
弱监督场景下的行人重识别研究综述∗
2020-11-03 12:26:12于沛泽
软件学报 2020年9期
祁 磊, 于沛泽, 高 阳
(计算机软件新技术国家重点实验室(南京大学),江苏 南京 210023)
近年来,随着社会安防意识增强和科学技术的进步,城市中监控摄像头的数量越来越多.这些监控系统往往部署在写字楼、校园、商场、大大小小的街道和社区等各种各样的场所,在安防领域起到了重要的作用.例如:当某地发生偷窃事件时,公安机关或安保部门可以通过监控记录来获取偷窃者出现的时间及行踪轨迹等重要信息.不过对于监控中记录的视频数据,当前大多数情况都是通过人工的方式来进行查看、分析,工作量非常大且效率非常低.换句话说,通过人工的方式对多个摄像头中的内容进行关联,是一项非常耗时的工作.
随着人工智能技术的发展,许多曾经需要人来执行的任务都可以通过人工智能技术来实现,甚至在某些任务上机器比人完成得更加精确.例如在大规模图像数据集ImageNet[1]上,机器对于图像的分类任务远远比人更精确,并且识别速度比人更快速.计算机视觉技术能够帮助我们有效地利用现有的大规模图像或视频数据,并进行分析和理解.对于监控视频数据而言,行人是其主要的目标对象之一.目前,行人检测技术、行人跟踪技术和行人重识别技术(person re-identification,简称Re-ID)已经在学术界和工业界受到了广泛的关注.相对于行人检测技术和行人跟踪技术,行人重识别技术起步较晚,近些年才逐渐得以关注.传统的检测和跟踪技术只关注在一个视频中的行人目标,而行人重识别技术则关注多个视频中的行人之间的关联性,即旨在将多个不同的摄像头下的同一个行人目标进行关联.如图1 所示,实现一个完整的行人重识别系统,应当包括行人检测[2-4]、行人跟踪[5]和行人重识别[6,7]技术这3 个模块.
1 相关背景
从技术层面来讲,行人重识别是用某个查询图像(query image)在一个大的图像数据库(gallery set)中检索和匹配相关图像的任务,也可以看作是一种只针对行人图像的图像检索(image retrieval)任务,如图2 所示,其目标是希望获得具有判别性的特征来区分相同身份和不同身份的行人图像.因此,在行人重识别问题中,绝大部分工作都是关注在怎样获取具有判别性的特征上.由于行人图像来自多个不同的摄像头,因此该问题的研究在现实应用中面临着许多挑战,包括不同摄像头下图像的光照条件、分辨率、视角以及行人姿态等各方面差异.
当前,该领域的大部分工作都关注在有监督场景下的行人重识别问题.然而在现实中,行人重识别的数据标注工作往往需要花费大量的人力和财力,特别是对跨摄像头间的行人数据进行关联的这一步骤.并且在当前深度学习时代,大部分方法都是依赖大规模的有标记数据来训练一个深度模型.而数据标注的高成本使得有监督的方法难以扩展到现实应用中,这也是阻碍行人重识别技术能够真正落地的一大因素.另一方面,在现实中我们能够轻松获得大量无标记的行人数据.因此在行人重识别问题的研究中,如何使用少标记的大规模图像数据来训练得到鲁棒的模型,具有重大的研究价值和意义.
目前,大部分行人重识别领域的工作主要集中在有监督场景下相关算法的研究.早些年,一些研究者主要致力于提取鲁棒的特征来强化行人特征的判别性[8-12],也有一些研究者主要关注在学习方法上,例如设计更好的度量方法,以使其更容易地识别相同的人并区分不同的人[13-16],或者通过学习公共的子空间或字典来消除不同摄像头视角之间的差异[17-19].近些年,深度学习技术不断发展,特别是其在机器视觉应用领域取得了巨大成功,新提出的行人重识别方法基本上都是基于深度学习的.其中,一些研究工作使用注意力机制的方式来提高行人重识别模型的泛化能力[20-28],也有一些研究工作通过设计损失函数来提升行人重识别模型的性能[29-31].最近也出现了一些基于局部的学习方法[32-35],该类方法虽然简单,但是可以获得更具有判别性的特征,在行人重识别任务上取得了较优的性能.虽然在有监督场景下行人重识别问题已经有了突破性的进展,但是有监督场景下的学习不利于行人重识别模型很好地泛化到其他场景下,因此考虑在深度学习需要大量的有标记数据参与训练的背景下,研究弱监督场景下的少标记学习,在行人重识别任务中具有重大的意义与价值.
考虑到计算机视觉任务的相关应用在现实场景的落地需求,少标记学习在学术界和工业界渐渐受到关注.基于行人重识别任务,本文将少标记学习问题分为无监督的场景和半监督的场景,其更具体的场景分类如图3所示.
以下主要对当前存在的弱监督场景下的行人重识别方法进行总结、分类和对其性能进行分析.
2 无监督场景下的行人重识别问题
在深度学习时代之前,绝大部分无监督的方法主要借助传统的领域自适应方法来学习共享的模型参数[36]、公共的子空间[37]或字典[38].这些方法沿用了传统的领域自适应方法的数据设定,即在训练中可以使用有标记的源域数据(source domain)和无标记的目标域数据(target domain)来进行模型参数的学习.除了该设定之外,也有一些方法只使用无标记的数据.例如一些研究者使用无监督的方式训练并学习一个字典[39,40],也有一些研究者通过无监督的方式学习一些具有判别性的特征[41,42].
随着深度学习技术的广泛应用,近年来也出现了一些基于深度学习的无监督行人重识别方法.本文将这些方法划分为5 类:基于伪标记的方法、基于图像生成的方法、基于实例分类的方法、基于领域自适应的方法和一些其他方法.在大部分无监督深度行人重识别方法中,一般会使用有标记的源域样本和无标记的目标域样本进行训练模型,其中:基于伪标记的方法和基于实例分类的方法一般使用有标记的源域的数据进行模型预训练,然后使用无标记的目标域数据进行无监督学习;基于图像生成的方法一般通过将源域中的图像转化成目标域风格的图像,然后再使用这些图像来训练模型;基于领域自适应的方法旨在减少领域间数据分布的差异,通过特征的层级来对齐源域和目标域的数据分布,以将源域中的判别性信息迁移到无标记的目标域中.
2.1 基于伪标记的方法
伪标记方法在无监督学习中有着广泛的应用,其主要思想是为无标记的数据产生高质量的伪标记来训练和更新神经网络,如图4 所示.Yu 等人[43]提出了一种基于软的多标记学习的方法来解决无监督行人重识别问题,该方法通过借助有标记的辅助数据集来生成代理标签.具体地,通过在辅助数据集上为每一个类别产生一个代理(可以将其视为聚类中心),然后针对每个无标记的样本计算它们与这些代理的相似性并生成一个相似性向量(即软的多标记),进而判断两个无标记样本的相似性.例如:如果两个无标记数据生成的软的多标记相似,则它们大概率属于相同的行人.另外,根据无标记数据原始特征的相似性,该方法挖掘了难的负样本对(即属于不同的人但外表比较相似的样本对).该方法最终由以下3 种损失同时优化:(1) 软的多标记学习旨在将无标记数据中潜在相同的人尽可能拉近,难的负样本对尽可能推远;(2) 软标记分布的一致性学习旨在将不同视角下的软标记分布尽可能变成相同的分布;(3) 代理样本的学习旨在找出合适的代理,以对有标记的辅助数据集中的每一个类别(即每一个人)进行表示.
