
基于MobileFaceNet网络改进的人脸识别方法
2020-11-07 12:38张子昊王蓉
北京航空航天大学学报 2020年9期
张子昊,王蓉,*
(1.中国人民公安大学 警务信息工程与网络安全学院,北京 100038;2.安全防范技术与风险评估公安部重点实验室,北京 100038)
人脸特征具有易获取、易捕捉、易处理以及非接触式等特性,已经受到学者们的广泛关注,并在公共安全等领域应用日趋广泛。但是,在实际的应用场景下,人脸识别精度依然受到不同的姿态、光照、遮挡等因素的影响。因此,如何提取更具鲁棒性的特征来有效地辨识人脸便成为解决问题的关键。传统的人脸识别方法主要有主成分分析法(PCA)[1]以及局部二值模式(LBP)[2]。主成分分析法就是将高维人脸信息通过正交变化投影到低维子空间中,形成特征脸,然后通过分类器对低维的特征脸进行分类;局部二值法是将检测窗口划分为许多小区域,对每一个像素将其与周围相邻像素比较,并重新赋值,通过计算每个区域的直方图,并使用机器学习的方法对其进行分类。近年来,随着深度学习应用的日趋广泛,使用深度学习的方法来进行人脸识别成为计算机视觉领域的热门方向。
与传统方法相比,深度学习的方法通过海量的数据来训练模型,使模型提取到的人脸特征更具有泛化性。最具代表性的是香港中文大学汤晓鸥团队提出的Deep ID[3]系列。该团队中的Sun等提出Deep ID1[4]通过使用单一的卷积网络来进行特征提取并进行分类识别,之后,又在文献[4]的基础上提出了Deep ID2[5]模型,通过将人脸认证信号和人脸验证信号引入网络,以达到增大类间距缩小类内距的要求。随后,为了进一步提高模型提取特征的代表性和鲁棒性,Google提出了FaceNet[6]模型,将模型映射到欧几里德空间,并使用三元组损失Trip let loss[7]来增大类间距,从而提高模型性能;为了解决不同特征向量大小对分类效果的影响,Deng等提出Arcface[8]损失,将特征向量归一化到超球面上,使模型在角度空间对分类的边界进行最大化;为了解决训练过程中超参数的选择问题,Zhang等提出AdaCos[9]人脸损失函数,引入自适应动态缩放参数来解决超参数的选择问题。但是以上介绍的方法中主干网络大多比较复杂,模型参数较多,增加了计算量,影响计算效率以及模型的收敛速度。
本文在MobileFaceNet[10]网络的基础上加入风格注意力机制,将改进后的模型作为特征提取网络,使提取到的特征更具代表性和鲁棒性。同时引入AdaCos人脸损失函数来对模型进行训练,通过动态自适应缩放系数的调节优化训练,减少了人为调节超参数对训练的影响,提高了训练效率。
1 基于M obileFaceNet网络的人脸识别方法
1.1 M obileNetV1和M obileNetV 2网络
