
基于跨尺度特征聚合网络的多尺度行人检测
2020-11-07 12:38:10曹帅张晓伟马健伟
北京航空航天大学学报 2020年9期
曹帅,张晓伟,马健伟
(青岛大学 计算机科学技术学院,青岛266071)
随着人工智能与计算机视觉技术的发展以及人们对公共安全领域的日益重视,智能视频监控技术已经发展为当前的研究热点。行人检测是智能化视频监控系统中的核心关键技术之一,并为后续的更高层次的视频分析与理解提供可靠的数据支持。因此,行人检测技术直接影响着智能视频监控的智能化水平,具有重要的研究意义和应用价值。
近年来,基于深度卷积神经网络的通用目标检测[1-3]取得了巨大的成功,尤其是Girshick等提出的基于R-CNN[4]目标检测模型,代替了手工设计特征[5-6]极大地提高了行人检测的性能。然而,在视频监控系统中行人存在不同空间尺度的差异,尤其是大尺度、低分辨率的行人目标对行人检测技术带来了极大的挑战。为解决行人在空间尺度变化下的检测问题,目前主要分为2种策略:图像金字塔[7-8]和特征金字塔[2,9-10]。基于图像金字塔的多尺度行人检测方法通过采样输入图像得到不同尺度的图像金字塔集合,以预测最终的检测结果。其中,具有代表性的图像金字塔的尺度归一化网络(SNIP)[7]及其加强版具有高效重采样的图像金字塔的尺度归一化网络(SNIPER)[8],其选取若干个正样本区域和负样本区域作为图像金字塔。然而,这种基于图像金字塔的行人检测方法在时间和内存方面的消耗是巨大的,限制了在实时智能监控视频任务中的应用。
为兼顾精度与速度,基于特征金字塔的多尺度方法被广泛应用到目标检测。与图像金字塔相比,特征金字塔需要的内存空间和计算量要少的多,并且结构简单,能够有效地嵌入到各类目标检测器中。其中,单镜头多盒检测器(SSD)[2]就是基于视觉几何组网络(VGG-16)提取不同分辨率的多层特征图集合用于多尺度目标检测。感受野块网络(RFB-Net)[9]在SSD网络的基础上采用2个模拟人类视觉感受野的特征提取模块替换原有卷积层,并使用6个不同层级的特征图用于检测。类似的,渐进定位网络(ALFNet)[10]在Res-Net-50[11]后3个阶段的最后一个卷积层以及新添加卷积层上堆叠多个目标分类和空间位置坐标回归模块,形成渐进定位网络,从而实现对多尺度目标精确定位。
大量研究表明[12-13],通过添加横向连接和自上而下信息传播路径进行特征融合,生成的特征表达能力更强。特征金字塔网络(FPN)[14]通过自上而下的跨层路径有效地融合了高层特征所具有的鲁棒语义信息生成特征金字塔网络。路径聚合网络(PANet)[15]基于FPN网络结构添加自底向上的扩展路径,以精确的定位信息增强整个特征金字塔表达能力,有效提高了目标分割的准确度。多级特征金字塔目标检测器(M2Det)[16]提出了多层次的特征金字塔网络,使用多层次重复的网络结构生成具有更强表达能力的特征金字塔。受上述研究工作的启发,为充分利用不同尺度特征层在视觉语义信息上的互补性,本文提出了跨尺度特征聚合网络(TS-FAN)模块,在几乎没有增加任何时间耗费的前提下实现了不同层次特征信息的聚合,以增强特征金字塔的语义鲁棒性和定位精确性。
