
融合多源数据的企业竞争对手画像构建
2020-11-06 07:27黄晓斌张明鑫
现代情报 2020年11期
关键词:数据融合
黄晓斌 张明鑫
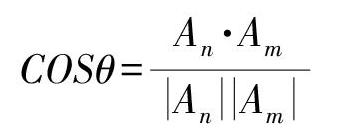
作者简介:黄晓斌(1961-),男,教授,博士,研究方向:信息分析与情报研究、竞争情报。张明鑫(1996-),男,硕士研究生,研究方向:信息分析与信息行为。
摘要:[目的/意义]融合多源数据,从大量真实具体的企业竞争对手中抽取出竞争对手的画像,为解决海量竞争对手无限性和企业竞争情报资源有限性之间的矛盾提供启发。[方法/过程]从画像指标体系、数据采集、数据融合、数据分析、画像构建和画像应用等环节出发,提出了一套融合多源数据的企业竞争对手画像构建模式,然后以H公司为例开展了实证研究。[结果/结论]基于所提出的竞争对手画像构建模式,构建了H公司的主要竞争对手画像,从而为企业的竞争对手画像构建实践以及为后续相关理论研究和实证研究提供参考。
关键词:企业竞争对手;多源数据;多源信息;数据融合;画像研究
DOI:10.3969/j.issn.1008-0821.2020.11.002
〔中图分类号〕G25225〔文献标识码〕A〔文章编号〕1008-0821(2020)11-0013-09
Construction of Enterprise Competitor Portrait Based on Multi-source Data
Huang XiaobinZhang Mingxin
(School of Information Management,Sun-Yat-Sen University,Guangzhou 510006,China)
Abstract:[Purpose/Significance]This paper integrates multi-source data and extracts the portraits of competitors from a large number of real and specific enterprise competitors,which provides inspiration for solving the contradiction between massive competitors and the limitation of competitive intelligence resources.[Method/Process]From the aspects of portrait index system,data collection,data fusion,data analysis,portrait construction and portrait application,this paper put forward a set of competitor portrait construction model with the integration of multi-source data.Furthermore,an empirical study with H company as an example was carried out.[Results/Conclusions]Based on the proposed construction model of competitor portraits,this paper constructed the portraits of major competitors of H company,so as to provide reference for the practice of the construction of competitor portraits and the subsequent theoretical and empirical research.
