
基于移动端的神经网络汉英翻译模型
2020-11-03 11:36:52成洁
计算机测量与控制 2020年10期
成 洁
(陕西国际商贸学院 基础课部, 西安 712046)
0 引言
深度学习在自然语言处理的各个领域都得到了成功的应用,基于强化学习的神经网络机器翻译的研究也得到了迅速的发展[1-4]。近年来,基于神经网络的机器翻译与统计机器翻译相比已经取得了很大的成就,因此研究者不断地、逐步地改变方法,以利用神经网络来改进机器翻译[5-8]。尽管机器翻译有很多方法和技术,但也存在一个问题。不同的机器翻译方法或技术不能完整、准确地描述同一源语句子的翻译信息,而源语句子中的表达必然会产生错误[9-12]。复述可以纠正和补充机器翻译结果,以尽可能地弥补上述问题的错误,从而可以用源语言更全面地描述翻译结果。针对以上问题,系统融合也提出了解决方案。对于不同的系统,系统融合将不同机器翻译方法的输出结果融合在一起,以生成输出结果,由于其改进,该结果优于原始机器翻译。
本文运用目前的主要机器翻译方法来建立释义模型,以完成提高汉英机器翻译的任务。然后,它使用系统融合技术融合翻译,以进一步提高翻译质量。然后,在翻译和释义的基础上,利用网络和移动设备设计和开发汉英翻译模型,并在神经机器翻译和释义汉英移动翻译系统的基础上初步完成了开发工作。
1 神经机器翻译方法
1.1 基于递归神经网络的翻译模型
递归神经网络(RNN)是神经网络机器翻译中最为广泛的结构,而其它方法在编码时只改变RNN的内部隐藏结构或固定向量计算[13-15]。与一般的前馈神经网络FNN不同,RNN在其基础上引入了循环机制[16-18]。这样,RNN可以处理前后不相关的输入,但它不像以前的神经网络那样需要一次性完成输入特性。
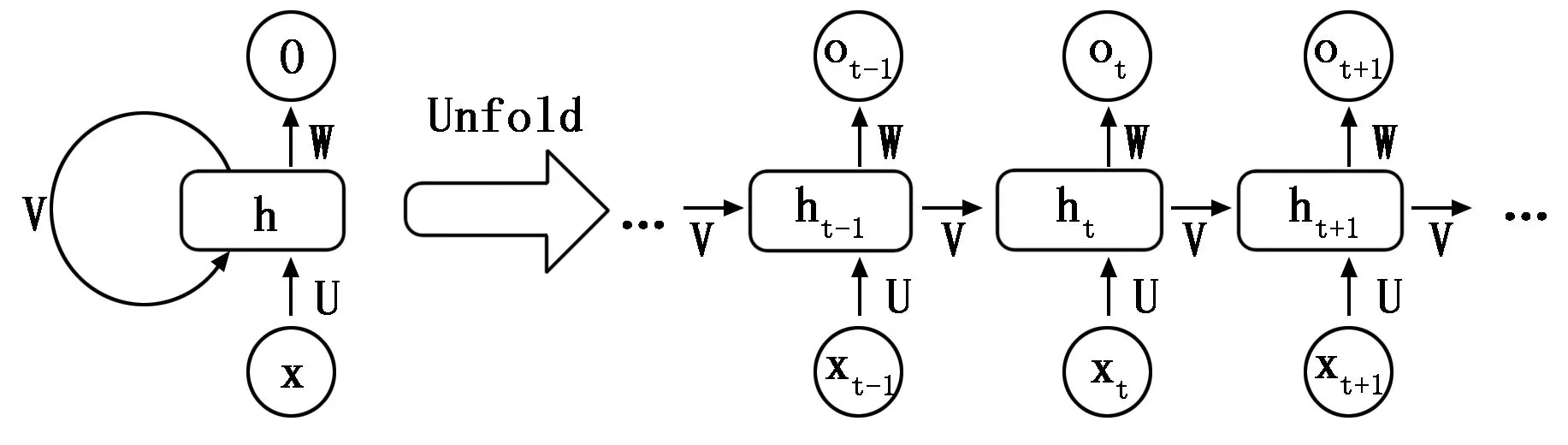
图1 RNN模型架构
图1描述了RNN的展开架构。x和o分别表示输入和输出;h表示隐藏层;t表示时间;U表示参数从输入层到隐藏层;V表示参数从隐藏层到输出层;W表示隐藏层之间的递归参数。对于某一时刻的t,其输出应考虑当前输入xt和由某一状态St-1发送的值。
对于xt。它是在整个网络的时间t处输入的字向量。对于st,它是时间t的状态,也是网络的存储单元。它包含时间t之前的所有状态,计算如下:
st=f(Uxt+Wst-1)
(1)
在公式(1)中,f是非线性激活函数。
对于ot它是在时间t时的输出,通过公式(2)可以得到计算结果。
ot=softmax(Vst
(2)
1.2 编解码模型
图2 基于编码解码器的神经机器翻译系统
基于神经网络的机器翻译系统的典型模型是编码-解码。其基本思想是:将给定的源语言句子映射成连续的密集向量。解码是指它根据这个向量转换成目标语言句子。一个编码-解码:基于结构的神经机器翻译系统(NMT)如图2所示。编码和解码通常使用RNN实现。由于普通RNN具有梯度消失和梯度爆炸的特性[19-21],因此通常采用长短期记忆网络(LSTM)。
