
基于随机映射技术的声纹识别模板保护
2020-11-11 09:08李佳慧唐士杰王会勇
计算机研究与发展 2020年10期
丁 勇 李佳慧 唐士杰 王会勇
1(桂林电子科技大学计算机与信息安全学院 广西桂林 541004) 2(桂林电子科技大学数学与计算科学学院 广西桂林 541004) 3(桂林电子科技大学电子工程与自动化学院 广西桂林 541004) 4(广西密码学与信息安全重点实验室(桂林电子科技大学) 广西桂林 541004) 5(鹏城实验室网络安全研究中心 广东深圳 518055)
随着人工智能的迅速发展,传统的身份验证(如密码、IC卡等)容易遗忘、丢失、被盗或者被人共享等缺点[1],促进了生物特征认证系统的快速发展.生物特征识别技术是指“在不泄露用户原始身份特征信息的情况下,利用自动技术对人体的生理特征(如人脸[2]、虹膜[3]、指纹[4]等)或者行为特征(如步态、字迹、声音[5]等)进行特征提取,并将这些特征与数据库模板进行比对,完成身份识别或认证的过程”[6-7].生物特征信息的不易伪造性以及生物特征识别系统的不可链接性可以提供更高的安全性.
生物特征具有唯一性、隐私性、不可撤销[8]的特性,将原始生物特征信息直接存储在第三方服务器存在一定风险.生物特征信息可以与用户身份永久关联,若生物特征信息被敌手或者不可信的第三方篡改、盗用后非法利用,生物特征信息在服务器就会失效或者丢失,导致的隐私问题比传统身份验证更加严重[8].Kumar等人[9]提出了生物特征隐私保护的几种攻击类型,如伪造攻击、联系攻击、模板攻击等.
近年来,为了保护生物特征信息的安全,生物特征的隐私保护问题已经成为研究的热点问题[10-16].研究工作主要集中在模板保护和防欺诈方面[6],生物特征识别的模板保护问题是主要的研究方向.模板保护问题分为3类[14]:可取消的生物特征[15-16]、生物加密系统[5]以及混合生物特征加密系统[17].在过去的20年里,生物特征识别技术已经广泛应用到商业、电子、金融等领域[10],这些领域的研究对生物特征识别技术的发展具有重要意义.
目前,对人脸、指纹等图像特征的模板保护算法研究较多[2-4],基于声纹识别认证的模板保护算法也相继提出.声纹识别是基于声音的一种识别方式,由计算机利用待识别语音波形中所包含的反映特定说话人的生理和行为特征的语音特征参数来自动确定或鉴别说话人身份的技术[18],主要包括2个方面:1)训练阶段.首先对每个说话人的语音段进行预处理,然后提取声学特征,训练每个说话人的语音特征得到该说话人对应的模型,最后将全部说话人的模型进行组合,形成说话人的模型库.2)识别或认证阶段.系统对待识别语音进行相同的特征提取,将得到的声纹特征与建立的模型库进行对比,得到对应说话人模型的相似性得分,根据阈值大小来判断说话人的身份.声纹识别的基本流程图如图1所示.声纹识别的身份认证比指纹认证、虹膜认证等更容易受到攻击,如重放攻击、语音合成等[19].因此,急需提出一种安全的声纹识别的模板保护方案以防止用户数据的泄露和保护用户信息的隐私安全.
理想的生物特征加密技术[20]对生物特征模板的保护应具备3个特性:1)不可链接性.对于同一个生物特征,生成不同种类的模板应用于不同的系统、在同一系统对模板进行重新生成或者撤销来完成各个模板间或者模板与原生物特征间的不可匹配.2)不可逆性.生物特征模板容易生成,但从存储的生物特征模板中难以恢复原始生物特征数据.3)识别性能.生物特征模板的加密特征对身份认证的准确性影响较小.本文以声纹为例,提出了一种基于随机映射特性的声纹模板保护方案.将随机映射变换后的数据作为生物特征模板,当随机矩阵被泄露时变换关系也丢失(已知密钥和密文),此时,若各随机矩阵为方阵时,根据逆变换来恢复出原始特征数据,将会导致信息泄露.随机映射实现模板保护的可撤销性和可再生性,导致其抵抗性较差.因此,利用改进的随机映射来提高生物特征数据的随机性和安全性,以及利用正交变换保持距离不变的性质来保证识别效率的准确性.

