
基于并行深度强化学习的混合动力汽车能量管理策略优化
2020-11-02 06:16:12李家曦孙友长庞玉涵伍朝兵杨小青
重庆理工大学学报(自然科学) 2020年9期
李家曦,孙友长,庞玉涵,伍朝兵,杨小青,胡 博,2
(1.重庆理工大学 车辆工程学院 汽车零部件先进制造技术教育部重点实验室,重庆 400054;2.宁波市鄞州德来特技术有限公司,浙江 宁波 315100)
1 研究现状
混合动力汽车的能量管理策略决定了其在行驶过程中能否实现对能源的高效利用,以达到节能减排的目标。能量管理策略主要是在发动机和电机的总功率满足驾驶员的功率需求时,通过对两者间的功率分配改善能源利用率,提高燃油经济性[1-2]。如图1所示,目前主流的控制策略有两类:基于规则或者基于优化。基于规则的控制策略往往需要消耗大量调参资源并且适用范围受到工况限制,早已有学者对其在混合动力汽车能量管理策略上的应用进行了研究[3-4]。而基于优化的控制策略因为其适应性好,调参相对简单等特点,使得基于优化的控制策略逐渐成为研究热点。国内外近年来对混合动力汽车能量管理策略的优化算法研究案例也逐渐增多,如Serrao等对3种已知的优化算法进行了比较分析[5],包括动态规划、庞特里亚金最小原理(pontryagin’s minimum principle,PMP)和等效能耗最小策略[5-7],讨论了能量管理策略的实时和全局优化方法。全局优化中的代表算法动态规划虽然能够达到全局最优的控制效果,但由于动态规划需要事先获得行驶工况信息导致其一般不能满足实时控制要求。庞特里亚金最小原理由苏联学者庞特里亚金提出的极大值原理转换得到[8]。多位学者尝试引入庞特里亚金最小值原理来求解混合动力汽车在特定工况下的最优控制问题[9-12],但是基于PMP的控制方法较为复杂且系统方程并非连续,需要通过离散状态解决,这一点并不符合大多数工程控制领域的连续动作控制[13]。而基于庞特里亚金最小原理发展出的等效能耗最小策略(equivalent consumption minimization strategy,ECMS)解决了PMP方法中系统方程不连续的问题[14]。本文重点讨论ECMS方法在混合动力汽车能量管理控制策略领域的应用发展。
ECMS是一种由Paganelli等提出的实时优化方法[15],通过将全局最优问题转为瞬时最优问题,使得实时计算成为可能,并且消耗计算资源相对较少。通过ECMS中的等效因子将消耗的电能转化为等效的燃油消耗,加以计算最小化瞬时能耗,因此等效因子的选择也即ECMS方法的关键点[16-17]。Serrao等[18]通过将ECMS应用于混合动力汽车能量管理策略,证明了合适的等效因子能够使ECMS逼近全局最优控制。而根据等效因子在行驶过程中是否固定,ECMS又分为nonadaptive-ECMS和adaptive-ECMS,固定等效因子的nonadaptive方式虽然有逼近全局最优解的可能,但由于需要事先获得行驶工况信息对等效因子值进行调整,而不能满足实际多变的行驶工况,这时能够在行驶过程中对等效因子进行调整的adaptive方式则更加符合实际车辆行驶的需求[19]。传统的adaptive-ECMS方法往往是通过较为简单的PID反馈控制器对等效因子进行调整[20-21],这可能会使调整效果较为一般,从而无法在调参能力有限时达到更优的控制目标。而随着近年来人工智能技术尤其是机器学习中强化学习(reinforcement learning,RL)的快速发展,结合强化学习的智能算法在工业控制问题的应用研究取得了良好进展[22-23]。本文将通过强化学习改进A-ECMS方法,并对改进后的算法性能进行讨论。
