
结合状态转移规则的深度睡眠分期模型
2020-11-02 11:52马家睿王行愚
计算机工程与设计 2020年10期
马家睿,王 蓓,金 晶,王行愚
(华东理工大学 化工过程先进控制和优化技术教育部重点实验室,上海 200237)
0 引 言
近些年,深度学习方法在自然语言处理、图像识别、语音识别等领域获得了巨大的成功,为睡眠自动判读带来了新的思路[1-4]。睡眠自动判读主要包含特征提取和分类识别两大步骤[5]。在特征提取阶段,深度学习方法能够从原始信号中自动提取特征,避免了手工设计特征的局限性。例如,Bonnet等构建了一个多层卷积神经网络[6],Yuita等结合了深度信念网络和长短时记忆模型对睡眠状态进行划分[7],Supratak等设计了基于卷积神经网络和长短时记忆模型的深度睡眠网络[8]。上述研究均取得了较好的效果,但仍存在不足之处。一方面,随着神经网络深度的增加,特征表达的能力也会增加[9,10],然而当网络深度达到一定程度时,会导致梯度爆炸或弥散问题。另一方面,自动判读的结果往往存在与实际睡眠状态转换不相符的情况,且较难通过调整模型本身的结构来改善。因此,如何考虑睡眠状态的变换规律[11,12],贴近人工判读的经验方式,得到与实际相符的睡眠状态变化结果仍有待研究。
针对上述不足,提出了一种结合状态转移规则的深度睡眠分期模型。首先,在卷积神经网络中添加多个残差块来加深网络层数,提取信号高维特征,再进行分类;其次,考虑睡眠状态之间的转移规律,基于Dijkstra算法转化为最短路径,设计了转移规则和平滑规则,对预测结果中不合理的状态转移情况进行修正;最后,对模型进行评估,与人工判读方式进行了分析和比较,同时也与相关的一些方法进行了对比。