另一方面,为检测视频图像中的不同尺度目标,Faster R-CNN[1]基 于 多 尺 度 区 域 建 议 网 络(RPN)生成多尺度初始候选目标区域检测多尺度目标。进而FPN利用多个RPN子网络来尽可能的覆盖图像中目标的所有尺度,但这种方式忽略了不同路径RPN网络生成的候选目标集存在行人分类与定位回归之间的不一致性,从而影响多尺度行人的检测性能。为解决这一问题,本文引入一种基于多路径RPN的尺度补偿策略来有效处理多尺度目标,以提高不同尺度行人的召回率。受尺度自适应的三叉戟网络(TridentNet)[17]多分支检测的启发,为避免极端尺度行人对不同路径模型训练影响,本文利用尺度感知的策略使不同路径RPN检测与特征层感受野相匹配的多尺度行人候选框,并将不同路径RPN生成的候选目标区域单独处理,避免了不同路径下不同候选目标相互之间产生的影响。同时,根据Li等[18]的研究,不同尺度行人实例在不同特征层上具有不同的特征表达,因此本文对不同尺度行人使用不同的特征映射函数,为多路径RPN生成的不同尺度候选目标区域集匹配相适应的聚合特征层,形成多尺度行人检测网络。
综上所述,本文主要贡献如下:
1)引入一种基于多路径RPN的尺度补偿策略,依据不同分辨率行人实例构建多路径RPN网络,使各路径RPN网络分支基于有效感受野大小自适应地生成候选目标尺度集,以提高多尺度目标的召回率,并通过非极大值抑制的方法得到多尺度的目标候选区域集合。
2)根据不同分辨率特征层在视觉语义信息和精确定位信息上的差异性,本文提出了TS-FAN模块,通过跨层连接聚合多尺度特征信息,极大地缩短了底层特征信息传播到顶层特征层的路径,增强了特征金字塔的语义鲁棒性和定位精确性。
3)基于尺度感知的端到端训练方案,将多路径RPN中得到的不同尺度候选目标集映射到与之匹配的聚合特征层中进行特征提取,形成多尺度行人检测网络。实验结果表明,在Caltech[19]和ETH[20]数据集上明显优于目前一流行人检测方法TLL-TFA[21],尤其对大尺寸、低分辨率行人的检测性能提升较为显著。
1 TS-FAN网络结构
TS-FAN总体结构如图1所示,主要包含3个部分:基于尺度补偿策略的多路径RPN、TS-FAN模块和多尺度行人检测网络。TS-FAN网络模型基于端到端的训练方式联合不同路径RPN子网络和TS-FAN模块,通过多路径RPN产生得到的行人候选区域自适应感知其在相应特征聚合网络模块上的有效特征,并采用尺度感知的策略形成多尺度行人检测网络。图中:C1~C5分别为Res-Net-50的5个不同阶段;H3~H5分别为不同分辨率的聚合特征。

图1 TS-FAN总体网络架构Fig.1 TS-FAN overall network architecture
1.1 基于尺度补偿策略的多路径RPN
