
基于Vague集理论一维属性
——需求匹配的知识推荐算法研究
2020-10-24 06:59臧振春崔春生
运筹与管理 2020年8期
臧振春, 崔春生
(1.周口师范学院 数学与统计学院,河南 周口 466001; 2.河南财经政法大学 计算机与信息工程学院,河南 郑州 450046)
0 引言
电子商务推荐系统[1]已成为全球电子商务网站提升销售业绩的一项重要营销工具,并引起了学者及业界的广泛兴趣和关注。它是一个涵盖心理学、人工智能、管理学、计算机可学等多学科的研究领域[2]。电子商务推荐系统是解决信息超载问题的有效途径之一[3],它根据用户的个性需求、兴趣等,将产品或信息推荐给特定用户。
1 研究综述
推荐系统的研究包括输入、算法和输出三个内容,其中算法作为系统的黑匣决定了推荐结果的有效性影响了推荐质量,是推荐系统中的核心和关键。目前,主流的推荐算法包括协同过滤推荐、基于内容推荐、基于知识推荐和组合推荐四种[2]。协同过滤是研究最为成熟和广泛的一种算法,它主要通过识别用户的邻居用户,根据其生成产品的评价分类;内容推荐算法是根据用户的评价生成产品的分类,这种算法因特征提取的难题客观存在,在发展的过程中受到了阻碍;组合推荐算法是唯一能够使其他算法的缺点得到补偿的一种有效算法[4,5],大部分研究和应用是对基于内容的推荐和协同过滤推荐进行组合。比较而言,知识推荐算法发展缓慢,该算法通过计算产品属性和用户需求的匹配程度达到有效推荐的目的。在大数据时代,人工智能技术发展迅速,“推理”成为一种重要的问题解决手段,因此加大对知识推荐的认识和研究显得至关重要。
基于知识推荐[6]的本质是一种决策推理技术,借助用户知识和产品知识的思想,通过前期的学习,挖掘用户的偏好兴趣,进而推理产品知识满足用户需求的程度,以此向用户提供推荐。基于知识推荐算法运用了“功能知识”的概念,认为功能知识是某个产品的属性(或性质)能够满足特定用户的知识。功能知识在用户知识和产品知识之间建立起了某种内在的联系,它能解释用户需要和产品推荐之间的联系。“功能知识”构建的用户模型可以是任何知识,并非一定是用户的需求和偏好,只要能支持系统推理即可。例如:Google采用的是两个网页之间的链接关系,以此推断某网页的权威度(Authoritative Value)和流行度(Popularity Value)[7]。Quickstep and foxtrot systems[8]使用关于学术论文主题的本体知识库向读者推荐,蒲珊珊[9]等提出一种考虑知识互补的专家推荐模型,以此来探究专家的知识结构与学术影响力,发现最佳的科研合作团队。基于知识的推荐缺点在于个性化程度不及协同过滤,但只要依据合理的知识推理,它的推荐结果就能为多数用户接受,所以在某种程度上可以缓解“信息茧房”的出现,换句话说这种方法得到的推荐结果更多的都是非个性化推荐。另外,该技术的难点在于知识的表达和知识的获取。
2 问题描述