1.2.1 LSTM的原理
长短期记忆网络(LSTM)是递归神经网络种的一种特殊网络,这种网络可以对长期依赖关系进行学习和获取。Hochreiter等人提出了该网络,并在接下来的数十年里,许多学者对该网络模型进行了完善和改进。LSTM及相关变种网络的被设计出来的目的是为了避免长期依赖及相关的问题。对于LSTM来说,记住长期信息是其本身的自发默认行为,是不需要通过大量学习就能够实现的。
所有普通的循环神经网络种,都有重复模块,这些模块以链式存在。在标准的RNN中,重复模块非常简单,例如只有一个 tanh层,如图3所示。
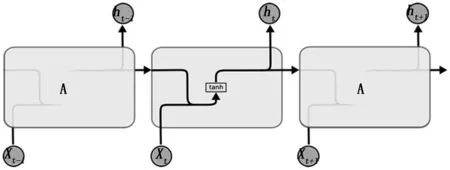
图3 标准RNN的重复模块包含一个单层网络
基于以上背景可知,在LSTM及相关变种网络中,同样存在这样的链状结构,但是与普通RNN中的区别在于,LSTM中的重复模块的结构是不一样的,具体如图4所示。在LSTM中,原来的单层网络被一个四层网络所代替,并且他们之间的交互方式也十分特别。

图4 LSTM网络的重复模块包含一个四层的交互网络
cell状态是LSTM及相关变种网络的关键,图5表示了一个横穿整个cell顶端的水平线。
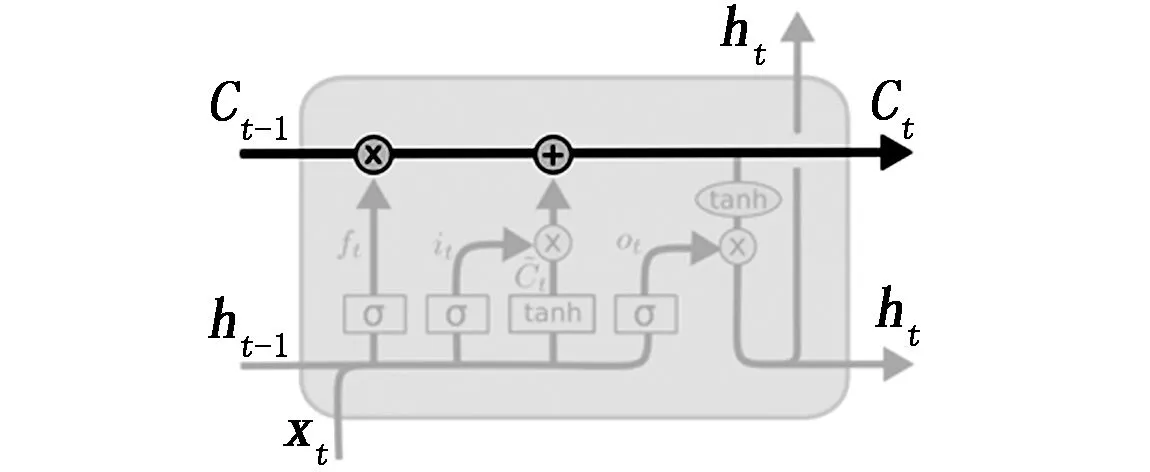
图5 水平线横穿cell示意图
在长短期记忆网络中中,cell状态类似于传送带。为了保证承载的信息在传送过程中保持不变,以及方便传输,cell状态是直接穿过链,并且只在少数地方进行一些较小的线性交互。
在LSTM中,为了能够改变cell状态,如对信息的添加或删除,所以引入一种叫做“门”的结构来对其进行操作。在这里,一个sigmoid神经网络层和一个位乘操作组成了门,如图6所示。门在LSTM中的作用是控制信息,有选择的让信息通过。

图6 门结构示意图
sigmoid层输出数值是0或者1,这两个值代表对应的信息是否允许通过。当数值为0时,当前不允许信息通过,而当数值为1时,则表示当前所有信息都能够通过。一个LSTM中门有3个,从而实现对cell状态的保护和控制。下面将具体介绍这3个门。
第一个门:首先在LSTM中需要决定哪些信息要从cell状态中被抛弃。这个选择是由一个被称为“遗忘门”的sigmoid层控制。这个门的输入是ht-1和xt,输出为0或者1。1代表保留这个信息,0代表这个信息需要被抛弃。
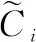
第三个门:接着,在LSTM中,是需要对最终输出做出决定。当前的cell状态会影响输出结果,但是为了使结果更加准确,将会对结果进行过滤。首先,建立一个输出门,这个门是基于sigmoid神经网络层,这个门的作用是用来决定哪一部分的cell状态是可以输出。然后,将cell状态通过tanh函数后,乘以输出门。最终就输出了只允许被输出的部分。