最近几年,将强化学习应用于能量管理策略的研究引起国内外学者的关注。强化学习是来源于机器学习的一个普遍且高效的技术,适用于解决序贯决策问题[24]。2012年,Hsu等[25]使用Qlearning算法对混合动力自行车进行功率管理,他们量化了安全性和舒适性指标,比如骑行质量和电池的能源利用率。仿真结果表明:骑行质量和能源利用率可分别提高24%和50%。Yue等[26]提出了一种基于TD(λ)-learning、无模型(modelfree)的在线策略来管理HEV中超级电容器和电池中的能量流。如图2所示,Hu等[27]在ADVISOR上评估了他们基于深度Q网络(deep Q network,DQN)的能量管理策略,并通过与基于规则的控制策略进行比较,在当前的驾驶情况下,通过值函数误差选择最优匹配策略,证明了该策略可以满足实时控制和在线学习目标。Zhao等[28]应用深度神经网络(DNN)来训练离线值函数,并使用Q-learning算法实现在线控制,可以适应不同的动力系统建模和驾驶情况。Liessner R等[29]构建了基于DRL的能量管理策略,该策略考虑了不同司机的驾驶行为以提高燃油效率。而目前应用强化学习在混合动力汽车能量管理控制策略方面的研究案例中,大部分还是通过离散动作的控制方法,这也导致控制效果与离散程度高度相关,不满足实际工程控制需求。为了解决此类需要执行连续动作的控制问题,谷歌Deepmind近期提出了深度确定性策略梯度算法(deep deterministic policy gradient,DDPG),该算法结合深度Q网络与评论家-批评家算法(actor-critic,AC),具有两者各自的特点,能够大幅提升算法收敛速度和控制效果。
不同于其他基于强化学习的控制策略对能量管理进行优化,本文提出了一种结合DDPG与AECMS的控制方法。通过DDPG对A-ECMS中的等效因子s进行控制以解决整车的SOC保持、油耗管理问题,同时在边缘计算架构下以并行的深度强化学习框架加快算法的收敛速度。本文其余结构如下:第1节介绍了混合动力汽车模型以及ECMS方法,第2节说明了所使用的强化学习理论,在第3节解释了设计的实验仿真流程,第4节分析了实验结果,第5节给出了结论。
2 混合动力汽车模型及等效消耗最小策略
2.1 混合动力汽车模型
研究对象选择一款P2构型的混合动力汽车,电机置于变速箱的输入端,在发动机与变速箱之间。车辆结构图如图3所示。
汽车运动模型:考虑汽车行驶时需要克服的路面滚动阻力Fr、空气阻力FW,不考虑其他动力学因素。
空气阻力表示如下:
A是迎风面积;CD是空气阻力系数;ρα是空气密度;v是车速。滚动阻力表示如下:k是车辆滑动阻力系数;M是整备质量;g是重力加速度。设驱动力Fx,汽车加速度表示如下:
发动机模型:采用准静态模型进行发动机建模。燃料消耗率定义为
Ten是发动机输出扭矩;nen是发动机转速;燃油消耗率是两者的函数。在时间T内的总油耗可由燃油消耗率积分得到:
电机模型:电动状态时输入电能,功率由定子端电压和电流的乘积决定,输出为机械能,功率由转子端转速和转矩乘积决定,此时有功率损失,建模需查看效率表。发电状态时能量流方向相反,输入为电机转矩和转子转速的机械功率。输出为定子端电压和电流乘积的电功率。本模型建模未考虑温度等因素影响。
电动状态时,电机转矩Tm与转速ωn满足(ηm是电机电动状态的效率):
发电状态时,电机转矩Tm与转速ωn满足(ηm是电机发电状态的效率):
电池模型:采用最大容量5.3 Ah的磷酸铁锂电池,选用内阻模型建模。由于SOC与开路电压关系特性曲线可由电池实验获得,则已知电池输出功率时,可由SOC状况求得电池电流,以此获得此时电压状况,由电池功率平衡关系和电压关系得:
Ubat和Voc分别为电池输出电压和开路电压,rint是电池内阻;Pbat是电池输出功率。SOC微分表达式为
Qbor为电池额定容量。为保证部件的安全性和可靠性,需满足式(11)约束(发动机与电机的输出转速、转矩范围,SOC变化范围,电池电流、功率变化范围):
2.2 等效能耗最小策略ECMS
ECMS基于这样的理念:混合动力车行驶过程中,初始SOC状态应与行驶结束时的SOC保持相同,这个过程电池可以被看作是一个可逆的燃料箱,只作为能量缓冲器使用,所有能源消耗均来自发动机,目的是提高发动机工作效率。在电池放电阶段使用的任何储存电能必须在以后的阶段通过发动机燃料或是通过再生制动进行补充。ECMS通过将计算全局燃料消耗最小值转化为计算瞬时燃料消耗最小值,并以此推导出电机与发动机的功率分配比。ECMS中的瞬时成本被定义为
