
基于KNN算法的手写数字识别研究
2020-10-26 08:55马亚州侯益明
无线互联科技 2020年14期
张 勇,马亚州,侯益明
(山西农业大学 信息科学与工程学院,山西 太谷 030801)
0 引言
近年来,随着科学技术的不断发展和创新,人工智能迅速崛起,手写数字识别在各行各业也有了应用,尤其在金融行业应用更加广泛,但数字识别的错误在金融领域所带来的后果是不可低估的[1],因此,对手写数字识别的准确率要求相当高。
为了提高手写数字识别的准确率,本研究使用K最近邻(K-Nearest Neighbor,KNN)算法构建分类器,识别手写数字的准确率得到了很大的提高,而且实现方便简单,运行速度快,值得进一步去研究。
1 KNN算法
KNN算法中存在一个样本数据集合,在该集合中,每个数据对应一个标签,即数据与其类别之间一一对应[2],当输入一个未知类别的数据之后,算法会计算该数据的每个特征与样本数据集中所有数据对应特征之间的关系,具体计算方法:

(1)
将计算结果从小到大排序,选择前K个距离最近的数据[3],判断其中出现次数最多的类别,将其作为输入数据的类别。
2 数据准备
(1)收集0—9的手写数字图像共2 721张,包括1 856张图像作为样本数据集,865张图像作为测试数据集合。在分类之前,需要将图像进行预处理,可以使用图形处理软件,使之成为宽高是32×32 px的黑白图像,并将图像转换为文本格式,使之成为32×32的二进制矩阵[4]。
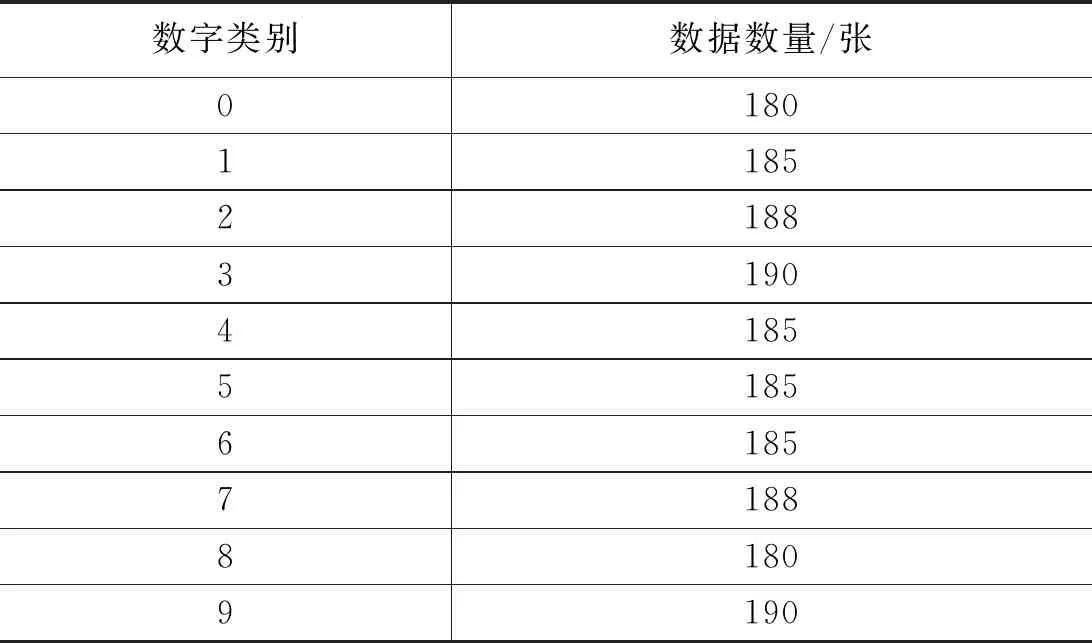
表1 样本数量表
(2)要想使用KNN算法构造的分类器来识别手写数字,就需要将数据处理之后得到的二进制矩阵转换为1×1 024的向量,使之满足数据集中一行代表一个数据的基本要求。
3 实验过程
3.1 构造分类器
根据KNN算法的原理,构造一个有4个参数的分类器:待分类数据、样本数据集、样本标签集、K值,依次进行新数据与样本数据之间距离的计算、对距离由小到大排序、取得前K个距离最近的数据、确定前K个点中各类别出现的次数、出现次数最多的类别为新数据类别之后,即可预测出新数据的类别[5]。分类器流程如图1所示。
3.2 参数K的选择
K值的选取非常重要。(1)当K的取值过小时,如果有噪声成分存在,将会对预测产生比较大的影响。例如,取K值为1时,一旦最近的一个点是噪声,那么就会出现偏差。(2)如果K的值取的过大时,就相当于用较大邻域中的训练实例进行预测,学习的误差会增大,与目标点距离较远的实例也会对预测起作用,使预测可能发生错误。(3)如果K取N时,就是取全部的实例中出现次数最多的类别,则失去了预测的意义。