1 模型结构
本文提出的结合状态转移规则的深度睡眠分期模型结构如图1所示。
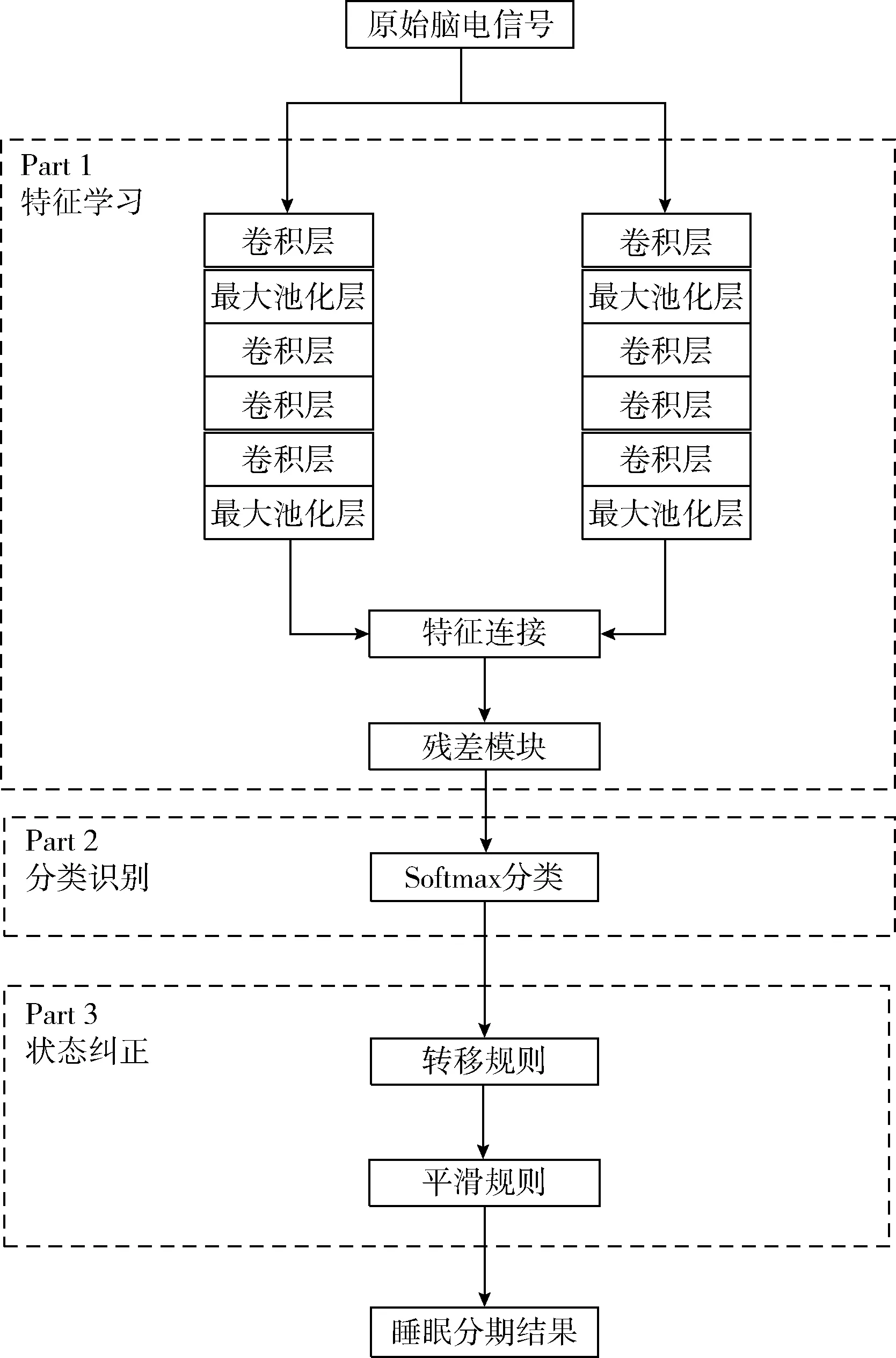
图1 结合状态转移规则的深度睡眠分期模型
图1主要包含Part 1、Part 2和Part 3这3个模块。Part 1是特征学习模块,通过卷积神经网络和多个残差块构成深度神经网络模型,自动提取高维特征;Part 2是分类识别模块,采用Softmax对睡眠状态进行分类。Part 3是状态纠正模块,在深度神经网络预测结果基础上,通过转移规则和平滑规则进行修正处理。其中,Part 1和Part 3两个模块的处理过程将在1.1和1.2节中进行详细介绍。
1.1 特征学习
特征学习部分是一个含有20层的卷积网络,由卷积模块和残差模块两部分组成。每个卷积模块由4个卷积层和两个最大池化层组成。卷积模块采用了两个不同大小的卷积核分别提取时域和频域特征,并依次执行卷积和线性单元(ReLU)激活两个操作。池化层用来降低特征维度。对于卷积神经网络,如果只是简单地增加深度,会导致梯度弥散或爆炸的问题发生,虽然数据的正则化[13]可以解决梯度问题,但这会导致网络的性能降低。因此,为了避免梯度问题的发生,并增强神经网络特征表达能力,在卷积网络之后添加了残差块。假设x输入通道数为128,W1,W2分别表示残差块第一层和第二层的权重,F(x)表示第二个激活函数之前的残差块的输出。数学表达式可由式(1),式(2)表示
F(x)=W2σ(W1x)
(1)
H(x)=σ(F(x)+x)
(2)
上述表达式只有当输入和输出维度相同时才能直接使用,如果x和F(x)的维度不匹配,则有两种方法可以采用。一种方法是使用线性投影Ws,由式(3)表述
