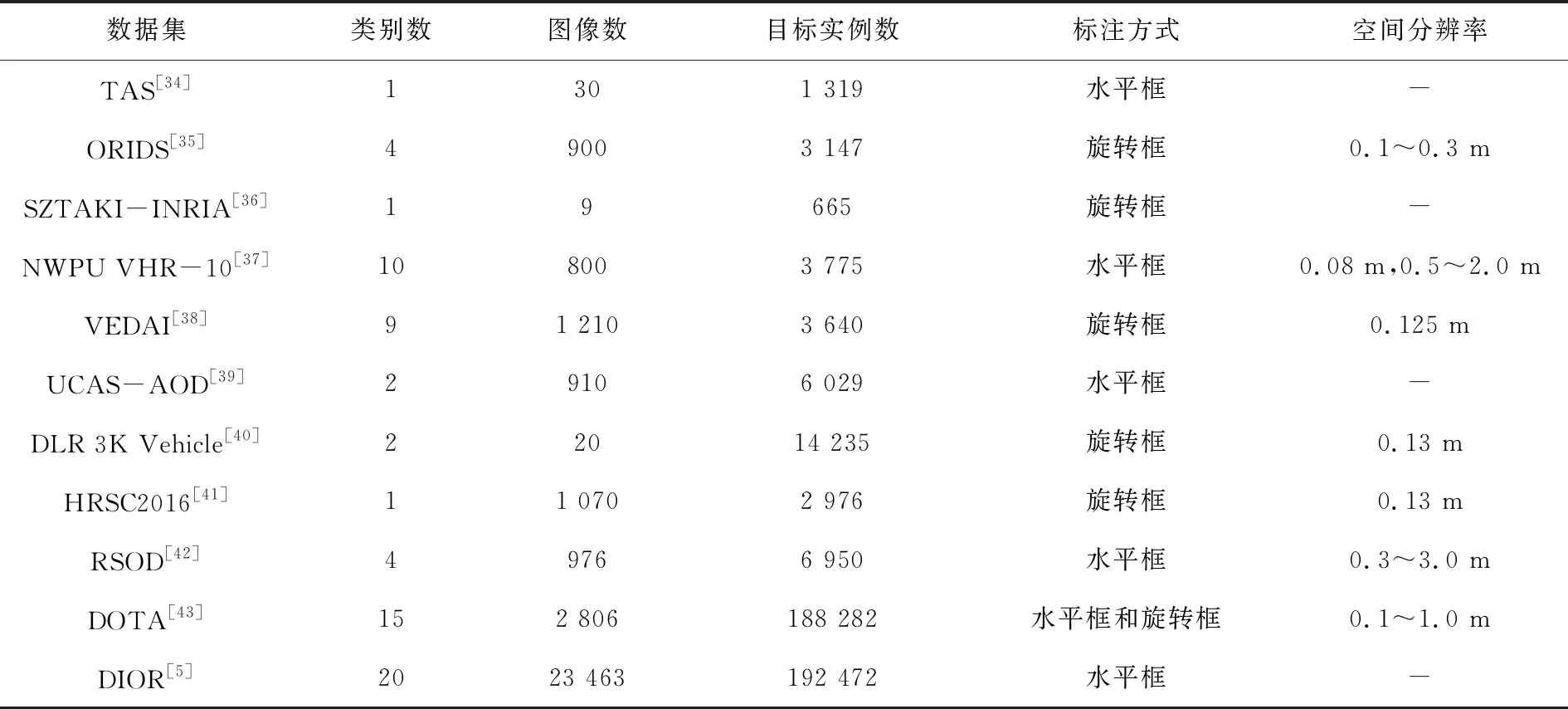
表2 光学遥感图像目标检测公共数据集比较Tab.2 Comparison among publicly available optical remote sensing image datasets for object detection
在这些公共数据集中,TAS、ORIDS和DLR 3K Vehicle用于检测车辆。其中TAS和ORIDS属于较早期的数据集,图像分辨率普遍较低,TAS使用水平框标注;而ORIDS开始使用旋转框标注;DLR 3K Vehicle则是2015年提出的数据集,规模更大、分辨率更高,图像宽度达到了5 616像素。SZTAKI-INRIA用于检测建筑物,包含6个不同国家和城市。HRSC2016用于检测船只,包括海上及码头等各种场景,且船只型号、大小及形状等变化大。UCAS-AOD则用于检测飞机和车辆两种高价值目标。VEDAI包含9种目标类别,均为交通工具。以上这些数据集对于检测的目标类别都比较有针对性,而其他数据集则包含更加多样化的目标类别。NWPU VHR-10是被广泛使用的数据集之一,图像分为高分辨率和超高分辨率(Very High Resolution,VHR)图像2种。RSOD类别数目较少但是每一类的规模都有所提升。DOTA是目前最为广泛采用的数据集之一,也是最有挑战性的数据集之一。同时使用水平框和旋转框标注,且规模比之前的任一数据集都要更加庞大,包含各种方向、大小的目标。DIOR数据集是最新提出的一个光学遥感图像目标检测数据集,比DOTA数据集规模更大,且目标类别数是目前最多的,使用水平框标注。研究者可根据需要选取不同的数据集。
2.2 基于人工提取候选区域的方法
R-CNN[18]获得成功后,许多学者开始尝试将该框架应用到光学遥感图像的目标检测中来。R-CNN采用选择性搜索算法(Selective Search)[44]生成目标候选区域,这是一种人工提取候选区域的方法。在传统图像处理中,一般用穷举法或者滑动窗口来得到一系列可能出现物体的候选框。由于物体大小不同,需要采用许多不同大小的滑窗,这显然是一个复杂度很高、效率低下的方法。而选择性搜索算法先使用基于图的方法对图像进行分割,然后使用贪心策略对相似度最高的区域进行合并,直到最后合并为整张图。这实际上是一个自底向上的过程,产生的候选框数目远少于滑动窗口法,且能拥有很高的召回率。得到候选区域后,R-CNN将目标检测问题转换为对候选框的分类和回归问题,能够使用深度学习方法进行训练。