Yang 等人[44]提出了基于分块的判别性特征学习方法,该方法由以下两个模块构成:(1) 基于块的特征学习,该模块基于分块网络将得到的相似图像块拉近,不相似的图像块推远;(2) 图像层级的块的特征学习,该模块将原始图像通过随机图像转化的方法[45]对其风格进行一定程度的转化,然后得到对应的正样本对,而对于负样本的选择则采用循环排序的方法挖掘困难的负样本(即对于一个查询样本得到的排序结果,将这些结果中的图像依次作为查询图像重新得到一个排序列表,然后根据列表中图像的重叠度来判断该查询图像和排序列表中的图像是否属于一个人),最后,基于生成的正负样本对进行块的三元组损失的计算和优化.Wang 等人[46]在有标记的源域上引入属性语义信息和身份判别信息分别训练两个不同的分支网络,并使用一个自编码网络将身份信息从身份分支迁移到属性分支.而对无标记的目标域数据,采用在有标记的源域上训练好的属性分支来生成属性的伪标记信息,再使用这些带有伪标记信息的目标域数据来更新网络.在测试阶段中,作者使用属性分支的特征作为最终的特征.Lv 等人[47]提出使用摄像头的时空信息来提升生成正确的正样本对的概率,然后基于这些融合时空信息的正负样本对进行模型的训练和更新.在框架中,作者提出了一种基于贝叶斯推断的融合模型,该模型能够有效地将时空信息融入到样本的相似性度量中.
近年来,许多工作也将传统的聚类方法引入到无监督的行人重识别任务中,用来产生伪标记的信息.
Fu 等人[48]利用DBSCAN 聚类算法[49],基于在源域上预训练的模型提取特征来对无标记的数据进行聚类,然后基于聚类的结果构造三元组,并使用三元组损失(triplet loss)[29]来进行训练.在每一轮训练之后,利用得到的神经网络再次提取特征并进行聚类,重新得到更新的标记信息进行训练.聚类和网络的训练是迭代的过程,这样能够不断地获得更优的标记信息和更鲁棒的特征表示.Zhang 等人[50]提出了一种自训练的渐进式增强框架,主要分为保守训练和提升训练两个步骤,并在训练过程中使用HDBSCAN 聚类方法[51]产生伪标记.保守训练过程中使用传统的三元组损失和基于排序的三元组损失联合训练网络,提升训练过程中,使用交叉熵损失进一步提升网络的泛化性能.在整个训练过程中,保守训练和提升训练也是基于迭代的方式来优化网络.Lin 等人[52]提出了一种自底向上的聚类策略来不断地融合相似的样本,该方法起初将每一个样本视为一个类,并将每一类的特征存储在一个空间中,在训练过程中不断地更新融合不同的类,并且更新每一个类的新的表示特征.作者还在文中提出了一种多样性的归一化方法,以避免每一类中的图像数量差别过大.
Tang 等人[53]利用神经网络的最后两层(在残差网络中,即全局平均池化层和全连接层)的输出分别作为特征,并通过DBSCAN[49]进行聚类,然后基于聚类的结果产生标记信息,在网络的最后两层上都采用三元组损失函数同时进行网络的训练,并且也使用交替学习的方式更新网络以及获得新的标记信息.Yang 等人[54]考虑到通过聚类产生伪标记的方法往往会带来许多噪声信息,因此提出了一种能够在聚类之后对样本进行过滤的方法.作者认为在学习过程中所有的样本都是重要的,因此该方法根据DBSCAN 聚类[49]将样本划分为正常样本(在聚类过程被划分到某个类别)和异常样本(在聚类过程中没有被划分到某个类别),而在一些其他基于聚类的方法中一般会忽略这些异常样本.同时,该方法使用主模型和协作模型两种模型来相互促进学习,其中,主模型利用正常样本和异常样本来训练,而协作模型只使用正常样本来训练.特别地,对于用来训练主模型的异常样本,需要通过协作模型来选择其中一些置信度高的伪标记样本进行训练;而对于用来训练协作模型的正样本,需要使用主模型对已分配标记的样本再次进行过滤,以确保选择的样本都是纯净的,即保证这些样本的伪标记具有较好的可靠性.整个学习过程通过迭代的方式,不断地提升两种网络的性能.Ding 等人[55]提出一种基于分散度的聚类方法来对无标记的样本进行聚类,该聚类方法不仅仅考虑了类别间的差异性信息,而且也考虑到了类别內的紧凑程度.相比于其他的聚类方法,该方法能够更广地考虑到多个样本间的关系,并且能够有效处理不平衡的数据分布所带来的问题.
目前,在无监督行人重识别领域中,为无标记样本数据生成伪标记的方法已经成为主流的技术路线.该类方法具有思路简单清晰、性能良好的优点,特别是一些基于聚类的伪标记生成方法,可以展现出与有监督学习方法相接近的性能.然而,该类方法在伪标记生成的准确度以及如何有效利用生成的伪标记等方面仍然存在进一步提升的空间.
2.2 基于图像生成的方法
近些年,生成对抗网络已经取得了很大的进展.在无监督行人重识别领域,一些研究者基于该技术从图像层级角度来解决领域迁移的问题,如图5 所示.Huang 等人[56]考虑到不同领域图像背景的差异较大,且现有的图像分割方法并不能很好地将行人图像的前景和背景分开,因此提出了SBSGAN 通过产生软掩模的方法来移除图像的背景区域,该方法能够有效地抑制图像分割方法带来的错误.考虑到当前许多基于GAN 的方法只能产生单一风格的图像,Chen 等人[57]提出了一种对偶条件图像生成器以生成不同风格的行人图像数据,该方法能够将一张图像迁移到多个风格下.Liu 等人[58]认为领域间的差异信息由多种因素造成,如光照、分辨率、摄像头视角等,因此作者采用分而治之的方法将风格迁移网络分成多个子网络,分别针对不同的领域差异因素进行迁移,如光照迁移网络、分辨率迁移网络和视角迁移网络等.每个子网络首先进行预训练,最终通过一个选择网络来产生每个子网络的权重信息,并融合所有子网络中的信息生成最终的风格迁移图像.