H(x)=σ(F(x)+Wsx)
(3)
另一种方法是使用全0填充。考虑到使用线性投影增加了神经网络的参数和计算量,因此,当输入输出维度不匹配时,使用全0填充使输入和输出维度保持一致。一个典型的带有shortcut的残差块结构以及维度不匹配残差块结构分别如图2(a),图2(b)所示。
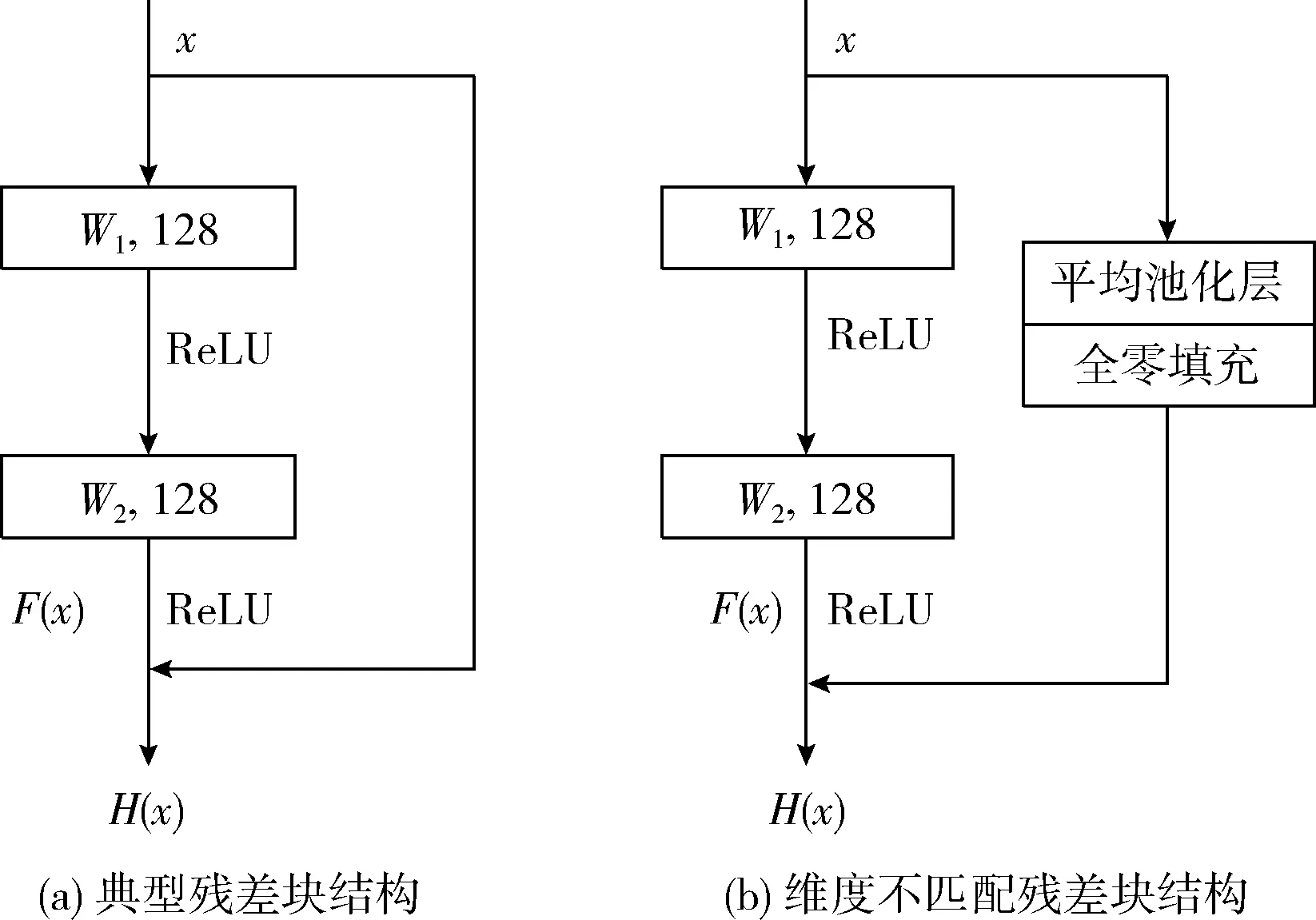
图2 残差网络结构设计
本文中,在卷积神经网络后添加了7个残差块,每个残差块中依次包含卷积、批规范化,线性激活操作。假设输入信号序列为x1,x2, …,xi, …,xn,特征学习自动提取时域和频域特征的过程由式(4)~式(7)表述
fi=Filterθf(xi)
(4)
fj=Filterθt(xi)
(5)
ff=fi+fj
(6)
ft=Res_blockθr(ff)
(7)
其中,Filterθf和Filterθt表示不同大小的卷积核,fi和fj表示提取的频域和时域特征,Res_blockθr表示多个残差块,ft表示经多个残差块处理后得到的高维特征。表1给出了特征学习中深度神经网络每层参数的设定以及输出。
其中1-6层有两组参数,分别代表提取的时域和频域特征网络参数。
1.2 状态纠正
在不受到外界干扰的情况下,人的整夜睡眠是一个由浅入深再到浅的动态过程。在过渡阶段,当前时刻睡眠状态会向相邻的睡眠状态转换,而不相邻的睡眠状态转换的可能性较小甚至极小。在持续阶段,睡眠的某一状态会保持一段时间,然而仅依靠脑电等生物电信号的特征来判断并不够充分,需要依据前后特征变化来判断当前睡眠状态是否处于持续期。本文设计的状态纠正模块由转移规则和平滑规则两个部分组成。不同的规则代表了睡眠状态变换规律的不同特性,转移规则表示不同睡眠分期之间过渡的最大可能性,平滑规则代表了某一睡眠分期的持续性。