R-CNN直接应用到光学遥感图像目标检测,面临的问题之一是物体的旋转问题。这一问题在自然场景图像中并不明显。但是,由于光学遥感图像俯视视角成像,物体可以在地面呈现出各个方向,这会对模型的学习造成一定的影响。RICNN[45]针对该问题引入了可学习的旋转不变层,在目标函数中加入正则化约束使得物体旋转前后的特征尽可能一致,从而有效地实现了旋转不变性。RIFD-CNN[46]的思路是在CNN学习到的的特征上加上一个正则化器和Fisher描述符,通过设计新的目标函数达到这一目的。RIFD-CNN不仅可以应用在R-CNN中,还可以加入到其他的检测模型,如Faster R-CNN[21]等。R-CNN的另一个问题是小目标的精确定位问题,小目标的检测在通用目标检测领域中是一个难点。光学遥感图像由于空间分辨率高使得目标往往更小,这一问题更加突出。USB-BBR算法[47]提出了一种无监督的打分机制,能够优化边界框回归,在小目标检测上获得了一定的精度提升。其他基于R-CNN的相关工作还有海豹检测[48]和大区域检测[49]等。
虽然基于R-CNN框架的工作在当时取得了不错的成绩,但是人工提取候选区域的方法是制约整个模型性能的关键点之一。在后续Faster R-CNN提出利用CNN自动生成候选区域后,这一类方法便很少被使用了。
2.3 基于候选区域生成网络的方法
候选区域生成网络(Region Proposal Network,RPN)是Faster R-CNN[21]提出来的用于自动生成候选区域的方法。它对主干网络提取的特征图使用一个n×n的滑动窗口生成候选区域,每一个滑动位置生成k个不同大小和宽高比的预测框,每一个预测框对应一个锚点。由于该方法使用了共享卷积层,相比于选择性搜索方法速度大大提升,在精度上也有一定提升。此外,候选区域生成网络,可以方便地插入到目标检测流程中,使得目标检测模型成为端到端的模型,得到广泛应用。此后,在光学遥感图像的目标检测领域也诞生了许多基于该方案的技术,表3给出了各方法的对比。