RPN在Faster R-CNN[1]中被提出,因其引入了多尺度滑动窗口遍历特征图的每个空间位置,极大地提高了目标检测的召回率。然而,RPN只在某一深度卷积特征层上提取候选目标,其固定尺寸的卷积核限制了单一特征层的视觉感受野大小。对此,FPN[14]在多个特征层上生成多尺度候选目标,进一步提升了目标检测的召回率。在此基础上,本文开展了对多路径RPN行人召回率的实验分析,发现不同深度卷积特征层对不同尺度行人候选目标召回率具有较大的性能差异。大尺寸行人在高层特征图具有较高的召回率,而小尺寸行人在分辨率高的低层特征具有较高的召回率。为此,根据各深度卷积特征层的有效感受野大小[22],本文采用尺度补偿策略,将行人候选目标划分为3个路径的RPN来适应行人的多尺度变化,如图2所示。其中左、右分支作为辅助检测网络,中间分支则为主检测网络。本文使用ResNet-50作为特征提取基础网络,定义C3、C4、C5代表基础网络结构中每个阶段的最后一个残差块res3d、res4 f、res5c。不同分支RPN中设置有效真实标注框的高度(行人实例高度像素值)分别在小于50像素、所有像素、大于100像素范围内,跨越该范围的真实标注视为无效标注,不参与该RPN分支训练。由于每个RPN路径针对不同尺度的行人目标进行训练,所以不同RPN路径使用独立损失函数,其中RPN多任务损失函数定义为
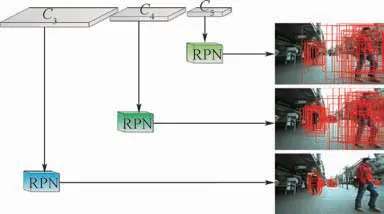
图2 多路径RPNFig.2 Multipath region proposal network
L=lcls+φ[y=1]lloc(1)
式中:lcls为分类损失采用交叉熵损失函数[1];lloc为位置回归损失采用Smooth-L1损失函数[1];φ为一个超参数;y=1表示只有正样本进行位置回归。基于单个RPN损失函数,给出总体损失函数,其定义为

式中:L1、L2、L3分别为左、中、右分支的多任务损失函数。
基于上述多路径RPN得到具有不同尺度范围的候选区域集P={Ps,Pa,Pl},其中Ps和Pl分别为小尺度集和大尺度集,它们是对所有尺度集Pa的尺度补偿。对于上述候选区域集使用阈值为0.7的非极大值抑制减少重叠候选目标框,为目标识别阶段提供高质量的候选区域。
1.2 跨尺度特征聚合网络
特征金字塔被广泛应用到多尺度检测的模型中,如 图3所 示,SSD[2]和STDN[23]网 络 都 是基于自底向上的信息传播方式生成不同空间分辨的特征金字塔。然而这种方法没有考虑到不同层次信息的互 补 性[24-26],TLL-TFA[21]、CSP[27]等利用反卷积等上采样操作将不同层次的特征层归一化到同一分辨率,并通过特征通道叠加的方式进行特征融合。FPN[14]和PANet[15]模型构建了自上而下和自底向上的信息传播路径,融合不同层次特征层作为目标检测特征层。而M2Det[16]提出了多层次的FPN,使用更加复杂的网络结构生成具有更强表达能力的特征金字塔。然而这些方法都是通过复杂的网络构建更多的特征金字塔,从而得到更加鲁棒的特征表示,其忽略了低层次特征的重要性,丢失大量的细节特征信息。
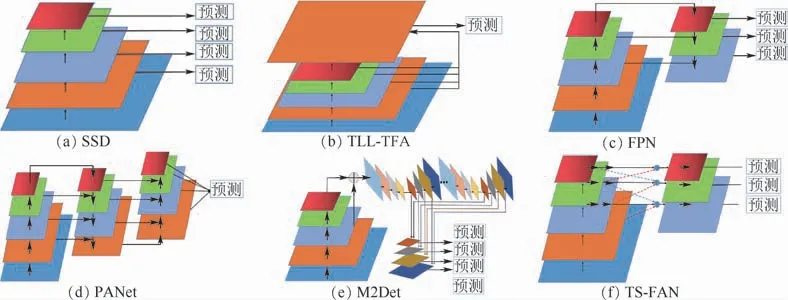