1.3 基于神经网络的释义模型
1) 扩展语料库信息。释义技术弥补了训练集、开发集和测试集中句子信息的缺陷。
2) 改变句子表达。复述技术对机器翻译的输入句子进行复述,使翻译系统能够更好地理解或复述输出的翻译文本,使翻译句子更符合目的语的语言习惯。
通过不同的释义语料库和不同的神经网络建立不同的释义模型,并通过第二种方法对机器翻译结果进行复述,以提高机器翻译的结果质量。释义模型的生成需要几个步骤来完成:
1)得到神经网络翻译模型;
2)得到释义语料库;
3)训练并得到释义模型。
2 基于释义的机器翻译融合模型
2.1 RNN编解码器的改进分析
在改进方法的基础上,引入了译码器中的对齐模型,使该模型能够同时学习对齐和平移。与传统的RNN编解码器最大的区别是改进后的模型不将整个输入序列变换成固定长度的中间矢量表达式,而是通过应用双边递归神经网络将输入序列变换成具有相同输入长度的隐单元表达式。在此基础上,解码器可以在解码过程中选择一个或多个隐藏表达式进行对齐和翻译。该模型在处理长句子时具有较好的处理能力。
2.1.1 编码器:双向RNN表达式输入序列
科学家们推测,在38亿年前,火星的大气层比现在要更浓密,温度也比现在更高,能够允许大量的液态水存在于火星表面,甚至还形成了海洋。在火星表面,能够找到不少可能由水的流动而形成的地貌特征。然而,在现今的火星上,除了零星出现的液态水特征外,很难见到像南北极冰盖这样大规模的液态水分布。
对于给定的输入序列x=(x1,…,xT),传统的递归神经网络模型将根据该序列从第一个序列到最后一个序列的顺序依次输入该模型,最终将整个序列转化为一个中间向量表达式。为了使每个字的隐藏层都能在这个序列中携带其前、后信息,该模型采用双向RNN模型来代替传统的RNN模型。

这样,隐藏的分层状态表达式就包含了整个输入序列的信息。RNN模型的隐层表达趋向于更大程度上的表达和该词附近的信息。因此,隐藏的分层向量hj对于每个词的信息主要集中在该词附近的上下文信息上,每个词都可以以给定词的上下文信息为中心来表达。在此基础上,解码器引入对齐模型,对输出序列进行更合理、更准确的解码
2.1.2 解码器:训练对齐模型
在该模型中,重新定义了以下方程:
p(yi|y1,y2,...,yi-1,x)=g(yi-1,si,c)
(3)
其中:si是时间i时的隐藏层状态,并且隐藏层状态的计算可以通过式(4)得到:
si=f(si-1,yi-1,ci)
(4)
其中:ci可以由输入序列的隐藏状态向量表示。这种隐层状态向量的实现依赖于上下文中双向递归神经网络模型表达式的输入序列。这种隐层矢量计算是通过对每个输入序列的隐层状态进行矢量加权和来实现的。
(5)
每个向量hj的权重aij可以通过式(6)计算得到:
(6)