该类方法一般针对要检测的目标形状特点重新优化锚点框的参数设置,如AVPN[50]等,这也是其弊端之一,即不同的应用场景都需要人为地设计对应特点的锚点框来达到更好的结果。另外,早期检测方法多使用水平框检测。但是,旋转框慢慢发展成主流,因为研究者发现在许多场景中水平框会包含大量不属于目标的信息,给检测带来很大困难。相比于水平框,旋转框因为多了旋转角而变得更加复杂,需要对模型进行专门的设计。最初许多模型都是在RPN的基础上加入旋转角度,从而生成旋转的候选区域,如R^3-Net[51]、R^2PN[52]等。这些方法虽然有效,但是会大大增加计算量,RoI Transformer[53]针对该问题进行了优化,它仍然使用RPN产生水平框的候选区域,但是添加了一个可学习的空间变换机制以将水平框转变成旋转框,仅仅增加了少量的计算量,就取得了非常不错的结果。而GlidingVertex[54]则提出了一种全新的旋转框定义方式,在每个对应的侧边上滑动水平边界框的顶点,以准确地描述多方位的对象。APE[55]同样提出了一种新的旋转框表示方式,角度由周期不同的两个二维周期向量表示,并且该向量随形状变化而连续。此外,还有一些学者注意到模型在训练过程中存在的旋转灵敏度误差问题[56],该问题会导致模型训练不稳定,甚至影响检测精度。SCR-Det[57]设计了一种新的损失函数来缓解该问题,但仍未从根本上解决。后续工作中,CSL[58]将角度回归问题转换成了分类问题,这是一个比较成功的尝试,但仍有较大的改进空间。除了一般性的问题之外,还有一些学者致力于研究复杂背景干扰问题[59]及小目标检测问题[60]等。
目前,由于基于候选区域生成网络的方法具有较高精度,它仍是光学遥感图像目标检测的主流。
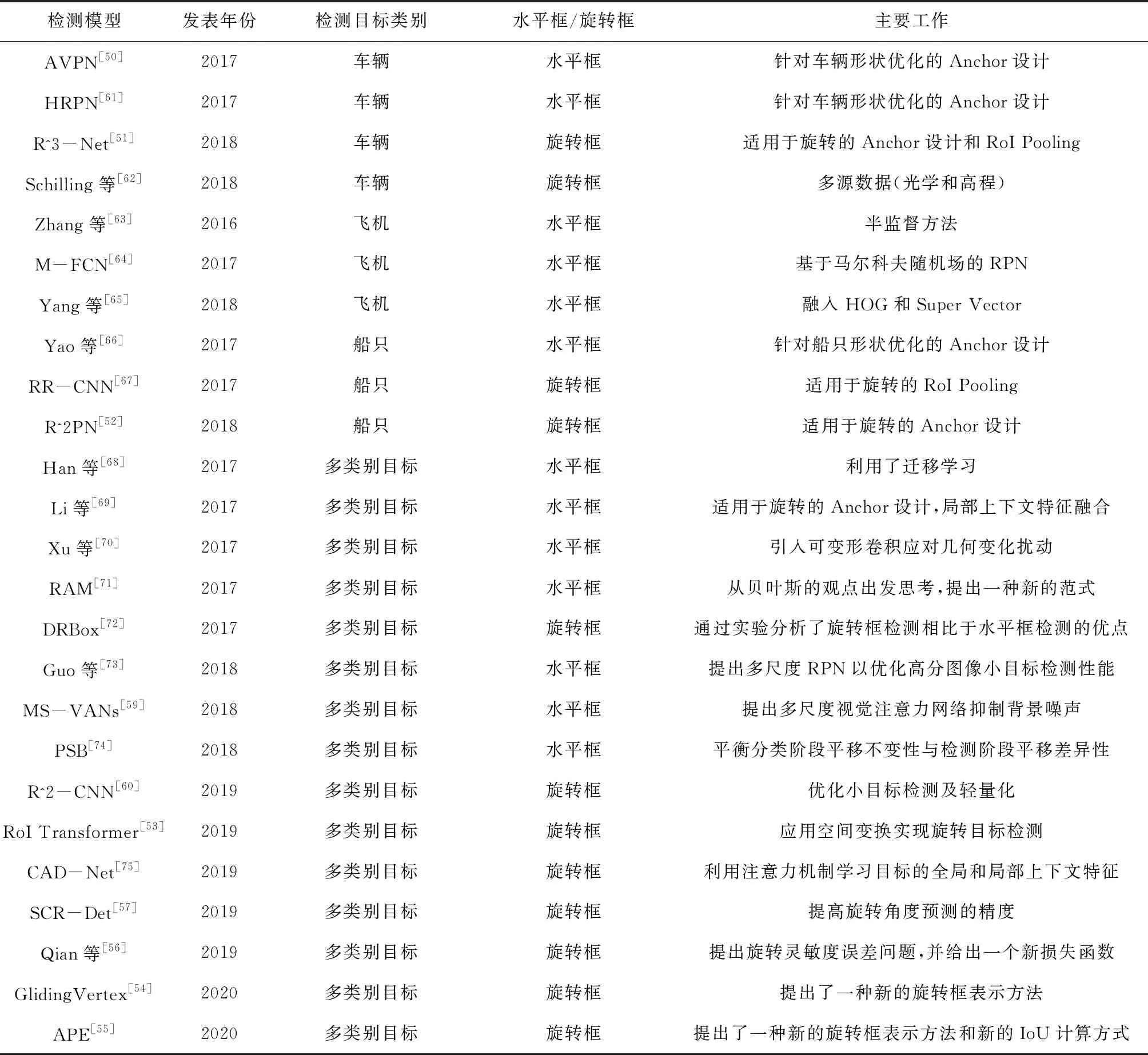
表3 基于候选区域生成网络的光学遥感图像目标检测方法比较Tab.3 Comparison among region proposal network based (RPN) object detection methods in optical remote sensing images
2.4 基于回归的方法
虽然基于候选区域生成网络的方法因为其精度高占据着主流,但基于回归的方法也取得了一些进步。该类方法去除了生成候选区域这一步骤,将目标检测问题简化为回归问题,虽然精度上有所损失,但是更加高效。Oriented-SSD[76]和DRBox[72]都是在SSD[25]的基础上加入了旋转特性以适应目标的角度变化。