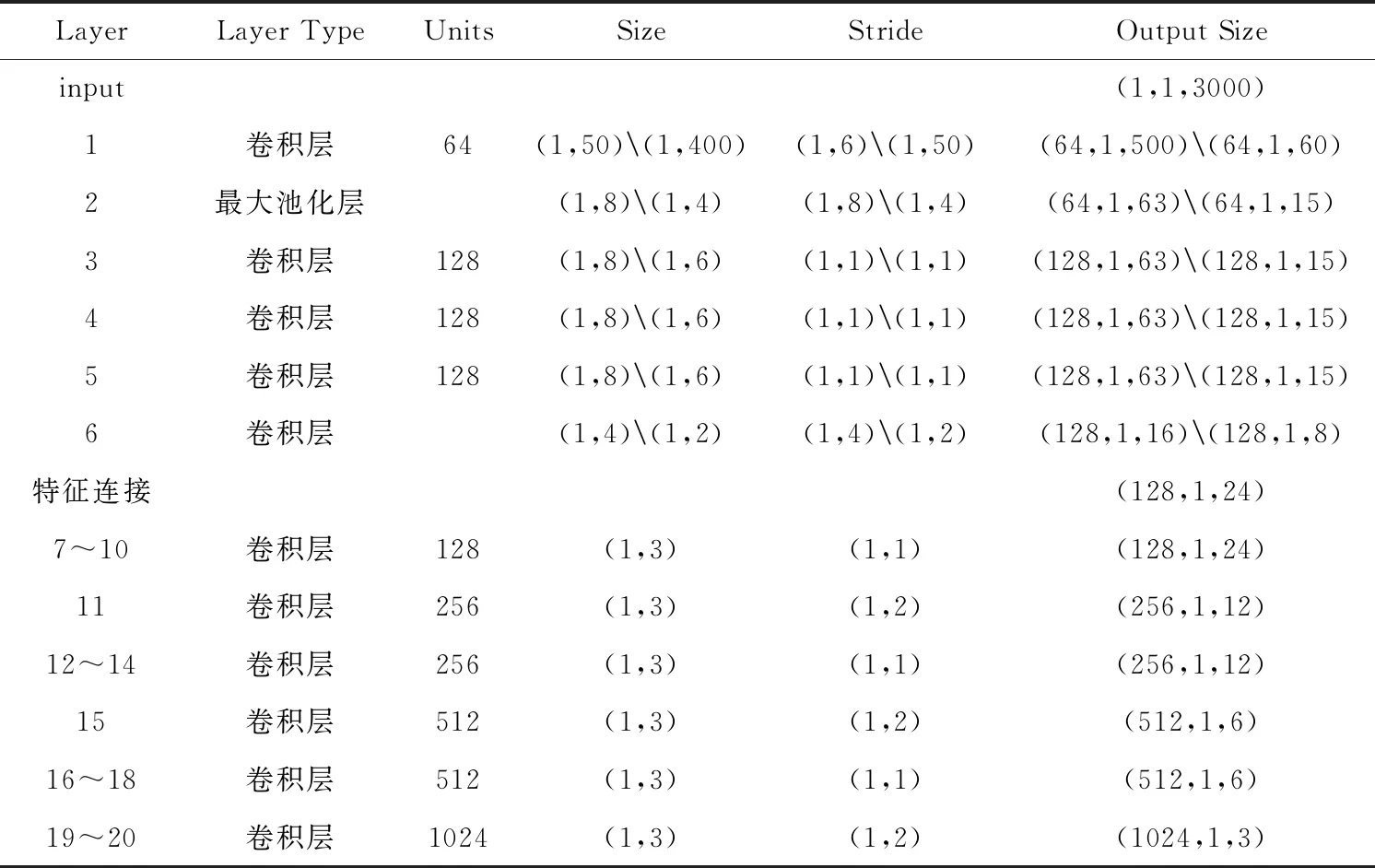
表1 深度神经网络每层参数以及输出
1.2.1 转移规则
从一个睡眠状态过渡到另一个睡眠状态,脑电信号的特征会呈现出逐渐变化的过程。例如,当睡眠状态从清醒期Wake向入眠期S1过渡时,脑电信号中往往伴随着α特征逐渐减少而θ特征逐渐增加的过程。从聚类的角度来分析,过渡阶段的特征与持续阶段的特征相比,会逐渐地偏离聚类中心,从而造成自动分类结果在相邻的睡眠分期中相互混淆,很难得到合理的判断结果。
针对该问题,解决思路是使用概率高的状态转移路径取代概率小的状态转移路径。首先,基于马尔可夫模型,计算了不同睡眠状态之间的转移概率,见表2。其中,第一列表示当前数据段对应的睡眠状态,第一行表示下一个数据段对应的睡眠状态,对角线上的数值表示同一睡眠状态的持续概率,其余数值表示不同睡眠状态之间的转移概率。
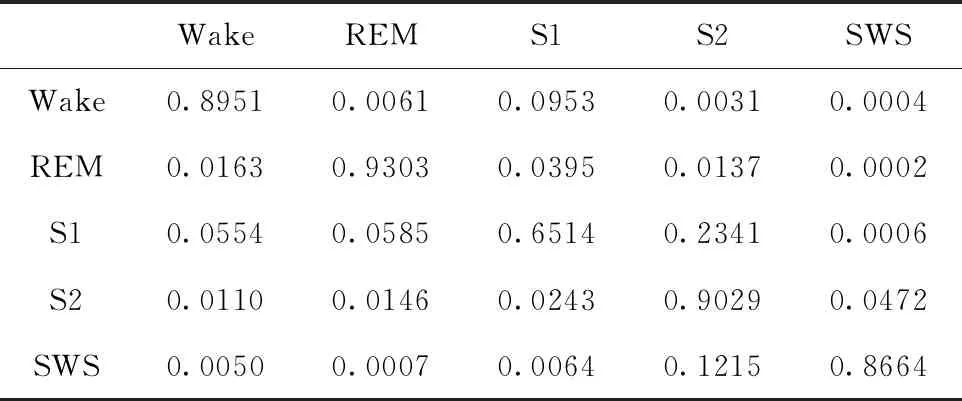
表2 睡眠状态转移概率
其次,设G(i,j)表示从阶段i转移到阶段j的概率,由于状态自身转移的概率较大,为了避免转移过程中状态自身转移覆盖不同阶段转移的情况,将状态自身转移概率设置成一个无穷小的正数,再通过式(8)将状态转移概率转换为睡眠状态之间路径长度
T(i,j)=-logG(i,j)
(8)
显然,转移概率越大,对应的路径长度越短。如果将睡眠的不同状态看作是有向图的若干个节点,那么不同睡眠状态之间的最合理转移情况可以看成带正权边有向图节点之间最短路径问题。