图3 多种特征金字塔模型示意图Fig.3 Schematic diagram ofmultiple feature pyramid models
本文提出的TS-FAN模块是在FPN网络模型的基础上通过添加自底向上快速路径,缩短低层次高分辨率特征图到高层次特征图的传播路径,以有效聚合低层特征图中的局部细节特征信息。本文在自底向上的特征编码路径引入平均池化层,来丰富用于检测特征层的特征信息,实现不同尺度卷积特征的增强表示。
本文提出的TS-FAN模块有效地融合了自顶向下、由底向上和同层映射三种路径特征,如图4所示。在特征融合之前,首先使用1×1卷积核对当前特征层Ci和上、下相邻特征层Ci+1、Ci-1(i⊂{3,4,5})实现特征维度的统一,得到空间分辨率不同但 是 特 征 通 道 数 相 同 的 特 征 层C′i+1、C′i、C′i-1。在自上而下的特征传播路径中,使用双线性插值的上采样方法将C′i+1特征层的空间分辨率扩大到原来的2倍,并且保持特征维度不变,保留其高层特征图中较为鲁棒的语义特征信息。另一方面,为保留低层有利于目标定位较为敏感的局部位置信息,在自底向上的特征增强路径中,采用平均池化方法对C′i-1层特征层下采样缩放至原来一半的空间分辨率大小,并且不改变其特征维度,保留其低层特征图中较为精确的定位信息。特征聚合通过对特征图逐像素相加的方式实现,其能够增加特征的信息量,但特征维度本身没有增加,这对于最终的图像分类是有益的。最后为减少上采样过程中的混叠效应,添加了一个3×3卷积处理融合后的特征图生成最终的具有强表达能力的特征图。TS-FAN模块的计算公式为
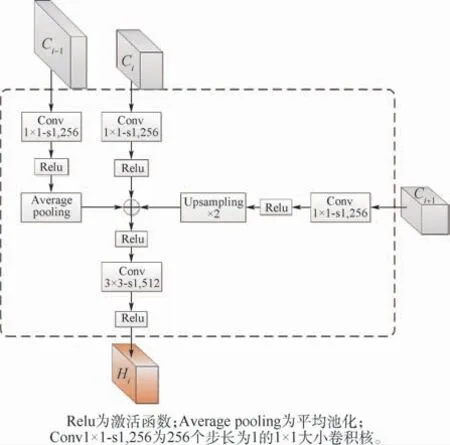
图4 特征聚合模块Fig.4 Feature aggregation module

式中:c为特征通道维度;Ki为3×3卷积核;“*”为卷积操作;Avgpooling为平均池化操作;Upsampling为上采样操作;Hi为TS-FAN模块得到的增强特征表示。
1.3 多尺度行人检测网络
本文根据不同分辨率的特征层对于不同尺度行人的有效性,通过多尺度检测方法联合多路径RPN生成的多尺度行人候选集Pi={Ps,Pa,Pl}和TS-FAN模块得到的聚合特征Hi={H3,H4,H5}提取候选区域特征编码。如多路径RPN中的主检测分支生成Pa集合中的行人候选区域匹配到相应的TS-FAN生成的聚合特征H4,从而得到该特征层的感兴趣区域,利用RoI-pooling归一化提取的特征编码得到7×7×512特征,将提取的特征编码由全连接层变换到1 024维高维特征向量,精确计算候选区域的置信度分数和4个坐标偏移量,得到最终的检测结果,其他2个辅助检测分支类似。对于不同尺度集的候选区域使用对应的检测分支,每个检测分支训练都有真实类别标注p*和真实标注框b*=分别为真实标注框的左下角坐标和宽、高。本文单分支行人检测训练的损失函数定义如下:
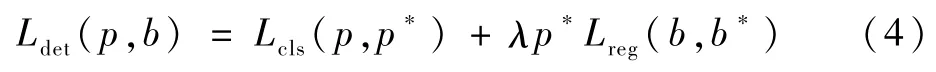