Key words:enterprise competitors;multi-source data;multi-source information;data fusion;portrait research
“知己知彼,百戰不殆”,在激烈的市场竞争中,企业为了保持竞争优势,需要不断监测和分析竞争对手的动向,及时调整自身的经营策略和战略规划。传统的企业竞争对手监测,重点关注对某一个或某几个具体的企业竞争对手进行分析;然而,伴随着大数据和互联网的不断发展,企业面临的竞争环境和竞争格局日趋复杂,来自不同行业和不同领域的海量竞争对手均有可能对企业造成威胁。在实践中,囿于企业竞争情报资源有限性的制约,单一地对某一个或某几个具体的竞争对手进行跟踪监测或会造成一定的认知偏差,进而不利于企业了解海量竞争对手的一般情况。因此,企业需要在真实竞争对手的基础之上,从具体的竞争对手中抽象出能够反映海量竞争对手的一般画像特征。从大量真实具体的竞争对手中抽象出企业竞争对手的画像,不仅有助于企业快速识别和了解潜在竞争对手的一般情况,树立学习标杆和赶超对象,同时也有助于企业通过对竞争对手画像的分析,来实现对画像背后所代表的大量竞争对手的监测和预警,从而提升企业竞争情报活动的效率。可见,建立企业竞争对手画像,是解决海量竞争对手的无限性和企业竞争情报资源有限性之间矛盾的重要途径。尤其在多源数据环境下,如何从不同来源搜集不同类型的数据,采用多种方法构建企业竞争对手的画像,从而为企业的标杆学习、竞争对手监测和预警等提供支撑,成为企业竞争对手情报分析的重要问题。
为了解决以上问题,本研究首先回顾了多源数据融合、画像研究和企业竞争对手研究等国内外相关文献,然后基于已有成果,提出了一套融合多源数据和方法的企业竞争对手画像构建模式,指出了融合多源数据和方法的企业竞争对手画像构建的要素、流程、方法和应用等关键问题,最后以H公司为例,搜集数据开展了实证研究,以期为企业的竞争对手画像构建实践以及为后续相关理论研究和实证研究提供启发。
1相关研究述评
多源数据融合是指将利用多种方式采集的、不同来源和不同呈现形式(如文本、数值和图片等)的数据融合到一起,使其形成统一格式并面向多种应用的数据集合的過程;多源数据融合可以划分为多传感器数据融合和社会数据融合[1-2]。首先,多源数据融合最早起源于军事遥感领域[2]。由于在遥感领域实践中,不同类型的传感器采集的数据等存在着多源异构的特点,因此如何对多源异构的数据进行融合处理,成为遥感领域关注的重点。因此,早期的多源数据融合又被称为多传感器数据融合[3]。同时,多源数据融合在社会科学领域也逐渐受到了重视。不同社会科学领域的学者结合本学科领域的问题,对搜集的多种来源和多种形式的社会数据进行融合,并开展了相关研究。例如,鲁奇[4]对旅游客户多源数据进行融合,实现了对旅客用户群体的细分研究;张大勇等[5]融合微信多源数据,探讨了微信用户信息分享行为的发生机理。
与此同时,如何融合不同来源的数据开展企业竞争对手相关研究,也成为情报学领域关注的重要方向。首先,企业竞争对手评价指标体系是开展企业竞争对手评价的核心,而指标体系所指向的指标数据往往具有非结构化、异质性和分散性等特点,因此,企业竞争对手评价应当包括指标信息融合环节[6]。具体而言,所建立的企业竞争对手评价指标可以包括定性指标和定量指标[7]。在定量指标的融合转换方面,采用数据归一化方法实现不同类型定量数据之间的无量纲化;在定量-定性指标之间的融合转换方面,一般的数据融合思路是将定性指标统一转换为定量指标,计算定性文本的主题隶属度或情感倾向值(取值范围[0,1]),将隶属度或情感倾向值作为数据转换结果[8]。然而,竞争对手评价指标体系侧重于从竞争对手的资源、能力和技术等角度评价竞争对手的威胁力和竞争力[7],而竞争对手画像的目标在于从若干具体的竞争对手中抽取竞争对手的画像特征,用更加生动、直观和形象的“拟人化”方式理解和描述竞争对手。
