
基于数据挖掘的雷达探测目标误差测量技术
2020-11-03 11:36:06张彤
计算机测量与控制 2020年10期
张 彤
(成都理工大学 工程技术学院,四川 乐山 614000)
0 引言
随着雷达技术的不断发展与进步,不同领域都将该技术进行了很好的应用,如军事领域、农业畜牧等领域,他们通过该技术得到了具有丰富信息且非常清晰的图像[1]。雷达图像中存在着许许多多的目标,其中不乏一些复杂的,识别这些复杂的图像是非常困难的,雷达技术最基础的功能和应用就是对所需目标进行识别,所以对如何利用雷达技术识别所需目标是一个备受瞩目的焦点[2]。目标的不同特性和变化多端的天气对雷达在进行探测时的效能有着非常大的影响,雷达所探测的信息中夹杂着许多杂波信息,很难得到具有一定影响价值的规律和模式,也就导致了“数据丰富,知识贫乏”的出现[3]。
雷达探测目标的误差测量技术不仅非常深奥复杂,而且是一种具有系统性的工作,主要是由“白箱”建模和“黑箱”建模两种基本的方法组成,所谓“白箱”就是通过理论分析推导,进而得出机理模型,也就是对之前已经经过验证的知识进行推导;“黑箱”是,通过测试雷达系统所输入/出的数据信息,并作出相应的判断的方法。当今主要是用传统的方法进行“黑箱”建模,即数理统计的方法进行仿真雷达探测,但是这种方式不能反映出真实的误差的特性,而是只能进行误差总体上的规律的反映,对整体测量技术的真实性有比较大的影响,因为该方法得到的系统误差和标准差只是通过分析历史上存有的误差数据资料和对通过对比模仿得到的,比对模型是高斯白噪声模型。数据挖掘是指对隐含且未知的数据进行提取的过程,所选数据是随机的、数量庞大的且不清晰的,但这些信息确认是潜在的且有用的,所以提出了建立于该方法之上的雷达探测目标误差测量技术。
1 基于数据挖掘的雷达探测目标图像识别
数据挖掘技术的激光雷达图像识别思想为:最开始要进行图像的去噪,在小波变换下进行去噪处理,接着提取图像的Zernike不变矩阵的特征进行,最后建立深度的网络层进行识别模型[4]。
1.1 目标图像的特征提取
图像切割:如果把具有极其复杂性的图像直接输入到分类器里面,分类器会随之变得非常复杂。所以,需要切割整个完整的图像,切割步骤为:1)确定图像的阀值,即从众多阀值中选择适合的数值;2)对图像做二值化处理和平滑处理[5]。从水平的方向开始扫描图像,计算从第一行起的图像中白色像素的数量,如果数量大于N(已设阀值)时,需要对此进行特殊的标记。若与它相邻的两行仍然出现这种情况,即白色像素的数量大于已设阀值,那么视为之前的标记为合理标记,否则的话,就要从头开始再次操作[6]。若出现合理的标记时,就要开始改为向下的扫描。接着计算以最后一行起的每行中白色像素的数量,如果数量大于N,就要将这一整行进行特殊标记。然后接着做向上的扫描,若相邻两行仍是白色像素的数量大于N,同上需要视之前的标注为合理的,且重新进行该操作[7]。若过程中有合理标记出现,就要停下水平方向的扫描。垂直方向同理,需在水平方向的扫描区进行[8]。
1.2 图像归一化
一般需要在分类器中输入图像之前对其进行归一化处理,包括位置、大小等的归一化处理。
1)位置归一化。主要是将目标移动到所规定的位置,以达到位置偏差的消除目的。有下面两种比较简单的归一化方法:(1)对目标的质心进行计算,随后将其移动到指定的位置,该方法被称为建立于质心之上的归一化方法;(2)对目标的外边框进行计算,然后寻找重心,再将其移动到指定位置,该方法称之为建立于目标外边框之上的位置归一化方法[9]。
2)大小归一化。进行变换大小不一的目标,使其大小相同,该变换过程为大小归一化。主要有下面两种方法:(1)为了使目标符合规定,需对目标外框进行放大或者缩小,缩放过程要按照比例进行;(2)根据目标在水平和垂直两个方向的分布进行大小归一化[10]。
1.3 图像识别
如何在向量机中进行目标图像特征的输入,并对其进行分类和预测,主要有下面3个步骤:
1)建模,也就是向量机模型的建立。模型中的核函数为径向基函数。该函数在模型选择时由以下两个参数决定:惩罚因子和核参数。分类器的性质和预测能力受到该参数的直接影响[11]。
2)学习,通过样本进行训练以对向量机提出支持。用于目标图像识别的支持向量机的学习过程如图1所示。