最后,基于Dijkstra算法得到不同睡眠状态之间的最短路径,并设计状态纠正处理步骤。需要注意的是,在整夜睡眠过程中会发生持续时间短暂的中途觉醒,但较难体现在表2中的状态转移概率中。本文在判断最短路径时将该特定状态的发生也融入到纠正处理步骤中。当出现前后连续的3个状态各不相同的情况时,如初始值分别为Sk-1=SA,Sk=SB,Sk+1=SC。
(1)假设Sk-1和Sk+1为真,判断状态SA到状态SC的最短路径。
Case 1:当SA经由SB到SC的路径最短时,不需要修正,输出结果(SA,SB,SC);
Case 2:当SA直接到SC的路径最短时,且SB是清醒期W或入眠期S1(中途觉醒),则不修正Sk并输出结果(SA,SB,SC),反之SB不是清醒期W和入眠期S1,则修正Sk为SC并输出结果(SA,SC,SC);
Case 3:当SA到SC的最短路径,经由其它SX(非状态SB)时,将(SA,SX,SC)保留待定;
(2)假设Sk-1和Sk为真,判断SA经由SB到其它状态的最短路径,也就是Case 4(SA,SB,SY),并与Case 3(SA,SX,SC)相比较,将两者中最短路径对应的状态作为输出结果。
1.2.2 平滑规则
平滑规则是对睡眠状态的持续性进行修正。由于脑电等生物电信号的复杂性,即使在睡眠状态持续过程中,也会出现特征变化,且特征波往往会以簇的形式出现在信号中,也造成前后数据段特征波的能量存在差异性。专业医师在进行人工判读时,会结合前后数据段对中间数据段对应的睡眠状态进行平滑处理。因此,相对于人工判读,计算机自动判读的结果往往会出现不必要或者不合理的波动。例如,清醒期Wake可能会转变为浅睡眠S1或S2,但很少会直接进入深度睡眠期SWS和快速眼动期REM。本文设计的平滑规则也分为两个步骤:
(1)在连续5个数据段中,当前后3个数据段状态相同,而中间混合两个状态相同的数据段的情况。如初始值分别为(SA,SB,SB,SA,SA),将其修正为(SA,SA,SA,SA,SA)的形式。
(2)在连续3个数据段中,当前后两个数据段的状态相同,而与中间数据段的状态不同的情况。如初始值分别为(SA,SB,SA),判断B是否是清醒期Wake或入眠期S1(中途觉醒)。如果是,则不需要修正,输出结果(SA,SB,SA);如果否,则进行修正,输出结果(SA,SA,SA)。
2 实验过程与分析
2.1 数据来源
分析测试用的数据来自于公共数据库SLEEP-EDF。该数据库包含了受试者整晚的多导睡眠图记录,包括脑电、眼电和肌电等信号。由于脑电信号中包含了睡眠过程大部分信息,因此仅使用了来自Pz-Oz通道的脑电信号进行分析。共有20名被试的数据,年龄在25-34岁之间,男女各占一半,在采集的过程中没有使用任何药物。采样频率为100赫兹。将连续记录的脑电信号划分为每30 s一段,每一段对应一个睡眠分期标签,包含了Wake,REM,S1、S2和SWS这5个类别。
2.2 参数设置
在对深度神经网络的训练过程中,采用了均方根传递算法(root mean square prop,RMSprop)对网络模型进行训练,其中学习速率被设置为0.01,动量因子设置为0.9。为了提高计算机的内存应用率,将每次训练的batch size 大小设置为128。
2.3 结果分析
为充分利用数据,采用20折交叉验证对模型进行评估,一个受试者的数据作为测试集,其余19个受试者数据作为训练集,重复20次,最后生成一个混淆矩阵,并计算召回率(Recall,RE),F1评分(F1-score,F1),查准率(Precision,PR),准确率(Accuracy,ACC)。表3为仅使用卷积神经网络进行预测的混淆矩阵,表4给出了结合状态转移规则的深度睡眠分期模型的混淆矩阵。矩阵的行表示人工判读标签,列表示模型预测标签。