s(t)为等效因子EF,等效因子的作用是将电池功率转化为等效燃油功率。
在传统的离线实验中,等效因子是通过迭代搜索发现最优值(通过打靶法求得),也即nonadaptive-ECMS方法。例如将每次迭代的等效因子值持续输入训练环境中并观察效果,以此获得能达到全局最优控制效果的最佳值。由于其值与某时刻所达到的SOC值存在明确关系,故通过迭代搜索是可行的。
而在当前基于ECMS方法的混合动力汽车能量管理策略中,等效因子的值往往是通过PID控制器调整,即将SOC与目标SOC(即初始值)之差作为PID控制器的输入,经过计算得到输出,即等效因子值,属于一种常见的A-ECMS方法,如图4。而基于PID的A-ECMS方法往不能达到较好的控制效果或是满足在多个或未知工况下的行驶需求,本论文将通过深度强化学习对解决此问题进行探索。
3 强化学习理论
3.1 强化学习
强化学习是机器学习方法的一个分支,它通过智能体(Agent)与环境交互,即向环境输入动作,并且从环境获取反馈的方式来对自己的策略进行调整。算法逻辑结构如图5所示,智能体根据环境当前的状况作出决策并采取动作,在下个时间段获得环境新的状况以及奖励信息Reward,通过这个过程来学习并更新强化学习的控制器,目标是通过试错(Trial-and-error)的方式达到改进系统性能的目的[30-31],使奖励信息的累计值达到最大。
3.2 深度强化学习
深度强化学习由谷歌Deepmind在2015年首次提出并被应用于解决围棋任务,取得了极好的效果且击败了围棋界的顶级人类选手[32-33]。图6是深度强化学习算法的逻辑图,智能体通过神经网络代替强化学习中的Q表,将状态输入给神经网络预测其价值并输出动作。
3.3 深度确定性策略梯度算法(DDPG)
DDPG是由谷歌Deepmind团队在2016年提出的[34],它成功实现了网络直接输出动作,从而使算法能够在连续空间进行控制,DDPG和Actor-Critic算法相同的是:DDPG同样具有Actor和Critic 2个网络,通过Actor输出动作,Critic基于Actor输出的动作进行评估,而Actor基于Critic产生的梯度进行更新。DDPG算法和DQN相同之处是通过经验数据回放的方式更新网络,而Actorcritic是通过回合进行更新,DDPG的Actor-critic网络中同样具有evaluate和target 2个网络,更新方式也与DQN相同,这一关系可由图7表示。
DDPG算法的逻辑结构如下:
DDPG Algorithm
1:Randomly initialize critic network Q(s,a|θQ)and actor μ(s|θμ)with weightsθQandθμ
2:Initialize target networkθ*andμ′with weightsθQ←θQ,θμ←θμ
3:Initialize replay buffer R
4:for episode=1,M do
5:Initialize a random process N for action exploration
6:Receive initial observation state
7:for t=1,T do
8:Select action at=μ(st|θμ)+Ntaccording to the currentpolicy and exploration noise
9:Execute action atand observe reward rtand observe new state st+1
10:Store transition(st,at,rt,st+1)in R
11:Sample a random minibatch of N transitions(si,ai,ri,si+1)form R