Zhong 等人[59]利用StarGAN[60]对目标域中不同摄像头风格下的图像进行转化,训练过程中的正样本对来自于同一个摄像头风格下,结合原始目标域图像、源域图像和这些转化的图像一起生成三元组来训练更新神经网络.特别地,对于三元组,如果一个anchor 样本可以容易地在有标记的源域中得到它对应的正样本,同样也能从目标域中得到它的负样本,这样的三元组能够减小源域和目标域之间的差异.Bak 等人[61]认为,剧烈变化的光照条件是跨领域行人重识别问题的一个巨大挑战,然而对于当前单一数据集来说,光照情况相对比较单一.因此作者提出了一个合成的行人重识别数据集(synthetic person Re-Identification,简称SyRI),其包含在140 种不同的光照条件下的100 个虚拟的行人.该方法首先训练一个140 类的光照推断模型,用来推断一个目标域与哪种光照情况下的源域数据接近,然后利用CycleGAN[62]将该源域的数据转化成目标域风格的图像,再用来训练特征提取网络.Deng 等人[63]在CycleGAN 的基础上引入两个重要的跨域行人重识别特性来保证图像风格迁移的质量:其一,每张风格迁移后的图像应该与转换前的图像保持身份信息的一致性;其二,任何图像从源域迁移到目标域后都应与目标域中所有图像的身份信息不同.为了在原始的CycleGAN 上引入这两个特性,作者利用对比损失[64]的子网络来约束原始的CycleGAN 的训练.Wei 等人[65]提出了PTGAN(person transfer GAN)来对图像进行从源域到目标域的迁移,该方法在CycleGAN[62]的基础上引入行人前景分割图像来保证行人区域迁移前后的一致性.
这类方法的思想是:从图像层面进行风格迁移,其很大程度上依赖于生成对抗网络所生成图像的质量.与其他场景的不同点在于:从监控摄像头获取的行人图像往往质量较低并且存在一些噪声,导致风格转换后图像的质量并不高.因此,该类方法在无监督场景下的性能提升并不是很理想,需要进一步研究更加适合于行人场景的生成对抗网络来解决该类问题.
2.3 基于实例分类的方法
在传统的图像分类问题中,无监督学习已经取得很大的研究进展.受非参数化实例分类的方法[66]的启发,近期也有一些研究者将其引入到无监督行人重识别任务中来.非参数化实例分类的方法考虑到在分类任务中,外表相似的类别与外表相似性较小的类别相比有一个更大的预测概率值,这说明这些相似的类别在特征学习网络中存在潜在的相关性,因此该方法将所有独立的样本当作一个单独的类别来训练网络.假设我们有年n张图像x1,x2,…,xn,它们的特征分别为v1,v2,…,vn,对于一个图像x,其对应的特征为v,属于第i个样本(类别)的概率为
其中,每个样本的特征vj被存储在内存银行(memory bank)M中.特别地,M在每一个epoch 之后会被更新.τ是一个超参数,用来调节特征向量在单位球体上的集中程度[67].基于公式(1),对于样本x,其对应的特征为v,我们得到基于实例的损失函数为
其中,rj∈{0,1}n表示图像x对应的指示值.即:如果x和xj被判定为邻近的样本则为1,否则为0.
该类方法旨在关注如何得到更好的邻近关系r来学习模型,如图6 所示.Zhong 等人[68]沿用了非参数化实例分类的框架,并且对于每一个独立的样本(即每一个类),通过对抗生成网络StarGAN[60]生成一些其他摄像头风格的图像来增加每一个类的样本数量,即类似于一种数据增广的方式,并且在训练过程中考虑拉近一些邻近样本间的距离来强化类别之间的关联.对于邻近样本的选择,Zhong 等人[69]进一步提出了一种基于图的预测方式来判别两个样本是否是真实的邻近样本,该方法主要考虑了所有样本间的关系进一步确保选择的真正同类样本的正确性.Ding 等人[70]通过设置一个距离阈值来选择每一个实例的邻近样本,并且考虑到每个实例的邻近样本的不均衡性会导致偏向于学习某些样本,在损失函数中融入了一种平衡机制来抑制该问题.
基于实例分类的方法虽然在性能方面展现出了优越性,然而其对于样本之间的关联问题仍然需要进一步研究,即考虑如何采用有效的算法更加精确地进行样本关联度匹配.
2.4 基于领域自适应的方法
在深度学习的无监督行人重识别方法中,许多研究工作沿用了传统的领域自适应的架构,即考虑消除或减少领域间的差异来将判别性的信息从源域迁移到目标域中,如图7 所示.
Lin 等人[71]提出了一种多任务中间层的特征对齐方法(multi-task mid-level feature alignment,简称MMFA)来解决无监督跨域行人重识别问题,该方法联合身份学习和属性学习一起来训练更新网络,对无标记的目标域采用基于源域训练的模型生成的伪属性标记来进行模型的训练,并通过MMD(maximum mean discrepancy)[72]的方法减少源域和目标域之间的差异.考虑到跨域行人重识别问题中数据分布的差异不仅仅存在于领域之间,也存在于同一领域下的不同摄像头之间(不同摄像头下光照、分辨率、背景和视角等方面也存在差异),Delorme等人[73]和Qi 等人[74]都针对性地提出了基于摄像头的对抗网络来解决在跨域行人重识别任务中的数据分布差异问题.其中,Delorme 等人[73]在源域和目标域中所有的摄像头之间做等价的对抗,并且对无标记的目标域中的数据采用标记平滑的方式[32]分配到源域的类别中进行训练.Qi 等人[74]提出了源域和目标域中摄像头交互式的对抗,并在理论上证明了该对抗方式能够将源域和目标域所有的摄像头下的数据映射到同一空间中;另外,还利用时序信息从无标记的目标域中挖掘一些判别性的信息来训练更新网络.同时,作者在文中也提到:对于在行人重识别任务中使用的这种传统领域自适应框架,挖掘无标记的判别性信息是非常重要的,这是因为单一地减少数据分布差异可能会破坏目标域中的原始样本间的关系.因此引入目标域中的一些信息,能够一定程度地保证这种信息不会被破坏.
由于从数据分布的视角来解决无监督行人重识别问题是一种间接的处理方法,因此该类方法与基于伪标记的方法和基于实例分类的方法相比,在性能方面稍有些不足.但是与基于图像生成的方法相比,该类方法的性能更好.因此,这说明了在行人重识别问题中,从特征层级的迁移效果要比从图像层级的迁移效果更好.
2.5 其他方法
除上述的几大类方法之外,还有少量从其他角度设计的方法.Wu 等人[75]观察到摄像头內样本的相似性分布和摄像头间样本的相似性分布不一致,提出了摄像头一致性的学习方式,以使得摄像头內的数据分布和摄像头间的样本相似性分布趋于一致,并且在学习过程中保持摄像头內样本间的相似性分布与其在预训练上的模型一致.也有少部分的研究者关注在基于领域泛化的行人重识别任务上,在该任务的训练过程中,只存在有标记的源域样本,对于目标域没有任何可用的数据.Kumar 等人[76]探索了只简单地结合多个源域来训练一个模型的方式,在目标域上也具有良好的泛化性能.Jia 等人[77]考虑到领域间的差异性主要是由不同领域间的风格信息的差异引起的,受风格迁移学习的启发,作者提出在神经网络的低层使用实例归一化来减少不同领域的风格的影响;同时,在高层使用特征归一化进一步地减少领域间风格信息的影响.Song 等人[78]提出领域不变性的映射网络来解决行人重识别任务在未见领域上的泛化问题,该方法专注于在一张行人图像和身份分类器的权重之间学习一种映射.具体地,对于每一个来自于候选集合中的图像,可以生成一个分类器的权重向量.为了获得领域间的不变性,作者使用了元学习(meta-learning)中的插曲训练机制(episodic training)来更新网络的参数.在测试过程中,对于一张来自查询集合的图像和一张来自候选集合的图像,利用查询分支中提取的特征向量和候选分支中提取的权重向量进行点乘的值作为这两张图像的相似性.