协同过滤对冷启动问题的敏感度较高,在评分数据不足时得到的推荐质量偏低;再者,协同过滤和内容推荐算法的时间敏感度也比较高,在时间跨度较大的情况下,用户兴趣的漂移会使推荐的“精准”问题大打折扣。知识推荐的优点在于它不须要评分数据,因此不存在启动问题,也不存在数据的稀疏性问题,仅仅依赖于知识库中的“知识规则”或关联关系得到推荐结果。知识推荐广义上“是以一种个性化方法引导用户在大量潜在候选产品中找到感兴趣或实用的产品”的系统,所以该方法得到的“新颖度”较高,一直受到资深网民的追捧。但是基于知识推荐过程又是一个交互式的过程,用户必须指定需求,然后系统设法给出合适的产品;如果找不到,用户必须修改需求,在这样的多轮交互过程中,可以让系统提升对用户需求的了解程度。基于知识的推荐有两种思路,一是根据用户需求,依据相似度计算方法寻找相似的产品;二是完全依赖系统中定义的推荐规则进行一对一的匹配。两种思路异曲同工,都是在寻求用户需求和产品特征的匹配关系。
知识推荐算法的根本是产品特征与用户需求的匹配,其难点在于产品属性特征和用户需求均属非结构化的问题,因此在数据处理方面有一定的难度。其次,产品特征的描述也是困难之一,这个问题同样存在于内容推荐算法中,这是协同过滤推荐算法较内容推荐算法研究广泛的原因之一。第三,用户需求的描述也存在一定的困难。伴随社会经济的发展,中国的市场早已从卖方市场转入买方市场,商品的极大丰富使中国的老百姓早已满足马斯洛需求层次理论中的低层次需求,进而转向高层次的个性化需求阶段,个性化需求的捕捉描述成为推荐系统研究中的难点之一。
论文正是基于以上问题,借助Vague集理论和方法解决知识推荐中存在的问题,优化和改进知识推荐算法。因而,本文的主要工作体现在以下几个方面。第一,借助内容推荐算法中的优秀成果,将其属性描述的手段移植到本研究中,并基于知识推荐中“属性——需求匹配”的思想,借助Vague集理论对产品特征的描述进行优化。第二,在用户需求抓取方面,视用户需求为系统中的输入数据,从显式输入和隐式输入两个角度入手,借助Vague集理论合理的描述用户的需求。在显示输入方面,抓取用户注册信息,评分记录等有价值的信息;在隐式浏览输入方面,抓取用户浏览记录、浏览时间、访问路径、网络行为(购买、收藏、下载、转载、分享、评论、点赞等),进而定义用户的需求。第三,从产品特征和用户需求出发,借助相似度或关联性的计算,寻找两者的匹配关系,进而达到推荐的目的。
3 Vague集理论的引入
在Fuzzy集基础上,Gau和Buehree[10]于1993年根据Fuzzy集的特征,通过引入真隶属度和假隶属度的方式来推广Fuzzy集,提出了Vague集的概念。Vague集的一个重要特点是,能够分别以真隶属度函数与假隶属度函数表示模糊信息的两个方面,其中真隶属度即实际信息中对研究对象隶属的支持程度,假隶属度即实际信息对研究对象隶属的反对程度,并且在此之中,还暗含着犹豫的状态,即不支持也不反对的中间状态。这一种重要特点保证了Vague集相对于其他经典Fuzzy集在体现现实信息不确定性方面的天然优势,使其能够更加详尽地表达研究对象的模糊特性。Vague集是一种能够很好地解决不确定性问题的工具,它用形式化的语言表达事物的特征,描述了事物的发展。