式中:Lcls为分类交叉损失函数;Lreg为候选目标的回归损失函数,Lreg(b,b*)=R(b-b*),R为Smooth-L1损失函数;p和b=(bx,by,bw,bh)为网络候选目标框置信度分数和空间位置;λ为平衡分类与回归任务的损失函数,本文中λ=10。预测得到的候选目标框与任何一个真实标注框的重叠度大于0.5时p*=1,否则p*=0。多尺度行人检测的具体实现过程如算法1所示。
算法1基于TS-FAN的多尺度行人检测。
输出:网络模型权重ω和ωb。
初始化:加载ImageNet数据集上的预训练权重,为新添加的卷积层使用高斯函数初始化权重。设定学习率ζω和ζωb。
迭代循环:

其中:t和T分别为当前迭代次数和总迭代次数;Lfar、Lmedium、Lnear分别为大尺寸、中尺寸、小尺寸分支路径的损失函数;ζω和ζωb分别为权重的学习率和偏置项的学习率。
2 实验与分析
2.1 数据集与实验设置
本节在2个公开基准数据集Caltech和ETH上测试本文的TS-FAN方法对多尺度行人检测的有效性。本文基于Caltech评估标准[19]:平均每幅图像假阳性(FPPI)在[10-2,100]之间的行人漏检率,用MR-2表示。依据Caltech测试集数据划分标准[19],划分为:Reasonable子集(行人高度大于50像素和可见度在65%以上);All子集(高度最小为20像素和可见度在20%以上);Large、Near、Medium和Far子集分别表示行人高度范围为大于100像素、大于80像素、30~80像素之间和20~30像素之间的测试子集。设置学习率为0.001、权重衰减为0.0005、梯度更新权重为0.9,在单GPU上每个mini-batch使用2张图片,选择使用SGD优化器。实验所使用环境为Ubuntu14.0、caffe2、CUDA8.0.61、python2.7.12,硬件配置为NVIDIA GeForce GTX 1080Ti(一块)、Intel(R)Xeon(R)CPU E5-2609v4@1.70GHz×16。
2.2 消融实验
2.2.1 RPN尺度补偿策略的重要性
为验证基于尺度补偿策略的多路径RPN对多尺度行人候选目标生成的有效性,本文在Caltech数据集上通过RPN获取300个目标候选框,以评估行人检测的召回率(表示为R300)。本实验设置预测目标框与真实标注框重叠度阈值大于0.5即为判断为正样本,否则为负样本。
首先,在ResNet-50的不同层次特征层(C3、C4、C5)中引入RPN,P34表示为FPN网络中联合使用P3、P4特征层,C34表示为联合使用C3、C4特征层,其他依次类推。从表1数据可以看出,小尺寸的行人在高分辨率的特征层上具有较高的召回率,如C3要比C5表现得更好。而在C4层,该层能够更好地兼顾不同尺度行人实例,对于多尺度检测表现出良好的效果,但对于小尺寸行人实例召回率仅为75.2%,这意味着单卷积层的RPN并不能有效覆盖图像中行人实例的所有尺度。本文引入多路径RPN尺度补偿策略提取多尺度目标候选框,在整个Caltech多尺度行人集合上取得了97.2%的行人召回率。而且从表1中还可以看到,在卷积特征层上联合多路径RPN生成行人候选目标比在FPN中更为有效,其原因可归结为经过卷积后的特征层比融合后的FPN特征含有更多的局部细节信息。