3 半监督场景下的行人重识别问题
近年来,一些研究者也开始关注如何利用较少的标记信息来训练一个较优的模型.特别地,不同于无监督学习的定义,半监督学习在行人重识别中的有许多不同的设定.对于现有的方法,本文将其划分成如下几个场景.
(1) 少量的人有标记
Liu 等人[79]提出利用半监督的对偶字典学习来解决少标记的行人重识别问题,该方法利用少量的标记数据来学习在不同摄像头之间的特征关系,而大量的未标记数据用来获得鲁棒的稀疏表示.Wu 等人[80]假定了只有少量的行人标记样本的情况,通过在其他有标记的数据集上训练好的多个不同模型来迁移信息,这些模型可以被视为多个教师模型.该方法使用教师学生网络训练机制来进行网络的训练,通过使用大量的无标记数据训练更新学生网络,并通过少量有标记样本来判断每个在源域上训练的模型的权重(即对于不同的样本,不同教师模型贡献程度不同).Xin 等人[81]使用少量的有标记数据训练模型,然后通过多视角聚类方法对无标记的数据进行聚类,再联合有标记数据和带有伪标记的无标记数据更新网络,并继续基于新的网络再次执行聚类算法,整个过程是迭代交替的.
(2) 每一个人有少量标记
Wu 等人[82]提出了一种渐进式的学习方法来解决该问题:首先,根据每个人的少量标记数据训练初始模型;然后对大量无标记数据中置信度较高的数据分配伪标记,其余置信度较低的数据暂不分配标记信息.在训练过程中,结合有标记和伪标记的数据一起使用传统的交叉熵损失更新训练网络.对于暂未分配标记的数据,接下来采用实例分类的方法,将每一个独立的样本当作一个类别并在网络中进行训练,然后基于训练好的网络再次重新分配伪标记.该方法的学习过程也是采用迭代更新的方式.然而该场景存在一定的局限性,其很难拓展到实际应用中.这是因为在该设定下,通常很难获得整个数据集上所有行人的数量,除非对整个数据集进行标记,这将耗费大量的人工成本,与半监督设定的初衷相悖.因此,采用该设定的研究工作较少.
(3) 基于tracklet 的学习
Li 等人[83]把行人重识别任务划分为摄像头內的学习和摄像头间的学习.对于摄像头內的学习,作者假设摄像头內经过跟踪算法已得到若干tracklet,并提出了一种基于时序的稀疏采样方法以获得摄像头內不重复的tracklet(即这些tracklet 尽可能属于不同的人),然后使用交叉熵损失来学习这些有标记的样本.对于摄像头间的学习,作者提出一种损失函数以使得相近的跨摄像头的tracklet 尽可能相似.在此基础上,Li 等人[84]进一步对摄像头內的学习做出改进,不再需要选择一些不重复的tracklet,即可以使用全部的tracket,同时提出了一种软分类学习的方式来自动探索摄像头內tracklet 的关系.在这两个研究工作的实验过程中,作者给定了图像数据集中摄像头內的标记信息.Wu 等人[75]沿用了文献[83]中tracklet 的选择方式,该方法主要提出了基于图的关联方式来建立跨摄像头tracklet 之间的关联.特别地,基于视频的方法致力于使用给定的tracklet 来探索时序信息,以便于将其融入到特征表示中.然而,上述半监督方法主要是使用tracklet 信息作为部分的标记信息来执行学习任务.
(4) 摄像头內有标记,摄像头间无标记
受基于无监督的tracklet 的学习的启发,Qi 等人[85]定义了一种新的半监督行人重识别设定,并且分别从数据分布的角度和伪标记学习的角度提出了两种不同的解决方案[85,86].在该设定下,每一个摄像头內均给定标记信息,而摄像头间是没有标记信息的.由于在行人重识别问题中,标记摄像头间的信息需要花费大量的成本,而摄像头內的标记信息可以借助于跟踪算法和少量的人工标记即可完成,因此这种半监督行人重识别的设定在实际应用中有较大的意义.在文献[85]中,作者考虑到不同摄像头间数据分布的差异性(由背景、光照、视角等因素带来的影响),提出了一种基于摄像头对齐的对抗学习网络,以将不同摄像头的数据映射到同一空间中.在文献[86]中,作者通过在跨摄像头间生成渐进式的软标记来探索跨摄像头间样本之间的关系.同时,Zhu 等人[87]提出了类似的问题,即:对某一个摄像头中的数据,分别在其他每个摄像头下找到最相似的人.然而这样的方式存在一个问题,即:当一个人在某个摄像头中没有出现的时候,该方法会强制性选择一个错误的样本进行关联.
4 数据集和评价标准
为了评估行人重识别的相关算法,我们往往需要在一些公开数据集上进行实验,并通过统一的评价标准来评估所提出方法的性能.本节,我们对行人重识别的相关数据集和评价标准进行了总结.
4.1 数据集
近年来,行人重识别问题在科研中的关注逐渐得到提高,因此也出现了越来越多的更大规模的数据集.这些数据集主要分为两类,即基于图像的数据集和基于视频的数据集.我们将选取部分常用的数据集分别进行介绍.
(1) 图像数据集
常用的图像数据集主要包括Market1501[88],DukeMTMC-reID[32],MSMT17[65]和CUHK03[89],这些数据集既可以用于无监督任务,也可以用于半监督任务.其基本信息概括在表1 中.