而用户画像研究相关的成果,为企业竞争对手画像的构建提供了有益的思路。用户画像是现实中典型目标用户的抽象,是基于大量真实用户的人口特征、认知特征和行为特征的刻画结果[9]。例如,在构建视频用户画像的过程中,吴剑云等[9]学者将用户的自然属性(ID、昵称和性别等)和活动属性(活动兴趣属性和视频兴趣属性等)作为用户画像属性特征,利用K均值算法等模型对用户聚类,构建了视频用户画像。袁润等[10]学者将用户基本属性数据和行为数据作为用户画像特征数据,采用数理统计等方法构建了学术博客用户画像。王益成等[11]学者将用户的期望偏好数据和用户行为日志数据作为描述科技情报用户画像的重要数据来源。可见,基本人口统计特征、认知特征和行为特征是构建用户画像的3个重要维度。
已有的多源数据融合、企业竞争对手和用户画像等相关研究为本研究开展企业竞争对手画像构建提供了理论基础和方法基础。然而,已有研究主要关注多源数据融合视角下的科研团队画像和用户画像等,较少有学者关注企业竞争对手画像构建研究。融合多源数据与方法开展企业竞争对手画像构建研究,有助于为企业的竞争对手监测预警和标杆学习等提供启发,解决企业竞争情报资源有限性和海量竞争对手无限性之间的矛盾。因此,本研究借鉴用户画像构建的思路和方法,提出了一套适合企业竞争对手画像构建的模式,并结合该模式以H公司为例开展了实证研究。
2融合多源数据的企业竞争对手画像构建模式
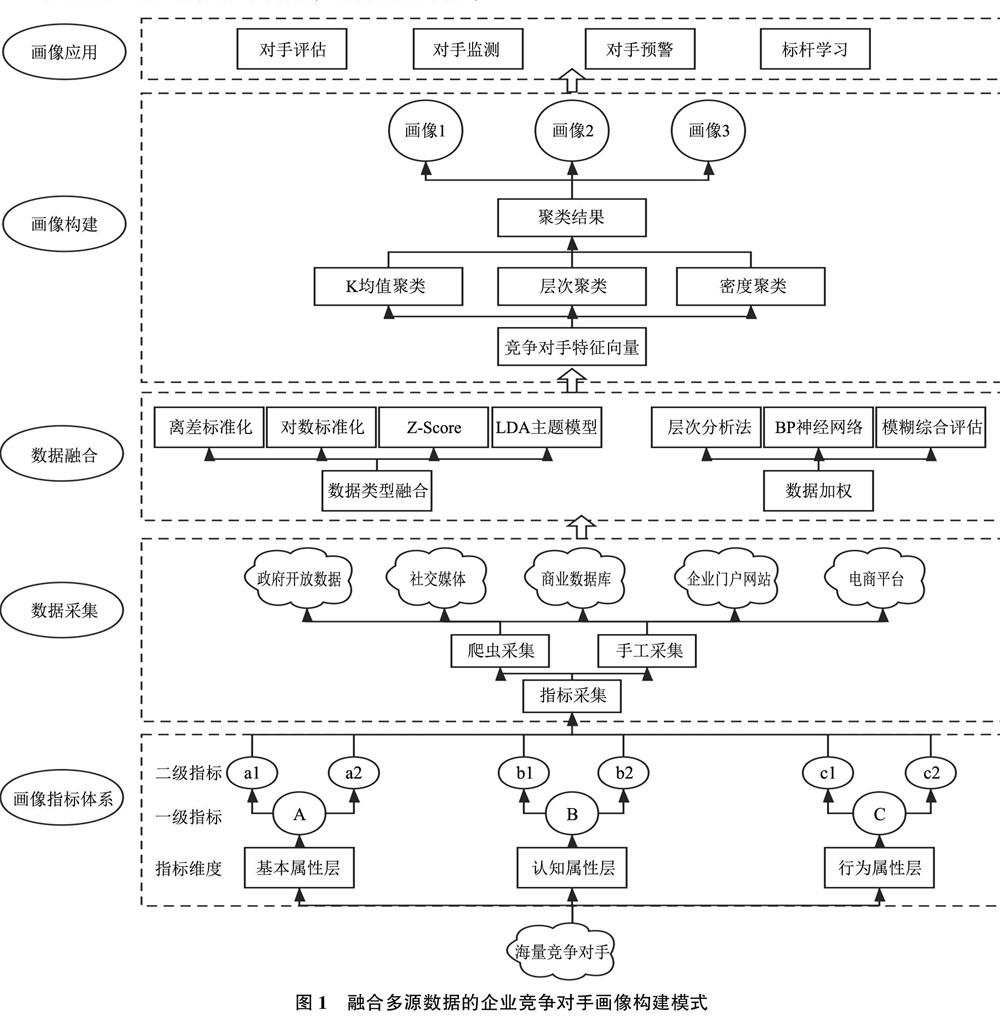
本研究从画像指标体系构建、指标数据采集、多源异构数据融合、画像构建和画像应用5个环节出发,提出了企业竞争对手画像构建模式的流程、数据来源、数据融合方法、画像构建方法和画像应用场景等关键问题,如图1所示。
21企业竞争对手画像维度及指标体系
借鉴用户画像的定义,本研究将企业竞争对手画像理解为建立在企业真实竞争对手的基础之上,从具体的竞争对手中所抽象出来的,能够反映潜在竞争对手普遍典型特征的虚拟代表;其重要意义在于通过对画像的跟踪监测,实现对画像背后所代表的大量真实竞争对手的分析。借鉴用户画像的基本思想,从基本属性层、认知属性层和行为属性层3个维度出发明确企业竞争对手画像的维度,从而实现了用户画像三维度与企业竞争对手画像三维度的一一映射,最终实现了对企业竞争对手的“拟人化”描述,如图2所示。
在明确了企业竞争对手画像的3个维度之后,分别从基本属性层、认知层和行为层出发建立画像指标体系。其中,基本属性层指标侧重于各类型的客观特征(如用户画像中的性别年龄和竞争对手的
企业规模等),认知层关注各类型的主观认知层面的指标(如用户画像中的性格以及竞争对手的品牌形象等),而行为层关注具体的行为指标(如用户画像中的用户浏览检索行为和企业竞争对手的兼并购行为)。
22指标数据来源及采集
明确了画像指标体系之后,进一步采用网络爬虫采集或手工采集等方法搜集竞争对手各个指标的数据。例如,采用网络爬虫或手工采集等方式从对手网站中获取竞争对手的企业基本信息、产品信息、企业战略、愿景使命和企业最新动态等涉及基本属性层、认知层和行为层3个维度的画像指标数据。
23多源异构数据融合