表3 基于卷积神经网络模型的睡眠分期预测混淆矩阵(ACC:0.792)
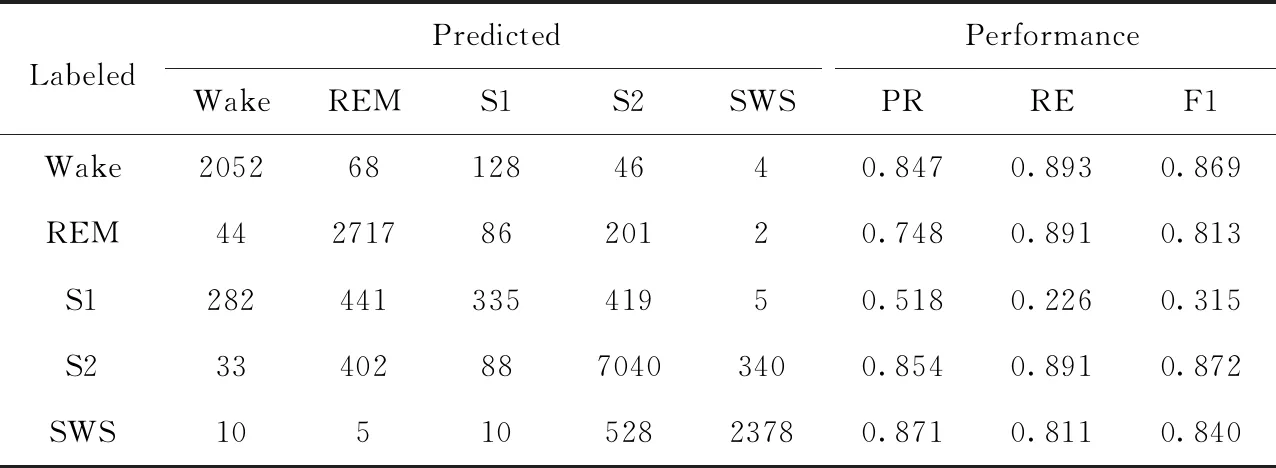
表4 结合状态转移规则的深度神经网络模型的睡眠分期混淆矩阵(ACC:0.823)
从表3和表4可以看出,本文所提出的深度睡眠分期模型与卷积神经网络相比,总体判读精度提高了3.1%。观察每一类的F1-score可得,非快速眼动期REM、浅睡眠期S2和深睡眠期SWS均有显著提高,清醒期Wake也保持了较好的水平。相对于其它睡眠分期,入眠期S1的F1-score相对较低,但与表3相比,表4中S1的F1-score值也有所提升。入眠期S1主要是从清醒期Wake到浅睡眠期S2的过渡状态,在整夜睡眠中S1的样本数量远小于Wake和S2期,存在数据不平衡的现象,使得神经网络对S1的训练不够充分,从而造成精度较低。
此外,为了验证提出的深度睡眠分期模型的判读效果,与现有的一些方法也进行了比较,这些方法均使用了相同的数据集。比较结果见表5。
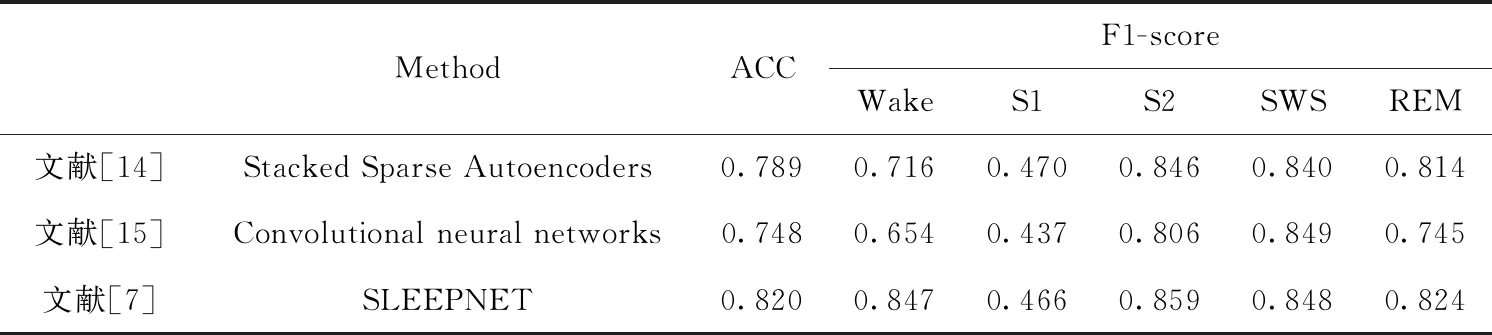
表5 与其它方法的比较
其中,文献[14]采用的是人工提取特征结合机器学习方法进行睡眠分期判别,文献[7]和文献[15]均采用的是自动提取特征,也属于深度学习方法的研究工作。结合表4的分类精度,可以看出提出的深度睡眠分期模型相对于其它方法获得了较好的分类效果。