其中:eij是一个对准模型,用于估计对准概率,具体可以通过式(7)计算得出:
eij=a(si-1,hj
(7)
基于隐层状态向量si-1和jth双向递归神经网络,获得了这种对准概率。
2.2 对准模型
通过上下文中可以看出,在Tx×Ty的每一个时间段中,双语句子都将与输入模型保持一致。在模型训练和解码过程中,需要进行大量的运算。因此,为了降低计算复杂度,所以将使用感知器来完成这样的功能。具体如式(8)所示:
(8)

2.3 释义生成
在复述任务中,把复述语言的输入和输出作为不同的语义表达。与翻译任务不同,释义任务的输入和输出属于同一种语言。基于这一思想,所以利用该模型对同一语言的复述系统进行训练,并以机器翻译结果为输入,生成句子规模的复述结果,使每个句子语义一致。由于在同一语言中很难获得大规模的平行释义语料库,因此采用机器翻译文本和参考翻译文本的平行语料库来近似释义语料库。在系统融合任务中,更多希望得到的是机器翻译结果的复述句,因此与机器翻译文本和参考文本相比,并行复述语料库在一定程度上具有更大的优势。同时,在一定程度上提高了机器翻译质量的效果。
当得到释义语料库时,释义模型的生成相对简单。释义模型的生成过程与翻译模型的训练过程相似。在已有RNN网络和CNN网络的基础上,利用释义语料库分别训练模型,从机器翻译文本和参考翻译文本中获得释义模型。模型实现后,将机器翻译结果输入到“复述系统”中进行翻译,从而为输入的句子生成理想的句子级复述结果。
3 基于移动系统的模型应用与测试
3.1 系统设计与翻译过程
本文的软件设计框架采用MVC(model view controller)软件构建模式[22]。MVC三层架构通过业务逻辑、数据和界面显示的分离,促进系统组织代码,减少耦合,提高可重用性。系统生命周期成本低,可维护性高。内容提供者主要用于管理共享数据,实现不同应用程序之间的数据共享。

图7 系统工作流程
通过内容提供者提供的完整性机制,可以实现一个程序对另一个程序的数据访问。如果内容提供商允许,它甚至可以更正数据。目前,Android提供的标准跨程序数据共享正在使用内容提供商。移动翻译软件系统的整体流程图如图7所示,在该系统中,移动终端视图层用来告诉用户输入和收集源语言语句。控制器用于将句子传输到服务器。
当系统接收到需要翻译的源句后,系统将该句子输入到模型中,通过控制器,将源句传输到远端服务器,然后服务器通过利用前文所提的基于递归神经网络的翻译模型对句子进行翻译,然后根据基于释义的机器翻译融合模型对释义进行优化,增加译后句子的可读性。然后远端服务器将处理后的句子再次通过控制器传输回移动端,最后在移动端展示出结果。
3.2 系统展示
该软件的主要功能是将英语翻译成汉语。当软件打开时,图8中的初始界面将显示在手机上。可以看到在打开软件后,有一个友好的界面建议。

图8 软件初始界面