然而,不同类型的指标数据来源不同,在数据类型和数据格式上也存在较大差异;因此需要对多源异构指标数据进行融合预处理。多源数据融合主要涉及同名消歧、别名识别、字段映射和数据加权等问题[12-13],而结合本研究的实际,本研究的多源数据融合主要涉及的是不同类型指标数据的数据类型融合转换和数据加权问题。
1)数据类型融合问题。首先,在定量-定量指标数据融合方面,定量指标之间存在着量纲差异,而为了消除定量指标之间的量纲差异,需要采用一定的算法实现无量纲化。离差标准化、对数标准化和Z-score算法等方法是较为常见的实现定量数据无量纲化的方法。其次,在定性-定量指标数
据融合方面,以企业产品口碑等为代表的指标以定性指标为主,为了实现定性-定量指标数据的融合转换,需要综合采用文本分类算法、TF-IDF算法或LDA主题模型等计算某文本隶属于某主题的倾向值(取值范围[0,1]),将其情感倾向值作为融合转换的结果并用于后续研究。其主要流程包括文本清洗预处理、分词与词性标注、关键词抽取、竞争对手关键词向量构建和向量相似度或情感倾向值计算等。
2)数据加权问题。最后,在指标数据加权方面,实现了不同类型指标数据的融合之后,还需要确定不同指标之间的权重大小,其主要方法包括模糊综合评价方法、BP神经网络法和层次分析法等。其中,层次分析法要求参考决策者和领域专家的打分意见,兼具定性和定量的特点,是一种计算指标权重较为重要的方法。具体流程包括:确定指标、指标判别比较、构造判断矩阵、计算矩阵特征向量、计算矩阵权重向量和一致性检验。基于层次分析法所确立的指标权重,计算出加权之后的竞争对手各个维度的指标值,为后续的竞争对手特征向量构建提供基础。
24数据分析及画像构建
对企业竞争对手的各个维度的指标进行了融合转换处理和指标加权处理后,进一步开展数据分析并构建画像。企业竞争对手画像构建的核心在于对海量竞争对手的归纳,抽取出具有一般性和代表性的“虚拟对手”;而聚类分析能够实现对具有相似特征的单位的聚集和分类,通过聚类结果来抽取画像。因此,聚类分析方法在画像研究的方法体系中占据着十分重要的位置。主要流程包括:
1)构建竞争对手的特征向量。设企业竞争对手集为M={A1,A2,A3,…,An},其中An表示第n个竞争对手;第n个竞争对手的特征向量为An=(b1,b2,b3,…,bi),其中bi表示第i个指标(取值[0,1])。
2)特征向量两两间相似度计算。采用余弦夹角算法,计算竞争对手特征向量两两之间的相似度。
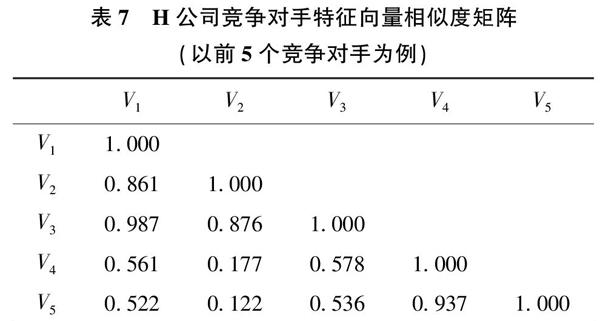
3)构造竞争对手特征向量距离矩阵。基于竞争对手特征向量两两之间的相似度,构造特征向量相似度矩阵,如表2所示。
4)基于相似度矩阵,采用K均值聚类和层次聚类等算法进行聚类分析。以层次聚类算法为例,利用简单连接法、完全连接法、平均连接法、质心法或Ward法等对矩阵进行聚类。
5)提取并描述聚类结果。由研究者提取出聚类结果并对聚类分析结果进行解读和描述,采用可视化图表或故事化面板等形式展现企业竞争对手画像,并将其提交至决策者。
25画像应用
最后,将可视化呈现的竞争对手画像用于企业的管理和决策活动之中,实现竞争对手画像的应用价值,包括:
1)对手监测。竞争对手画像用于企业竞争对手的动态监测过程中,能够通过对画像监测的方式实现对海量竞争对手的检测,包括了解竞争对手近期的成长变化情况(如市场占有率和市场规模的变化等)以及了解竞争对手近期的行为轨迹(如招聘和海外并购等)。
2)对手评估。用拟人画像的方式评估竞争对手的威胁力和实力等,为企业竞争对手评价提供重要依据,从而为企业管理层的决策提供支撑。
3)对手预警。与此同时,监测竞争对手画像,了解竞争对手近期的主要动向,从而挖掘出竞争对手背后的战略意图,为企业开展竞争对手预警活动提供参考。