Fig. 1 Basic framework of voiceprint recognition system图1 声纹识别系统的基本框架
首先,利用改进的随机映射算法对特征数据进行处理,生成受保护的生物特征模板,保证即使在数据丢失的情况下,敌手也不能完全恢复出用户的原始特征信息,这有效提高了认证的安全性和隐私性.其次利用变换后的特征进行模型训练,识别认证.最后,实验仿真表明此算法的安全性和认证效率的准确性.
本文的主要贡献有2个方面:
1) 提出了一种改进的随机映射算法与声纹模板结合的方法,在注册过程中就保证了数据的安全性.除此之外,在认证过程中生成的变换特征具有随机性,也能保证模板的匹配性能和信息的安全性.
2) 设计实现了一个声纹保密认证方案,在不显著影响声纹识别精度的同时也保证了数据的安全性和用户的隐私性.
1 预备知识
本节主要研究了基于随机映射技术的声纹识别(i-Vector)的身份验证的模板保护机制.
1.1 声纹识别的模型
在文献[21]中Dehak等人提出了一项开创性工作,即i-Vector模型,可用于用户的语音验证.模型表示为
M=m+Tω,
(1)
其中,M是高斯混合模型均值超矢量,m是特定说话人和信道无关的超向量,T是低秩矩阵,ω是服从高斯分布的随机向量.
i-Vector模型用因子分析法[21]生成一个低维的说话人空间和信道空间.将3种信道补偿技术:类内协方差归一化(within class covariance normalization, WCCN)、线性判别分析(linear discriminant analysis, LDA)以及扰动属性投影(nuisance attribute pro-jection, NAP)应用于低维空间以去除与信道空间相关的噪声[21].其实验结果表明基于i-Vector和LDA的声纹验证效果要优于其他技术[21].
1.2 声纹识别的隐私保护
文献[22]提出一种在不需要观察明文的情况下,基于安全多方计算(secure muti-party computa-tion, SMC)协议的声纹识别系统的加密语音数据的计算.该算法与传统算法的识别精度相差不大,但计算开销较大.文献[23]提出了一种高斯混合模型的随机映射的声纹模板保护方案.注册时,在随机映射空间对用户的原始身份特征进行高斯混合模型(Gauss mixture model, GMM)的学习,存储模型参数模板到服务器;认证时,用相同的随机矩阵对认证用户的身份特征进行处理,与服务器的模板进行匹配打分.实验结果表明对不同混合度的GMM变换前后的认证性能基本不变,以及在一定误差范围内的降维不仅不影响识别性能,还可以提高用户数据的安全.但由于安全参数依赖随机矩阵,若R泄露,我们根据穷举法可以得到用户的数据特征,使得用户信息的隐私性能降低.Pathak等人[5]重新设计了一种基于高斯混合模型(GMM)的声纹识别的认证方案,以达到隐私目的.该模型依赖于同态密码系统,如Paillier加密.其实验结果证明了在不影响准确性的前提下声纹识别认证的定义.为了克服同态加密所带来的负荷计算量,文献[13]中提出了位串匹配的框架,利用局部敏感Hash函数将超向量表示的语音输入转换为位串,计算匹配度.该方法易于计算位串,有较高的效率,但其准确性较差,等错误率为11.86%.Rahulamathavan等人[10]提出一种基于i-Vector和线性判别分析技术的隐私保护语音验证算法.该算法利用一种基于随机化的技术来进行语音认证,允许用户在随机域注册和验证他们的声音.根据实验证明该算法既不影响认证的准确性,也不增加随机操作带来的额外复杂性.
1.3 随机映射
随机映射是一种根据随机矩阵将特征从d维欧氏空间向k(d≥k)维欧氏空间进行投影,以达到降维的方法.该方法来自JL引理[24],
引理1.若对任意ε∈(0,12)及任意充分大的集合P⊂Rd,满足:

则存在一个映射f:P→Rk,使得对任意的u,v∈P,有:
(2)
引理1表明利用随机投影的方法在降低特征维度的同时又能保证距离的不变性.
文献[23]给出了随机映射的形式表达式,即:
(3)
其中,x表示原始的特征向量,R∈Rd×k(d≥k),表示随机的正交矩阵(可根据斯密斯正交化得到),y(y∈Rk)是随机映射之后的特征向量.一般情况下,d=k,即:
y=RTx.
(4)

Fig. 2 Flowchart of voiceprint recognition system based on improved random mapping图2 基于改进随机映射的声纹识别系统流程图

2 方案设计
2.1 基于随机映射技术的声纹模板保护定义
文献[23]介绍了随机映射算法在GMM-UBM(Gauss mixture model-universal background model)中的应用.具体步骤为:
注册阶段:
1) 提取用户注册语音的MFCC特征X=(x1,x2,…,xi,…,xn),其中xi(1≤i≤n)为语音特征向量;
2) 生成一个随机矩阵R∈Rd×k(d≥k),并且R中的元素rdk是服从独立同分布的高斯随机变量,即rdk~N(0,1),(1≤d,k≤n).
3) 用式(4)对声纹特征向量处理得到Y=(y1,y2,…,yi,…,yn),1≤i≤n;
4) 对yi进行训练,得到要保护的声纹模板W.
认证阶段:



在模板生成中,传统的随机映射算法存在2个问题:1)将随机映射变换后的声纹特征向量直接作为模板,难以抵抗已知密文和密钥的攻击,根据不可逆变换对身份特征进行处理会导致精度的下降.2)在认证时生成相似的变换特征,若该变换被盗用,会导致用户隐私的泄露,如认证次数.针对上述问题,本文先对随机映射技术进行改进,再利用变换矩阵正交的特性,证明其识别精度以及生成声纹模板的安全性.算法改进的声纹模板保护框架如图2所示:
2.2 改进的随机映射声纹模板保护方法
我们由y=RTx对随机映射技术进行改进.改进的随机映射技术既提高了用户数据的安全性和隐私性又保证了声纹识别系统认证效率的准确性.改进后的声纹识别模板保护算法的过程为:
注册阶段:
1) 提取训练语音的声纹特征向量x,再随机生成一个正交矩阵R,且R中的元素rdk是服从高斯分布的独立随机变量,即rdk~N(0,1),1≤d,k≤n;
2) 对R进行分解R=R1+R2(R1,R2均为正交矩阵),用式(4)对声纹的特征向量x处理,得Rx=R1x+R2x,即:
y=y1+y2;
(5)
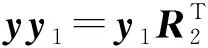
认证阶段:
1) 提取测试语音的声纹特征向量x′,再随机生成一个正交矩阵R,且R中的元素rdk是服从高斯分布的独立随机变量,即rdk~N(0,1)(1≤d,k≤n);
2) 对R进行分解R=R1+R2(R1,R2正交矩阵),用式(4)对声纹的特征向量x′处理,得Rx′=R1x′+R2x′,也即:
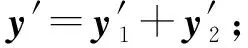
(6)