DRBox还通过实验分析了水平框相较于旋转框检测的一些不足之处。Liu等[77]为了解决近海密集船只监测问题,基于YOLO v2[23]使用旋转框检测,因为水平框难以将密集排列的船只分离。YOLT[33]旨在从大范围的遥感图像中快速检测感兴趣目标,借鉴YOLO的思想设计了新的检测模型,检测速度能够达到0.5 km2/s以上。R3Det[78]为了解决基于回归的方法特征未对齐的问题,设计了一个特征细化模块,通过特征插值实现特征重构和对齐,精度有了很大的提升。
2.5 其他方法
除了上述提到的三类方法外,还有一些方法跳出了这些基本检测框架。例如,Yu等[79]提出了一种超像素分割策略,在分割后的结果上应用深度玻尔兹曼机得到其特征表示,然后构建了一组多尺度霍夫森林得到具有旋转不变性的物体中心点。SVDNet[80]使用奇异值分解网络得到候选区域,然后使用线性SVM分类器得到检测结果。虽然这些模型非常新颖,但是训练过程比较复杂。Qu等[81]致力于解决数据标注成本高昂的问题,提出了一种新的基于不确定性的主动学习方法。这种方法能够选择训练集中具有更丰富信息的图像进行训练,在只利用其中一小部分的图像时也能够得到高性能的检测器。而随着Anchor-Free方法在通用目标检测领域涌现,也有一些学者开始尝试将其应用到光学遥感图像的目标检测中。IENet[82]借鉴了FCOS[31],在其结构上添加了一条分支用于预测角度,并使用交并比引导模型学习。O^2-DNet[83]和P-RSDet[84]则是基于关键点的策略,前者用中心点加上两条中线表示旋转框,后者则将坐标系转换到极坐标系,在此基础上可通过中心点和旋转角及半径来构成一个旋转框。
3 结束语
深度学习在2012年之后在许多领域得到了广泛应用,基于深度学习的目标检测算法如雨后春笋般涌现,现在已经发展得较为成熟,但距离人类水平还有很远的距离。光学遥感图像目标检测领域基于深度学习的方法起步相对较晚,大部分方法都是在通用目标检测器上进行修改,但在近两年也涌现了一些优秀模型。通过分析现有基于深度学习的光学遥感图像的目标检测方法,我们认为目前仍存在以下问题:
小目标检测该问题一直都是整个目标检测领域的难点,主要原因在于其包含的信息少,在模型推断过程中信息会大量丢失甚至完全丢失,导致检测效果非常差。而光学遥感图像往往空间分辨率高,目标相对更小,因此这一问题更加严重。解决这一问题的关键在于尽可能减少小目标的信息丢失,并能够使用一些方法扩充其信息表示。