图1 支持向量机的学习过程
由图1可知,通过目标图像识别样本,对目标识别图像进行前期处理后,计算目标识别图像的特征矩,并对特征矩进行归一化处理,再输入到初始支持向量机中进行训练,得到训练后的支持向量机。
3)预测,在向量机中输入未经分类的图像特征,并对此做出分类和预测。
根据上述内容,设计具体识别流程如图2所示。
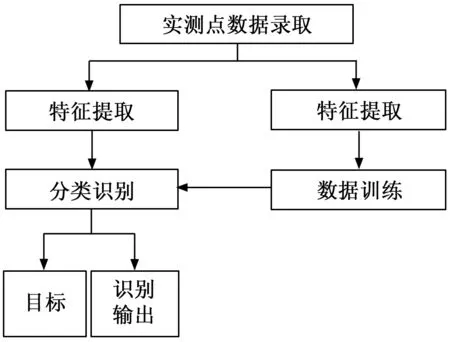
图2 雷达图像的识别流程
由图2可知,雷达图像的识别流程为录取实际测量点的数据,分别提取实际测量点的数据特征,再对实际测量点的数据进行训练后,分类识别目标图像样本,并输出目标图像识别结果。
2 数据预处理
在进行数据挖掘时,必不可少的一步为数据的预处理。因为被挖掘的原始数据有着冗杂多余且空洞无用的特点,在进行数据挖掘时要对其进行加工,处理其中的噪声,这就是所谓的数据预处理[12]。数据预处理流程如图3所示。

图3 数据预处理流程
预处理的主要流程为:
1)将所需处理的数据进行相应的转换、集成和匹配。要想实现数据挖掘,就要将目标雷达所得到的实际测量数据和真实航迹数据进行对比,并获得差值。但是上述两种数据在采集时的步长是不同的,并且被存放在不同的文件中,所以要对二者做航迹匹配处理,并且为了二者步长变得一样,还需要对数据进行三点插值处理。
2)将数据处理成一致的。目的是保证挖掘结果的精确度和干净整洁,且具备一致性的特点。
3)读取雷达数据文件,并将其装入数组之中,指针指向数组初始位置,数组是否为计算机保留的值?如果是,则结束程序;如果不是,则查看数据是否为模式数据?如果是,则需解码,并将结果存储到计算机指令之中,否则直接查看解码时间信息;将解码结果存储到模式数据库之中,查看解码时间信息,并将结果存储到时间表之中,解码方位信息,并将结果存储成AZ格式。不断重复上述步骤,直到获取所需数据。
3 雷达探测目标误差测量
雷达探测误差数据挖掘需要输入和预测属性,前者为真值距离和真值方位,后者为距离和方位误差,而误差模型的建立还要依靠决策树来完成,评估树的准确性还要依据保留测试法来实现。保留测试法对样本数据集进行划分,划分为训练和测试数据集,并且二者是互不相交的。
在SQL Server 2005中进行误差数据的挖掘,为了选择适合且可用的决策树算法,需要选择挖掘模型参数。决策树-即树形结构的流程图,属性的测试由内部节点表示,测试结果由分支表示,类别则由叶节点表示,根节点即树的最高层,如图4所示。

图4 决策树树形结构图
为了形成决策树,需要进行训练样本子集的选择,若该树不能给出任何对象正确答案,则要将没有得到正确答案的特殊情况添加到该树中,一直重复上述操作,直到正确决定集的出现为止。完成一个符合要求决策树,即每个叶子都可以代表一个类别,每一个节点都代表一个属性,每一个分支都代表一个属性所对应可能值。
进行熵计算方法下的拆分分数计算,和节点的拆分,拆分方法为二分法。通过以上操作,挖掘模型会分别生成距离和方位误差的决策树。通过对包含在叶节点中的最少的样本数的设定进行决策树的剪枝和修剪,并对其进行评估,评估需要根据测试数据集完成,确定了距离误差决策树在样本数最少时生成预测性能比较好。
基于数据挖掘的雷达探测目标误差测量技术实现流程如图5所示。
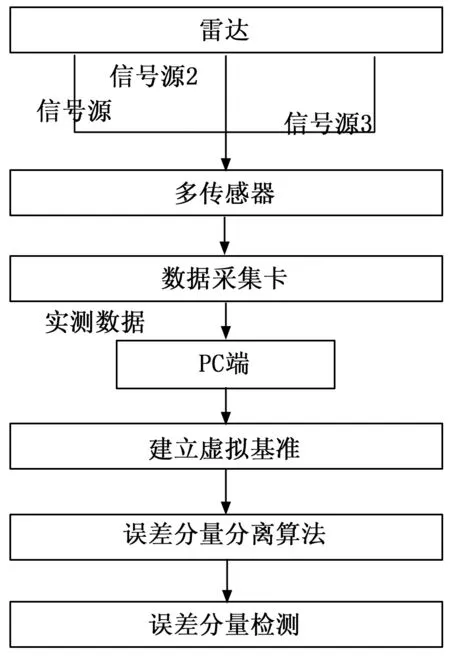
图5 雷达探测目标误差测量流程
由于雷达探测目标通常是通过相关指令实现目标探测的,相应获取的雷达运行轨迹误差图像真实反应了从雷达指令发布的完整信息。通过信号源为被探测目标提供所需要的信号,利用多传感器融合相关数据参数,再通过数据采集卡,将模拟信号转化为数字信号,传输到PC端,以此建立雷达探测目标误差测量的虚拟基准。利用数据挖掘方法分离出各个误差分量,并且分析出产生误差的根本原因。根据探测结果,还可以优化雷达探测位置,提高测量精准度。
4 雷达仿真结果验证
针对基于数据挖掘的雷达探测目标误差测量技术研究,进行仿真实验验证。
4.1 数据挖掘处理
雷达信号中存在的孤立点需通过挖掘分离处理,使用数据挖掘技术在后期处理时主要通过以下两种方法得以应用。
1)进行原始的雷达信号和已经被处理过且孤立点已经被删除的信号之间的比较,将其送到雷达终端,雷达终端会将目标点迹图显示出来,以达到有效性确定的目的。