3.1 基本定义
定义1(实数值Vague集,RVVS, Real Value Vague Sets)[10]设U是一个论域,其中任何一个元素用x表示。U上的一个实数值Vague集A是由真隶属函数tA和假隶属函数fA描述的:tA:U→[0,1],fA:U→[0,1]。
对于x∈U,tA(x)是从支持x∈A的证据所导出的x∈A的肯定隶属度的下界,fA(x)是从反对x∈A的证据所导出的x∈A的否定隶属度的下界,并且tA(x)+fA(x)≤1。x关于Vague集A的隶属度可由[0,1]上的子区间[tA(x),1-fA(x)]表示,或者称[tA(x),1-fA(x)]是x在Vague集A中的Vague值。称πA=1-tA(x)-fA(x)为x关于A的未知度,也称为犹豫度或踌躇度。πA是x相对于A的未知信息的度量,πA的值越大,说明x相对于A的未知信息越多。当tA=1-fA时,πA=0,即tA+fA=1时,Vague值x退化为普通模糊值。
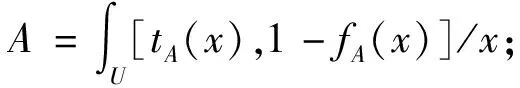
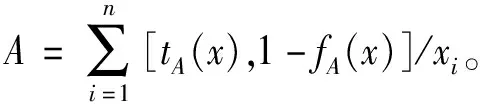
3.2 数值计算
1993年,Gau和Buehree 在定义Vague集的同时给出了运算法则。1994年,Atanassov[11]定义了直觉模糊集的运算规则。在此基础上,De等[12]重新定义了Vague集的运算规则。
根据徐泽水[13]的定义,可以得到两个Vague值x=[t(x),1-f(x)],y=[t(y),1-f(x)],的基本运算规则:
(1)和运算:x+y=[t(x)+t(y)-t(x)t(y),1-f(x)f(y)];
(2)积运算:x·y=[t(x)t(y),1-(f(x)+f(y)-f(x)f(y))];
(3)系数乘积:λx=[1-(1-t(x))λ,1-f(x)λ],λ>0;
(4)幂运算:xλ=[(t(x))λ,f(x)λ],λ>0。
3.3 相似度
Vague集研究领域中大量研究的都是Vague集(值)之间的相似性。从现有度量公式的表现形式及主要特点来看,主要的有三种思路:
第一种是基于Vague值的记分函数。Vague值的记分函数概念是Chen于1994年提出的,并利用记分函数定义了Vague集的相似度。
定义2[14]设Vague值x=[tx,1-fx],tx,fx∈[0,1],且tx+fx≤1,称S(x)=tx-fx为x的记分函数。记分函数反映了现有的确定性证据中,支持与反对力量的对比,因而也称为优势函数。
第二种是基于距离测度的相似度量方法,有代表性的研究如文献[15,16]。目前基于距离的Vague集的相似度量主要有两种方法。一种是利用距离对偶的公式sim(A,B)=1-d(A,B)[17]。另一种是用x到y的距离及x到y的补集的距离的比值来评价两个Vague值x,y的相似程度[17]。王伟平[18]分别根据第一种思路,在确定新的距离公式基础上定义了实数值Vague集A的相似度:
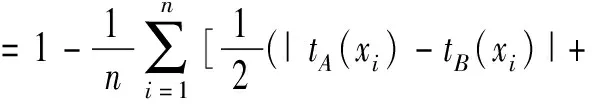

第三种思路建立在未知度的再分配基础上,在衡量相似度时将未知度按比例分配到真、假隶属度中,再进行比较。
以上求得的相似度满足以下准则:
准则1(规范性)0≤Sim(A,B)≤1;
准则2(对称性)Sim(A,B)=Sim(B,A);
准则3Sim(A,B)=Sim(AC,BC);
准则4(单调性)若A⊆B⊆C,则Sim(A,C)≤min{Sim(A,B),Sim(B,C)};
值得注意的是,考虑到现有的相似性度量是建立在Vague值x服从均匀分布这一默认前提下的,最近一些学者将统计中的概念引入到相似度的度量中来。文献[19]提出了一种基于正态分布函数的相似度量方法, 实例证明该方法既可以解决几种特殊的直觉模糊集合之间的相似度量问题,也可以克服现存的几种相似度量方法中存在的缺陷。
4 基于Vague集的知识推荐描述
4.1 符号界定
为了问题描述,论文界定如下符号:
定义产品集合为I=Ii(i=1,2,…,n)={I1,I2,…,In}
定义用户集合为U=Uj(j=1,2,…,m)={U1,U2,…,Um}
定义产品一维属性特征集合为X=xk(k=1,2,…,p)={x1,x2,…,xp}
4.2 基于Vague集理论的产品属性特征描述
知识推荐算法的核心是实现产品特征与用户需求的匹配,因此先要实现产品特征的表示。然而,网上产品,尤其是一些畅销产品,其属性一般都是采用非结构化的语言来描述,这给问题的解决带来了一定的困难。同时,产品的属性又是由不同的产品特征组成的,这样构成了一个产品属性与产品特征之间的树状关系图,如图1所示。
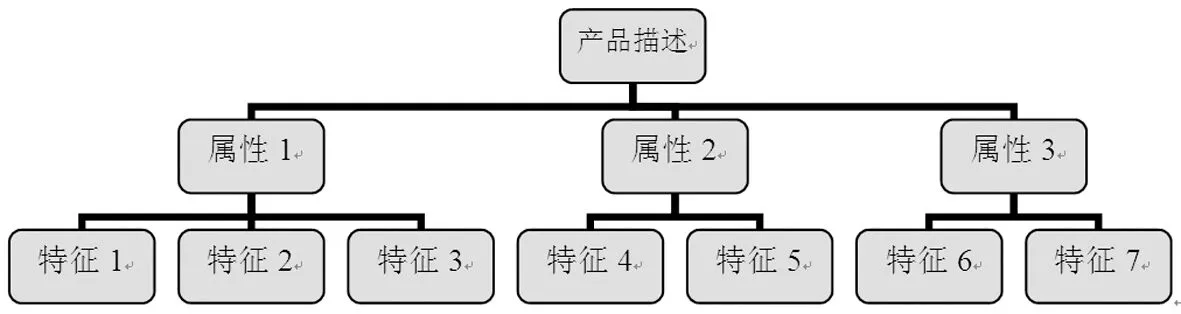
图1 产品属性结构图
从内容推荐算法的角度来说,实际上就是系统经过一系列的前期学习,发现大量的产品与用户之间的匹配关系。产品借助于属性特征描述,例如某产品具有特征1、特征3、特征4和特征6,用户的兴趣也用产品特征描述,例如用户的兴趣点是特征1、特征3、特征4和特征6,这样就建立起了产品和用户兴趣之间的知识库,基于知识库的学习,达到产品特征与用户兴趣的匹配。
产品的属性集一般都是多维的,例如爱奇艺网站,其电视剧产品的属性划分为:频道、地区、类型、年代等四个属性,其中类型属性包含:言情剧、历史剧、武侠剧、古装剧、年代剧、农村剧、偶像剧、悬疑剧、科幻剧、喜剧、宫廷剧、商战剧、神话剧、穿越剧、罪案剧、谍战剧、粤语电视剧、超清1080P、青春剧、家庭剧、军旅剧、剧情、都市、网络剧。电影产品的属性则描述为:年代、地区、语言、类型、主演、导演、总播放量、简介等,其中类型的属性又包括:喜剧、悲剧、爱情、动作、枪战、犯罪、惊悚、恐怖、悬疑、动画、家庭、奇幻、魔幻、科幻、战争、青春等。
