
基于深层神经网络的英语口语发音错误捕捉方法研究
2020-10-23 08:54:52窦旭霞
黑龙江工业学院学报(综合版) 2020年8期
窦旭霞
(烟台职业学院,山东 烟台 264670)
随着语音信号处理技术的发展,采用语音信号识别方法进行英语口语发音错误捕捉,能够有效提高英语口语发音错误捕捉能力,因此对该问题的研究在提高英语口语教学有效性方面具有重要意义[1]。由于相关的英语口语发音错误捕捉方法对于英语口语发音规范化具有促进作用,因此对于英语口语发音错误捕捉方法的研究受到人们的极大关注。传统英语口语发音错误捕捉方法是建立在语音信号分析基础上,采用动态特征分析方法进行英语口语发音错误捕捉和特征识别[2],但是该方法存在英语口语发音错误捕捉准确性较低的问题,实际应用效果并不理想。为了解决传统方法存在的问题,提出了基于深层神经网络的英语口语发音错误捕捉方法。
一、英语口语发音语音信号模型和特征分析
1.英语口语发音语音信号模型
为了实现基于深层神经网络的英语口语发音错误捕捉,首先构建英语口语发音语音信号检测模型,采用多传感检测方法,进行英语口语发音语音信号的原始数据采集,对采集到的英语口语发音语音信号进行尺度分解和特征提取[3],在此基础上进行英语口语发音错误捕捉和特征检测。其中,英语口语发音语音信号的数学模型表达式为:
(1)
上式中,a(t)称为英语口语发音语音信号在第n个阵元接收信号幅度,有时也称为包络;φ(t)称为多均匀直线宽带阵列相位,Z(f)可由S(f)通过傅里叶变换得到,H(f)为英语口语发音语音信号的阶跃式传输函数。
基于粒子群算法进行英语口语发音语音信号建模和检测识别,得到语音信息采样的阵元分布为vm,m∈[1,n]。英语口语发音语音信号的回波脉冲表示为:
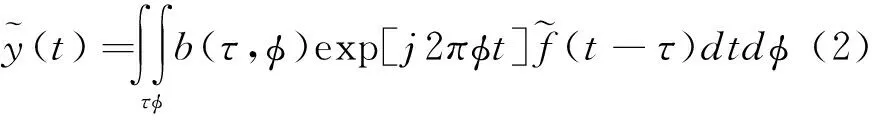
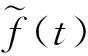
(3)
上式中,f(t)为接收到的英语口语发音语音信号的瞬时频率估计值,ρ(a,b)为宽带信号入射到阵元上的延时分量,a为信号的高阶统计特征信息,b为频移分布[4]。在新的簇头节点,得到英语口语发音信息的特征分量为:
(4)
更新融合权重,得到输出信号分量Xp(u),表示为:
(5)
其中,p为最佳接收极化矢量的阶数,可以为任意实数,语音检测的相位为α=pπ/2,当足π/2时,即旋转至频率轴,由此实现对英语口语发音语音信号的统计信息建模[5]。
2.英语口语发音谱特征量分析
采用多传感融合跟踪识别方法进行英语口语发音的语音信号采集,结合时频特征分解方法进行英语口语发音错误信息特征提取,英语口语发音语音信号长度l,得到英语口语发音语音信号的谱特征量为:
(6)
l=a·fl+b
(7)
其中,a、b表示英语口语发音语音信号的块稀疏特征参数。对于给定的宽带高分辨英语口语发音语音信号x(n)和尺度d,采用期望和方差联合估计方法进行英语口语发音语音信号动态检测,设置英语口语发音语音信号x(n)在尺度d的方差用E(ni,d)表示、最大功率谱特征量用max{E(ni,d)}表示,英语口语发音语音信号的模糊度辨识参数为:
(8)
对x(t)进行抽样滤波处理后,能够获取英语口语发音语音信号的离散特征分量x(n),英语口语发音语音信号的集成窗函数h(t)的宽度为T=(2d+1)Ts,Fs=1/Ts。设宽带高分辨英语口语发音语音信号为x(t),对其进行加窗操作[6],英语口语发音语音信号在频谱分布区间[m0-Δm/2,m0+Δm/2]上服从均匀分布,英语口语发音语音信号的谱特征量为:
r(t)=g(t)+n(t)
(9)
式中,g(t)为概率密度函数,采用多级滤波方法进行英语口语发音语音信号的稀疏性检测,结构模型如图1所示。根据英语口语发音语音信号的谱特征分离结果,实现英语口语发音谱特征量分析。
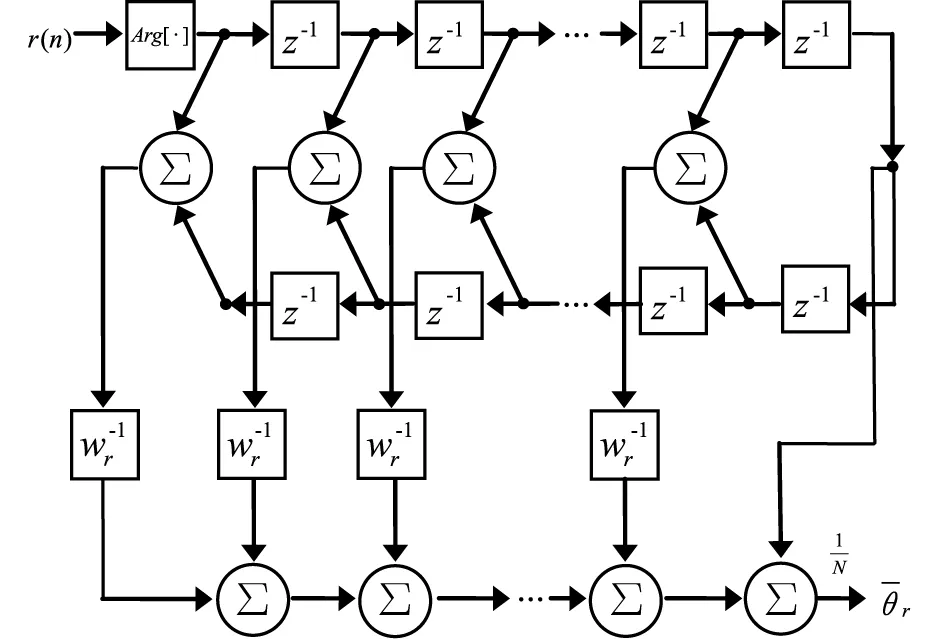
图1 英语口语发音语音信号的谱特征检测模型
二、英语口语发音语音错误捕捉优化
1.英语口语发音信号的特征筛选和分类识别
假设输入的英语口语发音语音信号为一个单频信号cos2πf0t,其中f0为英语口语发音频率,设第1个阵元检测到的英语口语发音语音信号的基准分量,构建英语口语发音的错误特征筛选模型,采用时频特征变换方法进行英语口语发音语音信号动态检测和特征筛选处理[7],则第m个块稀疏特征量为:
sm(t)=cos{2πf0[t+τm(θ)]}
(10)
采用目标源信号检测方法,进行英语口语发音语音信号的特征监测,得到英语口语发音错误特征分布为:
(11)
其中:
um=cos[2πf0τm(θ)];vm=sin[2πf0τm(θ)]
(12)
通过上述过程提取到英语口语发音语音信号的特征量,采用波束形成方法进行英语口语发音语音信号的特征聚焦,采用深层神经网络检测方法进行英语口语发音语音信号错误特征检测[8],输出为:
y1(t)=A1(t)exp{j2π[F(t-ta)ln(t-ta)-
F(t-ta)-FlnDt+fe1t]}
(13)
输出的英语口语发音错误特征量表示为:
y2(t)=A2(t)exp{j2π[F(t-ta)ln(t-ta)-
F(t-ta)-FlnDt+fe2t]}
(14)
式中,fe1为波束域截止频率,fe2为谐波截止频率。采用统计特征分析方法进行英语口语发音错误特征分离[9],得到英语口语发音错误信息为:
y(t)=s(t)+n(t)
(15)
英语口语发音错误信息的频谱为:
Yp(u)=Fa[y(t)]
=Fa[s(t)+n(t)]
=Fa[s(t)]+Fa[n(t)]
(16)
在信号的先验概率满足收敛条件的情况下,计算英语口语发音语音信号的时间宽度:
(17)
英语口语发音语音信号的频域特性描述为:
(18)
根据贝叶斯公式,进行英语口语发音信号的特征筛选,检测输出为:
(19)
采用深度神经网络学习方法,进行英语口语发音信号的特征筛选和分类识别。
2.英语口语发音语音错误捕捉输出
建立英语口语发音错误信号的统计特征分析模型,采用深层神经网络分类器进行英语口语发音信号的特征筛选和分类识别,根据特征分类结果实现英语口语发音错误信息捕捉和识别,为了防止过拟合,对L个块特征量采用模糊状态分离方法,得到特征参数a1(t)和a2(t)由下式确定:
(20)