图6 雷达目标点轨迹
从以上点迹图可以很明显地看出经过处理和未经处理的雷达信号的区别。两幅图由于是在不同的时间段采集的,会有略微的区别,但是前后两幅图因采集数据的时段不同略有差异,但是可以看出原始点击图中显示的航线附近非常多的干扰点在处理过的图中得到了明显的解决,可以断定该处理有效过滤且去除了价目表的信号。
2)进行提取孤立点信号,并将其送到终端显示器上,接着对其进行观察,确定其规律后,做出合理的处理。通过以上方法,提取了4种类型:
(1)出现在25 km的半径范围内,该范围是以雷达站为圆心计算的,除此之外, 25~50 km之间偶尔也会有假目标出现。真假目标距雷达站有着相同的距离;假目标数量比较多,一般在2~3个,情况很糟糕时甚至会出现4~5个之多,分布为扇形,并且会出现在真目标的顺/逆时针方向。
(2)出现在半径50~120 km之内,出现更加频繁的位置是65 km和100 km附近,而且30~50 km、120~180 km的范围之间也会有假目标的出现。真假目标距雷达站有着相同的距离;多数情况下是一个,恶劣时会出现两个。若假目标在真目标的逆时针方向出现,从雷达矩阵引两条夹角为40°的射线到真目标和假目标上面。反之,如果假目标在真目标的顺时针方向出现,则所需射线的夹角为30°。
(3)出现在270~280 km方位一般情况下是一个假目标,不好的情况会出现两个,二者之间离的非常近,且夹角也比较小。
(4)假目标很偶尔的会出现,且没有规律,不会长时间的出现。
4.2 雷达运动轨迹研究及结果分析
根据上述4种假设目标类型,对雷达运动轨迹展开分析,如图7所示。
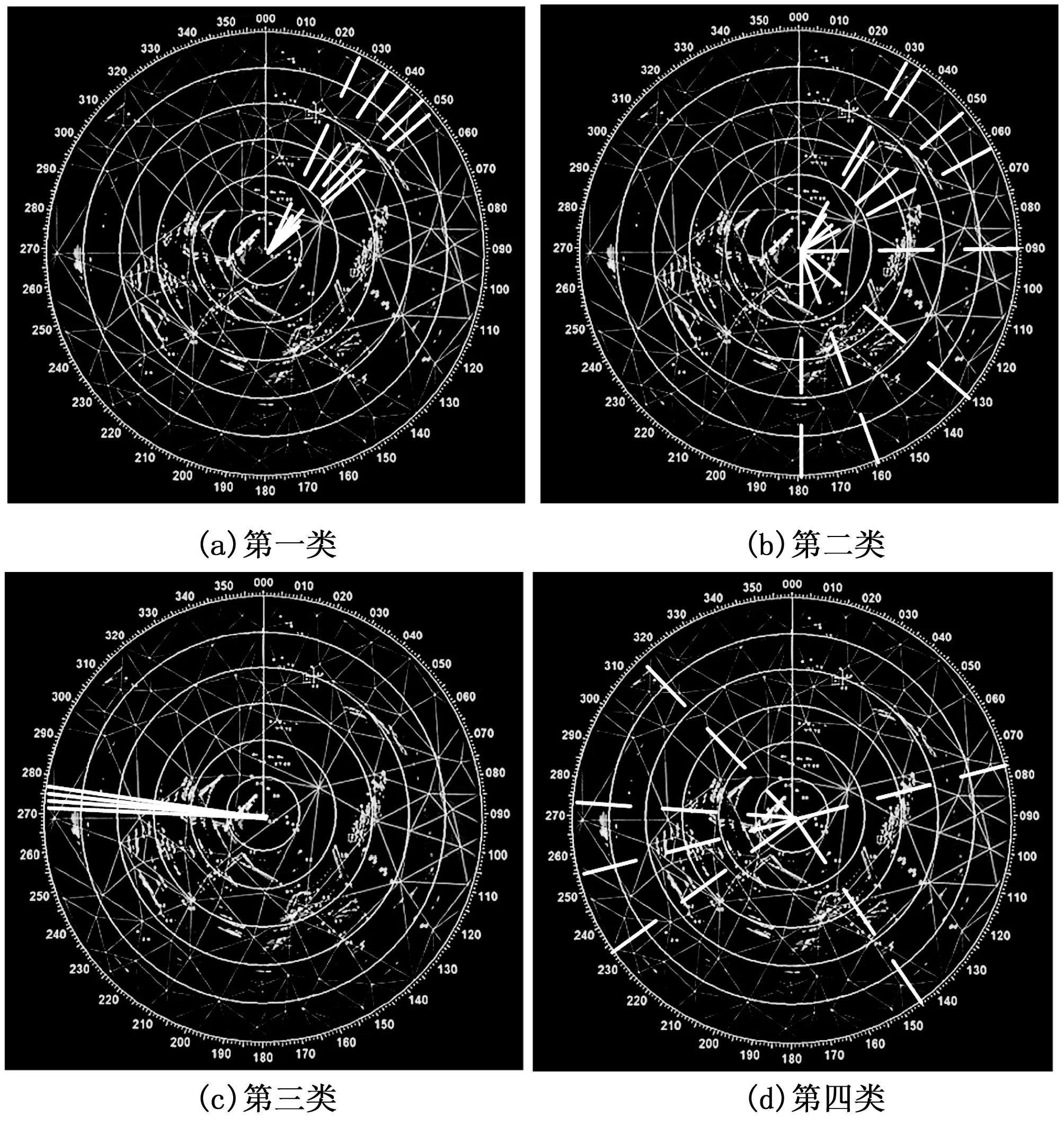
图7 4种假设目标类型雷达目标点轨迹
用图7所示的目标点轨迹,将传统方法与基于数据挖掘方法的雷达探测目标误差测量精准度进行对比分析,结果如表1~4所示。