MobileNetV1[11]是Google发布的网络架构,提出深度可分离卷积的概念。其核心就是把卷积拆分为Depthwise+Pointwise两部分。其中Depthwise卷积是指不跨通道的卷积,即Feature Map的每个通道有一个独立的卷积核,并且这个卷积核作用且仅作用在这个通道之上,输出Feature Map的通道数等于输入Feature Map的通道数,因此它并没有升维或者降维的功能。Pointwise卷积用于特征合并以及升维或者降维,一般使用1×1的卷积来实现功能。由此,可以将一个普通的卷积拆分成如图1所示的结构,图中:N、M 和Dk分别为卷积的个数、卷积通道数和卷积的宽、高。
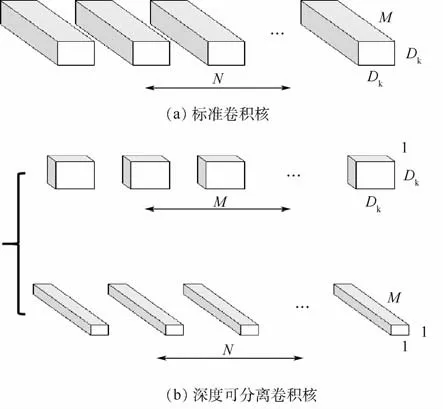
图1 可分离卷积示意图Fig.1 Schematic diagram of detachable convolution
标准卷积的参数数量是Dk×Dk×M×N;卷积核的尺寸是Dk×Dk×M,一共有N个,每一个都要进行Dw×Dh次运算,所以标准卷积的计算量P1为
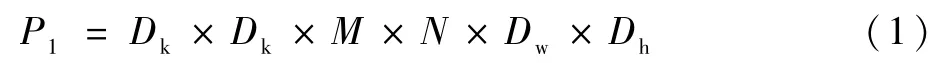
式中:Dw和Dh分别为标准卷积的宽和高。
深度可分离卷积的参数量是:Dk×Dk×M+1×1×M×N;深度可分离卷积的计算量是由深度卷积和逐点卷积两部分组成:深度卷积的卷积核尺寸Dk×Dk×M,一共要做Dw×Dh次乘加运算;逐点卷积的卷积核尺寸为1×1×M,有N个,一共要做Dw×Dh次乘加运算,所以深度可分离卷积的计算量P2为

参数数量和乘加操作的运算量下降倍数P3为
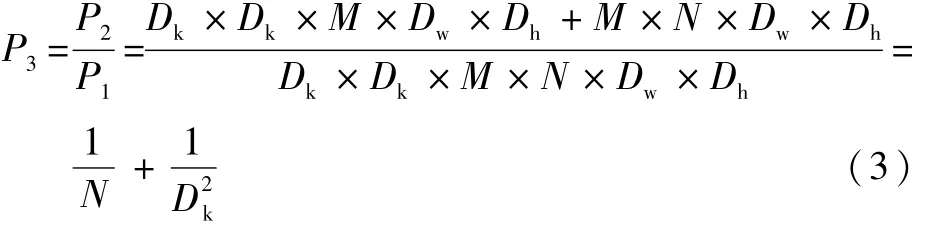
从式(3)可以看出,深度可分离卷积在参数数量以及计算量上与标准卷积相比,大幅度的降低,提升了模型的运算效率。
深度卷积本身没有改变通道的能力,即输入通道等于输出通道若是输入通道数较少,则深度卷积只能在低维度工作,最终卷积效并不会很好。所以MobileNetV2[12]在MobileNetV1的深度卷积层之前,使用1×1的卷积进行升维操作,使网络在一个更高维的空间进行特征提取,这就使得提取到的特征更具全局性。同时,为了解决低维度Relu运算产生的信息丢失问题,将最后一个Relu替换成Linear线性激活函数。MobileNetV2网络结构如表1所示,表中:z为通道扩张倍数;c为输出通道数;n为重复次数;v为步长;f为输入通道数。
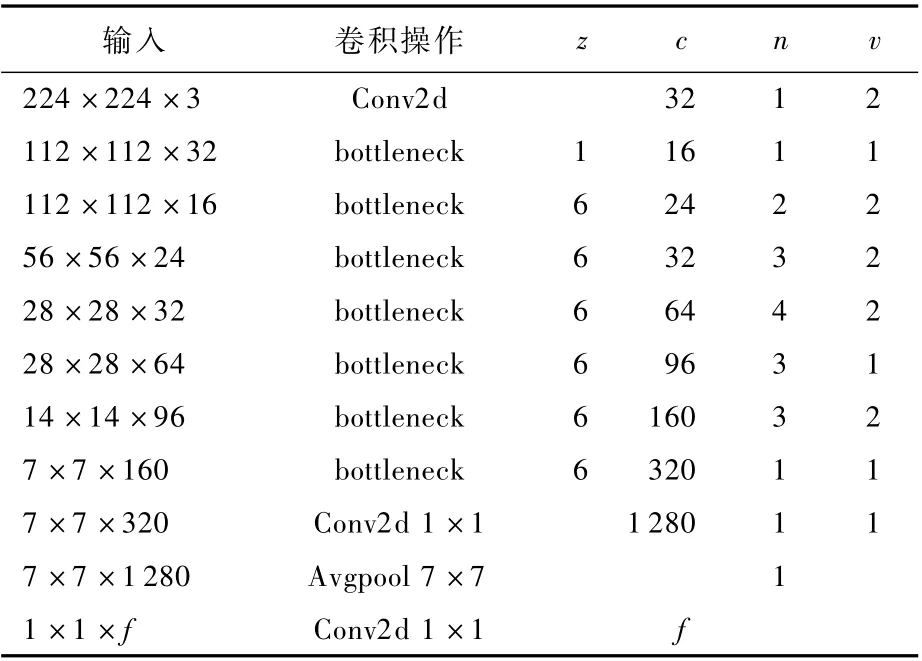
表1 M obileNetV2网络结构Table 1 M obileNetV2 network structu re
1.2 M obileFaceNet人脸特征提取网络
MobileFaceNet是MobileNetV2的改进版本。由于MobileNetV2中使用的是平均池化层,但是针对同一张图片,不同像素点的权重是不同的,全局的平均池化将权重平均,网络的表现能力自然会下降。所以在MobileFaceNet中,使用一个7×7×512的可分离卷积代替原本的全局平均池化层。同时使用Prelu代替Relu激活函数,并引入归一化层来加快模型收敛,防止模型过拟合。MobileFaceNet的网络结构如表2所示。
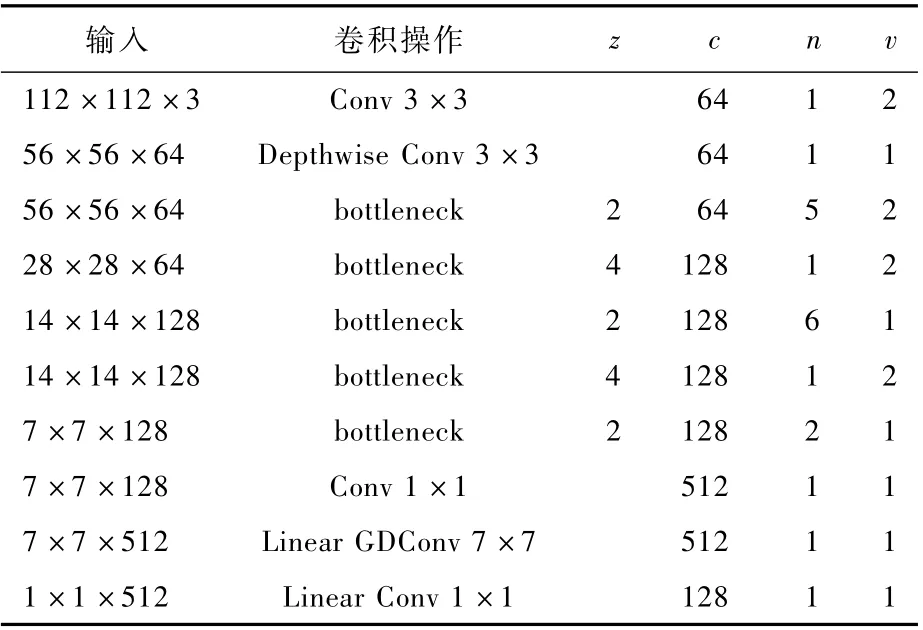