4) 由模板向量W与Z式进行匹配,计算余弦相似度scoreW,Z,得到决策结果.
3 性能分析
本节介绍实验所需数据集、结果以及改进的随机映射算法对声纹模板的识别精度以及安全性的分析.我们首先用Matlab2016进行声纹系统的仿真,测试了文中所提出的改进的随机映射声纹模板的性能;然后分析了改进的随机映射方法对声纹识别的识别精度及安全性的影响;最后证明了本文方法的可行性和安全性.
3.1 实验结果分析
本文主要研究随机映射的声纹识别模板保护的有效性,而不是声纹识别本身的算法.不同的声纹识别方法适用于不同的加密算法.本文是对i-Vector的声纹识别系统的模板保护,i-Vector是在GMM-UBM框架下,根据UBM模型自适应得到的,在训练过程中改变均值的大小,将说话人的信息差异都储存在GMM的均值矢量中.说话人在GMM模型中的每个高斯分量的均值叠加起来,形成了一个高维超矢量,即均值超矢量.在i-Vector模型中,利用全局差异空间,得到身份向量.全局差异空间既包括说话人之间的差异又包括信道之间的差异,因此在i-Vector的建模中GMM均值超矢量不严格区分说话者和信道的影响.
希尔贝壳中文普通话开源语音数据库(AISHELL)已经应用到智能家居、无人驾驶、无人驾驶等多个领域[25].AISHELL数据库包括了4种地域方言的400位使用者的录音文件[26].表1~3显示了希尔贝壳数据集的统计数据[26].我们利用AISHELL数据库进行实验的仿真模拟.
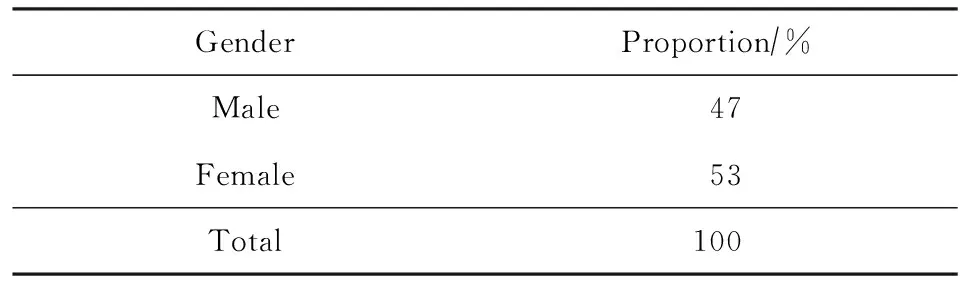
Tabel 1 Gender Ratio

Tabel 2 Age Ratio

Tabel 3 Regional Proportion of Dialects
文中采用等错误率(equal error ratio,EER)作为性能的评价认证指标,其反映了声纹识别系统整体的准确性和用户的可接受度等重要性质.等错误率是指不断调整阈值的大小, 使得错误拒绝率(false rejection rate, FRR)和错误接受率(false acceptance rate, FAR)相等时得到的识别率.我们针对不同的样本大小50,100分别进行了实验.以50人为例,选取其中20个用户的语音信息(数据)作为模型的测试集,选取另外30个用户的语音建立模型背景.在训练过程中生成注册数据的实验对,实验对可能由一条测试语音和一个注册模型构成;也可能由多条测试语音构成.最终得到一个声纹注册模型.
实验中,通过Matlab2016自带函数生成随机矩阵,利用正交函数对随机矩阵正交化.由表4可以看出,声纹识别系统的识别精度不受人数的影响.对身份向量进行随机化的正交矩阵处理时,声纹识别系统的识别精度基本不变.对不同方差的正态分布进行实验时,其识别精度也不受影响,如表4所示:

Table 4 EER of Normal Distribution with Different Variances in the Same Period
根据表5以及图3~6的实验结果,可以验证本文所提出的方法对声纹识别认证系统的精确度影响微乎其微.说明本文方法保证了声纹识别系统的识别性能以及其可行性.
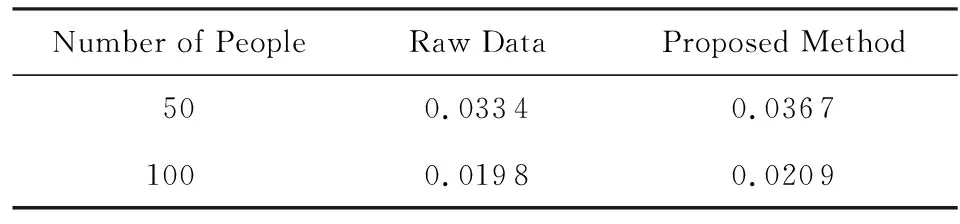
Table 5 EER Without Randomization and Based on Randomization