一般情况下,多维属性的推荐因其描述全面细致,分类详细,通常会得到更好的推荐结果,但是其计算复杂度呈指数倍增。鉴于多维属性推荐的计算复杂度,本文仅探讨一维属性,多维属性问题可以从一维出发进行拓展。
知识推荐中属性特征的描述和内容推荐算法中属性特征的描述具有异曲同工之效,借助内容推荐算法的特点和Vague集理论在非结构语言描述方面的优势,可以通过以下步骤得到产品的特征描述。
Step1定义产品属性
互联网上的任何产品实际上都是一组特定属性及其属性特征的集合,电影中“类型”属性的特征集合可表示为:X={喜剧、悲剧、爱情、动作、枪战、犯罪、惊悚、恐怖、悬疑、动画、家庭、奇幻、魔幻、科幻、战争、青春},分别用xk表示[20]。
Step2确定肯定隶属度
对产品Ii依特征xk的相关程度降序排列,也可以按照特征相对于产品的重要性进行降序排列。如:{x1,x6,x4,x8,x5,x3,x7,x2,…}表示该产品Ii的特征重要性或相关程度按1、6、4、8、5、3、7、2的次序逐渐降低。
考虑Vague集定义,用txk(Ii)表示产品Ii属于xk的肯定隶属度,其含义为该特征相对该产品的重要性程度。显然,针对某一产品的某特征,其重要性程度越高,该特征对应的肯定隶属度也就越高,因此各特征xk的肯定隶属度仍然依赖上述特征排序结果依次降低。
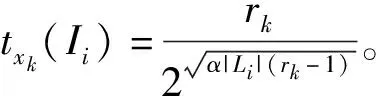
Step3确定未知度
否定隶属度的确定是一个比较困难的问题,这里可以借助论文[20]的思想,从肯定隶属度、否定隶属度、未知度的关系出发寻求否定隶属度。
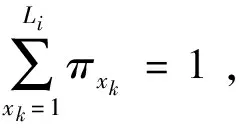
Step4Vague值产品特征表示
根据1-fxk(Ii)=πxk(Ii)+txk(Ii)得到产品Ii各特征xk的Vague值vxk(Ii)=[txk(Ii),1-fxk(Ii)]。
由于任何一个产品Ii在一维特征条件下具有多重特征,因此可以将之表达为一个Vague集的形式,即:V(Ii)={vx1(Ii),vx2(Ii),…,vxp(Ii)}。
4.3 基于Vague集理论的用户需求描述
知识推荐算法的另一个要点则是用户的需求描述。现实中用户需求具有漂移性,时间、地点、收入、年龄、环境等都会带来用户需求的变化。用户需求的描述内化于用户的网上行为,进而也反映出用户行为数据的获取。
推荐系统中用户需求捕捉通常采用有两种方式,一种是显性评分,另一种是隐性浏览。前者通过用户注册信息以及用户对历史产品的评价得到用户倾向爱好,后者通过用户购买、浏览、重复操作、保存、屏蔽、转发、收藏、推荐等一系列活动隐形分析用户的偏好。文献[22]采用浏览、收藏、添加到购物车、购买四种行为获取隐性数据,并且认为四种行为之间存在明显的权重等级:浏览<收藏<添加到购物车<购买。考虑到移动互联网端,其实用户在购买以后经常会有点赞、分享、转载等一系列行为表达自己对服务或产品的赞誉之情,我们可以定义用户的隐形行为包括:浏览、收藏、添加到购物车、购买、分享(或转载、点赞)。
