
基于朴素贝叶斯的新冠疫情新闻分类研究
2020-10-26 08:55马亚州侯益明王紫薇
无线互联科技 2020年14期
马亚州,张 勇,侯益明,王紫薇
(山西农业大学 信息科学与工程学院,山西 太谷 030801)
0 引言
2020年,新冠病毒来势汹汹,席卷全球。随着新型冠状病毒性肺炎疫情的蔓延,防控工作越来越艰巨,面临的问题也越来越严峻。在这没有硝烟的“战场”上,普通民众能做的就是保护好自己,因此,能够正确接收正规新闻报道,清楚地认清当下疫情情势和防控措施,才可以更好地保护自己,对社会有所贡献。
为了能够快速阅读到关于疫情的新闻,本文基于朴素贝叶斯算法来对当前一些实时新闻进行分类,将实时新闻分为疫情类与非疫情类。该算法用于分类的准确率较高且有一定使用意义,值得进一步研究。
1 朴素贝叶斯算法
朴素贝叶斯(Naive Bayes,NB)是基于“特征之间是独立的”[1]这一朴素假设,应用贝叶斯定理的监督学习算法。对应给定的样本X的特征向量x1,x2, ...,xm;该样本X的类别y的概率可以由贝叶斯公式得到:
(1)
特征之间是相互独立的,可得:
(2)
在给定样本的情况下,P(x1,x2, ...,xm)是常数:
(3)
要求得到最终的模型为:
(4)
计算出新闻分类中用于训练的每个新闻标题的每个单词在词汇表中出现的概率,之后对于待分类的新闻可分别计算其属于两个类别的概率,然后比较其大小,最终予以分类[2]。算法流程如图1所示。
2 数据准备
(1)通过Java爬虫代码分别从中国日报网英文版(http://www.chinadaily.com.cn/)、人民网英文版(http://english.peopledaily.com.cn/)、中国日报英文版(http://europe.chinadaily.com.cn/ )、新浪英文版(http://english.sina.com/ )等各大权威网站搜集近一个月以来的新闻报道标题,从中共筛选得到1 085条关于新冠疫情的新闻报道标题,从中随机选取200条用于测试错误率,其余用于训练,另外,选取同样数目的其他新闻标题也用于训练。将每个样本分别单独放到一个文本文档中,构成训练数据集和测试数据集[3]。