Fig. 3 Equal error rate of direct identification (50 People)图3 直接认证(50人)的等错误率

Fig. 4 Equal error rate of proposed method (50 People)图4 本文方法(50人)的等错误率

Fig. 5 Equal error rate of direct identification (100 People)图5 直接认证(100人)的等错误率

Fig. 6 Equal error rate of proposed method (100 People)图6 本文方法(100人)的等错误率
3.2 有效性和安全性分析
随机映射的有效性是指特征变换不会降低声纹识别的精度.3.1节已经分析出变换前后不会影响声纹识别系统的精度.研究表明:满足生物特征模板保护的所有要求是极其困难的.在实际应用中,这些条件相互制约,因此需要根据实际应用需求来进行选择.下面对所提算法在声纹模板的安全性方面进行分析,这里安全的定义是敌手不能根据变换后的特征得到原始数据.
在特征匹配过程中,通过随机映射正交矩阵R2,提取出与式(4)相同的特征信息,从而保持生物特征在匹配过程中距离不变的性质.在声纹识别系统中,正交矩阵保持距离不变,则随机映射的正交变换不影响其识别精度.
不可逆性由文献[23]可知需要满足2个特征:1)在变换域进行;2)若模板被盗,敌手也不能恢复出原始数据.本文算法的声纹特征的判别打分是在变换域进行,因此满足第1个特性.需要判断第三方或者敌手是否能根据y的信息得到x的数值,文献[23]的特征由等式y=Rx,可以看出,在一定时间内利用穷举法可推算出x,也即文献[23]会导致原始生物信息不易泄露,从而不具备可逆性.
本文改进的算法对随机矩阵进行分解,在服务器中有2个训练的特征以及随机矩阵.在密文和密钥受到攻击时,增加了恢复x的难度,使得敌手在多项式时间内很难恢复出x,从而具备不可逆性.随机矩阵的分解不仅提高了用户特征的不可逆性,在训练后的模板又增加了交叉匹配的安全性.当随机映射的正交矩阵R和x的维数相同,在没有R时,第三方或敌手无法通过y获取x,说明当随机矩阵安全保存时,该算法是安全的.


另外,对同一用户,可以在声纹识别中选择不同的随机矩阵,或在模板泄露的时重新更换随机正交矩阵,这提高了声纹模板抵抗已知密文的攻击能力,同时也证明了该方法的不可逆性.不同的随机正交矩阵映射到不同的空间,使得用户数据具有多样性和随机性.
4 总 结
本文基于随机映射的特点,与主流的声纹识别系统i-Vector结合,提出了一种具有随机映射特性的声纹模板保护方法.由理论和实验结果分析得出,当随机矩阵为正交矩阵时,变换前后的身份认证方案的识别性能基本保持不变.由于本文的方案需要先对用户的身份进行训练,再用此算法进行识别认证,有一定的局限性.因此,在设计声纹的安全模板时需要考虑在训练过程是否有数据的泄露.
猜你喜欢
建材发展导向(2022年20期)2022-11-03
建材发展导向(2022年12期)2022-08-19
建材发展导向(2021年20期)2021-11-20
考试与评价·高二版(2020年2期)2020-09-10
阅读(快乐英语高年级)(2019年5期)2019-09-10
电子制作(2019年9期)2019-05-30
电子制作(2019年24期)2019-02-23
小说界(2018年5期)2018-11-26
读与写·教育教学版(2017年10期)2017-11-10
南都周刊(2015年4期)2015-09-10