这里定义用户对某产品Ii一维属性特征xk的兴趣度包含显性兴趣度和隐性兴趣度,它们分别是显性行为和用户隐性行为的直接表现形式,其中,显性行为包括用户显性评分输入和用户注册资料中兴趣爱好的显性描述;隐性行为包括分享(或转载、点赞)、购买、收藏(包括放入购物车)、浏览等四个影响因素。隐性行为是基于用户隐式浏览输入获得的,这是捕捉用户兴趣的主要因素,尤其是对冷启动用户、产品评价数据不足以及注册信息不完备的用户尤为重要。不难发现,六项行为引发的六项数据,其可靠性不同因而在用户兴趣提取中的重要性程度也有所不同,我们可以定义:浏览<收藏<购买<分享<评分<注册。
由此,可以定义用户Uj(j=1,2,…,m)对一维属性特xk(k=1,2,…,p)征具有的兴趣度:Intjk=λ×ExIntjk+(1-λ)λImIntjk。
式中:Intjk表示用户Uj对一维属性特征xk的兴趣度,0≤Intjt≤1;
ExIntjk表示用户Uj对一维属性特征xk的显性兴趣度;
ImIntjk表示用户Uj对一维属性特征xk的隐性兴趣度。
λ(0≤λ≤1)称为表现系数,表示显性兴趣度在整个兴趣度中的权重,通常情况下λ≥0.5,也就是说显性行为在兴趣度的获取方面具有更强的显示度,对用户兴趣度的影响更大。当兴趣度提取时只有显性兴趣度,则Intjk=ExIntjk(λ=1),这种情况通常发生在新注册用户身上;当兴趣度提取时只有隐性兴趣度,则Intjk=ImIntjk(λ=0),这种情况通常发生在用户注册信息极度匮乏,用户自我保护意识强的情况。
进一步,可以定义:
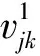

进而,用户的兴趣度可以描述为:
Intjk=λ×ExIntjk+(1-λ)×ImIntjk

由于用户的兴趣度内含于六项不同的行为,因此用户兴趣度Vague值的获取依赖于六项行为的Vague值获取[23]。
(1)注册Vague值
(2)评分Vague值
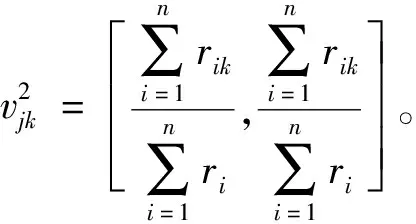
(3)分享(或转载、点赞)Vague值

(4)购买Vague值
购买Vague值的定义考虑两个因素:购物总量的比重、购物价值的比重。
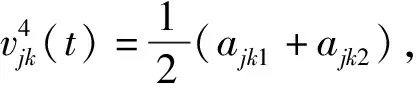
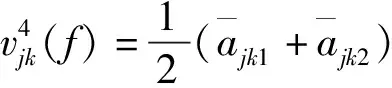

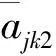
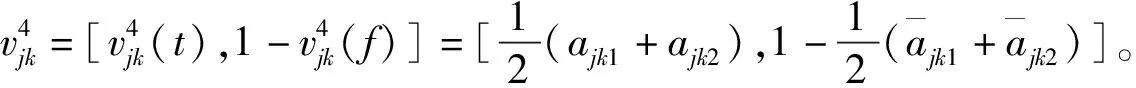
(5)收藏(包括放入购物车)Vague值
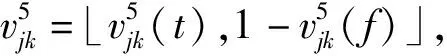
(6)时间Vague值
Tksi表示用户浏览产品的si相对时间;
αjs和γjs分别表示第S类产品的有效浏览时间阈值。