4)标杆学习。最后,竞争对手画像对企业而言也具有标杆学习和定标比超的作用。借助企业竞争对手画像,企业可以了解竞争对手的主要优势,确定赶超目标,明确竞争方向,为企业的标杆学习活动提供启发。
3实证研究
31研究对象
H公司是我国知名的家电企业,成立于20世纪50年代末,经过几十年的发展已成为我国家电行业的综合型跨国企业。在H公司竞争对手的选择上,结合本研究的实际情况(如物力和人力限制,示范过程为主要目的等),采用简单随机抽样方法从目前国内家电行业领域的上市公司名单中随机抽取15个企业作为竞争对手,分别将其标记为V1、V2、V3、…、V15。通过构建以上竞争对手的画像,一方面为H公司的竞争策略提供启发;另一方面也为融合多源数据构建企业竞争对手画像提供示范和参考。
32画像指标体系
结合H公司所属家电行業的特点,分别从基本属性层、认知层和行为层3个维度构建了竞争对手画像指标体系。
33指标数据搜集
在指标数据采集方法上,采用人工采集和八爪鱼爬虫软件爬取方式,对随机选取的15个企业的指标数据进行了采集。在指标数据来源方面,基本属性层的企业规模、盈利能力和科研投入3个指标数据主要来源于上市公司的招股说明书和企业官网;认知属性层的企业文化指标来源于百度百科和企业官网,产品口碑指标来源于官方商城平台中的消费者评论;行为属性层的产品研发和产品促销指标均来自企业官网和官方商城。
34多源异构数据融合
341数据类型融合
1)定量-定量指标数据融合。首先使用离差标准化方法对全部定量指标数据进行归一化处理:
X*=X-MinMax-Min
其中,X*表示经过标准化处理的指标值(取值范围[0,1]),X表示实际值,Min和Max分别表示该指标的最小值和最大值。
2)定性-定量指标数据融合。首先,采用TF-IDF算法和人工合并的方式,从文本中提炼出企业文化和产品口碑下的二级指标。采用Python的Jieba分词工具对全部文本进行分词和词性标注,去除停用词和无实际意义的词之后,使用TF-IDF算法从文本中抽取出关键词,然后由人工对关键词进行筛选和合并,最终确定了企业文化和产品口碑两个定性一级指标下的6个二级指标,如表4所示。
然后,借鉴宋新平等[8]的思路,使用Python的SnowNLP库,计算每一位企业竞争对手的各个二级指标所对应的多个关键词所在句子的情感倾向值,将多个关键词所在句子的情感倾向值的均值作为对应二级指标的最终情感倾向值;其取值范围处于[0,1]之间,值越接近1,则表明该二级指标在某竞争对手的特征中越正向明显。进一步地,采用离差标准化方法对指标情感倾向值进行无量纲化处理,最终实现了对企业文化和产品口碑下的6个定性指标的量化融合转换处理。
342数据加权
然而,不同类型和不同来源数据的重要性或存在一定差异;因此,多源异构数据融合的另一个关键问题在于数据加权问题。进一步采用层次分析法,计算并赋予不同指标权重系数,主要流程如下:
1)判别打分,构造判断矩阵。对一级指标和二级指标两两之间进行判别打分,构造出判别矩阵。
2)计算矩阵特征向量。在构造了判断矩阵之后,采用方根法计算每一个指标的特征向量。其中,Mn表示矩阵每一行中的第n个元素,n表示每一行的元素个数,W为计算出来的该行的特征向量。以一级指标判断矩阵为例,其特征向量为(313,050,073,187,059,074,104)。
W=nM1×M2×M3…×Mn
3)计算矩阵权重向量。进一步计算出判断矩阵的权重向量,权重向量中的值即代表该矩阵中的对应指标的权重。其中,R代表特征向量中对应指标的权重值,n代表特征向量中的向量个数,Ki表示第i个特征向量。以一级指标为例,7个一级指标权重分别为(036,007,008,021,006,010,012)。
R=Ki∑ni=1Ki