表2 M obileFaceNet网络结构Tab le 2 M obileFaceNet network structu re
网络结构不仅保留了MobileNetV2的升降维层以及线性激活函数,同时还在全连接层之前引入7×7的可分离卷积来替代原本的平均池化层,使网络提取到的特征更具泛化性和全局性。
1.3 AdaCos人脸损失函数
Softmax目前被广泛应用于图片分类中,主要通过输出样本属于各个类的概率大小来区分不同类别之间的特征。但是Softmax并没有对类内和类间距离进行约束,这就大大影响了人脸识别的精度。最新的人脸损失函数Arcface以及AdaCos就是基于Softmax改进的。
1.3.1 Arcface损失函数
Softmax函数为
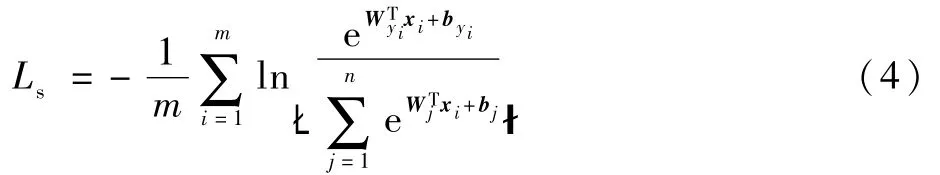
式中:m为每一个训练批次的大小;i为图像编号;j为当前样本的真实标签+byi表示全连接层输出,、xi、byi和yi分别为第i个图像类别的权重、图像的特征、图像类别的偏差和图像的真实类别的标签。通过提高+byi所占有的比重,提高对该类别的分类效果。但是Softmax只考虑到样本的分类正确性,而对于人脸识别这样的多分类问题,缺乏类内和类间距离约束。又因为为特征向量x和权重W 之间的夹角,即特征向量相乘包含有角度信息。为了让卷积网络提取到的特征可以学习到更可分的角度特性,将特征的权重值固定成一个定值s,同时为了简化模型参数,将偏置值设为0。这就将提取到的特征转化到了角度空间,使得决策边界只与角度有关。最后,通过引入一个新参数t(t>0)来控制角度余弦量值的大小,使得网络可以学习到更有区分度的特征。最终Arcface损失函数为

1.3.2 AdaCos损失函数
AdaCos损失函数在Arcface的基础上引入一个动态自适应缩放系数sd,使得在训练过程中可以动态地调整超参数,同时去掉了控制角度余弦量值的参数t。最终AdaCos损失函数为
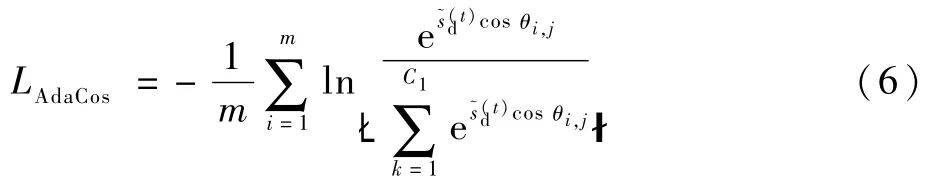
式中:C1为类别的数量;θi,j为特征向量xi和对应权重之间的夹角为一个动态缩放系数,会随着迭代次数td的不同,取值有2种情况,如下:

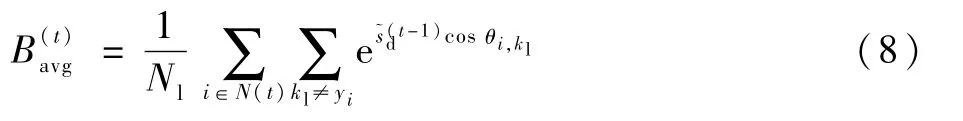
式中:N(t)为一个批次中人脸的类别数量;Nl为类别总数;kl为第i个图像的真实类别。
由AdaCos的公式可以看出,动态自适应参数在每次迭代的时候对分类概率的影响是不同的,由此就可以根据模型的收敛程度动态的产生合理的缩放系数,加快模型的收敛速度。
2 改进方法
本节在MobileFaceNet人脸特征提取网络的基础上,将风格注意力机制重新校准模块(Stylebased Recalibration Module,SRM)[13]加入到MobileFaceNet网络中,进一步提高了提取特征的鲁棒性和全局性。人脸识别方法流程如图2所示,多任务卷积神经网络(MTCNN)是一种人脸检测方法。
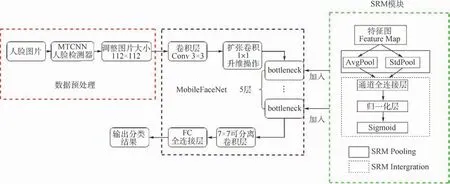