Table 1 Information of some image-based person re-identification datasets表1 部分行人重识别图像数据集信息
Market-1501[88]是在大学校园内一个超市前面采集的,由6 个摄像头拍摄得到.该数据集包含1 501 个行人的32 668 张图像(标注框),且每个行人都至少在两个摄像头中出现.训练集包括751 个行人的12 936 张图像,查询集包括750 个行人的3 368 张图像,测试集包括750 个行人的16 384 张图像.该数据集采用DPM 检测器[90]来检测行人标注框,而非采用人工裁剪的方式来获得,这样更加贴近现实应用,即可以考虑到行人检测的标注框会存在偏移与不对齐的情况.DukeMTMC-reID[32]是基于多摄像头多目标行人跟踪数据集DukeMTMC[91]构建而成的,由8 个摄像头拍摄得到.该数据集包含1 404 个行人的36 411 张图像(标注框),且该1 404 个行人中,每个行人都至少在两个摄像头中出现.训练集包含702 个行人的16 522 张图像,查询集包括702 个行人的2 228 张图像,测试集包括702 个行人的17 661 张图像.该数据集通过人工剪裁的方式来获得行人标注框.MSMT17[65]是从校园中部署的15 个摄像头中拍摄得到的,包含4 101 个行人的126 441 张图像.训练集包含1 041 个行人的32 621 张图像(其中包括验证集的2 373 张图像),查询集包含3 060 个行人的11 659 张图像,测试集包含3 060个行人的82 161 张图像.该数据集采用Faster RCNN 检测器[92]来检测行人标注框.CUHK03[89]由5 组摄像头拍摄得到,每组摄像头包含两个摄像头,且采用人工裁剪(labeled)和DPM 检测器(detected)[90]两种方式来检测行人标注框.该数据集存在两种测试协议,本文仅介绍新的一种协议,以下称为 CUHK03-NP[93].在 CUHK03-NP(labeled)中,训练集包含767 个行人的7 368 张图像,查询集包含700 个行人的1 400 张图像,测试集包含700 个行人的5 328 张图像;在CUHK03-NP(detected)中,训练集包含767 个行人的7 365 张图像,查询集包含700 个行人的1 400 张图像,测试集包含700 个行人的5 332 张图像.图8 展示了部分数据集的实例图像,其中左图来自Market-1501[88],右图来自DukeMTMC-reID[32],上下两行分别代表不同摄像头下的行人图像.
(2) 视频数据集
常用的视频数据集除了较早出现的PRID2011[94]和iLIDS-VID[95]以外,主要包括MARS[96],DukeMTMC-SITracklet[84]和DukeMTMC-VideoReID[97],这些数据集常用于半监督任务.其基本信息概括在表2 中.

Table 2 Information of some video-based person re-identification datasets表2 部分行人重识别视频数据集信息
MARS[96]是在大学校园中的6 个摄像头采集得到的,包含1 261 个行人的20 478 个tracklet 共计1 191 003张图片,分别将626 和635 个行人作为训练集和测试集,其所有的轨迹片段都是由DPM 检测器[90]和GMMCP跟踪器[98]自动生成的.DukeMTMC-SI-Tracklet[84]和DukeMTMC-VideoReID[97]均来自来自DukeMTMC[91],由8个摄像头进行拍摄,人工裁剪得到标注框.DukeMTMC-SI-Tracklet 由1 788 个行人的19 135 个tracklet 共计833 984 张图片组成,并分别将702 个和1 086 个行人作为训练集和测试集;DukeMTMC-VideoReID 由1 812 个行人的4 832 个tracklet 共计815 420 张图片组成,并分别将702 个、702 个和408 个行人作为训练集、测试集和干扰项.图9 展示了部分数据集的实例图像,均来自MARS[96],其中上下两行分别代表不同的tracklet.
4.2 评价标准
对于行人重识别算法的性能,通常使用累积匹配特性(cumulative match characteristic,简称CMC)曲线和平均精度均值(mean average precision,简称mAP)来进行评估.
CMC 曲线能够综合反映分类器的性能,可以表示匹配目标出现在大小为k的候选列表中的概率.直观上,CMC 曲线可以通过Rank-k准确率的形式给出,即目标的正确匹配出现在匹配列表前k位的概率.在行人重识别问题中,通常关注k={1,5,10,20}时的性能,即匹配目标的k={1,5,10,20}准确率.例如Rank-1 准确率表示正确匹配出现在匹配列表第1 位的概率,即查找1 次即可返回正确匹配的概率.通常,最后的Rank-k准确率是指对所有检索目标进行查询后取结果的平均值.
然而,当测试集中存在多个正确匹配时,Rank-k准确率不能完整地对算法进行评估.Zheng 等人[88]考虑到行人重识别的目标应将所有的正确匹配都检索出来,即在考虑查准率的同时,应当同时考虑查全率,因此建议采用mAP 来将算法的检索召回能力考虑进去.具体地,mAP 的计算过程需遍历所有检索目标,对于每个检索目标分别计算AP(average precision)并取平均,而AP 的计算过程即为求PR(precision-recall)曲线下的面积的过程,即考虑了目标在某些阈值下的查准率和查全率.因此在后续工作中,通常将mAP 与Rank-k准确率结合在一起作为行人重识别问题的评价指标,这样能够达到对算法性能进行全面评价的目标.
5 现有方法的性能及分析
本节将对现有弱监督场景下行人重识别算法的实验结果进行总结,并给出了分析和比较.
5.1 无监督方法
对于现有的无监督方法,我们总结了当前基于深度学习的方法在3 个大规模数据集上的实验结果,即Market1501[88],DukeMTMC-reID[32]和MSMT17[65].其中包括基于伪标记的方法,如TJ-AIDL[46],TFusion-uns[47],DC[55],HCR[99],BUC[52],PAUL[44],MAR[43],PCB-R-PAST[50],SSG[48],ISSDA[53]和ACT[54];基于图像生成的方法,如HHL[59],SyRI[61],PTGAN[65],SPGAN[63],ATNet[58],DA-2S[56]和CR-GAN[57];基于实例分类的方法,如ECN[68],AE[70]和LAIM[69];基于领域自适应的方法,如MMFA[71],CAT[73]和UCDA[74].实验结果总结在表3~表5 中.
表3 展示了现有无监督的方法在Market-1501 数据集上的结果,其中,*表示没有使用有标记的源域数据进行模型的预训练(即直接使用ImageNet 预训练的模型),†表示使用除DukeMTMC-reID,MSMT17 和CUHK03 之外的行人重识别数据集进行模型的预训练,-表示没有对应的实验结果,DukeMTMC-reID/MSMT17/CUHK03 表示分别使用这3 个数据集作为源域的实验结果.
表4 展示了现有无监督的方法在DukeMTMC-reID 数据集上的结果,其中,*表示没有使用有标记的源域数据进行模型的预训练(即直接使用ImageNet 预训练的模型),-表示没有对应的实验结果,Market-1501/MSMT17/CUHK03 表示分别使用这3 个数据集作为源域的实验结果.