4)一致性检验。最后,计算全部判别矩阵的CR和CI值,发现CR和CI均小于01,表明计算判断矩阵得到的权重结果具有较高的可靠性。
5)指标权重总排序。汇总得到全部指标的权重结果,如表6所示。
6)指标数据加权。获得指标权重之后,将15位竞争对手的各个指标数据进行加权处理,赋予其指标权重系数,进而实现了对不同来源指标的数据加权处理。
35聚类分析
1)构建竞争对手特征向量。基于数据类型融合和数据加权处理结果,构造出15位竞争对手的特征向量。以V1为例,其特征向量V1=(018,018,005,002,003,003,004,007,007,001,0005,0014,008,011)。
2)向量余弦相似度计算。对15位竞争对手特征向量进行两两之间的余弦相似度计算。
COSθ=An·AmAnAm
3)构建竞争对手相似度矩阵。基于竞争对手特征向量两两之间的余弦相似度,构建竞争对手相似度矩阵,如表7所示。
4)层次聚类分析。然后使用层次聚类分析,采用质心连接法对矩阵进行聚类,结果如图3所示。按照“簇间差异大,簇内差异小”的原则,将15位竞争对手划分为3个类别:竞争对手一号(V4、V5,V6,V8,V9,V11,V12,V13,V14,V15)、竞争对手二号(V2,V7)、竞争对手三号(V1、V3、V10)。
36画像构建
聚类结果表明,15位真实具体的竞争对手可以抽象为3个不同类型的竞争对手画像。因此,进一步对不同类别中所包含的竞争对手的指标数据进行描述性分析,并采用可视化图形等方式构建竞争对手画像,描述3种竞争对手画像的不同特点。
4结语与展望
本研究首先回顾了多源数据融合、企业竞争对手评价和用户画像研究等相关成果,然后从竞争对手画像指标体系、指标数据采集、多源异构数据融合、聚类分析、画像构建和画像应用等环节出发构建了一套融合多源数据的企业竞争对手画像构建模式,并以H公司为例,搜集指标数据展开实证研究,最终从H公司的主要竞争对手中抽取出了3个对手画像。
本研究具有一定的创新性和应用价值。首先,已有研究主要关注科研团队画像和用户画像研究,而本研究关注如何融合多源数据构建企业竞争对手画像;其次,本研究指出企业竞争对手画像应当借鉴用户画像的基本思想,从基本属性层、认知属性层和行为层3个维度出发构建“拟人化”的画像指标体系;最后,本研究提出了一套融合多源数据
的企业竞争对手画像构建模式,为后续理论研究和实践研究提供了借鉴。本研究也存在一定局限性,例如,受研究的人力物力等因素的影响,实证研究部分中所选择的企业竞争对手数量较少,未开展用户虚假评论的识别工作,画像指标体系和指标权重的确定过程较为粗糙。然而,鉴于实证研究部分的主要目的在于演示和示范本研究所提出的模式體系的有效性,因此从示范和参考的角度来看,实证过程依然具有一定的借鉴价值。
未来相关研究可以关注以下几个方面的内容:
1)构建企业竞争对手画像实时监测系统,实现竞争对手画像的自动监测和可视化呈现。对于企业而言,依赖人工开展指标数据的采集、数据融合、聚类分析和画像构建等,不仅需要耗费大量的人力物力,同时也会严重影响画像构建的效率和时效性。因此,企业可以建立竞争对手画像监测系统,将专家和决策者构建出的画像指标体系提交至系统,由系统自动采集和爬取各类型指标数据,基于数据融合算法实现不同类型数据的融合和加权处理,并自动开展聚类分析,形成聚类结果和可视化图表等。
2)注重采集指标的时间序列数据而非静态截面数据。此外,对于竞争对手画像的构建过程而言,关注竞争对手画像的演变和动态发展过程,也是竞争对手画像研究的重要内容。传统的静态截面数据只能反映某时某刻竞争对手的画像,其作用类似于给竞争对手“拍照”;而采用指标的时间序列数据开展竞争对手画像研究,有利于探析竞争对手画像的动态演变过程,其作用类似于给竞争对手“拍视频”,从而能更好实现竞争对手画像的追踪和实时监测。