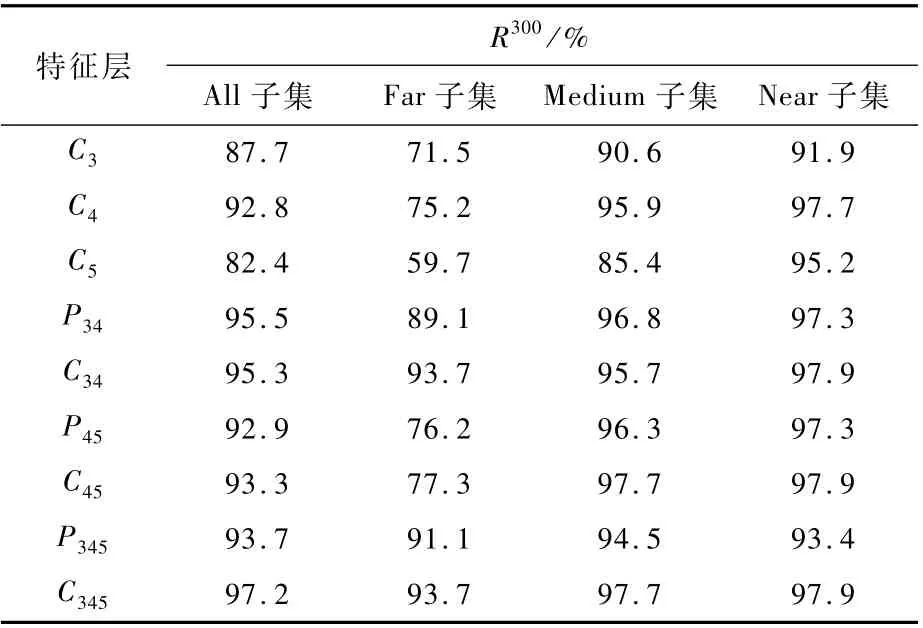
表1 在Caltech数据集上对于RPN的消融实验Table 1 Ablation experim ent of RPN on Caltech dataset
2.2.2 跨尺度聚合特征对于行人检测的有效性
为验证本文TS-FAN模块对行人检测的有效性,本节将其与FPN的行人检测结果进行了实验对比。表2中的Proposal为单路径RPN的输入,如FPN-P3和TS-FAN-H3分别表示FPN网络和TS-FAN网络在ResNet-50第3阶段检测,其余类似,TS-FAN-H3H4H5表示多分支检测。从表2中可以观察到,TS-FAN 模块 TS-FAN-H3和 TSFAN-H4相较于FPN 的FPN-P3和FPN-P4在Caltech数据集上均有明显的检测性能提升。尤其是TS-FAN-H3比FPN-P3在Caltech的Reasonable、Near、Medium子集上的行人漏检率MR-2降低了17.45%、28%、11.25%,TS-FAN-H4相对于FPN-P4在Far子集上的行人漏检率MR-2提升了9.91%。这可归因于聚合低层次特征的细节信息有利于提升行人的检测效果。

表2 Caltech数据集上验证跨尺度聚合特征的有效性Tab le 2 Verification of validity of trans-scale aggregation features on Caltech dataset
值得关注的是在FPN-P5加入低层次特征后,TS-FAN-H5只在Caltech的Near测试子集上表现出性能提升,其原因可归结为该特征层分辨率较低,更加倾向于大尺寸行人实例的检测。而且表2中联合各跨尺度聚合特征在Caltech的Reasonable和Near测试子集上表现效果略低于单跨尺度聚合特征,而在Medium和Far测试子集上行人漏检率MR-2为17.24%和50.38%,明显优于单跨尺度聚合特征。这是由于低层次特征的加入,使得网络更加关注中、小尺度行人。最后,本文相对于单路径RPN,在多路径RPN下联合各跨尺度聚合特征TS-FAN-H3H4H5,能够更有效地检测多尺度行人实例,在Reasonable、Near、Medium、Far测试子集上行人漏检率MR-2分别达到5.53%、0.47%、13.76%、47.30%。其在不同尺度行人的检测性能上均有明显的提升,其原因可归结为多路径RPN为第二阶段行人识别和预测行人目标包围框提供了高召回率、高质量行人候选区域集。
2.3 与目前一流行人检测方法的比较