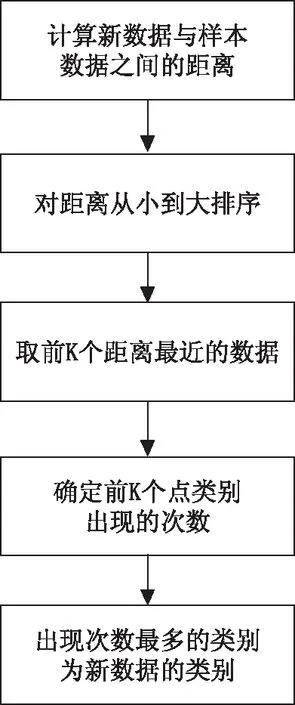
图1 分类器流程图
在选取K值时,应该尽量选取奇数,保证最终总会得到一个分类结果,如果为偶数,可能出现相等的情况,不利于分类。K通常是不大于20的整数,所以,从K取1开始进行测试,记录分类结果的错误率,每次使得K值增加1,选择错误率最低的K值作为分类器的K。分类错误率随K值变化如图2所示,据此进行分析,最终选择K值为3。
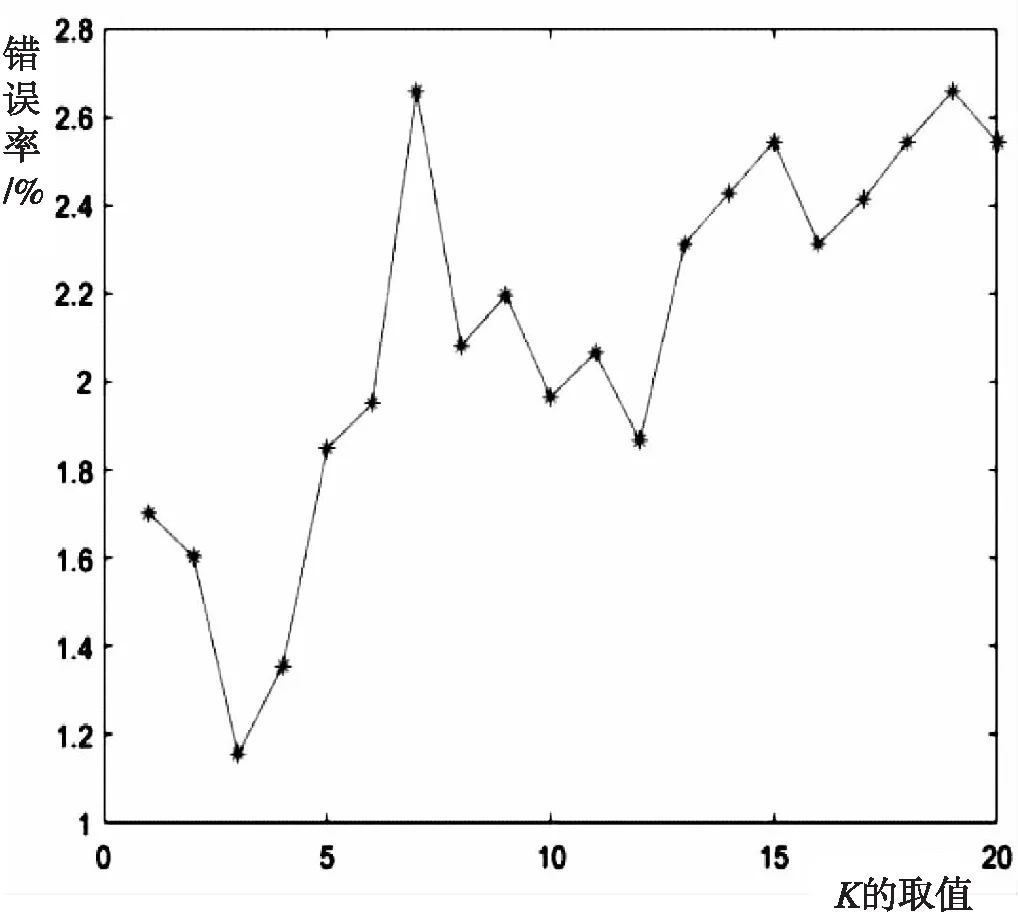
图2 分类错误率随K值的变化
3.3 数字识别
用收集到的1 856张图像作为初始的样本数据集合,将每张图进行预处理[6],转换为32×32的二进制矩阵,并存储在文本文档中,以X_i.txt格式命名,其中,X代表数据的真实分类,i代表该类别下的第几个数据。将样本数据集输入到算法中,使用split()函数对文件名进行分割,取下标为0的元素,即为数据的真实类别。
使用构造好的分类器进行测试,对于数字0—9分别进行测试。测试前,要使用split()函数对文件名进行分割,以得到数据的真实类别。将测试结果与其真实类别进行比较,若不相等,则分类错误,错误次数加1,错误率如式(2):
(2)
其中,x为错误分类的数据个数,N为进行测试的数据个数,可以得到手写数字识别的错误率,以评价分类的效果。
4 结果分析
将每个类别的数据分别输入到分类器中,各类别的分类准确率如表2所示。实验表明,基于KNN算法构建的分类器用于识别手写数字准确率最高可达98.89%,进一步证明了该方法用于识别手写数字的可行性,具有实现简单、运行速度快的优点,解决了人工处理大量数字的问题,具有很好的研究价值。

表2 各类别的分类识别准确率
猜你喜欢
作文成功之路·小学版(2020年7期)2020-08-24
新课程·上旬(2019年1期)2019-03-18
电子制作(2018年18期)2018-11-14
教师·中(2017年3期)2017-04-20
试题与研究·教学论坛(2016年27期)2016-08-11
自动化学报(2016年8期)2016-04-16
新校长(2016年8期)2016-01-10
商事法论集(2014年1期)2014-06-27
中国中医药现代远程教育(2014年16期)2014-03-01
食品科学(2013年8期)2013-03-11