不同类型产品的αjs、γjs会因为产品复杂度、网络速度、数据类型等不同而有所差异,在大数据背景下,αjs、γjs需要通过统计数据获得,目前《学习强国》视频浏览就采用了这种方法。用户对每一个产品的实际浏览时间需要满足T′ksi∈[αjs,γjs]方能认定为有效浏览。考虑到用户误操作、水军恶意点击等,若T′ksi<αjs,认为用户没有阅读该页面,则ρjsi=0;考虑到用户个人忘记关闭页面等情况,若T′ksi>γjs表征普通人以正常速度浏览完该页面所需要的时间上限(该数据可以借助历史数据通过统计分析得到),超出部分,不再计算,避免用户由于处理其他事情耽搁所带来的影响,此时ρjsi=1。
表示用户Uj浏览具有xt特征所有产品花费时间的平均值,其中I(s)表示第s类中具有xk特征的产品个数。
表示用户Uj浏览不具有xk特征所有产品花费时间的平均值,其中n为系统中的产品总数。
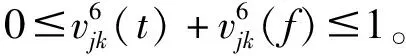
进而得到
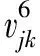
借助上文Vague值的基本运算规则,可以得到用户关于特征xk的兴趣度表示形式:
那么对于一维属性来说,用户的兴趣可以描述为多个特征构成的集合,每一个特征Vague值的大小代表用户的倾向态度。即:V(Uj)={Intj1,Intj2,…,Intip}。
4.4 产品属性特征与用户需求的匹配实现
由上文内容可知,系统中的产品可以用Vague值的形式表示为:V(Ii)={vx1(Ii),vx2(Ii),…,vxp(Ii)},系统中任意用户的需求兴趣度函数可以表示为:V(Uj)={Intj1,Intj2,…,Intjp}。
知识推荐就是要通过产品属性特征和用户需求兴趣度之间的内在联系,借助知识库中的知识抽取两者之间的关联关系。在推荐系统中,这种关联关系可以简单的描述为一种相关性,借助向量空间相似度、Spearman相关、Pearson相关、熵、余弦方法、修正余弦方法以及条件概率方法等多种方法[24]得到。由于产品属性特征和用户需求兴趣度均已表达为Vague集的形式,因此需要解决的问题是求得两个集合之间的关联关系,Vague集理论中关于两个集合关联关系的描述可以理解为两个集合的相似性问题。
根据系统中的两个Vague集V(Ii)和V(Uj),基于前文王伟平[18]提出的相似度的计算公式可以得到知识推荐中的相似度计算公式:
Sim(V(Ii),V(Uj))
其中n代表集合A和B中Vague值的个数。
可以得到产品和用户之间的相似程度,这种相似程度表达了产品属性特征与用户兴趣需求之间的匹配程度。
4.5 案例应用
本次案例抽取爱奇艺的数据,抽取的不同年龄段的5名用户信息如表1所示,同时抽取爱奇艺中2019年新发布的5部影片如表2所示。

表1 用户情况表

表2 电影情况表
定义电影属性为:X={剧情x1,喜剧x2,爱情x3,冒险x4,奇幻x5,动作x6,悲剧x7,犯罪x8,家庭x9,青春x10},利用4.2的内容可以得到各个电影关于各个特征的Vague值,如表3所示。