本节为横向对比本文方法对多尺度行人检测的有效性,首先在Caltech测试数据集上与目前表现较好的行人检测方法FasterRCNN+ATT[28]、RPN +BF[29]、AdaptFasterRCNN[30]、F-DNN +SS[31]、PCN[32]、GDFL[33]、F-DNN2+SS[34]、TLLTFA和AR-Ped[35]进行了实验对比。从表3中可以看出,本文TS-FAN方法在Caltech数据集上取得了最好的检测性能,其在Reasonable、All、Near、Medium和Far的子集上,行人漏检率MR-2分别为5.53%、26.21%、0.47%、13.76%和47.30%。在Caltech测试数据集Reasonable子集上,本文方法相较于当前一流的AR-Ped方法,行人漏检率MR-2降低了0.92%。与当前领先的TLL-TFA方法相比,在All、Near、Medium和Far的子集上行人漏检率 MR-2分别降低了11.94%、0.25%、9.16%和12.79%。量化的实验对比结果如图5中所示,可以明显地观察到本文提出的TS-FAN网络对于不同尺度的行人实例均表现出较好的行人检测效果。
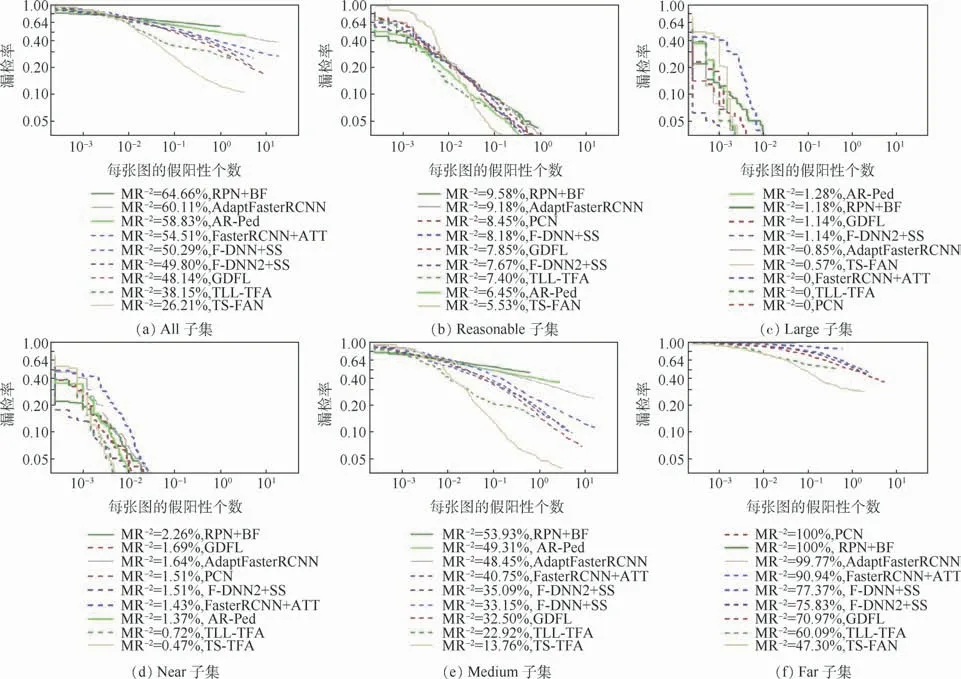
图5 在Caltech数据集上,本文方法与目前一流方法的对比Fig.5 Comparison of proposed method with some state-of-the-artmethods on Caltech dataset
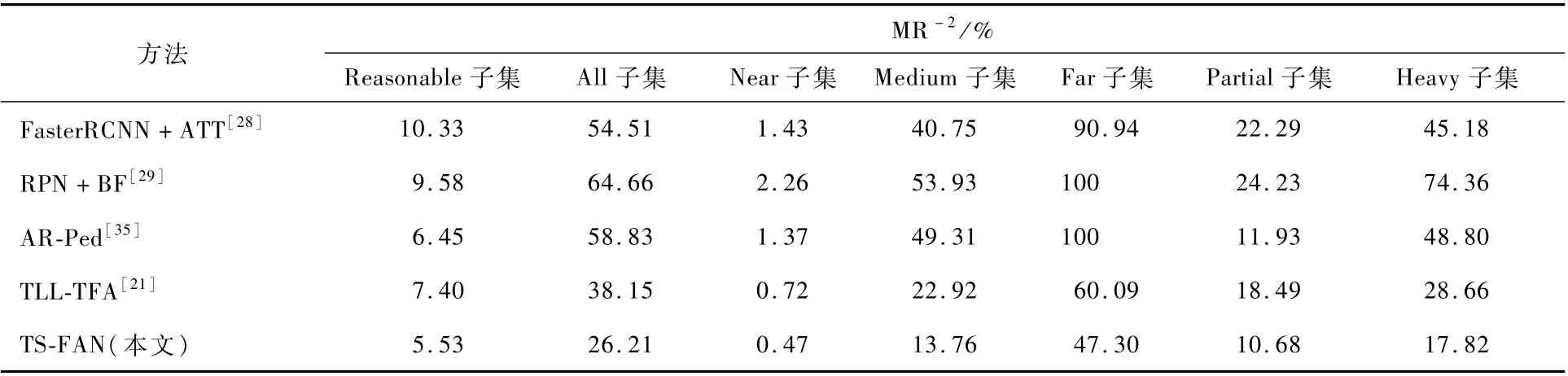
表3 在Caltech数据集不同重叠评估设置上,本文方法与目前一流方法的比较Tab le 3 Com parison of p roposed m ethod w ith som e state-of-the-art m ethods on the Caltech dataset under differen t overlapping evaluation p rotocols
低层次特征带来局部细节特征信息和较为精确的定位信息,使得网络对于位置感知能力更强,从而在行人间的遮挡问题上同样表现出具有竞争力的行人检测效果。TS-FAN方法在Caltech数据集的Partial和Heavy子集上与当前领先的TLLTFA方法相比,在Partial和Heavy子集上行人漏检率MR-2分别降低了7.81%和10.84%。在Partial子集上与AR-Ped方法相比,行人漏检率MR-2降低了1.25%。
在ETH测试数据集上,TS-FAN方法与目前检测性能较好的行人检测方法ChnFtrs[36]、Joint-Deep[37]、MultiSDP[38]、DBN-Mut[39]、TA-CNN[40]、RPN+BF和F-DNN2+SS进行对比实验,实验结果如图6所示。见图6(a)和(b),TS-FAN方法在All和Reasonable测试子集上比目前检测效果较好的F-DNN2+SS方法行人漏检率MR-2降低了7.28%和2.73%。尤其在Medium和Far子集上,TS-FAN方法行人漏检率MR-2提升了19.97%和29.21%,如图6(e)和(f)所示。而在Near子集上,TS-FAN方法较RPN+BF方法和F-DNN2+SS方法行人漏检率MR-2分别降低了1.51%和3.19%。其原因可归结为本文TS-FAN方法没有使用更深层次的卷积层(如特征图分辨率较原图下采样64倍)。