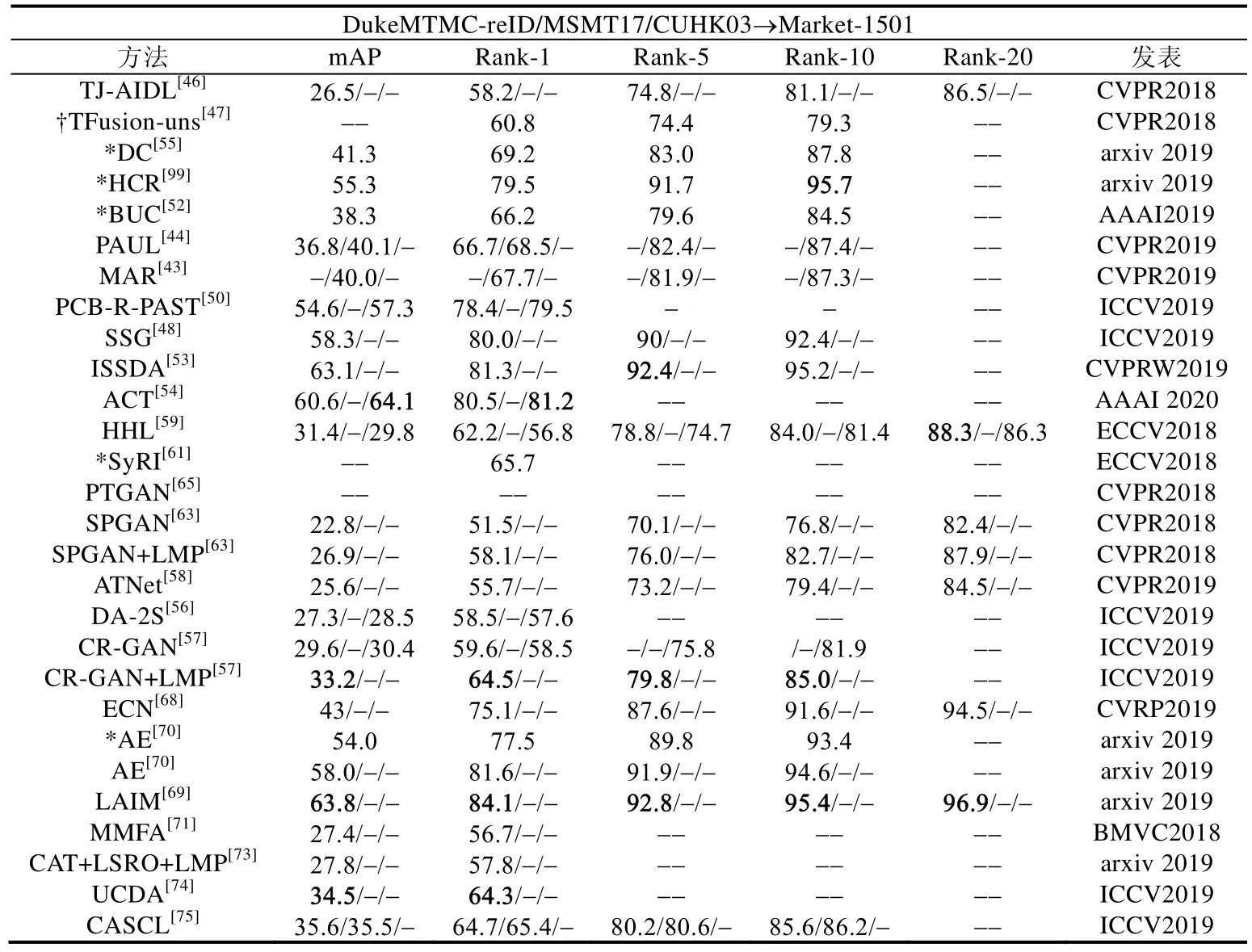
Table 3 Results of existing unsupervised methods on Market-1501表3 现有无监督的方法在Market-1501 数据集上的结果
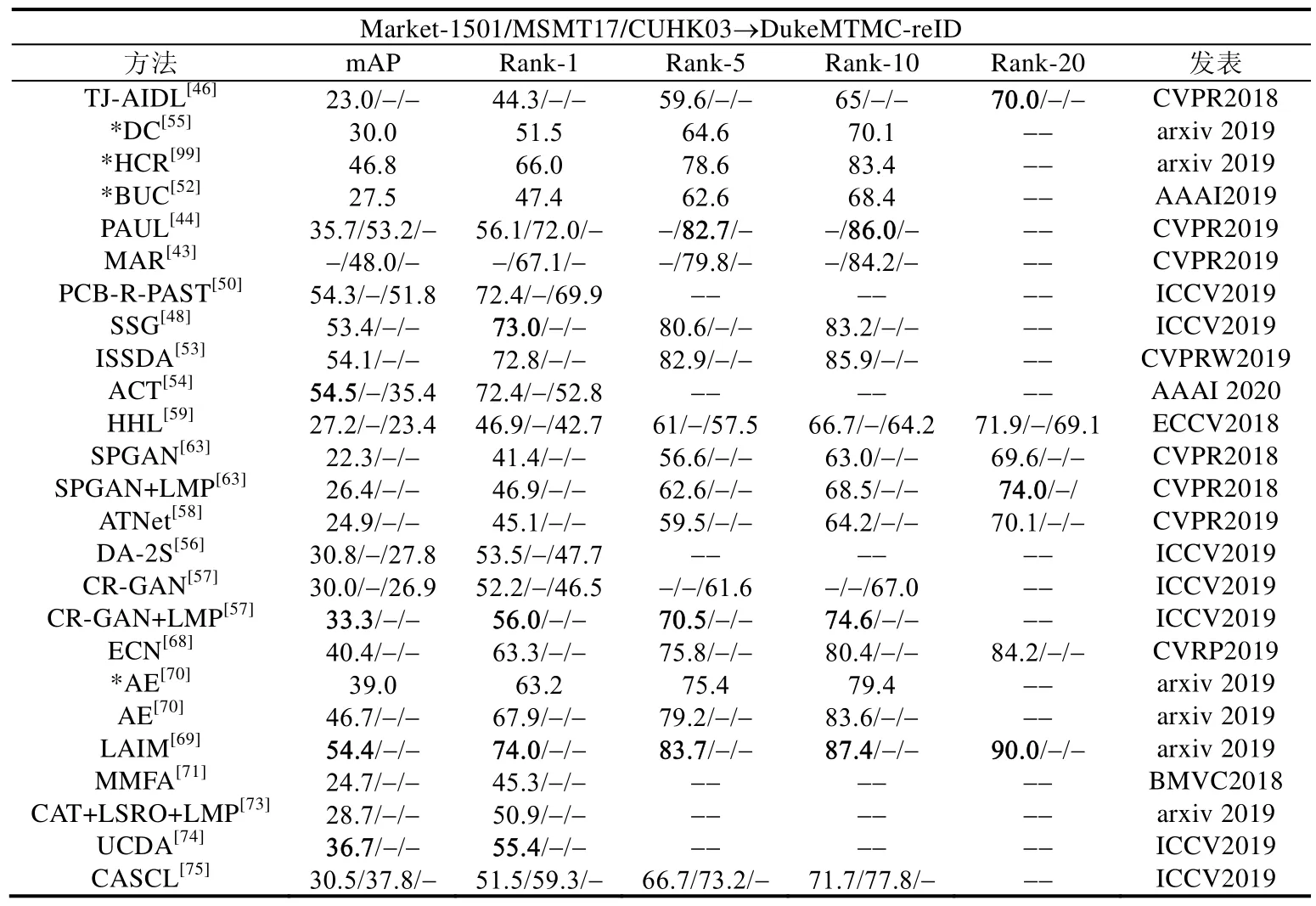
Table 4 Results of existing unsupervised methods on DukeMTMC-reID表4 现有无监督的方法在DukeMTMC-reID 数据集上的结果
表5 展示了现有无监督的方法在MSMT17 数据集上的结果,其中,*表示没有使用有标记的源域数据进行模型的预训练(即直接使用ImageNet 预训练的模型),-表示没有对应的实验结果,Market-1501/DukeMTMC-reID/CUHK03 表示分别使用这3 个数据集作为源域的实验结果.