图2 人脸识别方法流程Fig.2 Face recognition method flowchart
方法流程主要分为3个部分,即数据预处理、基于SRM模块改进的MobileFaceNet人脸特征提取网络、输出人脸分类结果。之后使用自适应人脸损失函数AdaCos来监督训练过程,减少了设置超参数对训练效果的影响,同时进一步扩大类间间距,缩小类内间距。方法的整体实现是基于pytorch框架。
2.1 SRM 模块
通常来说,不同的人脸图像会有不同的属性特征,卷积网络层通过提取图片特征来进行分类和识别。然而,针对不同的人脸图像会有不同的风格,这些风格属性会进一步影响卷积网络对特征的提取,进而影响之后的识别和分类精度。
SRM通过特征重新校准的形式明确地将风格信息合并到卷积神经网络(CNN)表示中。根据不同人脸图像的风格属性,动态地估计各个风格特征的相对重要性,然后根据风格的重要性动态的调整特征权重,这使得网络可以专注于有意义的风格信息,而忽略不必要的风格信息。SRM 模块结构如图3所示,C、H、W和d分别为通道的个数、特征图高度、特征图的宽度和风格特征的数量。
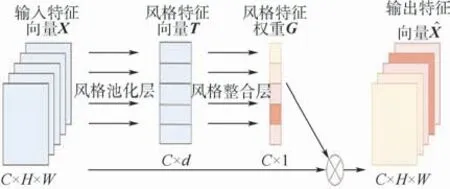
图3 SRM模块结构Fig.3 SRM module structure
SRM模块由2个主要组件组成:风格池化层(Style Pooling)和风格整合层(Style Integration)。风格池化层通过汇总不通空间维度的特征响应,从每个通道提取风格特征;风格整合层通过逐通道操作,针对图片的不同位置,利用风格特征生成相应的风格权重。同时根据不同的风格权重重新校准特征映射,以强调或隐藏它们的信息
与幼儿谈话,是发展幼儿语言能力较好的一种方法。但在实际教学中我们发现,和幼儿谈话时,刚开始幼儿往往有着很强烈的交流欲望,但随着活动的进展和时间的推移,幼儿往往会出现注意力不集中、交流兴趣下降、谈话效果不理想的状况。
2.1.1 风格池化层
风格池化层包括2个部分,即平均池化层和标准差池化层。对于每一个输入为 X ∈RNd×C×H×W的特征图,Nd为小批次中样本的个数,首先通过平均池化层,具体操作如下:

式中:μnc为原特征图平均池化后的结果;xnchw为原特征图,n、c、h和w分别为Nd、C、H和W 的分量。其次,将平均池化层的结果与原输入特征图进行标准差的计算,具体过程如下:

式中:σnc为经过标准池化层后的结果。最后,经过风格池化层的结果如下:

其中:tnc为经过风格池化层后的特征向量。
2.1.2 风格整合层
风格整合层包括3个部分,即通道全连接层(Channel-wise Fully Connected,CFC)、归一化层(Batch Normalization,BN)[14]以及激活层。将从风格池化层输出的结果作为风格整合层的输入,具体操作如式(12)~式(16)所示。

2.2 基于风格注意力机制改进的M obileFaceNet人脸特征提取网络
MobileFaceNet人脸特征提取网络中有5个bottleneck层,其结构如图4所示。