12:Set yi=ri+γQ′(st+1,μ′(si+1|θμ)|θQ)
13:Update critic by minimizing the loss:
14:Update the actor policy using the sampled policy gradient:
15:Update the target networks:
16:end for
17:end for
4 基于并行深度强化学习的实时能量管理策略
Nonadaptive-ECMS通过离线调整选出固定的等效因子并应用于整个工况,由文献[35]得知,可获得接近全局最优解的控制效果,同时满足SOC保持,缺点是消耗大量资源调参且对工况适应性差,无法在工况变化时仍保持最优控制,不满足实际工业控制的需要。而本研究是通过DDPG算法获得等效因子值,为验证算法效果,将其与传统基于PID反馈的A-ECMS方法进行对比。DDPG中Actor网络输出动作,即等效因子动作执行后,从环境获得到达状态和奖励回报,与动作值以及上一步所处状态组成一个四元组存入记忆池。通过将状态及动作输入Critic网络来得到Critic估计的Q值,计算梯度并以策略梯度方法对Actor网络更新。通过对Actor网络输入当前时刻状态,得到Actor网络对下一时刻状态估计的动作,并将此动作输入到Critic网络中,得到V值与Q-target值并计算损失,通过Adam优化器对Critic网络更新,每隔一定时间对Target网络进行更新,以此循环直至算法收敛。本文提出的基于DDPG的控制器逻辑结构见图8。
搭建基于深度确定性策略梯度算法框架,部分参数如表1。
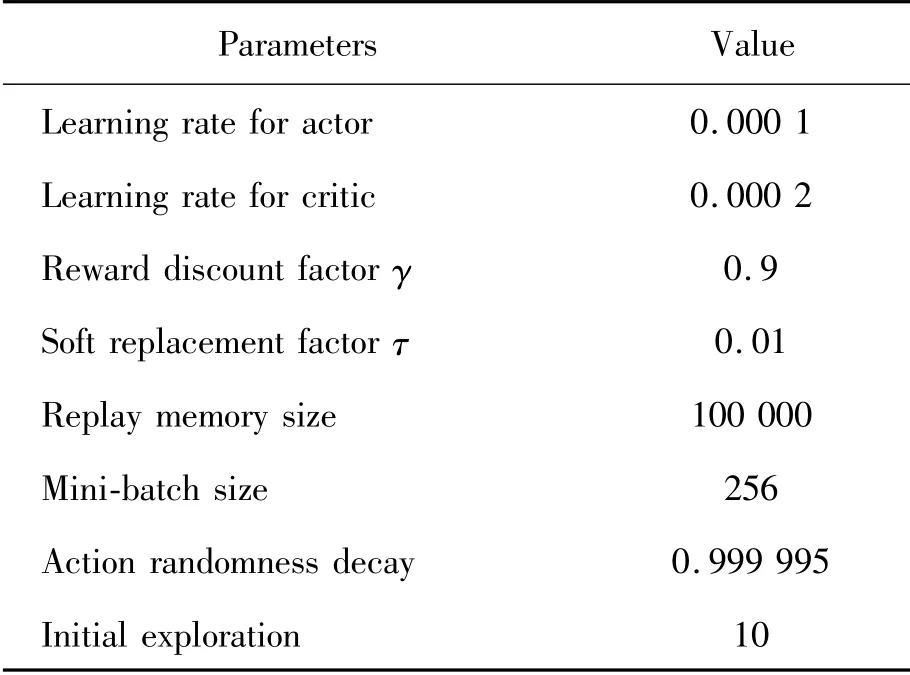
表1 DDPG超参数
DDPG中神经网络的结构搭建如图9,Actor和Critic均具有3个隐藏层,每层120个神经元。
状态由电池SOC、剩余行驶里程、上一步的输出动作组成,选择SOC与上一步的输出动作是为使DDPG智能体获得所要控制的SOC与目标值差距信息,以及自身上个动作导致的影响。而增加剩余里程作为状态一部分的原因是受到智能网联技术发展的启发,当前智能网联汽车中多数搭载有实时定位系统,通过此项技术可以迅速得知汽车位置与终点间距离情况,而此信息有助于DDPG智能体学习如何SOC保持,例如在距离终点过远时可以允许SOC值在较大幅度内变动,以使发动机工作在高效率点,而距离终点位置较近时,则可据此控制SOC快速回到初始值附件,以满足SOC保持目标;奖励回报函数构成如下:
通过高斯函数形式设置奖励回报函数,目的是能够对本研究的2个关注点,即SOC和油耗进行控制,做到SOC保持的同时减小油耗。et是电池SOC值相对初始值的偏差,而it是在控制周期10 s内的油耗量,经过调整设置et和it的系数分别为0.7与0.3。
本文的并行部分通过边缘计算的思想实现,所提出的并行深度强化学习控制器框架如图10所示,首先在云端建立全局网络,全局网络同样含有Actor与Critic框架,通过每个连入此网络的边缘设备(具有与云端完全相同的网络结构)运行各自工况时经历的状态等信息计算出更新全局网络的梯度,将此梯度用于云端的网络更新,同时将云端的最新网络参数同步到边缘设备中,此方法既能够综合多个边缘设备的算力来提升云端网络的收敛速度,也能以此来打破数据相关性。对于边缘设备在接入云端时,即获得由云端分配的适用于当前工况的控制策略,能够将多数算力分配到边缘设备端而不需对云端提出过高的算力及延迟要求。
5 实验结果
本研究计算任务通过一台安装Windows10专业版操作系统,具有64G RAM的高性能工作站完成,CPU:Intel Xeon Silver 4214(2颗,24核48线程),GPU:NVIDIA Quadro P2000。通 过 联 合Python、Matlab/Simulink进行仿真实验,在Simulink搭建仿真模型后,通过Python端的matlab.engine库调用Matlab中编写的m文件以达到控制Simulink仿真模型运行的目的,将Simulink端仿真模型产生的数据通过to workspace模块输出到Matlab工作区,再以m文件形式返回Python,以此循环完成仿真实验。