根据英语口语发音语音错误特征筛选输出为:
(21)
上式中,a(t)称为英语口语发音语音信号的z(t)瞬时幅度,φ(t)称为英语口语发音错误特征的模糊状态分量,采用如下检测门限进行英语口语发音语音错误特征检测:
xmin,j=max{xmin,j,xg,j-ρ(xmax,j-xmin,j)}
(22)
xmax,j=min{xmax,j,xg,j+ρ(xmax,j-xmin,j)}
(23)
结合先验概率和似然函数估计方法[10],得到英语口语发音错误特征检测输出为:
(24)
此时英语口语发音语音错误捕捉输出表示为:
其中,γ代表英语口语发音错误特征分量。
三、仿真实验与结果分析
为了测试本文算法在实现英语口语发音错误捕捉方面的性能,进行仿真实验,实验采用Matlab 7仿真软件设计,英语口语发音信号采样节点数量为120,特征提取的分辨率为200KHZ,输出的英语口语发音语音信号长度为1200,待测语音信号集个数为20,干扰信噪比为20dB,根据上述仿真参量设定,进行英语口语发音错误捕捉仿真分析,其中英语口语发音信号模型如图2所示。
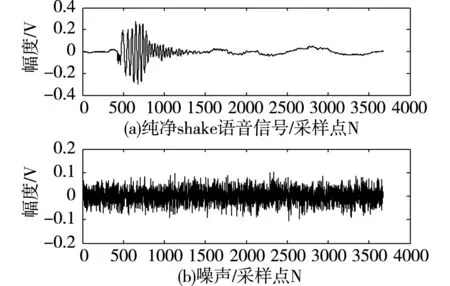
图2 英语口语发音信号模型
以图2的英语口语发音信号为研究对象,进行英语口语发音的错误捕捉,得到捕捉结果如图3所示。

图3 英语口语发音的错误捕捉结果
分析图3得知,本文方法能有效实现对英语口语发音的错误捕捉和特征分离。测试不同方法英语口语发音的错误捕捉的精度,得到对比结果如图4所示。

图4 捕捉精度对比
分析图4得知,本文方法的英语口语发音的错误捕捉的精度较高,实用性较强。
结语
研究英语口语发音错误捕捉方法,在提高英语口语教学有效性方面具有重要意义,能够促进英语口语发音规范化,因此本文提出基于深层神经网络的英语口语发音错误捕捉方法。给出英语口语发音语音信号检测模型,采用多传感检测方法进行英语口语发音语音信号的原始数据采集,对采集到的英语口语发音语音信号进行尺度分解和特征提取,提取英语口语发音语音信号的特征量,采用波束形成方法进行英语口语发音语音信号的特征聚焦,采用深层神经网络检测方法实现英语口语发音语音信号错误特征检测和捕捉。分析得知,本文方法进行英语口语发音错误捕捉的精度较高,可靠性与实用性较强。
猜你喜欢
阅读(快乐英语中年级)(2023年9期)2023-10-24 07:07:26
阅读(快乐英语高年级)(2019年5期)2019-09-10 07:22:44
电子制作(2019年14期)2019-08-20 05:43:38
电子制作(2019年9期)2019-05-30 09:42:10
小说界(2018年5期)2018-11-26 12:43:42
疯狂英语·新策略(2017年7期)2018-01-03 06:50:36
疯狂英语·新策略(2017年8期)2017-05-31 08:13:19
小学生时代·大嘴英语(2015年12期)2016-01-07 16:10:00
当代教育实践与教学研究(2015年2期)2015-02-27 08:03:04
小学生时代·大嘴英语(2014年11期)2014-12-04 20:13:32