(2)训练数据时,将所有训练数据集和测试数据集构成一个词汇表并且将其向量化,将得到包含所有单词的单词表及向量表,如表1所示。

表1 样本数量
3 实验过程
3.1 构造分类器
根据朴素贝叶斯算法的原理,首先,需要针对所有样本集构造一个词汇表;其次,根据词汇表将训练样本集向量化[4];最后,构造一个带有两个参数的分类器:训练文档矩阵和训练类别标签向量。将依次求得在整个数据集中,文档分别属于疫情类以及非疫情类的概率、词汇表中各个单词分别在疫情类以及非疫情类的概率,分类流程如图2所示。
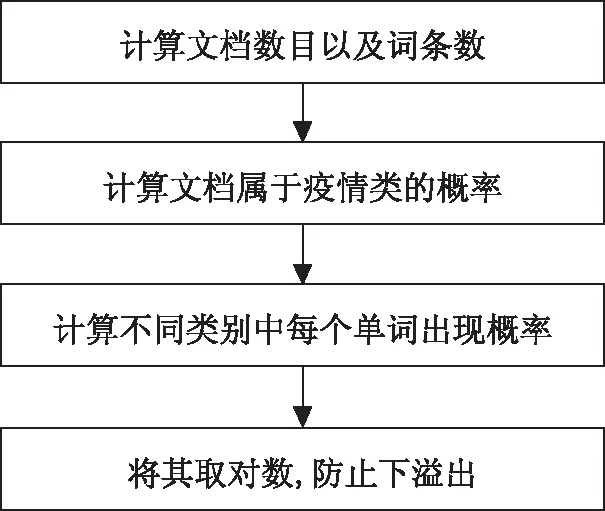
图2 分类流程
3.2 新闻识别
进行新闻识别前,根据在“构造分类器”部分得到的词汇表将待分类的200个新闻标题向量化[5],各自形成文本文档。
根据之前构造分类器输出返回的结果,可用于对新闻文档来进行分类。对每一个待分类新闻,首先使用split函数将其内部单词且分开,然后去除没意义的部分(长度小于3),之后将该文档使用于式(3),求出该文档分别属于各个类别的概率,最后取概率大的类别为最终分类类别。将测试结果与其真实类别进行比较,若不相等,则分类错误,错误次数加1,错误率为式(5):
(5)
其中,X为错误分类的数据个数,N为进行测试的数据个数。可以得到新闻分类的错误率,以此来评价分类的效果。
4 结果分析
经过对随机抽取的200条新闻进行分类测试,平均正确率可达到95.94%,分类准确率较高,如表2所示。
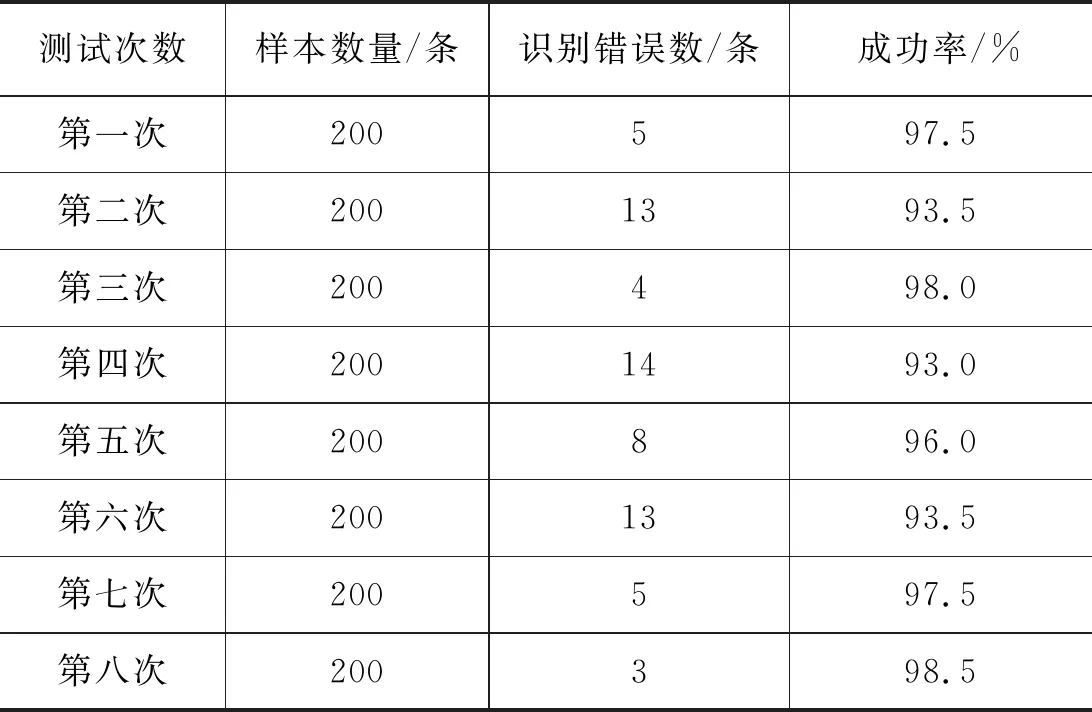
表2 每一次分类准确率
5 结语
将该分类器应用于实际的新闻分类将有实际意义,使民众能够快速接收到关于新冠肺炎疫情的消息,更好地保护自己和保护别人。
猜你喜欢
数理化解题研究(2017年4期)2017-05-04
铁道通信信号(2016年6期)2016-06-01
新校长(2016年8期)2016-01-10
电子器件(2015年5期)2015-12-29
商事法论集(2014年1期)2014-06-27
中国中医药现代远程教育(2014年16期)2014-03-01
郑州大学学报(理学版)(2014年2期)2014-03-01
食品科学(2013年8期)2013-03-11
双语时代(2009年3期)2009-09-24