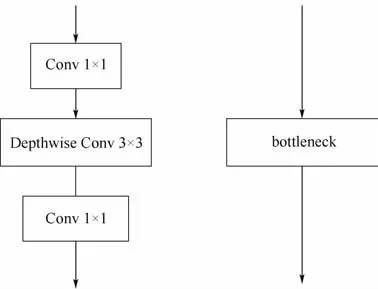
图4 MobileFaceNet中bottleneck层结构Fig.4 Structure of bottleneck layer in MobileFaceNet
将SRM模块加入到bottleneck层中后的结构如图5所示。
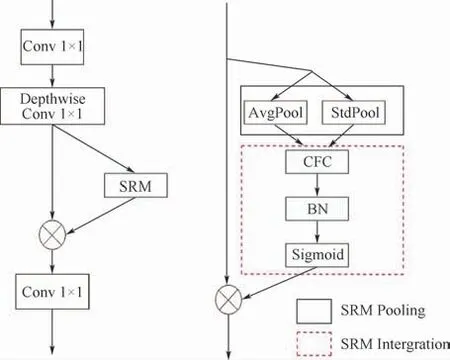
图5 MobileFaceNet-SRM bottleneck层结构Fig.5 MobileFaceNet-SRM bottleneck layer structure
将SRM结构放在了bottleneck层中的Depthwise操作之后,使得特征提取网络可以根据特征图的风格信息来动态地增强有用的特征表达,抑制可能的噪声,提高了特征提取的鲁棒性和代表性。这一操作与MobileNetV3[15]的网络架构相似,不同的是MobileNetV3的网路架构加入SE模块[16]。
3 仿真实验与结果分析
3.1 实验设置
3.1.1 数据预处理
本文使用CASIA-Webface人脸数据集作为训练数据集,包含了10 575个人的494 414张图像。使用MTCNN[17]人脸检测方法对CASIA-Webface中的图片进行再检测,并将检测到的人脸图片裁剪成112×112个像素大小。
测试数据集选用的是LFW、CFP-FF、以及AgeDB 3个人脸数据集来进行模型的评估。LFW数据集包含5749人共13233张人脸图像;CFP数据集包含500个身份,每个身份有10个正脸,4个侧脸,本实验使用CFP数据集中的FP(Frontal-Profile)人脸验证,即CFP-FP(CFP with Frontal-Profile)数据集;AgeDB 数据集包含440人共12 240张人脸图像。
3.1.2 实验环境及参数设置
实验中所有方法都是在pytorch框架下通过python语言实现的。训练和测试步骤在NVIDIA GTX2080Ti GPU上运行。训练总轮数epoch设置为50,训练初始学习率设置为0.1,迭代到10、25、40个epoch时,学习率每次除以10。训练中的bitchsize设置为64,总的权重衰减参数设置为5×10-4;使用随机梯度下降策略SGD优化模型,动量参数设置为0.9。
3.2 在不同backbone上的结果
不同的特征提取网络分别为Resnet-50、MobileFaceNet、MobileFaceNet-SRM,并 使 用AdaCos人脸识别损失来监督训练过程。ResNet50是AdaCos使用的基础网络;MobileFaceNet是改进前的特征提取网络;MobileFaceNet-SRM 是加入SRM模块后的特征提取网络。评估指标包括在3个数据集上的测试准确度以及模型大小,具体表现如表3所示。从表3可以看出,基于Mobile-FaceNet人脸识别方法在3个数据集上的测试准确度与ResNet50相比,在LFW、CFP-FF、AgeDB 3个数据集上分别提升了 0.49%、0.81%、2.48%,同时模型参数数量大大降低;在将SRM模块加入到MobileFaceNet后,与改进前的模型相比,模型参数数量略有提升,但是识别精度在LFW、CFP-FF、AgeDB 3个数据集上分别提升了0.25%、0.16%、0.3%,可以看出改进后的模型在精度上有所提升,证明了改进后模型的有效性。