旋转不变性不同于自然场景中的物体,由于视角的特殊性,旋转对于光学遥感图像中的物体影响非常大。现在广泛采用的是用于提取特征的卷积神经网络,其在旋转不变性方面表现较差,一般采用数据增强的方式生成不同旋转角度的图像来缓解这一问题,但是目前的检测模型在旋转角度的预测精度上仍然有较大的进步空间。
缺少全面的大规模数据集虽然DOTA与DIOR数据集已经是规模较为庞大的数据集了,但是还无法与通用目标检测领域的权威数据集COCO等比肩。此外,数据集的全面性也有待提升。一个规模大、全面的数据集能够极大地推动领域的发展,它不仅能为模型的训练提供充足的数据支持,也能为各个模型的评估和比较提供客观公正的平台。
从以上问题,可以窥见未来光学遥感图像目标检测技术的一些发展趋势。整体来说,研究者仍然可以跟进通用目标检测领域的最新进展,并在其基础上针对光学遥感图像的特点进行改进。对于小目标问题来说,超分辨率是目前一个比较热的研究点,而图像中物体的关系建模也是一个研究趋势,可以结合这两类技术寻求突破。由于全面且大规模的数据集仍然紧缺,且标注工作量巨大,基于半监督、无监督的方法也会是未来发展的一大趋势。此外,研究者应该不仅仅满足于在已有的经典目标检测模型上改进,而是分析光学遥感图像,并在此基础上设计能够贴合其特点的算法模型。总而言之,光学遥感图像目标检测模型会朝着实时、轻量、高效的方向不断发展。
猜你喜欢
初中生学习指导·中考版(2022年4期)2022-05-12 00:12:51
中学生数理化(高中版.高考理化)(2021年5期)2021-07-16 05:32:06
中学生数理化·七年级数学人教版(2020年11期)2020-12-14 06:59:52
艺术品鉴证.中国艺术金融(2018年8期)2019-01-14 01:14:28
艺术品鉴证.中国艺术金融(2018年10期)2019-01-08 02:44:26
艺术品鉴证.中国艺术金融(2018年12期)2018-08-26 06:03:48
中国科技博览(2016年2期)2016-04-25 20:32:39
小学生导刊(2016年34期)2016-04-11 00:49:44
电测与仪表(2015年5期)2015-04-09 11:30:52
航天返回与遥感(2014年1期)2014-07-31 17:55:36