表3 电影特征Vague值
利用4.3的内容可以得到各个用户关于各个特征兴趣度的Vague值(中间计算过程可以找作者索取),如表4所示。
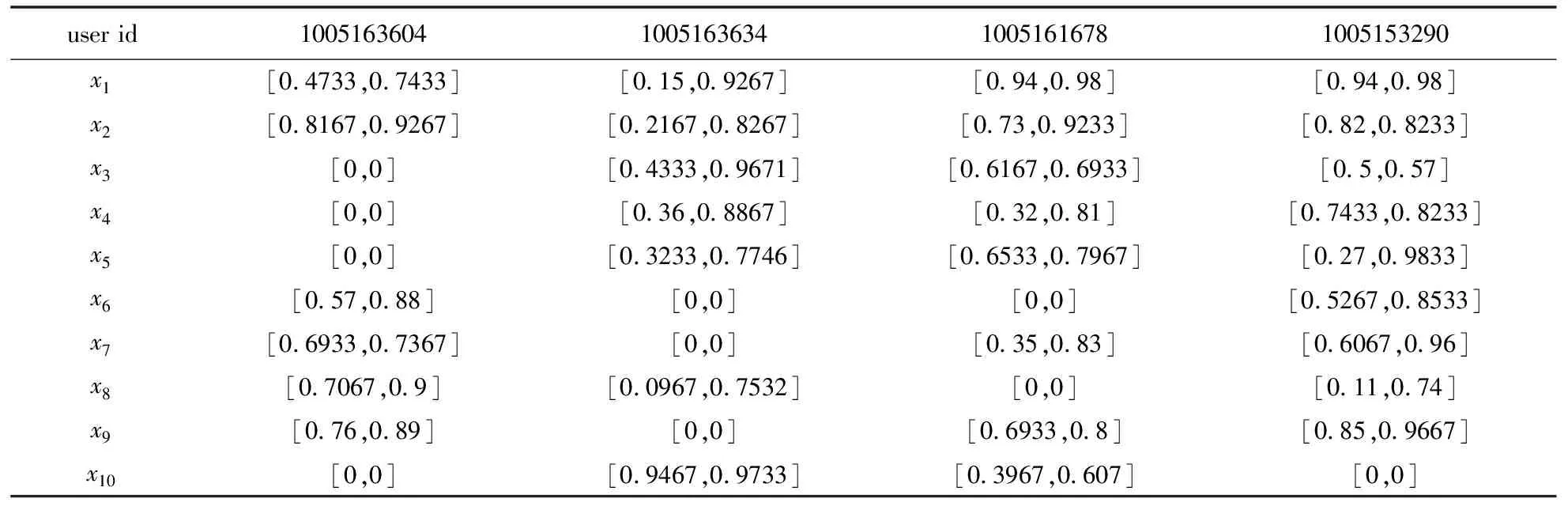
表4 用户兴趣Vague值
进而利用上文给出的相似度计算公式得到电影和用户之间的匹配度(相似度),如表5所示。
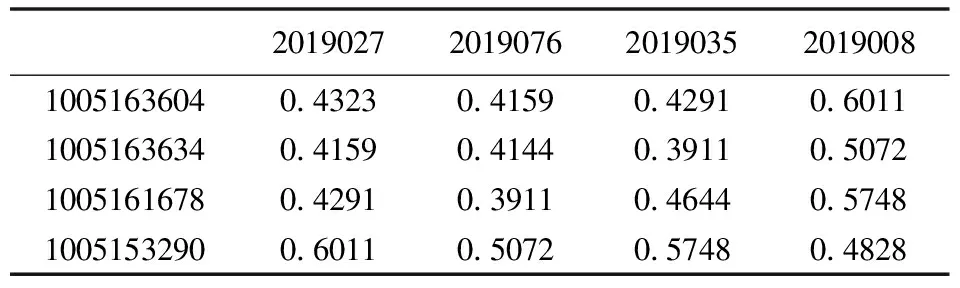
表5 用户与电影的匹配度
由上述计算结果可以看到,论文中提取的5个用户和5个产品中,产品属性特征和用户兴趣的匹配度并不是很高,说明5个用户对以上提取的新电影并不是很感兴趣。如果放松兴趣度阈值范围,可以认为2019027、2019035、2019076三部电影能在一定程度上满足用户1005153290的需求。由于相似度的可逆性可知,电影2019008也能在一定程度上满足用户1005163604、1005161678、1005163634的需求。从知识库的角度来说,可以构建六组知识库,进而形成后期决策和推荐的知识模型。
5 结论及展望
论文的主要工作表现在以下几个方面:第一,用产品的一维属性特征来描述系统中待推荐的产品,用户的隐性兴趣和显性兴趣集成用户的兴趣爱好。第二,整体上运用Vague集理论形式化的语言特征的优点,用Vague值描述用户的兴趣爱好和产品的属性。第三,用产品的属性Vague集与用户的兴趣爱好Vague集的相似度描述两者之间的匹配度,进而形成推荐系统中的知识库,构架知识推荐的基础。论文的这一研究思路首先解决了非结构化产品属性特征和用户需求的表达和描述难点,其次在冷启动无可规避的情况下,一定程度上解决了推荐系统中数据稀疏的研究难点。最后通过匹配度的计算构建了知识推荐中的知识库,形成后期知识推荐的模块规则。
通过论文的研究,也发现了一些后期研究的方向。第一,论文为了降低计算的复杂度,仅仅构建了一维属性模型,这种研究结果可能会有一定局限性,在多维属性条件下,研究的结果会带来更加精准的推荐结果。第二,在买方市场的背景下,个性化产品、个性化需求将会是未来的主流发展方向,然而在这种情况下,推荐结果的适应性问题并没有得到准确的诠释,如何借助不确定语言和不确定方法捕捉描述 “个性化”的问题也是后期研究的方向之一。
猜你喜欢
中学生数理化·中考版(2022年9期)2022-10-25
中学生数理化(高中版.高考数学)(2022年3期)2022-04-26
成都信息工程大学学报(2019年4期)2019-11-04
阅读与作文(英语初中版)(2019年8期)2019-08-27
当代陕西(2019年10期)2019-06-03
小学生学习指导(低年级)(2018年11期)2018-12-03
现代防御技术(2016年1期)2016-06-01
山东青年(2016年1期)2016-02-28
当代修辞学(2014年3期)2014-01-21
公务员文萃(2013年5期)2013-03-11