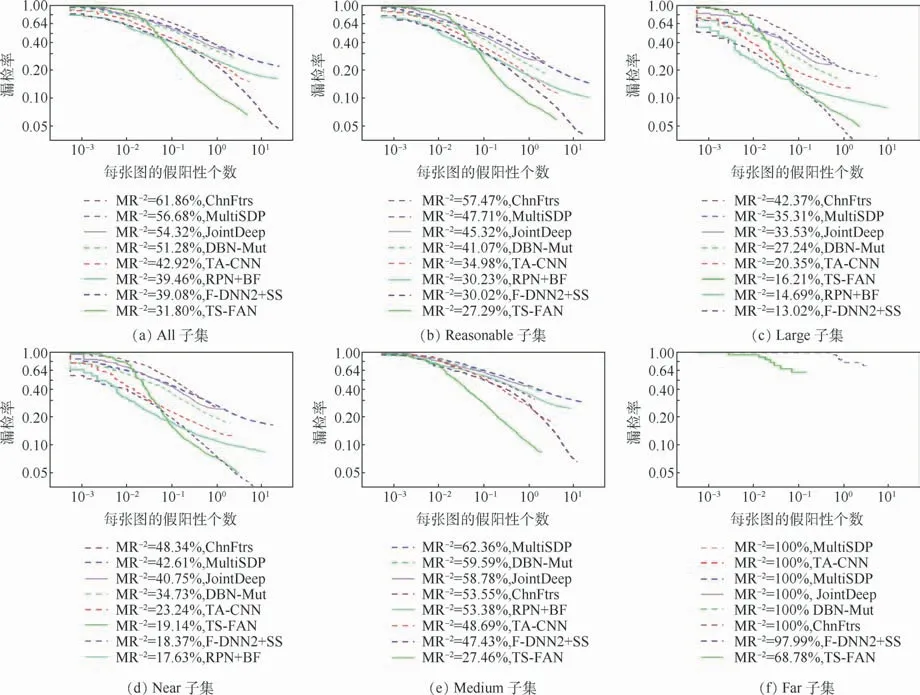
图6 在ETH数据集上,本文方法与目前一流方法的对比Fig.6 Comparison of proposed method with some state-of-the-artmethods on ETH dataset
为形象地观测本文TS-FAN模型在Caltech数据集和ETH数据集上的检测效果,图7和图8显示了本文方法与当前一流行人检测方法的输出结果。

图7 在Caltech数据集上,本文方法与目前一流方法可视化效果对比Fig.7 Comparison of visualized effects of proposed method with some state-of-the-artmethods on Caltech dataset

图8 在ETH数据集上,本文方法与目前一流方法可视化效果对比Fig.8 Comparison of visualized effects of proposed method with some state-of-the-artmethods on ETH dataset
3 结 论
1)本文针对多尺度行人检测任务,设计了一种跨尺度特征聚合的多尺度行人检测网络,其通过多路径RPN尺度补偿策略为行人识别阶段提供了高质量的目标候选区域。
2)提出的TS-FAN网络模块为多尺度行人检测网络提供了高鲁棒性的特征层用于特征提取,并通过实验验证TS-FAN网络模块能显著提高行人检测性能。
3)通过多尺度行人检测网络,联合多路径RPN得到的候选目标区域和跨尺度聚合特征进行行人识别和精细化空间位置。实验结果表明,本文方法TS-FAN在Caltech数据集和ETH数据集上取得了一流的多尺度行人检测性能。
猜你喜欢
环球时报(2022-09-19)2022-09-19 17:19:22
Contemporary Social Sciences(2021年5期)2021-11-22 10:38:10
北京航空航天大学学报(2021年9期)2021-11-02 08:24:16
意林(2021年5期)2021-04-18 12:21:17
少儿美术(快乐历史地理)(2019年2期)2019-06-12 08:43:06
中国交通信息化(2019年2期)2019-03-25 03:20:16
扬子江(2019年1期)2019-03-08 02:52:34
小天使·一年级语数英综合(2017年6期)2017-06-07 23:51:16
童话世界(2017年11期)2017-05-17 05:28:25
中国交通信息化(2015年10期)2015-06-06 06:39:32