输入要翻译的句子时,单击相应的按钮翻译该单词或句子。点击翻译后,输入的英文将被传送到服务器进行翻译。翻译和释义后,翻译结果将显示在图9的界面中,供用户检查。

图9 翻译结果示意图
3.3 性能评估
为了更好地评估所提出的翻译模型的性能,本实验基于NIST进行英文翻译任务,使用的语料测试集为NIST05,NIST06,NIST08。开发集才用的是NIST02[8]。
接下来通过BLEU算法评价性能[23-24]。BLEU算法的计算公式为:
(9)
表1列出了在基线系统中的方法和转换的结果。

表1 翻译结果的对比
表1给列出了相应的实验结果,ALL表示将所有的测试集放在一起,从表中结果可以发现,对于NIST08测试集,基线系统的BLEU值为30.07,是所有结果中最低的。相应的,提出的模型,在NIST08测试集上的BLEU值有所提高,为31.02,但同样为所有测试集中的最低的,但结果提高了1.02。在3个测试集中,NIST05的结果最好,分别为35.98和37.33。从表中可知,使用释义纠正短语概率的方法在一定程度上得到了改进。对于所有的测试集结果,基线系统的BLEU值为35.12,提出的模型的BLEU值为36.83,提高了1.71BLEU。结果表明,修正后的短语翻译概率在一定程度上解决了训练语料数据的稀疏性,修正后的短语翻译概率更加准确合理。然而,通过短语向量提取的短语复述过程中存在一定的噪声,因此机器翻译中的振幅改善并不大,不需要进一步改进。
4 结束语
本文提出了一种面向移动终端的释义机翻译系统融合。该方法利用RNN编解码模型生成语义一致性的句子级释义。我们把释义作为同一种语言之间的翻译任务。在没有大规模并行释义语料库的情况下,利用机器翻译结果和源语言的参考翻译文本来逼近并行释义语料库。利用该模型可以训练一个从机器翻译结果到参考翻译文本的释义系统,并生成语义连贯的句子级释义结果。然后,将释义结果引入系统融合的翻译假设候选集。从实验结果来看,该方法的改进比基于词尺度的短语尺度释义的系统融合结果要大,因此我们的机器翻译系统融合具有更大的潜力。
猜你喜欢
天津外国语大学学报(2020年1期)2020-03-25 13:29:26
电子制作(2019年19期)2019-11-23 08:42:00
小学生作文(低年级适用)(2019年5期)2019-07-26 00:45:10
读友·少年文学(清雅版)(2018年12期)2018-04-04 05:16:40
作文评点报·低幼版(2017年13期)2017-04-18 18:15:11
家庭百事通(2016年3期)2016-03-14 08:07:17
重型机械(2016年1期)2016-03-01 03:42:04
山东青年(2016年3期)2016-02-28 14:25:52
大连工业大学学报(2015年4期)2015-12-11 04:06:52
语言与翻译(2015年4期)2015-07-18 11:07:45