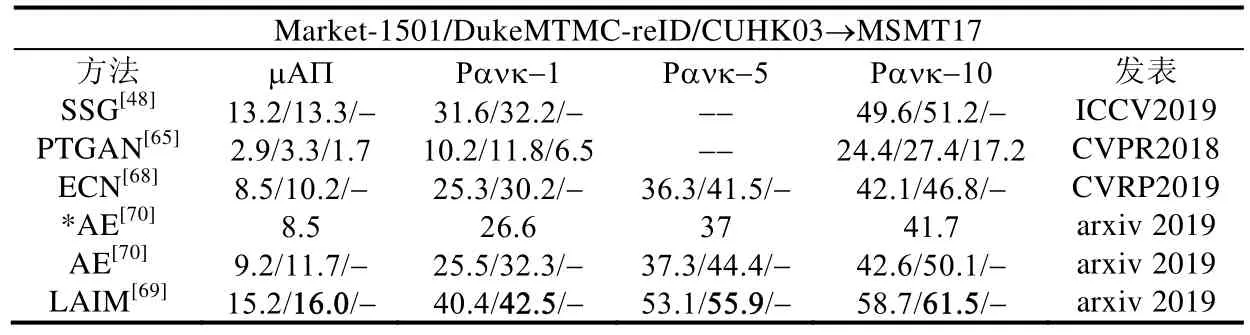
Table 5 Results of existing unsupervised methods on MSMT17表5 现有无监督的方法在MSMT17 数据集上的结果
对于基于伪标记的方法,TJ-AIDL[46]是通过结合属性学习并对目标域中的数据生成伪属性的方法来进行学习的;TFusion-uns[47]利用时序信息产生更可靠的伪标记信息;PAUL[44]和MAR[43]以有标记的源域数据为基准,生成无标记目标域的伪标记信息;DC[55],HCR[99],BUC[52],PCB-R-PAST[50],SSG[48],ISSDA[53]和ACT[54]都是基于聚类的算法,其中,ACT 对聚类后的结果进行了进一步处理,以便于找出确定性的伪标记信息和非确定性的伪标记信息,因此相对于其他方法,该方法能够得到相对更好的结果.另外,从表3 和表4 中可以发现,基于聚类的伪标记方法相对于其他伪标记的方法有更好的性能.
对于基于图像生成的方法,当前CR-GAN[57]的性能最优.不同于其他从领域层级或摄像头层级的风格迁移,如PTGAN[65],SPGAN[63]和ATNet[58]等,CR-GAN 是基于图像层级的风格转化,即根据一张特定图像的风格对一张目标的图像进行图像风格的迁移.因此,该方法相对于其他方法有更好的性能.此外,在所有这些基于图像生成的方法中,HHL[59]只使用了图像生成网络对目标域内的不同摄像头间的图像进行转化,以产生不同摄像头风格的正样本对.
对于基于实例分类的方法,当前方法基本都是关注在如何建立样本间的关系上,其中,LAIM[69]引入了图的关系来增强找出相同实例的可靠性,因此,该方法目前在此类型的方法中具有较好的表现.
对于基于领域自适应的方法,MMFA[71]使用传统的MMD 方法来减少领域间差异.在行人重识别问题中,数据分布的差异不仅存在于领域间,也存在于相同领域的不同摄像头间,而CAT[73]和UCDA[74]都考虑到了这一方面,提出了基于摄像头感知的领域对抗学习.对比于CAT,UCDA 提出了一种跨领域等视角的对抗学习方法来减少所有摄像头视角层级的数据分布的差异,并且利用了时序信息在无标记的目标域中挖掘判别性信息,以保证在减少数据分布差异的过程中目标域数据内部结构的不变性.因此在该类方法中,UCDA 目前具有最好的性能.
对比这几大类方法,基于图像生成的方法和基于领域自适应的方法相较于基于伪标记的方法和基于实例分类的方法表现性能相对较弱.主要原因可能是基于图像生成或领域自适应的方法可以看作是从数据分布的层级来解决无标记的学习问题,其中,基于图像生成的方法旨在缩小源域和目标域图像分布间的差异,而基于领域自适应的方法是从特征表示的层级来缩小领域间的差异.这些方法属于隐式地解决无标记的问题,而基于伪标记或实例分类的方法是显式地通过对无标记的数据直接产生伪标记或者是建立这些样本间的关联来进行学习.因此,基于伪标记和实例分类的方法相比较于其他方法能够更加直接地解决无标记行人重识别问题.
5.2 半监督方法
在本节,我们总结了当前基于深度学习的半监督行人重识别算法在3 个大规模图像数据集Market1501[88],DukeMTMC-reID[32]和 MSMT17[65]以及 3 个大规模视频数据集 MARS[96],DukeMTMC-VideoReID[84]和DukeMTMC-SI-Tracklet[97]上的实验结果.特别地,当前在行人重识别问题半监督的定义有很多种,本节总结的方法包括:(1) 少部分人有标记的场景,如Distilled-ReID[80]和MVC[81];(2) 每一个人有少量标记的场景,如One-Example[82];(3) 基于tracklet 的场景,例如TAUDL[83],UTAL[84],TSSL[100],TASTR[101]和UGA[75];(4) 摄像头內有标记但摄像头间无标记的场景,如ACAN[85],MTML[87]和PCSL[86].所有方法的实验结果总结在表6 和表7 中.表6展示了现有的半监督方法在图像数据集Market1501,DukeMTMC-ReID 和MSMT17 上的结果,其中,-表示没有对应的实验结果;表7 展示了现有的半监督方法在视频数据集MARS,DukeMTMC-VideoReID 和DukeMTMCSI-Tracklet 上的结果,其中,-表示没有对应的实验结果.特别地,与大部分无监督方法会涉及到源域和目标域的数据集不同的是,半监督的方法中只有目标域的数据集.