为了更直观地观察整夜睡眠状态的判读效果,图3和图4分别给出了一名被试整夜8小时的人工判读结果和混合模型预测结果,横轴表示时间,纵轴为不同的睡眠状态。对比图3和图4后可以看出,该深度睡眠分期模型所得到的整夜睡眠状态变化的总体趋势与人工判读较为一致。Wake、S2和SWS,以及REM的判读效果较为理想;S1期作为从清醒到睡眠的过渡阶段,会存在较易与相邻的Wake和S2相混淆的现象,部分REM与S1之间也存在混淆的现象,但与其它方法相比也有所提高。

图3 人工判读结果

图4 深度睡眠分期模型判读结果
3 结束语
本文提出了一种结合状态转移规则的深度睡眠分期模型,具有两大特点:一是在卷积神经网络中添加了残差网络加深网络层数,能够自动提取信号特征用于睡眠判读;二是利用最短路径算法设计了状态转移纠正规则对分类器预测结果不合理的部分进行了自动纠正。实验结果表明,该模型取得了和人工判读较为一致的结果,且状态转移规则更贴近实际睡眠状态的变换规律,对不合理的预测序列具有一定的纠正效果,提升了睡眠分期的判读准确率,能够为临床应用提供一种有效可行的睡眠分期辅助判读方法。
猜你喜欢
网络安全与数据管理(2022年3期)2022-05-23
北京航空航天大学学报(2021年9期)2021-11-02
北京航空航天大学学报(2020年10期)2020-11-14
电子制作(2019年13期)2020-01-14
电子制作(2019年19期)2019-11-23
自动化学报(2019年6期)2019-07-23
电子制作(2019年11期)2019-07-04
电子制作(2019年24期)2019-02-23
北京航空航天大学学报(2018年1期)2018-04-20
重型机械(2016年1期)2016-03-01