3)区分多源数据融合、多源信息融合和多源情报融合,针对不同的融合层次选择恰当的融合方法。数据融合面向数据底层,信息融合面向中层而情报融合面向顶层;从底层到顶层,数据的有序性、知识性以及人的介入性越明显。遥感和物联网领域所谈及的多源数据融合主要面向数据底层,在融合方法上包括卡尔曼滤波法、多贝叶斯估计法、产生式规则和模糊逻辑理论等面向数据底层的融合算法[1,3]。而企业竞争对手画像研究面向社会数据融合,其融合层次更高,更多涉及的是中层融合,即信息融合。在融合多源数据的竞争对手画像研究过程中,除了定量-定量融合的离差标准化和定性-定量融合的LDA主题模型等方法,未来相关研究可以结合多源社会数据融合的特点开发出更多的融合方法。
4)关注多源社会数据融合中的信息失真现象,把握数据融合与信息失真之间的平衡。企业竞争对手的多源数据融合面向中层的信息融合,因此竞争对手的多源指标数据本身携带了大量的信息。然而,数据融合过程中或存在一定的信息失真现象,即采用数据融合方法对不同类型和不同来源的指标数据进行融合处理时,一部分数据或在融合过程中丢失其原本形态所携带的信息。
数据融合程度越深,其信息失真现象或越严重。因此,如何选择合适的融合方法和融合层次,把握数据融合与信息失真之间的平衡,也是未来相关研究需要关注的重点。
参考文献
[1]化柏林,李广建.大数据环境下多源信息融合的理论与应用探讨[J].图书情报工作,2015,59(16):5-10.
[2]周群,化柏林.基于多源数据融合的科技决策需求主题识别研究[J].情报理论与实践,2019,42(3):107-113.
[3]徐绪堪,吴慧中,张吉成,等.基于多源数据融合的突发事件决策需求研究[J].情报理论与实践,2017,40(11):40-44,51.
[4]鲁奇.基于多源数据挖掘的旅游客户细分研究[D].哈尔滨:哈尔滨工业大学,2008.
[5]张大勇,景东,卜巍.融合多源数据的微信用户信息分享行为特征研究[J].情报科学,2019,37(2):83-88.
[6]李贺,毛刚.基于竞争情报分析的企业竞争对手评价系统构建研究[J].情报科学,2009,27(2):249-253.
[7]徐海宁,孙忠林.企业竞争对手威胁力评估指标体系研究[J].图书馆学研究,2016,(2):93-97.
[8]宋新平,陈梦梦,申彦,等.大数据下基于多源信息融合的企业竞争对手评价模型研究[J/OL].情报理论与实践,http://kns.cnki.net/kcms/detail/11.1762.G3.20190919.1333.010.html,2019-09-19.
[9]吴剑云,胥明珠.基于用户画像和视频兴趣标签的个性化推荐[J/OL].情报科学,http://kns.cnki.net/kcms/detail/22.1264.g2.20200430.1545.017.html,2020-05-06.
[10]袁润,王琦.学术博客用户画像模型构建与实证——以科学网博客为例[J].图书情报工作,2019,63(22):13-20.
[11]王益成,王萍,张禹.基于向量空间模型的科技情报用户画像及场景化服务推送研究[J].现代情报,2020,40(2):3-10,25.
[12]莫君蘭,窦永香,开庆.基于多源异构数据的科研团队画像的构建[J/OL].情报理论与实践,http://kns.cnki.net/kcms/detail/11.1762.G3.20200502.0936.002.html,2020-05-06.
[13]化柏林.多源信息融合方法研究[J].情报理论与实践,2013,36(11):16-19.
(责任编辑:孙国雷)