表1 第一类假设情况下两种方法测量精准度对比结果

表2 第二类假设情况下两种方法测量精准度对比结果

表3 第三类假设情况下两种方法测量精准度对比结果

表4 第4类假设情况下两种方法测量精准度对比结果
由上述表内容可知,采用传统方法雷达探测目标误差测量精准度与实际值相差较大,最大误差为16.8 km;而基于数据挖掘方法雷达探测目标误差测量精准度与实际值相差较小,最大误差为2.0 km。
5 结束语
建立于数据挖掘之上的雷达探测方法可以有效地分析和测量目标误差,提出了在这方面研究的新路径。在以后的研究中,为了能够得到更加具有真实性的雷达探测误差的结果,会对与误差探测有关的机制、环境等影响因素进行研究。
有几个问题在做研究的时候发现依然需要想出解决办法,主要问题是:1)在进行孤立点分析算法时发现维度越高,时间的复杂度也会随之增高;2)如何在如今手工选择不同时段数据以得到所需参数的方法之上,建立更加便捷动态高效的参数选择方法;3)如何提高信息挖掘的真实可靠性和准确率。当数据比较密集时,经常会出现真实的目标信号被误认为假的信号的情况。接下来为了建立更加真实有效的挖掘模型,将会进行雷达数据挖掘方法的更进一步的研究与探讨。
猜你喜欢
现代雷达(2023年11期)2024-01-05 15:01:52
传感器世界(2023年5期)2023-08-03 10:38:18
大众投资指南(2021年35期)2021-02-16 01:06:26
当代陕西(2020年24期)2020-02-01 07:06:56
成都信息工程大学学报(2018年5期)2018-12-06 09:23:52
测控技术(2018年3期)2018-11-25 09:45:52
自然资源情报(2017年4期)2017-11-26 07:51:28
电力与能源(2017年6期)2017-05-14 06:19:37
北京航空航天大学学报(2017年12期)2017-04-23 08:31:51
信息通信技术(2015年6期)2015-12-26 01:16:46