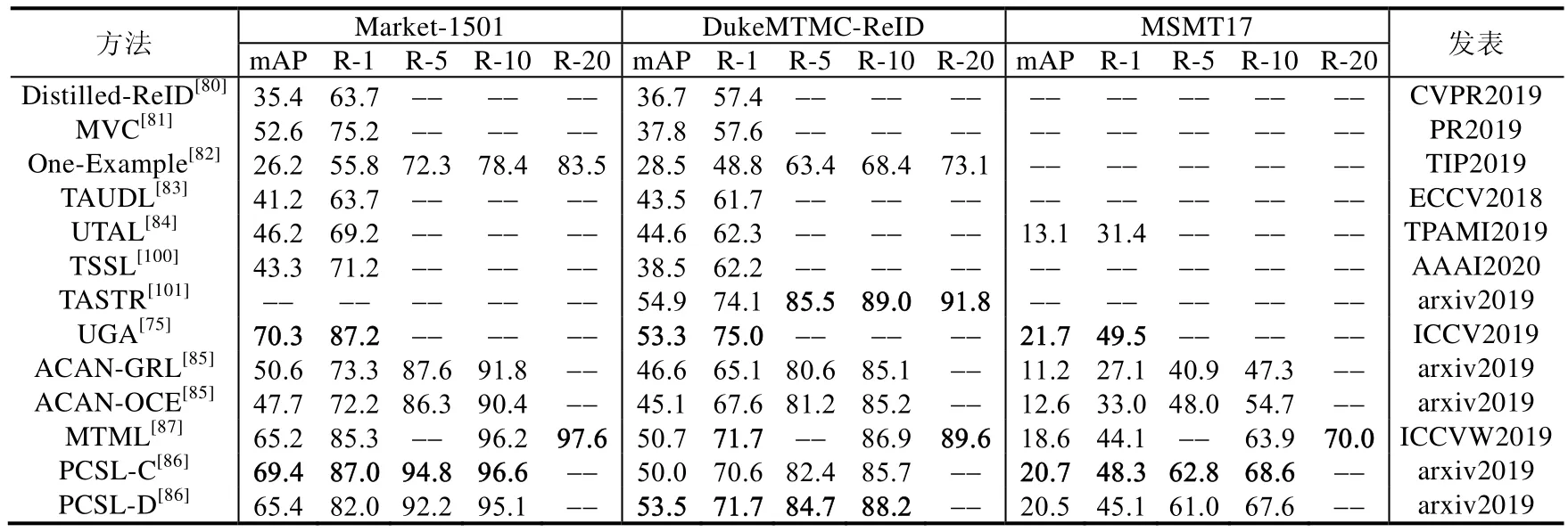
Table 6 Results of existing semi-supervised methods on image-based datasets表6 现有的半监督方法在图像数据集上的结果

Table 7 Results of existing semi-supervised methods on video-based datasets表7 现有的半监督方法在视频数据集上的结果
对于少量的人有标记的场景,MVC[81]和Distilled-ReID[80]的设定并不相同,因此它们并不具有可比较性.对于每一个人有少量标记的场景,在现实应用中,该方法并不是可行的.这是因为如果需要知道整个数据集行人的数量,就必须要对整个数据集进行标注,即这种设定不具有现实应用价值,因此针对该类场景的研究方法较少.对于基于tracklet 的场景,本文中我们将其归类为半监督的方法,因为tracklet 中的每个图像默认为同一个标记.特别地,一些方法在基于图像的行人重识别数据集中,假定每个摄像头內的人的所有图像在一个traklet 內,即对于这些数据集已经给定了摄像头內的标记信息.这类方法在近年来得到了较多的关注,一些研究工作主要关注在如何在摄像头內获得不重复的tracklet 上,例如使用时序信息来缓解该问题;除此之外,如何建立跨摄像头间的联系也是该类方法需重点解决的问题.由于这类方法采用了基于tracklet 的标记信息,因此该类方法相对于无监督的行人重识别别方法,整体来看具有更好的性能.进一步,Qi 等人[85]基于tracklet 的场景定义了一种新的半监督场景的学习方式,即摄像头內有标记而摄像头间无标记的场景.相对于基于tracklet 学习方法,该方法在基于视频的图像数据集上具有更好的性能.主要原因在于:基于tracklet 的方法通过采样的方法,并未完全使用摄像头的数据;而基于摄像头內给定标记的场景能够有效地利用所有的数据,并且摄像头內的标记并不需要大量的人工成本.因此,该类方法在现实中具有重要的研究意义.另外,ACAN[85]基于数据分布的视角来解决跨摄像头间无标记的问题,而MTML[87]和PCSL[86]直接采用关联的方法来建立跨摄像头样本间的关联性.从实验结果来看,直接建立样本间的关联性,相较于从数据分布的视角解决跨摄像头间无标记的问题,具有更好的性能.
6 总结
本文主要总结了弱监督场景下的行人重识别算法,包括无监督场景和半监督场景,并且对近年的方法进行了分类和描述.对于无监督的行人重识别算法,我们根据其技术类型划分为5 类,分别为基于伪标记的方法、基于图像生成的方法、基于实例分类的方法、基于领域自适应的方法和其他类型的方法.对于半监督的行人重识别方法,根据其场景类型划分为4 类,分别为少量的人有标记的场景、每一个人有少量标记的场景、基于tracklet学习的场景和摄像头內有标记但摄像头间无标记的场景.最后,我们对当前行人重识别的相关数据集进行总结,并对现有的弱监督方法的实验结果进行总结与分析.
研究弱监督场景下的行人重识别问题,能够帮助行人重识别技术更好地拓展到现实应用中.而基于弱监督场景下的行人重识别算法,其着重研究利用无标记或少量标记的数据来学习具有更好泛化性能的模型.对该领域的探索不仅具有理论价值,还有很高的应用价值.该领域虽然在近年来得到了一定的关注,但目前仍然不能完全达到有监督场景下的性能.该领域仍然有一些研究问题亟待解决.
(1) 实例间的关系评估
基于实例分类的无监督方法在近年来得到了广泛的关注,但其主要的挑战集中在如何有效地挖掘每个样本之间的实际关系,即:以一对样本而言,观察它们是否属于相同的类别.如果所有样本之间的关系能够被很好地评估,那么这一类方法的性能将等价于有监督场景下的行人重识别任务的性能.
(2) 领域泛化问题
虽然弱监督场景下的行人重识别算法相比于传统的有监督场景更能够有利于应用到现实当中,然而这些方法仍然需要收集无标记的样本来学习.在将来,通用性的行人重识别算法也许是该领域能够真正落地的一大发展趋势,即:只通过在现有的数据进行训练,就能够很好地泛化到其他未见场景中.这也是实现通用人工智能技术的必要的一条路.我们首先需要解决单一任务上的通用型,才能进一步去探索在不同任务上的通用性.这一类问题结合风格迁移和元学习的相关方法或许将在未来的研究中展现出很大的前景.
猜你喜欢
计算机技术与发展(2024年3期)2024-03-25 02:10:02
中国交通信息化(2022年9期)2022-10-28 06:14:40
汽车工程师(2021年12期)2022-01-18 06:02:43
意林(2021年5期)2021-04-18 12:21:17
计算机技术与发展(2020年11期)2020-12-04 07:50:46
扬子江(2019年1期)2019-03-08 02:52:34
小天使·一年级语数英综合(2017年6期)2017-06-07 23:51:16
电子与信息学报(2015年12期)2015-08-17 11:14:42
汽车维修与保养(2015年8期)2015-04-17 03:32:59
上海理工大学学报(2012年2期)2012-03-20 13:54:30