等效因子的实质作用是在调整发动机与电机功率分配比,而电机与发动机的功率分配不同将导致SOC与燃油消耗率发生变化。本节中用于测试算法的FTP72工况信息如图11所示。
图12 是基于深度强化学习的优化策略学习曲线图,在学习的前50回合,累积回报是在抖动的,而在50回合后,累积回报趋于收敛,此时算法已基本稳定,不再进行改变,策略基本训练完成。后期虽然Reward图仍然有波动,原因是设置有极小的动作探索并且仍在根据参数调整网络,对策略稳定性基本没有影响。
图13 表示DDPG控制器在训练初期具有较大的探索率,这是因为神经网络初始化时输出动作基本相同,直接执行将使智能体的记忆库中数据学习效果较差进而影响算法初期的收敛速度,可以看到:探索值随着时间越来越低并最终趋于0,这表示在后期智能体所执行的动作基本由DDPG控制器所给出。
图14 是FTP72工况测试中电池SOC的变化情况,可以看出3种优化策略均能够将电池SOC保持到较好水平。图中3种算法控制下的SOC终止值不同,并且基于DDPG控制的SOC终止值相对其他2种略低,这是由于3种算法在行驶过程中对等效因子值的选取不同,使得电机输出扭矩不同,进而引起SOC变化的差异累积所致。基于DDPG与接近全局最优控制效果的nonadaptive-ECMS方法则在行驶中使得SOC变化幅度更大,也就有更大余量能够改善发动机工作情况,提高工作效率。计算等效油耗[36]后得知:基于DDPG控制的等效油耗值较基于PID控制的等效油耗值更低,满足控制要求。
从图15~17可看出:基于DDPG的控制策略与基于PID的控制策略在控制过程中发动机与电机扭矩分配情况有明显差别,DDPG的控制效果则在多数情况能够接近nonadaptive-ECMS的控制动作,而电机扭矩不同就导致电池SOC变化会产生不同,发动机扭矩的差别就会导致燃油消耗量的差异。经过计算转化为等效油耗后,基于DDPG的控制策略油耗为百公里7.7 L,而基于PID的控制策略油耗为百公里8.3 L,DDPG相对PID方法油耗减少7.2%,表明了深度强化学习控制方法的有效性。
并行框架中设置不同数量边缘设备的累计回报如图18所示,多个边缘设备的深度强化学习智能体较单个边缘设备能够明显较快地得到算法收敛,其中8个边缘设备的加入使算法训练时间减少了约334%。
6 结束语
本文通过深度强化学习以及并行的深度强化学习控制A-ECMS中等效因子,理论分析的同时,在FTP72工况进行了验证并与传统PID控制器进行对比。实验结果证明:结合DDPG与ECMS的控制方法能够实现SOC保持并且减少油耗的目标,而边缘计算架构下的并行深度强化学习方法能够很大程度加快算法收敛速度。
本文的研究结果对当前混合动力汽车能量管理策略的发展有重要参考作用。未来将通过硬件在环及实车测试等对本文提出的控制算法进一步验证,并更加紧密地结合物联网技术,将交通信息、预测车速等数据导入算法框架,以提升算法的控制效果。
猜你喜欢
今日农业(2022年14期)2022-09-15 01:43:28
军事文摘(2022年14期)2022-08-26 08:14:30
建材发展导向(2022年10期)2022-07-28 03:03:58
科学大众(2021年21期)2022-01-18 05:53:42
小学科学(学生版)(2021年12期)2021-12-31 03:22:18
大众投资指南(2021年23期)2021-12-06 05:46:40
建材发展导向(2021年12期)2021-07-22 08:06:32
建材发展导向(2021年9期)2021-07-16 07:11:10
能源工程(2020年6期)2021-01-26 00:55:22
山东冶金(2019年3期)2019-07-10 00:54:04