表3 基于AdaCos的损失函数不同卷积框架人脸识别模型性能比较Tab le 3 Perform ance com parison of face recognition m odels w ith different convolution fram es based on AdaCos loss function
图6是3种主干网络在人脸损失函数Ada-Cos监督训练下,在AgeDB评测数据集上的受试者工作特征(Receiver Operating Characteristic,ROC)曲线。横轴为假正率(FPR),指的是分类器识别出的假正实例占所有负实例的比例;纵轴为真正率(TPR),指的是识别出的真正实例占所有正实例的比例。从图6可以看出,MobileFaceNet相较于ResNet50网络识别精度有明显提升,同时模型参数数量大大减少,计算效率有所提高。在向MobileFaceNet中引入风格注意力机制后,准确度相较于改进前的模型有所提升,这表明改进后的MobileFaceNet人脸识别方法的有效性。
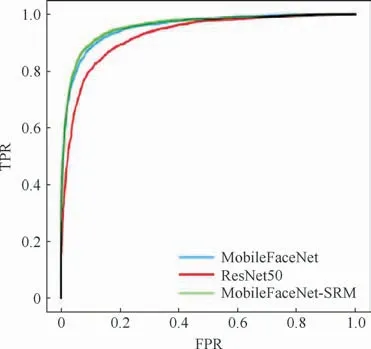
图6 三种主干网络在AgeDB数据集上的ROC曲线Fig.6 ROC curves of three backbone networks on AgeDB dataset
4 结 论
1)本文基于MobileFaceNet网络提出了一种新的人脸识别方法,通过引入风格注意力机制来增强特征的表达,将改进后的模型作为特征提取网络,大大减少了模型的参数数量,提高了模型的计算效率,同时提高了提取特征的鲁棒性和代表性。
2)使用自适应缩放损失函数AdaCos作为人脸损失函数来监督训练,通过动态自适应缩放系数,在训练过程中动态调整超参数,加快了模型的收敛速度。在LFW、CFP-FF和AgeDB 3个人脸数据集上对算法性能进行评测。
3)实验结果表明,本文方法相较于之前的人脸识别方法,在识别精度有所提升的基础上,大大降低了模型参数的数量,有效地减少了模型的计算量以及模型复杂度。
猜你喜欢
作文中学版(2022年1期)2022-04-14
少儿美术·书法版(2021年9期)2021-10-20
科技创新与应用(2021年23期)2021-08-30
无线互联科技(2020年15期)2020-11-10
学生天地(2020年31期)2020-06-01
科技传播(2020年6期)2020-05-25
动漫星空(2018年9期)2018-10-26
雷达科学与技术(2018年3期)2018-07-18
计算机工程(2015年8期)2015-07-03
发明与创新(2015年33期)2015-02-27
